
📖 학습주제
파이썬으로 웹데이터 크롤하고 분석하기 (3)
BeautifulSoup
지난 실습들에서 requests 모듈을 이용해서 HTTP 요청을 보내고, 이 응답을 받아 여러 요소를 보았다. 그러나 res.text를 했을 때, 해당 내용이 아주 긴 텍스트로 와서 분석하기 어려웠던 점이 있었다.
HTML Parser를 사용하면 우리가 원하는 요소만을 가져올 수 있도록 HTML 코드를 분석해준다. 오늘 실습한 BeautifulSoup 라이브러리가 이러한 것이다.
실습
- BeautifulSoup : 하는 요소만을 가져올 수 있도록 HTML 코드를 분석하는 라이브러리
- find : 특정 요소를 하나 탐색(가장 먼저 등장하는 요소)
- find_all : 특정 요소를 모두 탐색
https://www.example.comt 사이트로 실습을 진행한다.
import requests
res = requests.get('https://www.example.com')지난 강의와 마찬가지로 requests를 이용해 해당 사이트에 요청을 보낸다.
받은 응답을 BS4 이용을 위해 BeautifulSoup 객체로 생성한다.
# 첫번째 인자는 response의 body를 텍스트로 전달
# 두번째 인자는 "html"로 분석한다는 것을 명시
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, 'html')이 soup 객체는 HTML 정보를 분석해서 가지고 있다.
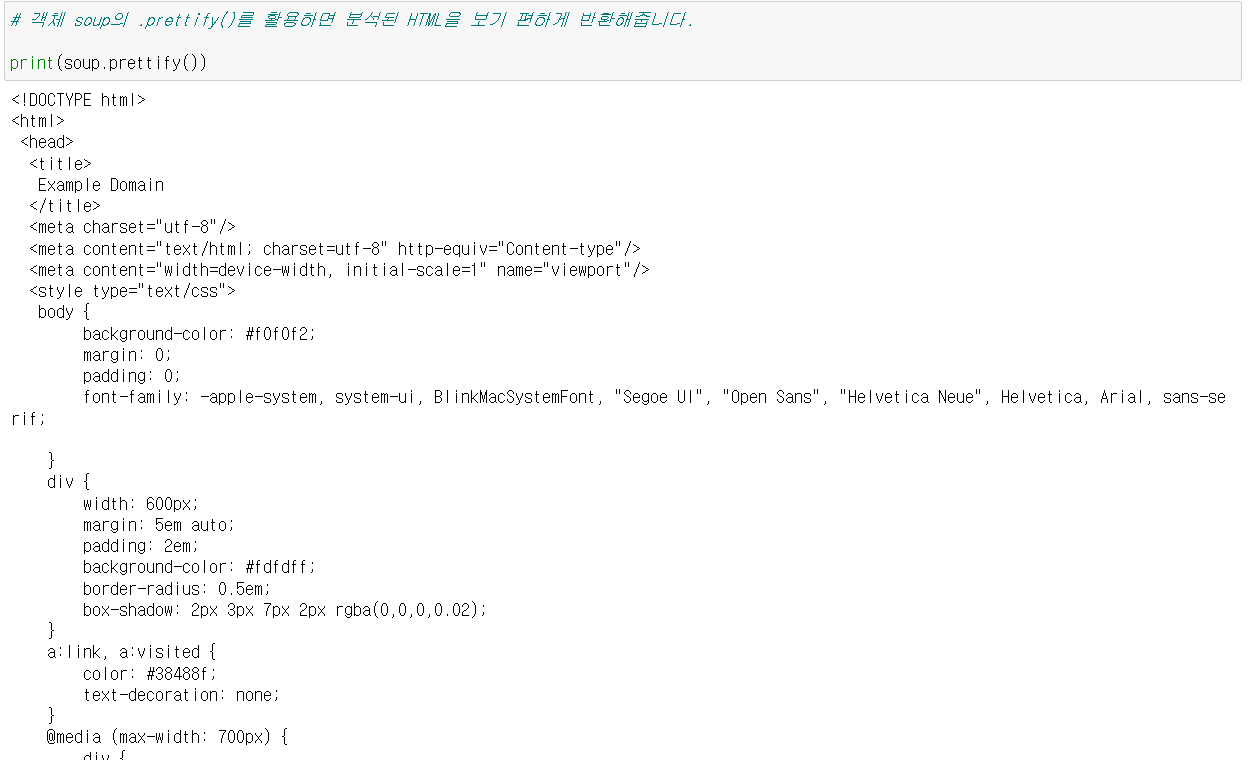
또한 이 soup 객체를 이용해 HTML의 특정 요소를 가지고 올 수 있다.
soup.title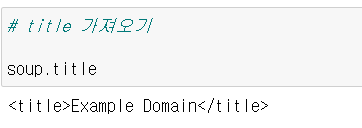
soup.head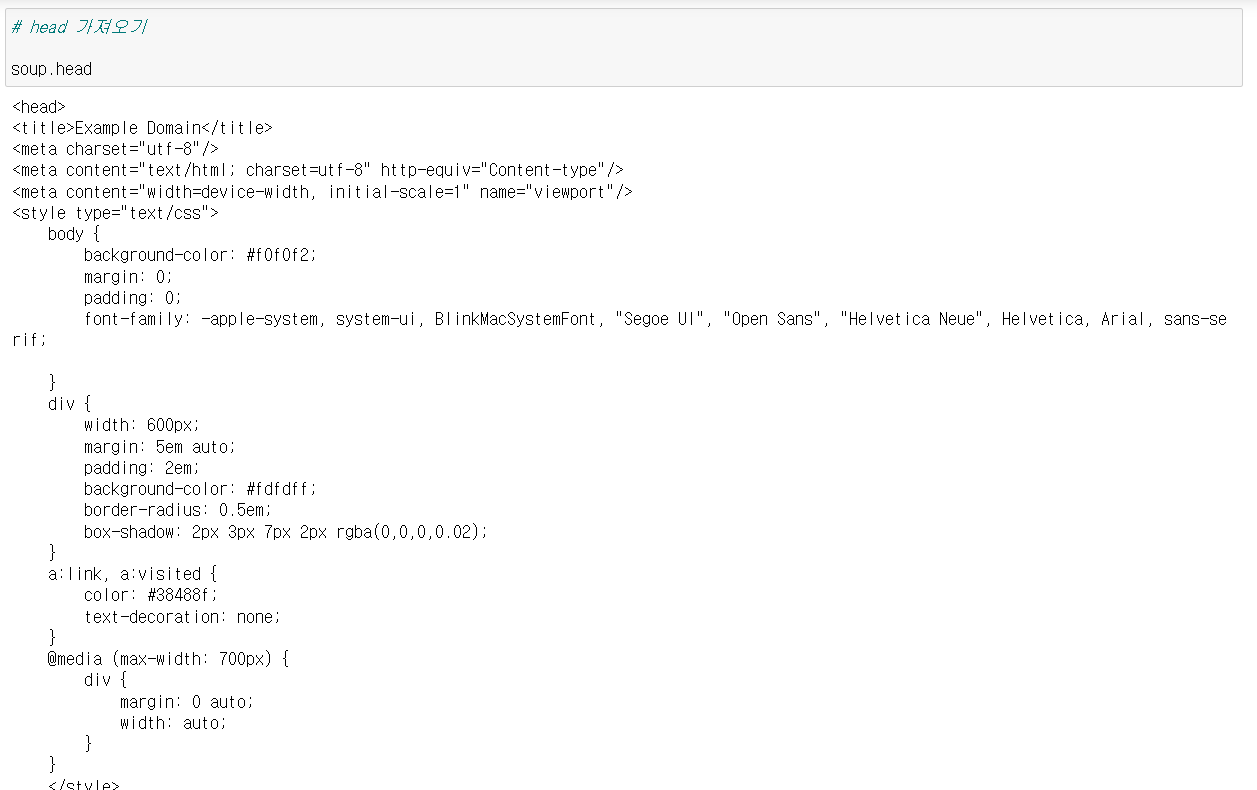
soup.body
위의 사이트에서 <h1>태그로 감싸진 요소를 하나 찾아보자.
h1 = soup.find('h1')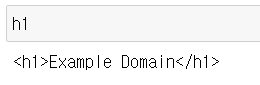
이번에는 find_all을 이용해서 <p>태그로 감싸진 요소들을 모두 찾아보자.
soup.find_all('p')
또한 태그의 이름, 태그의 내용도 알 수 있다.
h1.name
h1.text
이번에는 http://books.toscrape.com/catalogue/category/books/travel_2/index.html 에서 책들의 제목을 가져와보자.
위의 사이트에서 책의 제목은 <h3>태그 아래 <a>의 컨텐츠로 있음을 알 수 있다.
import requests
from bs4 import BeautifulSoup
res = requests.get('http://books.toscrape.com/catalogue/category/books/travel_2/index.html')
soup = BeautifulSoup(res.text, 'html')<h3>태그에 해당하는 요소를 하나 찾아 찾아보자.
book = soup.find('h3')
이 때 이렇게 만들어진 book은 객체이다. 파이썬에서 객체는 메소드를 호출하거나 속성을 참조할 수 있다. 다시 말해 이 경우에 <h3>태그 내의 <a>태그를 속성처럼 이용할 수 있다.
book.a
soup가 객체인 점을 이용해 반복문으로 책의 제목들을 가져올 것이다.
book_list = soup.find_all('h3')
for book in book_list:
print(book.a.text)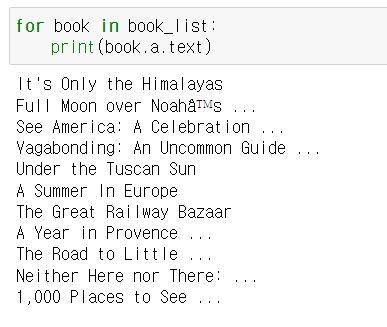
제목들이 잘려서 나온다.

위 사이트에서 일부를 가져온 사진인데 제목이 잘려있음을 확인할 수 있다. 좀 더 자세히 보자.
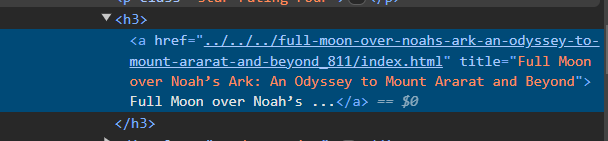
역시나 텍스트가 잘려있다. 그러나 title 속성은 이상이 없음을 확인할 수 있다. 그러므로 다음과 같은 방법을 이용한다.
book_list = soup.find_all('h3')
for book in book_list:
print(book.a['title'])
Locator
복잡한 웹사이트를 다루다 보면 같은 태그가 많은 경우가 많아 태그 이름으로만 데이터를 스크래핑하면 원치 않는 정보도 가져올 수 있다.
태그는 자신의 이름 뿐만 아니라 고유한 속성 또한 가질 수 있는데 이 중에서 id와 class는 Locator로서, 특정태그를 지칭하는 데에 사용힌다.
tagname: 태그의 이름id: 하나의 고유 태그를 가리키는 라벨, 두개이상의 태그가 같은 id를 공유해선 안됨class: 유사한 역할을 하는 여러 태그를 묶는 라벨
예시
<p>This element has only tagname</p>
<p id="target">This element has tagname and id</p>
<p class="targets">This element has tagname and class</p>https://hashcode.co.kr/ 을 이용해 실습해보자. 페이지 내의 질문 제목들을 가져올 것이다.
질문 제목은 question-list-item 라는 클래스를 가지는 <li>태그 아래 question클래스를 가지는 <div>태그, top클래스를 가지는 <div>태그, <h4>태그로 순차적으로 접근할 수 있다.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://hashcode.co.kr/')
soup = BeautifulSoup(res.text, 'html')
questions = soup.find_all('li','question-list-item')
for question in questions:
print(question.find('div', 'question').find('div','top').h4.text)
페이지네이션(Pagination)
많은 정보를 인덱스로 구분하는 기법
위의 사이트는 https://hashcode.co.kr/?page=i 처럼 페이지를 구분하고 있다. 이를 이용해 5페이지까지의 질문 제목을 가져와보자. 과도한 요청을 방지하기 위해 time.sleep()을 이용한다.
import time
for i in range(1, 6):
res = requests.get('https://hashcode.co.kr/?page={}'.format(i))
soup = BeautifulSoup(res.text, 'html')
questions = soup.find_all('li','question-list-item')
for question in questions:
print(question.find('div', 'question').find('div','top').h4.text)
time.sleep(0.5)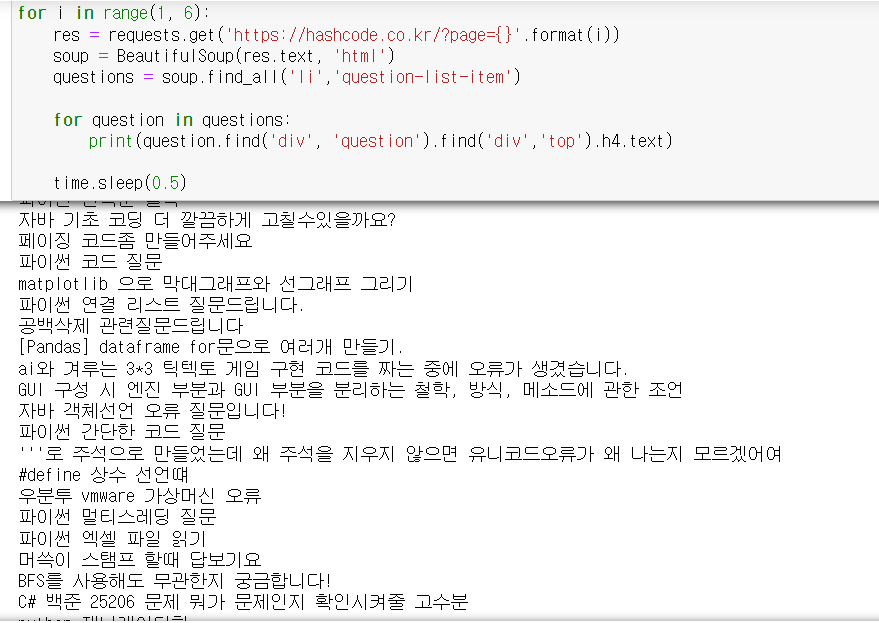
동적(dynamic) 웹페이지
웹페이지는 크게 정적 웹페이지와 동적 웹페이지 두가지로 구분된다.
정적(static) 웹페이지
- HTML 내용이 고정
- HTML 문서가 완전하게 응답
동적(dynamic) 웹페이지
- HTML 내용이 변함
- 응답 후 HTML이 렌더링 될 때까지 지연시간이 존재
동적 웹페이지의 작동방식
웹 브라우저에서는 Java Script가 동작하는데 이는 비동기 처리를 통해 필요한 데이터를 채운다.
동기 처리 : 요청에 따른 응답을 기다림
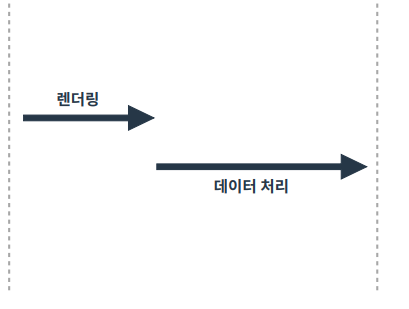 (렌더링 이후에 데이터를 처리)
(렌더링 이후에 데이터를 처리)
비동기 처리 : 요청에 따른 응답을 기다리지 않음
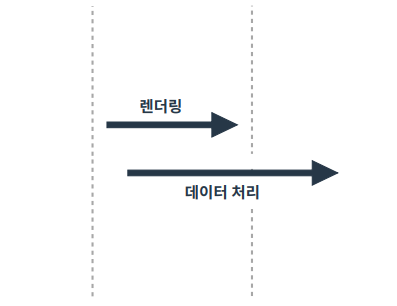 (렌더링 도중에 데이터를 처리할 수도 있음)
(렌더링 도중에 데이터를 처리할 수도 있음)
동기 처리가 된 경우 HTML 로딩에 문제가 없다. 그러나 비동기 처리에 경우 렌더링 이후에 응답한 후 데이터를 처리하는 경우도 있음. 상황에 따라 데이터가 완전하지 않은 경우도 발생함
지금까지의 스크래핑의 경우 두 가지 문제점을 가진다.
- 불완전한 응답을 받을 수 있음
- 키보드 입력, 마우스 클릭 등은 requests로 진행하기 어려움
이를 해결하기 위해서는
- 임의로 시간을 지연시켜 데이터 처리가 끝난 후 정보를 가져온다.
- 키보드 입력, 마우스 클릭 등을 프로그래밍으로 해결
-> 웹 브라우저를 파이썬으로 조작하자!
웹 브라우저를 자동화 하는 라이브러리 Selenium 이용
