
📖 학습주제
대용량 데이터 훈련 대비 Spark, SparkML 실습 (2)
Dynamic Partition Pruning
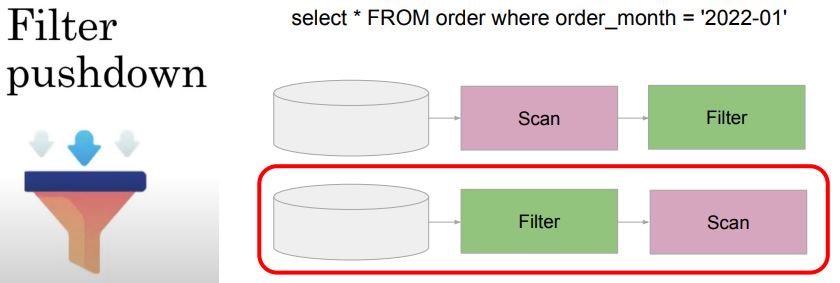
Filter (Predicate) Pushdown
- 데이터 소스에서 읽어들일 때 필터링을 적용해 읽는 데이터를 최소화
- 특정 데이터 소스에만 사용 가능 (PARQUET - 컬럼 통계 정보가 있는 경우)
Partition Pruning
최적화 방식의 일종, Optimizer가 정말 필요한 데이터와 불필요한 데이터를 구별하여 읽는 것
Static Partition Pruning
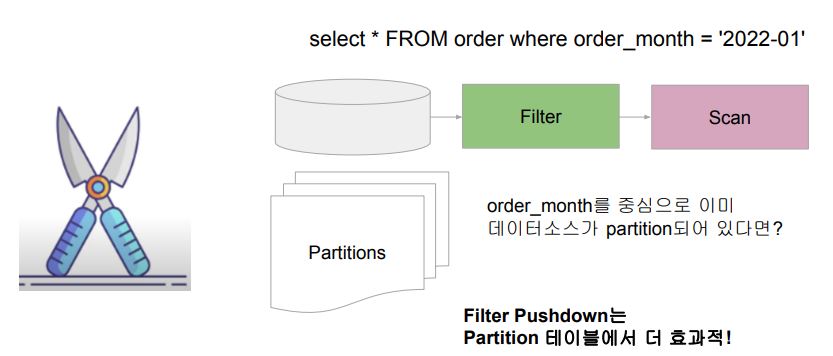
- 데이터소스가 필터링 컬럼을 중심으로 Partitioning되어 있는 경우
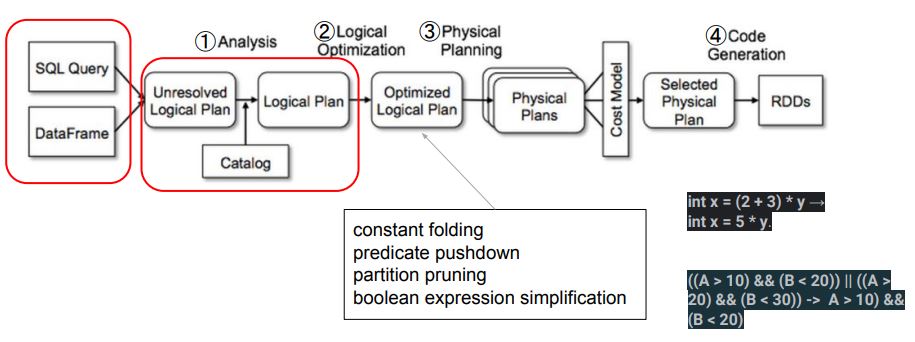
Partition Pruning과 Execution Plan
- Partition Pruning은 Logical Plan Optimization 단계에서 발생
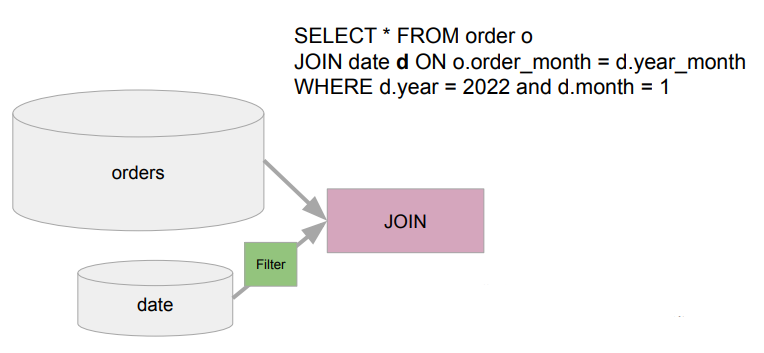
Static Partition Pruning의 문제
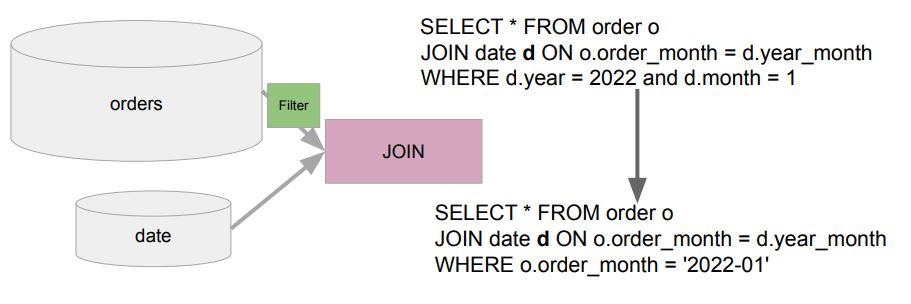
- Partitioning은 보통 큰 테이블에 적용되어 있음 (Fact 테이블). 그런데 만약 Fact 테이블(아래의 orders)과 Dimension 테이블(아래의 date) 조인시 필터링이 Dimension 테이블에 적용되어 있다면 규모가 큰 Fact 테이블은 모두 로딩되는데 이는 큰 낭비이다.
Dynamic Partition Pruning이란?
- 비 Partition 테이블에 적용된 필터링을 Partition 테이블에 적용해보는 것
- 후자가 작은 dimension 테이블이라면 브로드캐스트 조인까지 하면 금상첨화
Repartition and Coalesce
Repartition을 하는 이유
- 전체적으로 파티션의 수를 늘려 병렬성을 증가시키기 위해
- 굉장히 큰 파티션이나 Skew 파티션의 크기를 조절하기 위해서
- 파티션을 분석 패턴에 맞게 재분배 (Write once, read many)
- 어떤 DataFrame을 특정 컬럼 기준으로 그룹핑을 하거나 필터링을 자주 하는 경우
◦ 미리 그 컬럼 기준으로 저장해두었다면 그게 Bucketing
Repartition 방식
repartitionByRangerepartition(numPartitions, *cols)
- Hash 기반 Partitioning
-repartition(5)
-repartition(5, "city")
-repartition(5, "city", "zipcode")
-repartition("city")
-repartition("city", "zipcode")
repartitionByRange(numPartitions, *cols)
- 지정된 컬럼 값의 범위를 기준으로 파티션을 나누는 방식
- 데이터 샘플링 기반으로 파티션을 나누기에 결과가 매번 다를 수 있음
- Nondeterministic - 사용법 자체는 앞서 repartition과 동일
주의점
- Shuffling이 발생함. 분명한 이유를 가지고 Repartition을 사용해야함
- 많은 경우 repartition이 별 이유없이 사용되어 오히려 시간과 비용 증가
◦ 비슷하게 불필요한 counting과 distinct counting과 duplicate제거가 비용 발생 - Column이 사용되면 균등한 파티션 크기를 보장할 수 없음
- 파티션의 수를 줄이는 용도로는 사용불가 -> Coalesce 사용
Coalesce가 필요한 경우
- 파티션의 수를 줄이는 용도 (늘리지 않음)
- Shuffling이 발생시키지 않고 로컬 파티션들을 머지함
- 따라서 Skew 파티션을 만들어낼 수 있음 - Column이 사용되며 균등한 파티션 크기를 보장할 수 없음
DataFrame 관련한 힌트들
https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-hints.html
- Spark SQL Optimizer에게 Execution plan을 만듬에 있어 특정한 방식을 사용하도록 제안 (최적화된 방식을 변경하기 위해 사용)
DataFrame Partitioning 관련한 힌트들
COALESCEREPARTITIONREPARTITION_BY_RANGEREBALANCE
- DataFrame을 테이블로 저장할 때 아주 유용
- 파일의 크기를 최대한 비슷하게 만들어서 저장 (AQE 필요)
DataFrame Join 관련한 힌트들
BROADCAST,BROADCASTJOIN,MAPJOIN: Broadcast Join 사용 제안MERGE,SHUFFLE_MERGE,MERGEJOIN: Shuffle Merge Join 사용 제안
- Spark의 기본 조인 전략SHUFFLE_HASH: Shuffle Hash Join 사용 제안
- Full Outer Join에는 사용 불가SHUFFLE_REPLICATE_NL: Shuffle-and-replicate (Cross Join) Join 사용 제안
여러개가 동시에 사용이 될 경우, 위에서 아래로 갈 수록 우선순위가 낮아짐
참고
https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
AQE (Adaptive Query Execution)
Spark Optimization 역사
- Spark 1.x: Catalyst Optimizer와 Tungsten Project
- 전자는 규칙기반 최적화 수행 (Predicate pushdown, projection pushdown)
- 후자는 기본적으로 JVM 문제없이 코드 최적화를 하려는 것 (GC를 피하기 위해 직접 Off Heap 메모리 관리 수행) - Spark 2.x: CBO (Cost-Based Optimizer)
- 데이터프레임 통계정보 이용해 효율적인 execution plan 생성
◦ 전체 크기, 레코드 수, 컬럼별 특성 (최소/최대/히스토그램 등등)
AQE (Adaptive Query Execution) 이전 세상
SELECT sku, SUM(price) sales
FROM order
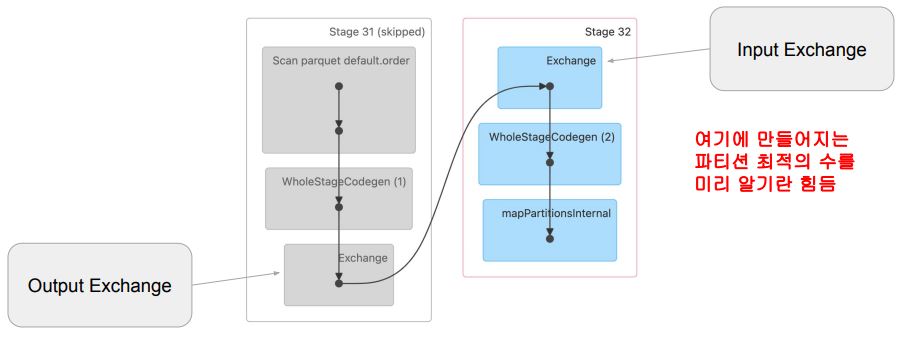
GROUP BY sku;- 위의 GROUP BY 쿼리는 2개의 stage를 만들어냄
spark.sql.shuffle.partitions값에 의해 Shuffling 후 Partition 수 결정
spark.sql.shuffle.partitions
- 이 변수 하나로 다양한 상황의 shuffling을 해결하기는 쉽지 않음
- MapReduce 세상에서mapreduce.job.reduces와 동일 - 적은 수의 Partition은 병렬성을 낮추고 OOM과 disk spill의 가능성을 높임
- 많은 수의 Partition은 task scheduler와 task 생성과 관련된 오버헤드가 생기며 너무 흔한 네트워크 I/O 요청으로 병목 초래
AQE
- “Dynamic query optimization that happens in the middle of query execution based on runtime statistics”
- AQE base all optimization decisions on accurate runtime statistics
언제 이런 실행시간 통계 정보를 뽑고 최적화 방식에 변경을 줄 수 있는 최적의 시점인가?
Query -> Job -> Stage -> Task

Stage가 가장 좋은 최적화 방식 변경 포인트
- Shuffling/Broadcasting이 Job을 Stage들로 나눔
- 또한 이 때 중간 결과들이 materialize됨
- 따라서 가장 좋은 시점이며 또한 Partition의 수와 크기 정보들도 알 수 있음
AQE 이후 세상
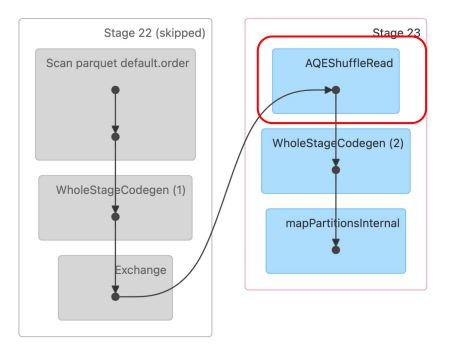
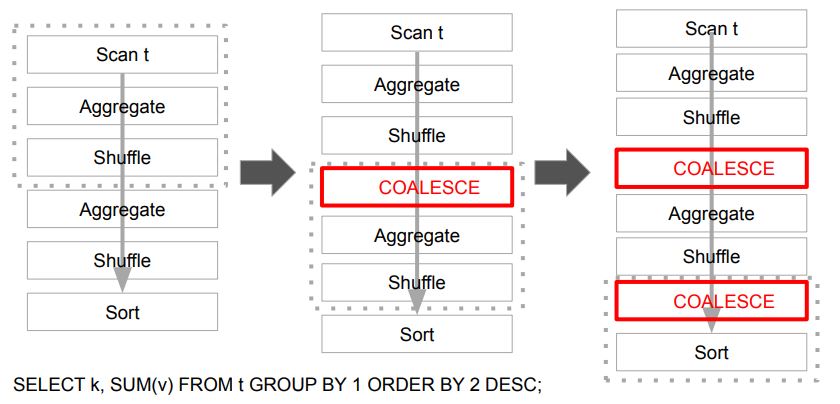
- 앞서 GROUP BY 쿼리 2번째 Stage 시작부에 AQEShuffleRead가 사용
AQE가 필요한 경우들
- Dynamically coalescing (Post) shuffle partitions (Spark 3)
- Dynamically switching join strategies (Spark 3.2)
- Dynamically optimizing skew joins (Spark 3)
Dynamically coalescing (Post) shuffle partitions
AQE의 동작 방식
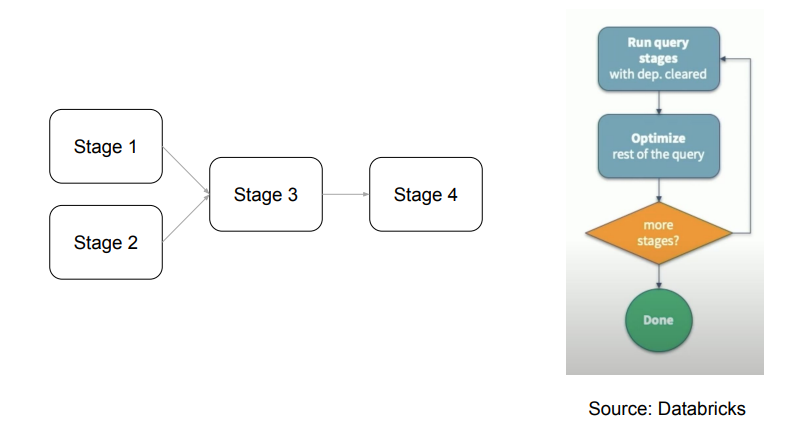
- Stage DAG를 순차적으로 실행
- 매번 새로운 최적화 기회가 있는지 조사
- 필요하면 다시 실행하거나 쿼리 플랜 변경
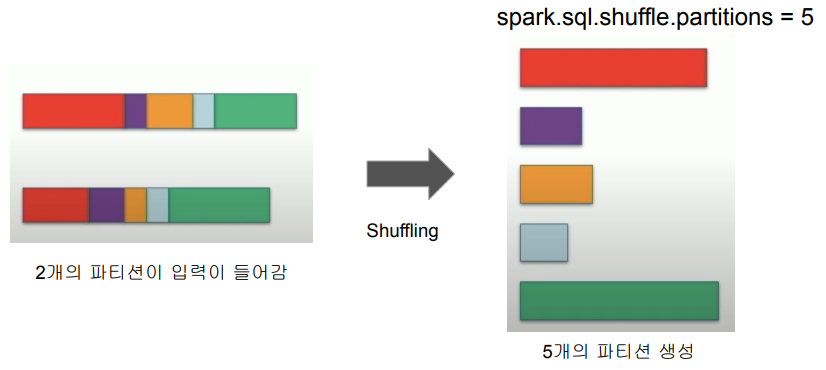
Dynamically coalescing shuffle partitions
왜 필요한가?
- 적당한 파티션의 크기와 수는 성능에 지대한 영향을 끼침
- 너무 많은 수의 작은 파티션
◦ 스케줄러 오버헤드
◦ 태스크 준비 오버헤드
◦ 비효율적인 I/O (파일시스템/네트워크)
- 적은 수 큰 파티션
◦ GC 악몽 (OOM = Out Of Memory)
◦ Disk Spill spark.sql.shuffle.partitions라는 하나의 변수로는 불충분
Dynamically coalescing shuffle partitions 동작방식
Dynamically coalescing shuffle partitions 관련 변수들 (3.3.1)
| 환경 변수 이름 | 기본값 | 설명 |
|---|---|---|
spark.sql.adaptive.coalescePartitions.enabled | True | spark.sql.adaptive.enabled도 true인 경우, 셔플 후 파티션 수를 동적으로 줄이며 파티션의 크기는 advisoryPartitionSizeInBytes 로 맞추려 시도 |
spark.sql.adaptive.advisoryPartitionSizeInBytes | 64MB | 셔플링 후 파티션 수를 줄일 때 목표로 하는 파티션의 크기 |
spark.sql.adaptive.coalescePartitions.parallelismFirst | True | 이 값이 true이면 병렬성 보장을 위해 위의 목표 크기가 무시되고 minPartitionSize만 보장 |
spark.sql.adaptive.coalescePartitions.initialPartitionNum | 없음 | Coalescing 전의 파티션 수. 없으면 spark.sql.shuffle.partitions로 설정 |
spark.sql.adaptive.coalescePartitions.minPartitionSize | 1MB | Coalescing 후 파티션의 최소 크기 |
Dynamically coalescing shuffle partitions 동작방식
AQE의 해법
- 내부적으로 많은 수의 파티션을 일부러 생성
-spark.sql.adaptive.coalescePartitions.initialPartitionNum (200) - 매 Stage가 종료될 때 필요하다면 자동으로 Coalesce 수행
-spark.sql.adaptive.coalescePartitions.enabled - 설정에 따라 파티션의 크기는 최소 크기 혹은 목표 크기를 맞추려 동작
-spark.sql.adaptive.advisoryPartitionSizeInBytes
-spark.sql.adaptive.coalescePartitions.minPartitionSize
- 무엇을 쓸지는spark.sql.adaptive.coalescePartitions.parallelismFirst에 의해 결정
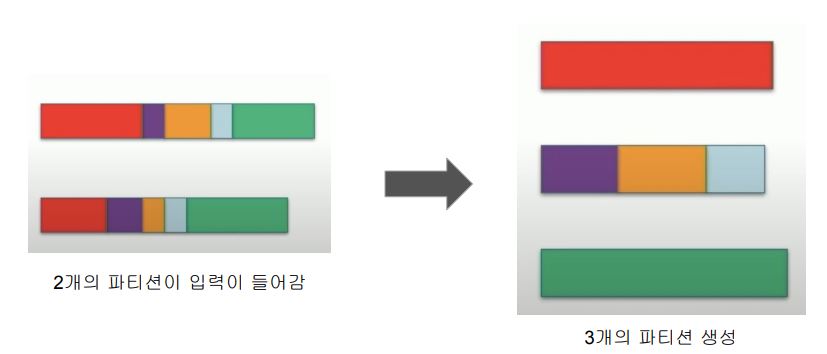
Coalescing이 없는 Shuffle
AQE Coalescing이 적용된 경우
Dynamically switching join strategies
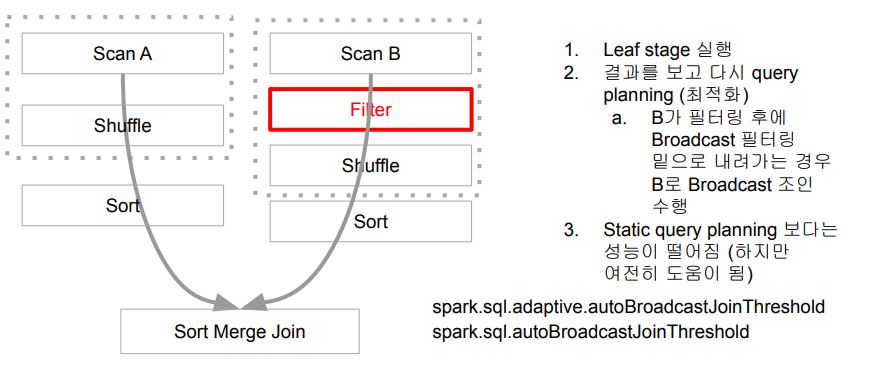
Dynamically switching join strategies
왜 필요한가?
- Static Query Plan이 여러 이유로 BHJ (Broadcast Hash Join) 기회를 놓친 경우
- 조인대상 DataFrame들에 대한 통계 정보 부족 (필터링 등)
- UDF가 사용된 경우
AQE의 해법
- Runtime 통계정보를 바탕으로 조인 전략을 변경
- 이는 stage들이 끝나고 조인되기 전에 다시 쿼리 플래닝을 수행 - 아래 두 가지 옵션이 존재
- Broadcast Join (추천되며 우선순위를 가짐)
- Shuffle Hash Join
Dynamically switching join strategies 동작방식
Dynamically switching join 관련 환경 변수들 (Spark 3.3.1)
| 환경 변수 이름 | 기본값 | 설명 |
|---|---|---|
spark.sql.join.preferSortMergeJoin | True | 데이터프레임 조인시 Sort Merge Join을 기본으로 사용 여부. 항상 Sort Merge Join을 쓴다는 의미는 아님 |
spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold | 0 | Hash Join시 파티션 별로 해시맵 생성에 사용 가능한 최대 크기 지정. 이 값이 spark.sql.adaptive.advisorPartitionSizeInBytes보다 크고, 모든 파티션 크기가 이 값보다 작다면 Has Join을 선택하여 조인 진행. spark.sql.join.preferSortMergeJoin의 값은 무시됨 |
spark.sql.adaptive.autoBroadcastJoinThreshold | 없음 | 브로드캐스트 가능한 데이터프레임의 최대 크기. 이 값을 -1로 설정하면 브로드캐스트는 사용되지 않음. 기본값은 spark.sql.autoBroadcastJoinThreshold와 동일하며 AQE가 활성화된 경우에만 사용됨. |

.