🖇 1. 데이터 준비하기
🖇 2. 딥러닝 모델 구성하기
🖇 3. 모델 컴파일과 학습
🖇 4. 테스트 데이터로 평가
🖇 5. 모델 개선
이번 실습은 가장 대표적인 이미지 분류 데이터셋인 MNIST를 활용하여 딥러닝 모델의 핵심 개념과 작동 원리를 실습을 통해 학습하는 것을 목표로 수행하였다.
합성곱 신경망(CNN) 구조를 중심으로 이미지에서 특징을 추출하고 이를 분류하는 전체 흐름을 학습하면서 다음의 내용을 이해할 수 있었다.
- 딥러닝 모델의 구성 단계 (Conv → Pooling → Flatten → Dense)
- 학습 과정에서의 손실 함수, 옵티마이저, 평가 지표의 역할
- 학습/검증 결과를 시각화하고 예측 결과를 분석하는 방법
특히 이번 글에서는 실습을 통해 딥러닝의 기초 이론을 직관적으로 이해할 수 있도록 충분한 설명과 함께 진행해 보았다.
🖇 1. 데이터 준비하기
MNIST란?
MNIST(Mixed National Institute of Standards and Technology)는 손글씨 숫자(0~9)로 구성된 이미지 데이터셋이다. 딥러닝 실습에서 가장 많이 활용되는 대표적인 이미지 분류 데이터셋으로, 딥러닝의 신경망 학습 과정을 이해하는 데 유용하게 사용된다.
- 총 70,000개의 28x28 픽셀 grayscale 이미지
- 학습용 데이터: 60,000개
- 테스트용 데이터: 10,000개
TensorFlow/Keras
- TensorFlow: 구글에서 개발한 딥러닝 프레임워크로, 복잡한 연산을 효율적으로 수행하며 GPU를 활용한 고속 연산이 가능하다.
- Keras: TensorFlow 위에서 동작하는 고수준 API로, 간단하고 직관적으로 딥러닝 모델을 설계하고 학습할 수 있게 해준다.
1.1 데이터 불러오기
x_train: 학습 이미지 (28x28 크기의 numpy 배열)y_train: 각 이미지에 대한 실제 숫자 라벨 (0~9)
from tensorflow import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()1.2 데이터 구조 및 확인
MNIST 데이터셋의 X 항목은 이미지 데이터를 담은 행렬(matrix) 형태이다. 각 픽셀은 0~255 사이의 정수 값으로 구성된다.
print(x_train.shape) # (60000, 28, 28)
print(x_test.shape) # (10000, 28, 28)
print('최소값:', np.min(x_train), ', 최대값:', np.max(x_train)) # 최소값: 0, 최대값: 255- 특정 이미지 시각화
# cmap=plt.cm.binary: 이미지를 흑백으로 표현하는 설정
import matplotlib.pyplot as plt
plt.imshow(x_train[1], cmap=plt.cm.binary)
plt.show()
print(y_train[1]) # 0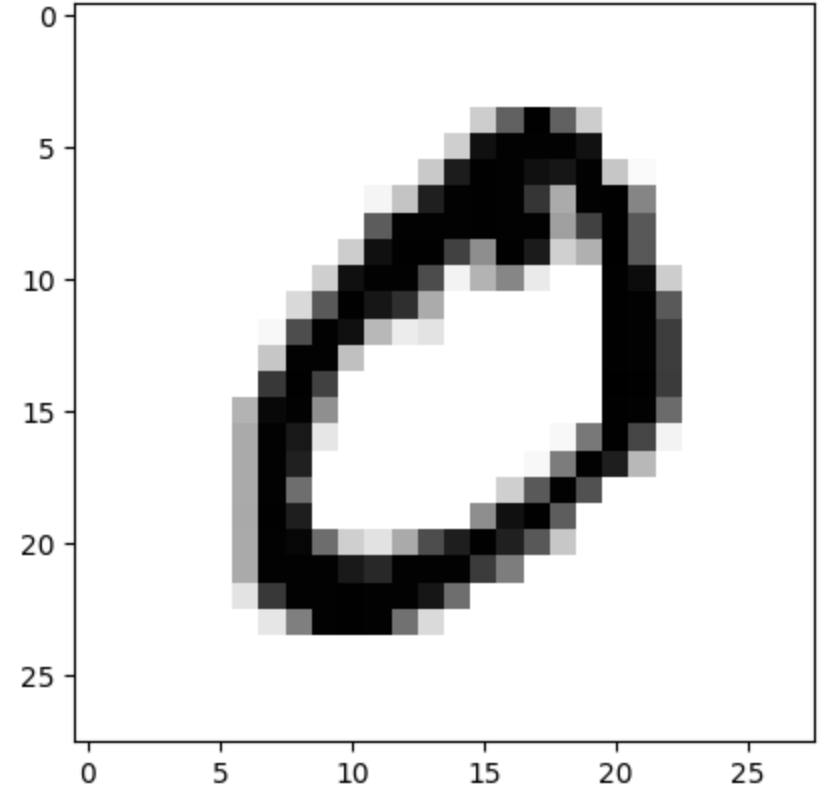
1.3 이미지 데이터를 벡터로 평탄화하기
평탄화(Flatten)란?
신경망 모델 중에서 MLP(다층 퍼셉트론, Dense 네트워크)는 1차원 입력을 요구하기 때문에 2차원 이미지 데이터를 1차원 벡터로 변환하는 과정이 필요하다. 예를 들어, 28x28 이미지는 784(=28×28)개의 픽셀을 가진 벡터로 변환된다.
시각적 확인 목적
- 평탄화 이해: Dense 신경망의 입력으로 1D 벡터가 필요하다
- 시각적 확인: 평탄화 후에도 데이터를 해석할 수 있다
- 전처리 기반 이해: 이후 Flatten() 레이어와 연결됨
flat = x_train[1].flatten() # 2D (28, 28) → 1D (784,)
for i in range(0, len(flat), 28):
print(' '.join(f'{val:3}' for val in flat[i:i+28])) 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 51 159 253 159 50 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 48 238 252 252 252 237 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 54 227 253 252 239 233 252 57 6 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 10 60 224 252 253 252 202 84 252 253 122 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 163 252 252 252 253 252 252 96 189 253 167 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 51 238 253 253 190 114 253 228 47 79 255 168 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 48 238 252 252 179 12 75 121 21 0 0 253 243 50 0 0 0 0 0
0 0 0 0 0 0 0 0 38 165 253 233 208 84 0 0 0 0 0 0 253 252 165 0 0 0 0 0
0 0 0 0 0 0 0 7 178 252 240 71 19 28 0 0 0 0 0 0 253 252 195 0 0 0 0 0
0 0 0 0 0 0 0 57 252 252 63 0 0 0 0 0 0 0 0 0 253 252 195 0 0 0 0 0
0 0 0 0 0 0 0 198 253 190 0 0 0 0 0 0 0 0 0 0 255 253 196 0 0 0 0 0
0 0 0 0 0 0 76 246 252 112 0 0 0 0 0 0 0 0 0 0 253 252 148 0 0 0 0 0
0 0 0 0 0 0 85 252 230 25 0 0 0 0 0 0 0 0 7 135 253 186 12 0 0 0 0 0
0 0 0 0 0 0 85 252 223 0 0 0 0 0 0 0 0 7 131 252 225 71 0 0 0 0 0 0
0 0 0 0 0 0 85 252 145 0 0 0 0 0 0 0 48 165 252 173 0 0 0 0 0 0 0 0
0 0 0 0 0 0 86 253 225 0 0 0 0 0 0 114 238 253 162 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 85 252 249 146 48 29 85 178 225 253 223 167 56 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 85 252 252 252 229 215 252 252 252 196 130 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 28 199 252 252 253 252 252 233 145 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 25 128 252 253 252 141 37 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0CNN에서는 평탄화 전의 28x28 형태 그대로 사용하지만, 전통적인 MLP에서는 이와 같이 1D 형태로 변환이 필수적이다.
1.4 정규화 (Normalization)
정규화란?
입력 데이터를 0~1 사이의 실수로 바꾸는 작업이다. 모델 학습의 안정성과 속도를 향상시키며 특히 ReLU나 sigmoid 같은 활성화 함수의 출력 범위와도 관련이 있다. 일반적으로 입력값의 범위가 너무 클 경우 학습이 느려지고, 가중치 업데이트가 불안정해질 수 있다.
x_train_norm = x_train / 255.0
x_test_norm = x_test / 255.0
print('최소값:', np.min(x_train_norm), ' 최대값:', np.max(x_train_norm))🖇 2. 딥러닝 모델 구성하기
Sequential 모델이란?
Sequential 모델은 Keras에서 가장 간단한 모델 구조로, 층을 위에서 아래로 순차적으로 쌓는다. 복잡한 병렬 구조나 skip connection은 불가능하지만, 기본적인 MLP나 CNN 모델에는 적합하다.
2.1 CNN(합성곱 신경망)이란?
CNN은 이미지나 시계열 데이터처럼 공간 정보가 중요한 데이터에 적합한 딥러닝 구조다. 아래와 같은 층으로 구성된다.
1) Conv2D
- 필터(커널)를 통해 입력 이미지에서 국소적인 특징(모서리, 점, 선 등)을 추출
- 필터 수가 많을수록 다양한 패턴을 포착할 수 있음
activation='relu'는 비선형성을 부여하고, 학습에 유리한 형태로 정보를 가공함
2) MaxPooling2D
- Conv2D를 통해 추출된 특성맵의 크기를 줄이고 연산 효율을 높임
- 과적합을 방지하고 위치 불변성을 제공함
3) Flatten
- CNN의 출력인 다차원 배열을 Dense 층에 연결하기 위해 1차원 벡터로 변환
4) Dense
- 완전 연결층으로 뉴런 간 모든 연결을 통해 정보를 통합하고 추론을 수행
- ReLU 활성화 함수는 양수는 그대로, 음수는 0으로 만들어 학습을 빠르게 만듦
5) Softmax
- 마지막 출력층에서 각 클래스(0~9)의 확률 분포를 출력
- 예측된 값 중 확률이 가장 높은 클래스를 최종 출력으로 선택
# Sequential 모델 생성: 층을 순차적으로 추가할 수 있는 기본 구조
model=keras.models.Sequential()
# 입력 이미지(28x28, 채널 1)를 받아 3x3 필터 16개로 합성곱 연산 수행
# 활성화 함수로 ReLU 사용 → 비선형성 부여
# 특징 추출 시작 (Edge, 선, 점 등 로우레벨 특징)
model.add(keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(28,28,1)))
# 2x2 크기의 필터로 MaxPooling → 공간적 크기를 절반으로 줄임
# 연산량 감소 + 과적합 방지 효과
model.add(keras.layers.MaxPool2D(2,2))
# 두 번째 합성곱 층: 더 많은 필터(32개)로 더 복잡한 패턴 추출
model.add(keras.layers.Conv2D(32, (3,3), activation='relu'))
# 다시 2x2로 MaxPooling → 특성맵 크기 감소, 추상화 강화
model.add(keras.layers.MaxPooling2D((2,2)))
# 다차원(2D) 특성맵을 1차원 벡터로 변환 → Fully Connected Layer로 전달
model.add(keras.layers.Flatten())
# 은닉층(Dense): 노드 32개, ReLU 사용 → Flatten한 특징 벡터를 추상화
model.add(keras.layers.Dense(32, activation='relu'))
# 출력층: 10개 노드 (0~9 숫자 클래스), Softmax로 각 클래스 확률 출력
model.add(keras.layers.Dense(10, activation='softmax'))
# 총 Layer 개수 출력
# - 총 7개: Conv2D, MaxPool, Conv2D, MaxPool, Flatten, Dense, Dense)
print('Model에 추가된 Layer 개수: ', len(model.layers))2.2 모델 구조 요약 확인
summary()를 통해 Layer 이름, 출력 텐서의 모양, 학습 가능한 파라미터 수를 확인할 수 있다.
- Layer(type)
- 레이어 이름과 종류 (Conv2D, Dense 등)
- Output Shape
- 해당 레이어의 출력 텐서 형태 (배치 차원 None은 입력에 따라 결정됨)
- Param #
- 해당 레이어의 학습 가능한 파라미터 개수 (weights + biases)
model.summary()Model: "sequential_5"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ conv2d_10 (Conv2D) │ (None, 26, 26, 16) │ 160 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_10 (MaxPooling2D) │ (None, 13, 13, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_11 (Conv2D) │ (None, 11, 11, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_11 (MaxPooling2D) │ (None, 5, 5, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_5 (Flatten) │ (None, 800) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_10 (Dense) │ (None, 32) │ 25,632 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_11 (Dense) │ (None, 10) │ 330 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 30,762 (120.16 KB)
Trainable params: 30,762 (120.16 KB)
Non-trainable params: 0 (0.00 B)이 모델은 28x28 이미지에서 두 번의 합성곱-풀링을 거친 뒤, 완전연결층(Dense)을 통해 10개의 숫자 클래스로 분류한다. 전체 3만여 개의 파라미터를 학습하며, 간단한 구조로 MNIST 분류에 적합하다.
| 층 | 층 이름 | 출력 형태 | 파라미터 수 | 설명 |
|---|---|---|---|---|
| 1 | Conv2D | (26, 26, 16) | 160개 | 3x3 크기 필터 16개가 이미지 특징을 추출한다. 이미지가 약간 작아진 이유는 경계처리(padding)를 안 했기 때문이다. |
| 2 | MaxPooling2D | (13, 13, 16) | 0개 | 특징을 반으로 줄여 계산량을 줄이고 중요한 정보만 남긴다. |
| 3 | Conv2D | (11, 11, 32) | 4,640개 | 이번엔 32개의 필터로 더 많은 특징을 뽑아낸다. |
| 4 | MaxPooling2D | (5, 5, 32) | 0개 | 또 한 번 줄여서 더 간단하게 만든다. |
| 5 | Flatten | (800,) | 0개 | 5×5×32개의 숫자를 한 줄로 펼친다. 즉, 800차원 벡터가 된다. |
| 6 | Dense | (32,) | 25,632개 | 800개 숫자를 받아서 32개의 숫자로 압축한다. |
| 7 | Dense | (10,) | 330개 | 마지막으로 0~9 중 어떤 숫자인지 확률로 나타낸다. softmax 함수가 쓰인다. |
2.3 모델 입력 형식 맞추기
"CNN은 4차원 입력을 요구한다"
Conv2D 층은 (배치 수, 높이, 너비, 채널 수) 형식의 입력을 받는다. MNIST는 흑백 이미지이므로 채널 수는 1이다.
- 3차원 배열 (60000, 28, 28) → 4차원 (60000, 28, 28, 1)
# CNN 모델 입력을 위한 4차원 텐서로 변환
# -1: 샘플 수를 자동으로 계산, 28x28: 이미지 크기, 1: 채널 수(흑백 이미지)
x_train_reshaped = x_train_norm.reshape(-1, 28, 28, 1)
x_test_reshaped = x_test_norm.reshape(-1, 28, 28, 1)🖇 3. 모델 컴파일과 학습
3.1 컴파일 단계 설명
# 모델 컴파일 (학습을 위한 설정)
model.compile(
optimizer='adam', # Adam: 학습률을 자동으로 조정해주는 최적화 알고리즘
loss='sparse_categorical_crossentropy', # 다중 클래스 분류에서 정수 레이블을 사용할 때 적합한 손실 함수
metrics=['accuracy'] # 모델 평가 지표로 정확도(accuracy) 사용
)3.2 학습 실행
# 모델 학습 수행
# - x_train_reshaped: (60000, 28, 28, 1) → CNN 입력 형식에 맞춘 학습 데이터
# - y_train: 정답 레이블 (0~9 정수)
# - epochs=10: 전체 데이터를 10번 반복하여 학습
model.fit(x_train_reshaped, y_train, epochs=10)Epoch 1/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 41s 21ms/step - accuracy: 0.8734 - loss: 0.4233
...
Epoch 10/10
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 32s 17ms/step - accuracy: 0.9959 - loss: 0.0120
<keras.src.callbacks.history.History at 0x7cddb589af10>학습이 반복될수록 손실은 줄어들고 정확도는 상승하는 경향을 보인다. 보통 몇 epoch 내에 99%에 가까운 정확도에 도달한다.
- 학습 정확도가 높다고 해서 테스트셋에서도 성능이 보장되는 건 아님. 과적합 여부를 확인하려면 model.evaluate() 결과도 함께 봐야 함
- History 객체(<keras.src.callbacks.history.History at 0x...>)는 학습 이력을 담고 있어, 나중에 history.history로 시각화도 가능
🖇 4. 테스트 데이터로 평가
모델이 학습 데이터에만 성능이 좋은 것이 아닌지 확인하기 위해 학습에 사용하지 않은 테스트셋을 이용하여 일반화 성능을 평가한다.
4.1 손실(loss)과 정확도(accuracy) 확인
# 테스트 데이터셋을 이용해 모델 성능 평가
# - x_test_reshaped: CNN 입력 형식에 맞게 reshape된 테스트 이미지 (10000, 28, 28, 1)
# - y_test: 실제 정답 라벨 (0~9)
# - verbose=2: 평가 과정에서 한 줄 요약 출력
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
# 테스트 결과 출력
print(f'test_loss: {test_loss}') # 손실값 (작을수록 좋음)
print(f'test_accuracy: {test_accuracy}') # 정확도 (클수록 좋음)313/313 - 2s - 6ms/step - accuracy: 0.9857 - loss: 0.0435
test_loss: 0.04353205859661102
test_accuracy: 0.9857000112533569테스트 데이터는 실제로 손글씨 작성자가 학습 데이터와 다르므로 약간의 성능 저하는 자연스럽다. 이로 인해 모델이 새로운 필체에 얼마나 잘 대응하는지를 확인할 수 있다.
4.2 예측 결과 확인 및 시각화
모델이 테스트 이미지에 대해 어떤 예측을 하는지 살펴본다.
- 모델이 출력한 확률 분포, 가장 가능성이 높은 예측 클래스, 실제 정답 비교
# 테스트 이미지에 대해 예측 수행
# : 각 이미지에 대해 0~9 클래스별 확률(예측 결과) 반환
# : (10000, 10) 형태의 배열이 출력
# → 각 행은 10개의 숫자(0~9)에 대한 확률값
predicted_result = model.predict(x_test_reshaped)
# 확률 배열(예측 결과) 중 가장 높은 확률값을 가진 클래스 인덱스 반환
predicted_labels = np.argmax(predicted_result, axis=1) # axis=1 → 각 행(이미지)에 대해 최대값(가장 확률이 높은)의 인덱스 선택- 특정 인덱스의 결과 확인 및 이미지 출력
# 예측 결과를 직접 확인하기 위한 인덱스 설정
idx = 0
# 모델이 출력한 0~9 숫자에 대한 확률값 배열 출력 → 벡터 형태
print('model.predict() 결과: ', predicted_result[idx])
# 모델이 가장 가능성 높게 예측한 클래스 번호 출력
print('model이 추론한 가장 가능성이 높은 결과: ', predicted_labels[idx])
# 실제 정답 레이블 출력
print('실제 데이터의 라벨: ', y_test[idx])model.predict() 결과 : [3.19225819e-07 1.06489765e-07 1.21569219e-05 5.04783338e-06
1.20160564e-07 1.96726347e-07 6.35414013e-11 9.99981701e-01
4.14569357e-08 2.43128085e-07]
model이 추론한 가장 가능성이 높은 결과 : 7
실제 데이터의 라벨 : 74.3 예측 오류 분석
모델이 틀린 예측을 분석함으로써 성능 향상을 위한 힌트를 얻을 수 있다.
- 모델이 어떤 데이터에서 실수하는지, 왜 잘못 판단했는지 확인
- 직접 이미지와 예측 결과를 비교함으로써 모델이 오해한 패턴 추적
import random
wrong_predict_list = [] # 모델이 틀린 예측의 인덱스를 저장할 리스트
# 모든 테스트 데이터에서 예측값과 실제값을 비교
for i, _ in enumerate(predicted_labels):
if predicted_labels[i] != y_test[i]: # 예측값이 정답과 다르면
wrong_predict_list.append(i) # 인덱스를 리스트에 저장
# 잘못 예측한 샘플 중 5개를 랜덤으로 뽑기
samples = random.choices(population=wrong_predict_list, k=5)
# 선택된 각 샘플에 대해 결과 확인 및 이미지 출력
for n in samples:
print('예측 확률 분포: ' + str(predicted_result[n])) # 0~9까지 각 숫자일 확률
print('정답 라벨: ' + str(y_test[n]) + ', 예측 결과: ' + str(predicted_labels[n]))
plt.imshow(x_test[n], cmap=plt.cm.binary) # 실제 이미지 출력
plt.show()예측확률분포: [2.9701886e-07 1.6675827e-03 5.6501359e-01 4.6994388e-03 3.0292587e-05
1.0023670e-06 3.9660527e-08 4.2849964e-01 8.8016124e-05 1.4242288e-07]
라벨: 7, 예측결과: 2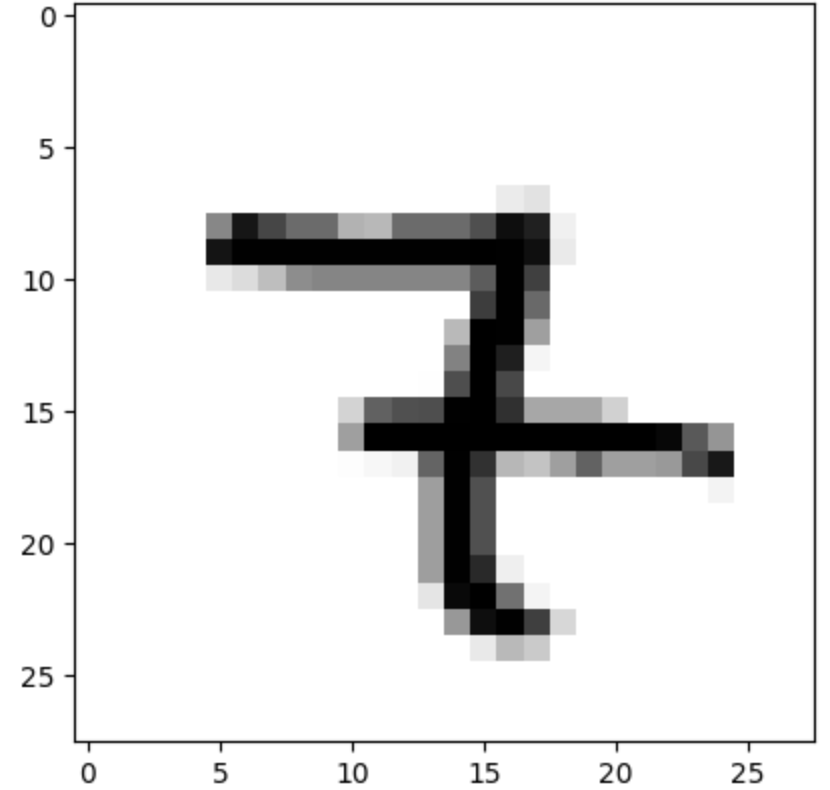
이렇게 잘못 예측한 숫자들의 이미지와 확률 분포를 시각화하면 모델이 어떤 패턴에서 혼동하는지 파악할 수 있다.
🖇 5. 모델 개선
모델 개선을 위한 하이퍼파라미터 조정까지를 포함하여 지금까지 살펴본 모델 학습의 전 과정을 정리해 보았다.
5.1 하이퍼파라미터 조정
# 하이퍼파라미터 설정: 모델 구조와 학습 횟수를 조절
n_channel_1=16 # 첫 번째 Conv2D 층의 필터 수 (이미지 특징 추출용)
n_channel_2=32 # 두 번째 Conv2D 층의 필터 수 (더 복잡한 특징 추출)
n_dense=32 # 완전 연결(Dense) 층의 뉴런 수 (최종 분류를 위한 중간층)
n_train_epoch=10 # 전체 데이터를 학습에 사용할 횟수 (epoch 수)
# 모델 정의: 순차적으로 층을 쌓는 방식(Sequential)
model=keras.models.Sequential()
# 첫 번째 합성곱 층: 3x3 필터, ReLU 활성화 함수 사용, 입력 이미지 크기는 28x28x1 (MNIST 같은 흑백 이미지)
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,1)))
# 최대 풀링 층: 2x2 영역에서 가장 큰 값을 선택해 특성 맵 축소 (연산량 줄이기, 중요 정보 유지)
model.add(keras.layers.MaxPool2D(2,2))
# 두 번째 합성곱 층: 더 많은 필터로 복잡한 패턴 학습
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
# 또 한 번의 최대 풀링
model.add(keras.layers.MaxPooling2D((2,2)))
# 특성 맵을 1차원으로 펼쳐서(Dense 층에 입력 가능하도록 변환)
model.add(keras.layers.Flatten())
# 완전 연결층(Dense): 중간 단계에서 중요한 특징 조합
model.add(keras.layers.Dense(n_dense, activation='relu'))
# 출력층: 클래스 수(10개)만큼 뉴런을 만들고, softmax 함수로 확률 분포 출력
model.add(keras.layers.Dense(10, activation='softmax'))
# 모델 구조 출력: 각 층의 이름과 출력 형태, 파라미터 수 등을 보여줌
model.summary()
# 모델 컴파일: 학습에 사용할 최적화 방법(Adam), 손실 함수, 평가 지표 설정
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', # 정수 레이블에 적합한 분류 손실 함수
metrics=['accuracy'])
# 모델 학습 시작: 학습 데이터를 n_train_epoch만큼 반복해서 모델에 학습시킴
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 테스트 데이터로 모델 평가: 손실값과 정확도 측정
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print(f'test_loss: {test_loss} ')
print(f'test_accuracy: {test_accuracy}')이러한 하이퍼파라미터는 실험적으로 조정하여 모델 성능을 개선할 수 있으며, 더 많은 필터나 뉴런, 학습 횟수를 통해 정확도를 높일 수 있다.
5.2 딥러닝 모델 학습 흐름 요약
1. 하이퍼파라미터 설정
2. 모델 정의
- Sequential() 방식
3. 특징 추출 단계
- Conv2D: 이미지를 보고 특징을 뽑는 눈 역할
- 이미지에서 국소적인 특징(모서리, 곡선 등)을 추출하는 필터 사용
- activation='relu': 음수를 제거하고, 비선형성을 부여해 신경망 학습에 도움
- 첫 번째 층은 반드시 input_shape를 명시
- MaxPooling2D: 특징을 압축해서 중요한 것만 남김
- 필터로 얻은 특성맵의 크기를 줄임으로써 연산량 감소 및 과적합 방지
- 중요한 정보는 유지하되, 덜 중요한 정보는 버림
4. 분류기 구성
- Flatten: 이미지 구조를 펼쳐서 Dense 층에 전달
- CNN 계층에서 출력된 3차원 텐서를 1차원 벡터로 펼침
- Fully Connected Layer(Dense)와 연결하기 위한 전처리 과정
- Dense + ReLU
- 뉴런 간 모든 연결을 가진 층
- n_dense=32는 뉴런 수를 의미하며, 일반적으로 특징을 조합해 추상적인 표현을 학습하는 역할
- Dense + Softmax
- 출력층. 10개의 클래스(숫자 0~9)에 대한 확률값을 출력
- softmax: 각 클래스의 확률 분포를 보장하여 가장 확률이 높은 클래스를 선택하게 함
5. 모델 요약 정보 출력
6. 모델 컴파일
- optimizer='adam'
- 확률적 경사 하강법(SGD)의 진화형. 빠른 수렴과 안정된 학습 제공
- loss='sparse_categorical_crossentropy':
= 라벨이 one-hot encoding이 아니라 정수(0~9)로 되어 있을 때 적합한 다중 클래스 분류 손실 함수
- metrics=['accuracy']:
- 학습과 테스트에서 정확도(Accuracy)를 추적
7. 모델 학습
- fit(): 모델 학습
- epochs=10: 전체 데이터를 10번 반복 학습
- x_train_reshaped: CNN 입력 형식에 맞게 (28, 28, 1)로 reshape된 데이터
8. 모델 평가
- evaluate(): 학습된 모델의 성능을 테스트 데이터셋에서 평가
- test_loss: 테스트 데이터에서의 평균 손실
- test_accuracy: 테스트 데이터에서 맞춘 비율인사이트 및 회고
지금까지 CNN 기반 딥러닝 모델이 이미지 데이터의 패턴을 어떻게 학습하고 분류하는지 구체적으로 이해할 수 있었다.
- Conv2D 레이어를 통해 이미지의 공간적 특징(선, 곡선 등)을 자동으로 추출하고
- MaxPooling 레이어를 통해 주요 특징만 추려내어 연산 효율성과 일반화 성능을 높이며
- Flatten 및 Dense 레이어를 통해 최종 분류 결과로 연결되는 과정을 체계적으로 학습할 수 있었다.
적절한 Conv 층 구성과 Pooling을 통해 모델의 복잡도를 조절하고, 훈련 손실과 검증 손실의 추이를 비교함으로써 과적합 여부를 직관적으로 확인할 수 있었다. Adam Optimizer를 사용함으로써 학습 속도와 안정성을 개선하는 전략도 실습해 볼 수 있었다.
머신러닝과 마찬가지로 모델 구조의 작은 변화가 정확도에 큰 영향을 미칠 수 있다. Conv 층을 추가하거나 필터 수를 조정하는 것만으로도 모델의 표현력과 성능이 달라지는 것을 확인할 수 있었다.
MNIST 숫자 분류 모델을 구현하면서 CNN의 구성과 딥러닝 모델 설계를 이해하였다.
