📖 학습주제
머신러닝, Scikit-learn, 실전 머신러닝 문제 실습 (2)
머신러닝을 위한 기초 선형대수
선형대수를 알아야 하는 이유
Deep learning을 이해하기 위해서 반드시 선형대수 + 행렬미분 + 확률의 탄탄한 기초가 필요하다.
Transformer의 attention matrix의 예를 보자.
Att↔(Q,K,V)=D−1AV,A=exp(QKT/d),D=diag(A1L)
이렇게 핵심 아이디어가 행렬에 관한 식으로 표현되는 경우가 많다.
기본 표기법 (Basic Notation)
- A∈Rm×n는 m개의 행과 n개의 열을 가진 행렬을 의미
- x∈Rn는 n개의 원소를 가진 벡터를 의미
- n개의 행과 1개의 열을 가진 행렬로 생각할 수 있다.
- 열벡터(column vector)라고 부르기도 함(명시적으로 행벡터(row vector)를 표현하고자 한다면 xT로 씀, T는 transpose)
- 벡터 x의 i번째 원소를 xi로 표기
x=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1x2⋮xi⋮xn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
- aij (또는 Aij,Ai,j)는 행렬 A의 i번째 행, j번째 열의 원소를 의미
A=⎣⎢⎢⎢⎢⎡a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎦⎥⎥⎥⎥⎤
- 행렬A의 j번째 열을 aj(또는 A⋅j), i번째 행을 aiT(또는 Ai⋅T)로 표기
In Python
numpy(이하 np)의 array를 이용해 배열을 생성할 수 있다. np.expand_dims(arr, axis) : 배열의 차원을 확장arr.shape : 배열의 형태arr[:, j] : 열벡터, arr[i, :] : 행벡터
행렬의 곱셉 (Matrix Multiplication)
행렬 A∈Rm×n, B∈Rn×p에 대해, 두 행렬의 곱 C∈Rm×p는 다음과 같이 정의된다.
Cij=k=1∑nAikBkj
벡터 × 벡터 (Vector-Vector Products)
벡터 x,y∈Rn에 대해, 두 벡터의 내적(inner product) xTy는 다음과 같이 정의된다.
xTy∈R=[x1x2⋯xn]⎣⎢⎢⎢⎢⎡y1y2⋮yn⎦⎥⎥⎥⎥⎤=i=1∑nxiyi
벡터 x∈Rm,y∈Rn에 대해, 두 벡터의 외적(outer product) xyT는 다음과 같이 정의된다.
xyT∈Rm×n=⎣⎢⎢⎢⎢⎡x1x2⋮xm⎦⎥⎥⎥⎥⎤[y1y2⋯yn]=⎣⎢⎢⎢⎢⎡x1y1x2y1⋮xmy1x1y2x2y2⋮xmy2⋯⋯⋱⋯x1ynx2yn⋮xmyn⎦⎥⎥⎥⎥⎤
행렬 × 벡터 (Matrix-Vector Products)
행렬 A∈Rm×n와 벡터 x∈Rn에 대해, 각 행렬과 벡터의 곱 y는 y=Ax∈Rm으로 정의된다.
In Python
arr1.dot(arr2) : arr1과 arr2의 내적np.matmul(arr1, arr2) : arr1과 arr2의 행렬곱
중요 연산과 성질들 (Operations and Properties)
- 정방행렬(square matrix) : 행과 열의 개수가 동일
- 상삼각행렬(upper triangular matrix) : 정방행렬이며 대각선 원소 아래 원소들이 모두 0
- 하삼각행렬(lower triangular matrix) : 정방행렬이며 대각선 원소 위 원소들이 모두 0
- 대각행렬(diagonal matrix) : 정방행렬이며 대각선 원소를 제외한 모든 원소가 0
- 단위행렬(identity matrix): 대각행렬이며 대각선 원소들이 모두 1. I로 표시
In Python
np.diag(arr) : 대각행렬을 리턴np.eye(n) : 크기 n의 단위행렬을 리턴
전치 (Transpose)
행렬 A∈Rm×n에 대해, 그 행렬의 전치행렬을 AT∈Rn×m으로 표기하고 다음과 같이 정의한다.
AijT=Aji
전치의 성질
- (AT)T=A
- (AB)T=BTAT
- (A+B)T=AT+BT
In Python
대칭행렬 (Symmetic Matrices)
정방행렬 A∈Rn×n과 그 행렬의 전치행렬 AT∈Rn×n에 대해,
A=AT이면 A를 대칭행렬이라고 하고 A=−AT이면 반대칭행렬이라고 한다.
대칭행렬의 성질
- AAT는 항상 대칭
- A+AT는 대칭, A−AT는 반대칭
대각합(Trace)
정방행렬 A∈Rn×n에 대해, i=1∑nAii를 A의 대각합이라고 하고 tr(A)로 표기한다.
대각합의 성질
A∈Rn×n,B∈Rn×n,t∈R에 대해,
- tr(A)=tr(AT)
- tr(A+B)=tr(A)+tr(B)
- tr(tA)=t⋅tr(A)
행렬곱(ABorABC)이 정방행렬이 되는 A,B,C에 대해
- tr(AB)=tr(BA)
- tr(ABC)=tr(BCA)=tr(CAB)
norm
벡터공간에서 벡터의 길이, 크기, 거리 등을 나타낼 때 사용되며, l2(Euclideannorm)은 다음과 같이 정의된다.
∣∣x∣∣2=i=1∑nxi2,(∣∣x∣∣22=xTx)
lp(Frobeniusnorm)
∣∣x∣∣p=(i=1∑nxip)1/p
Frobeniusnorm에 대해
∣∣A∣∣F=i=1∑mj=1∑nAij2=tr(ATA)
In Python
numpy.linalg(이하 LA)를 import
선형독립
벡터들의 집합 X={x1,x2,⋯,xn}⊂Rn에 대해, 모든 X의 원소가 다른 원소들의 선형 결합으로 나타낼 수 없을 때 이를 선형독립(Linear Independent)이라고 한다. (반대는 선형 종속(Linear dependent))
Rank
- Column rank : 행렬 A∈Rm×n의 열들의 부분집합 중에서 가장 큰 선형독립인 집합의 크기
- Row rank : 행렬 A∈Rm×n의 행들의 부분집합 중에서 가장 큰 선형독립인 집합의 크기
- 모든 행렬의 column rank와 row rank는 동일하며 행렬 A의 랭크를 rank(A)로 표시한다.
Rank의 성질
행렬 A∈Rm×n, B∈Rn×p에 대해
- rank(A)≤min(m,n)
- rank(A)=min(m,n)일 때, A가 fullrank라고 한다.
- rank(A)=rank(AT)
- rank(AB)≤min(rank(A),rank(B))
- rank(A+B)≤rank(A)+rank(B), (단, A,B∈Rm×n)
In Python
LA.matrix_rank(A) : rank를 리턴
역행렬(Inverse matrix)
정방행렬 A∈Rn×n에 대해, AA−1=I=A−1A일 때, A−1를 A의 역행렬이라고 하며 이 때, A를 invertible(또는 non−singular)하다고 한다.
역행렬의 성질
- Aisinvertible⇔Aisfullrank
- (A−1)−1=A
- (AB)−1=B−1A−1
- (AT)−1=(A−1)T
In Python
직교행렬 (Orthogonal Matrices)
두 벡터 x,y∈Rn에 대해 xTy=0 일 때, 두 벡터가 직교(Orthogonal)한다고 하며 모든 열들이 서로 직교이고 정규화된 정방행렬 U∈Rn×n를 직교행렬이라고 한다. 또한, ∥x∥2=1인 벡터 x∈Rn를 정규화(normalized)된 벡터라고 한다.
직교행렬의 성질
- UTU=I
- UUT=I
- U−1=UT
- ∥Ux∥2=∥x∥2 for any x∈Rn
- ∥Ux∥2=((Ux)T(Ux))1/2=(xTUTUx)1/2=(xTx)1/2=∥x∥2
치역(Range), 영공간(Nullspace)
생성집합(Span)
벡터의 집합 X={x1,x2,…,xn}에 대해,
Y={v:v=∑i=1nαixi,αi∈R}를 X의 생성집합(Span)이라고 하고 span(X)로 표기한다.
치역 (range)
행렬 A∈Rm×n에 대해, A의 모든 열들에 대한 생성(span)을 치역이라고 하며 R(A)로 표기한다.
R(A)={v∈Rm:v=Ax,x∈Rn}
영공간 (nullspace)
행렬 A∈Rm×n에 대해, A와 곱해졌을 때 0이 되는 모든 벡터들의 집합을 영공간이라고 하며 N(A)로 표기한다.
N(A)={x∈Rn:Ax=0}
치역, 영공간에 대한 성질
- {w:w=u+v,u∈R(AT),v∈N(A)}=Rn and R(AT)∩N(A)={0}
직교여공간(orthogonal complements)
R(AT)와 N(A)를 직교여공간(orthogonal complements)라고 하며 R(AT)=N(A)⊥라고 표시한다.
사영 (projection)
A의 치역 R(A), 벡터 y∈Rm에 대해, 다음을 만족할 때 Proj(y;A)를 R(A) 위로 벡터 y의 사영(projection)이라고 한다.
Proj(y;A)=argminv∈R(A)∥v−y∥2=A(ATA)−1ATy
UTU=I인 정방행렬 U는 UUT=I임을 증명
- U의 치역은 전체공간이므로 임의의 y에 대해 Proj(y;U)=y이어야 한다.
- 모든 y에 대해 U(UTU)−1Uy=y이어야 하므로 U(UTU)−1UT=I이다.
- 따라서 UUT=I이다.
행렬식 (Determinant)
정방행렬 A∈Rn×n의 행렬식(determinant) ∣A∣ (또는 det(A))는 다음과 같이 계산할 수 있다.
∣A∣=A1,1×∣A\1,\1∣−A1,2×∣A\1,\2∣+A1,3×∣A\1,\3∣−A1,4×∣A\1,\4∣+⋯±A1,n×∣A\1,\n∣
여기서 A\i,\j는 i번째 행과 j번째 열을 없애버린 행렬을 의미한다.
e.g.)
A=⎣⎢⎡147258360⎦⎥⎤
위의 식을 사용하면 아래와 같이 전개된다.
∣A∣=1×∣∣∣∣∣[5860]∣∣∣∣∣−2×∣∣∣∣∣[4760]∣∣∣∣∣+3×∣∣∣∣∣[4758]∣∣∣∣∣
이제 위의 2×2 행렬들의 행렬식을 계산한다.
∣∣∣∣∣[5860]∣∣∣∣∣=5×0−6×8=−48
∣∣∣∣∣[4760]∣∣∣∣∣=4×0−6×7=−42
∣∣∣∣∣[4758]∣∣∣∣∣=4×8−5×7=−3
따라서,
∣A∣=1×(−48)−2×(−42)+3×(−3)=27
#### 행렬식의 기하학적 해석
행렬
⎣⎢⎢⎢⎢⎡a1Ta2T⋮anT⎦⎥⎥⎥⎥⎤
이 주어졌을 때, 행 벡터들의 선형결합(단 결합에 쓰이는 계수들은 0에서 1사이)이 나타내는 Rn 공간 상의 모든 점들의 집합 S를 생각해보자. 엄밀하게 나타내자면
S={v∈Rn:v=∑i=1nαiai where 0≤αi≤1,i=1,…,n}
중요한 사실은 행렬식의 절대값이 이 S의 부피(volume)과 일치한다는 것이다!
예를 들어, 행렬
A=[1332]
의 행벡터들은
a1=[13]a2=[32]
이다. S에 속한 점들을 2차원평면에 나타내면 다음과 같다.
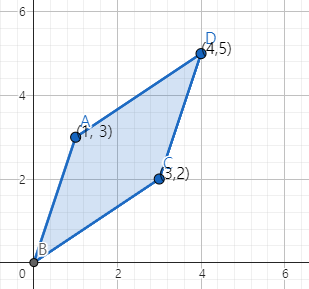
평행사변형 S의 넓이는 7인데 이 값은 A의 행렬식 ∣A∣=−7의 절대값과 일치함을 알 수 있다.
행렬식의 성질
- ∣I∣=1
- A의 하나의 행에 t∈R를 곱했을 때, 행렬식은 t∣A∣
- A의 두 행들을 교환했을 때 행렬식은 −∣A∣
- A,B∈Rn×n에 대해,
- ∣A∣=∣AT∣
- ∣AB∣=∣A∣∣B∣
- ∣A∣=0⇔Aisnotinvertible
- A가 non−singular할 때, ∣A−1∣=1/∣A∣.
In Python
정방행렬 A∈Rn×n와 벡터 x∈Rn가 주어졌을 때, scalar값 xTAx를 이차형식(quadratic form)이라고 하며 다음과 같이 표현할 수 있다.
xTAx=xT(Ax)=i=1∑nxi(Ax)i=i=1∑nxi(j=1∑nAijxj)=i=1∑nj=1∑nAijxixj
다음이 성립함을 알 수 있다.
xTAx=(xTAx)T=xTATx=xT(21A+21AT)x
따라서 이차형식에 나타나는 행렬을 대칭행렬로 가정하는 경우가 많다.
양/음의 (준)정부호
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx>0을 만족할 때, 양의 정부호(positivedefinite)라고 하고 A≻0(또는 단순히 A>0)로 표시한다. 모든 양의 정부호 행렬들의 집합을 S++n으로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx≥0을 만족할 때, 양의 준정부호(positivesemi−definite)라고 하고 A⪰0(또는 단순히 A≥0)로 표시한다. 모든 양의 준정부호 행렬들의 집합을 S+n으로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx<0을 만족할 때, 음의 정부호(negativedefinite)라고 하고 A≺0(또는 단순히 A<0)로 표시한다.
- 대칭행렬 A∈Sn이 0이 아닌 모든 벡터 x∈Rn에 대해서 xTAx≤0을 만족할 때, 음의 준정부호(negativesemi−definite)라고 하고 A⪯0(또는 단순히 A≤0)로 표시한다.
- 대칭행렬 A∈Sn가 양의 준정부호 또는 음의 준정부호도 아닌 경우, 부정부호(indefinite)라고 한다. 이것은 x1TAx1>0,x2TAx2<0을 만족하는 x1,x2∈Rn이 존재한다는 것을 의미한다.
positivedefinite 그리고 negativedefinite 행렬은 fullrank이며 따라서 invertible이다.
Gram matrix
임의의 행렬 A∈Rm×n이 주어졌을 때 행렬 G=ATA를 Grammatrix라고 부르고 항상 (positivesemi−definite이다. 만약 m≥n이고 A가 fullrank이면, G는 positivedefinite이다.
고유값 (Eigen values), 고유벡터 (Eige nvectors)
정방행렬 A∈Rn×n이 주어졌을 때, Ax=λx,x=0을 만족하는 λ∈C를 A의 고유값(eigenvalue) 그리고 x∈Cn을 연관된 고유벡터(eigenvector)라고 한다.
In Python
고유값, 고유벡터의 성질
- trA=i=1∑nλi
- ∣A∣=i=1∏nλi
- rank(A)는 0이 아닌 A의 고유값의 개수와 같다.
- A가 non−singular일 때, 1/λi는 A−1의 고유값이다(고유벡터 xi와 연관된). 즉, A−1xi=(1/λi)xi이다.
- 대각행렬 D=diag(d1,…,dn)의 고유값들은 d1,…,dn이다.
행렬미분 (Matrix Calculus)
Gradient
행렬 A∈Rm×n를 입력으로 받아서 실수값을 돌려주는 함수 f:Rm×n→R이 있다고 하자. f의 gradient는 다음과 같이 정의된다.
∇Af(A)∈Rm×n=⎣⎢⎢⎢⎢⎢⎡∂A11∂f(A)∂A21∂f(A)⋮∂Am1∂f(A)∂A12∂f(A)∂A22∂f(A)⋮∂Am2∂f(A)⋯⋯⋱⋯∂A1n∂f(A)∂A2n∂f(A)⋮∂Amn∂f(A)⎦⎥⎥⎥⎥⎥⎤
(∇Af(A))ij=∂Aij∂f(A)
특별히 A가 벡터 x∈Rn인 경우는,
∇xf(x)=⎣⎢⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎥⎤
Hessian
∇x2f(x)∈Rn×n=⎣⎢⎢⎢⎢⎢⎢⎡∂x12∂2f(x)∂x2x1∂2f(x)⋮∂xnx1∂2f(x)∂x1x2∂2f(x)∂x22∂2f(x)⋮∂xnx2∂2f(x)⋯⋯⋱⋯∂x1xn∂2f(x)∂x2xn∂2f(x)⋮∂xn2∂2f(x)⎦⎥⎥⎥⎥⎥⎥⎤
(∇x2f(x))ij=∂xi∂xj∂2f(x)
중요한 공식
x,b∈Rn, A∈Sn일 때 다음이 성립한다.
- ∇xbTx=b
- ∇xxTAx=2Ax
- ∇x2xTAx=2A
- ∇Alog∣A∣=A−1 (A∈S++n인 경우)
벡터가 아닌 경우
- (bx)′=b
- (ax2)′=2ax
- (logx)′=x−1

