🖇 로그 변환이란?
🖇 Python에서 로그 변환 방법
🖇 로그 변환 시 주의할 점
데이터를 분석하거나 모델링하기 전에, 꼭 한 번쯤 고민하게 되는 부분이 있다.
“이 데이터의 분포, 이대로 괜찮을까?”
실제 데이터는 대체로 정규분포가 아니고, 한쪽으로 치우쳐 있거나 이상치에 민감한 구조를 가지고 있다. 이때 우리가 취할 수 있는 전처리 기법 중 하나가 로그 변환(Log Transformation)이다.
이 글에서는 로그 변환의 개념부터 적용 이유, 사용법, 그리고 주의할 점까지 직접 예제를 통해 살펴보려고 한다.
🖇 로그 변환이란?
우선 유튜브 영상으로 로그의 개념(Khan Academy)과 지수와 로그의 관계(Khan Academy)를 짚고 넘어가자 :)
로그 변환(Log Transformation)은 데이터의 분포를 바꾸기 위한 전처리 기법 중 하나이다.
특히 즉 한쪽으로 치우친 분포를 가지는 데이터의 정규성을 높이고, 스케일을 축소해주는 데에 많이 사용된다.
그렇다면 왜 로그 변환이 필요한 걸까? 단순히 스케일을 줄이기 위해서만은 아니다.
💡 정규성을 높이는 이유?
선형 회귀(Linear Regression)와 같은 모델은 종속 변수와 독립 변수 사이에 선형 관계가 존재할수록 좋은 성능을 보인다. 하지만 실제 데이터는 종종 곡선형, 지수형, 또는 극단적으로 한쪽으로 치우쳐 있는 분포를 가지고 있다.
이럴 때 로그 변환을 통해 선형 관계에 더 가깝도록 바꿔줄 수 있다.
🖇 Python에서 로그 변환 방법
개념을 이해했다면, 이제 파이썬에서 어떻게 로그를 적용하는지 알아보자.
파이썬에서는 numpy 라이브러리를 활용해 간단하게 로그를 취할 수 있다.
import numpy as np
x = np.array([1, 10, 100, 1000])
np.log(x) # 자연 로그 (밑 e)
np.log10(x) # 밑 10 로그
| 입력값 | np.log() | np.log10() |
|---|---|---|
| 1 | 0.0 | 0.0 |
| 10 | ≈ 2.302 | 1.0 |
| 100 | ≈ 4.605 | 2.0 |
위의 표처럼 np.log()는 자연 로그(밑 e), np.log10()은 10을 밑으로 하는 로그를 계산해 준다.
데이터 전처리에서는 일반적으로 np.log() 또는 np.log1p()를 더 많이 사용하게 된다.
📌 [참고] np.log1p()란?
np.log1p(x)는 np.log(x + 1)과 동일한 기능을 하되, 0 또는 아주 작은 값의 로그를 계산할 때 발생할 수 있는 부동소수점 오차를 줄여주는 함수이다.
즉, np.log(x + 1)과 거의 같지만 수치적으로 더 안정적이다.
특히 x가 0에 가까울수록 더 정확한 값을 반환하기 때문에 머신러닝 전처리에서는 np.log1p()를 안정적인 대안으로 자주 사용힌다.
이제 직접 데이터를 만들어 비교해 보면서 로그 변환이 왜 필요한지 이해해 보자.
import matplotlib.pyplot as plt
import seaborn as sns
# 왜도가 큰 데이터(한 쪽으로 치우친 데이터) 생성
data = np.random.exponential(scale=2, size=1000)
# 로그 변환
log_data = np.log(data + 1) # 로그 취할 때 0이 있는 경우를 피하기 위해 +1 처리
# 시각화
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
sns.histplot(data, bins=40, ax=ax[0], kde=True)
ax[0].set_title("Before Log Transformation")
sns.histplot(log_data, bins=40, ax=ax[1], kde=True)
ax[1].set_title("After Log Transformation")
plt.tight_layout()
plt.show()
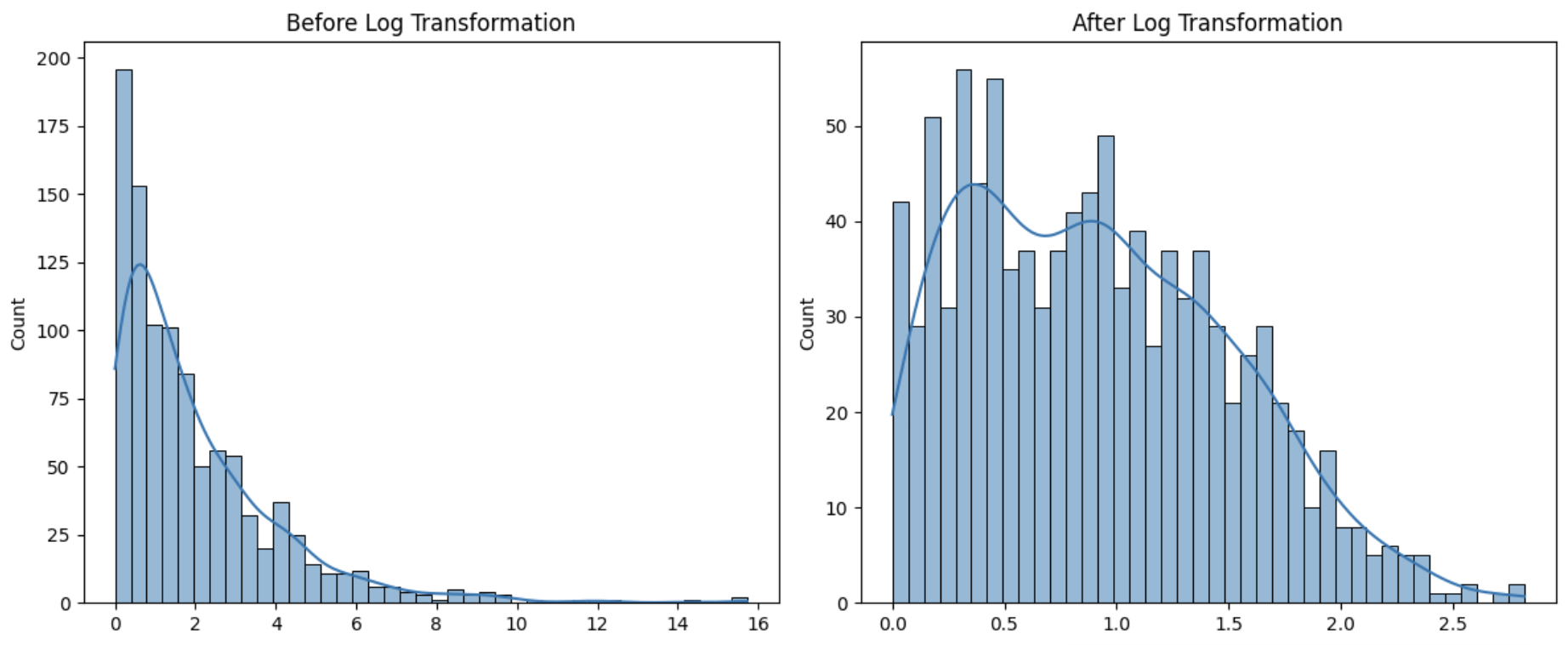 이 시각화 결과를 통해 로그 변환이 실제 데이터 분포에 어떤 영향을 주는지 확인할 수 있다.
이 시각화 결과를 통해 로그 변환이 실제 데이터 분포에 어떤 영향을 주는지 확인할 수 있다.
로그 변환 전에는 왼쪽으로 치우친 분포였지만,
변환 후에는 정규 분포에 더 가까운 형태로 바뀐 것을 확인할 수 있다.
만약, 모델 학습 이후 예측값이 로그 스케일로 출력된다면 다시 원래 스케일로 되돌릴 필요가 있다.
이처럼 로그를 되돌리고 싶다면 아래의 함수를 사용하면 된다.
original_value = np.exp(log_value) # np.log()의 역함수
🖇 로그 변환 시 주의할 점
물론 로그 변환에도 주의해야 할 점이 있다.
✓ 로그는 0 이하의 값을 입력받을 수 없다.
- 로그를 취할 때 0 값 때문에 오류가 나는 것을 방지하기 위해 종종
np.log(x + 1)처럼 1을 더해주는데,
이때 더 안전한 방법으로는np.log1p(x)를 사용하는 것도 좋다.
✓ 로그 변환은 스케일을 축소하는 성질이 있기 때문에, 값의 상대적인 차이가 작아질 수 있다.
✓ 모든 모델에서 로그 변환이 이득이 되는 건 아니다.
- 정규성 가정을 전제로 하는 모델(예: 선형 회귀, 회귀 분석)에서 효과가 크다.
로그 변환은 무조건적인 해결책은 아니지만, 분포가 한쪽으로 몰려 있는 데이터를 다룰 때 고려해볼 수 있는 좋은 선택지다.
결국 중요한 건 데이터를 변형하는 이유를 이해하고, 그 변형이 분석이나 예측에 어떤 영향을 줄지 스스로 판단할 수 있는 힘이다.
데이터를 정제하거나 모델에 넣기 전에, 한 번쯤 로그 변환을 떠올려 보는 습관을 가져보자.
