확률분포는 통계 분석과 데이터 과학의 핵심 개념이다.
이번 글에서는 대표적인 분포들을 시뮬레이션으로 구현한 과정을 정리해 보았다.
- 균등분포 (Uniform Distribution)
- 베르누이 분포 (Bernoulli Distribution)
- 이항분포 (Binomial Distribution)
- 정규분포 (Normal Distribution)
1. 균등분포 (Uniform Distribution)
균등분포는 말 그대로 특정 범위 내에서 값이 동일한 확률로 발생하는 분포이다.
예를 들어, 0과 1 사이에서 무작위 값을 생성하면 균등하게 퍼져 있는 데이터를 얻게 된다.
1-1. 기본 균등분포
from scipy.stats import uniform
# 균등 분포 생성 (예시: 0에서 1 사이)
uniform_dist = uniform.rvs(size=10, loc=0, scale=1)
# 결과 출력
uniform_dist
array([0.47684347, 0.68772204, 0.72270696, 0.69253243, 0.13443513,
0.29939559, 0.35871553, 0.80443721, 0.27875987, 0.21070496])rvs: Random Variated Sampling 함수로 무작위 샘플을 생성한다.loc=0: 시작값,scale=1: 구간의 폭 → 0~1 사이 값이 생성된다.
1-2. 균등분포 시뮬레이션
어떤 회사의 고객 대기시간은 5분에서 15분 사이의 균등분포를 따른다.
고객 100명이 대기한 시간을 시뮬레이션하고, 평균 대기시간과 표준편차를 계산해 보자.
import numpy as np
from scipy.stats import uniform
# 시뮬레이션
user_count = 100
waiting_times = uniform.rvs(loc=5, scale=10, size=user_count, random_state=0)
# 평균과 표준편차 계산
mean_waiting_time = np.mean(waiting_times)
std_waiting_time = np.std(waiting_times, ddof=1)
print(np.shape(waiting_times))
print(f"평균 대기시간: {mean_waiting_time:.2f}")
print(f"표준편차: {std_waiting_time:.2f}")
(100,)
평균 대기시간: 9.73
표준편차: 2.90loc=5,scale=10→ 5~15분 사이의 균등분포- 실제로 서비스 대기시간 시뮬레이션 등에 활용할 수 있다.
2. 베르누이 분포 (Bernoulli Distribution)
베르누이 분포는 "성공(1) 또는 실패(0)" 두 가지 결과만 가지는 분포이다.
동전 던지기처럼 단일 시행에 대해 성공 여부를 나타낸다.
2-1. 기본 베르누이 분포
from scipy.stats import bernoulli
# p는 성공 확률 (0과 1 사이)
p = 0.5
size = 10
# 베르누이 분포 샘플 생성
samples = bernoulli.rvs(p, size=size)
samples
array([0, 0, 0, 0, 1, 1, 0, 1, 1, 0])2-2. 베르누이 분포 시뮬레이션
한 신제품의 초기 성공 확률이 0.3이라고 가정한다.
10회의 시뮬레이션에서 성공한 횟수를 구하고, 각 성공 여부를 출력해 보자.
from scipy.stats import bernoulli
# 성공 확률과 시행 수 정의
p = 0.3
n = 10
# 베르누이 분포 샘플 생성
outcomes = bernoulli.rvs(p, size=n)
success_count = outcomes.sum()
print(f"각 시도 결과: {outcomes}")
print(f"성공 횟수: {success_count}")
각 시도 결과: [0 0 1 0 1 1 0 0 1 1]
성공 횟수: 510회의 시뮬레이션에서 성공 횟수를 구하였는데, 이는 확률 기반의 이벤트 분석에 유용하다.
3. 이항분포 (Binomial Distribution)
이항분포는 베르누이 시행을 여러 번 반복한 경우를 다룬다.
예를 들어, 동전을 3번 던져 앞면이 나올 횟수를 계산하는 경우다.
3-1. 기본 이항분포
from scipy.stats import binom
# n: 시행 횟수, p: 성공 확률, k: 성공 횟수
n = 3
p = 0.5
k = 2
# 이항 분포 확률 계산
probability = binom.pmf(k, n, p)
print(f"동전 3개를 던졌을 때 앞면이 2개, 뒷면이 1개 나올 확률: {probability}")
동전 3개를 던졌을 때 앞면이 2개, 뒷면이 1개 나올 확률: 0.37500000000000013-2. 이항분포 시뮬레이션 문제
한 수업에서 학생 20명이 5문제로 구성된 퀴즈를 치른다. 각 문제의 정답 확률은 0.7이라고 가정할 때, 각 학생이 맞힌 점수를 시뮬레이션하고, 전체 학생의 평균 점수를 계산해 보자.
from scipy.stats import binom
import numpy as np
# 이항 분포: 문제 수, 정답확률, 학생 수
num_of_stds = 20
num_of_quizzes = 5
percent = 0.7
# 각 학생의 점수 시뮬레이션
scores = binom.rvs(num_of_quizzes, p=percent, size=num_of_stds, random_state=0)
average_score = np.mean(scores)
print(f"학생별 점수: {scores}")
print(f"평균 점수: {average_score:.2f}")
학생별 점수: [3 3 3 3 4 3 4 2 2 4 3 3 3 2 5 5 5 3 3 2]
평균 점수: 3.254. 정규분포 (Normal Distribution)
정규분포는 평균을 중심으로 대칭 형태를 가지며, 자연 현상에서 자주 나타나는 분포다.
4-1. 정규분포 누적확률 계산
from scipy.stats import norm
# 1380점에 대한 백분율 계산
percentile = norm.cdf(1380, loc=1150, scale=150) * 100
print(f"SAT 점수 1380점의 백분율은 약 {percentile:.2f}% 입니다.")
SAT 점수 1380점의 백분율은 약 93.74% 입니다.4-2. 정규분포 시뮬레이션 문제
한 공장에서 생산되는 제품의 무게는 평균 50g, 표준편차 5g의 정규분포를 따른다. 1000개의 제품 무게를 시뮬레이션하고, 무게가 45g 이상 55g 이하인 제품의 비율을 계산해 보자.
import matplotlib.pyplot as plt
from scipy.stats import norm
import numpy as np
# 정규 분포 파라미터
mu = 50
sigma = 5
num_of_samples = 1000
# 샘플 생성
weights = norm.rvs(loc=mu, scale=sigma, size=num_of_samples, random_state=0)
# 45g 이상 55g 이하의 비율 계산
conds = (weights >= 45) & (weights <= 55)
within_range = len(weights[conds]) / len(weights)
print(f"45g 이상 55g 이하의 비율 계산: {within_range:.2f}")
45g 이상 55g 이하의 비율 계산: 0.704-3. 히스토그램 그리기
# 히스토그램 그리기
plt.hist(weights, bins=30, density=True, alpha=0.7, label="Weights")
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 100)
plt.plot(x, norm.pdf(x, mu, sigma), 'r--', label="PDF")
plt.xlabel("Weight (g)")
plt.ylabel("Density")
plt.title("Product Weight Distribution")
plt.legend()
plt.show()
45g 이상 55g 이하 비율: 69.90%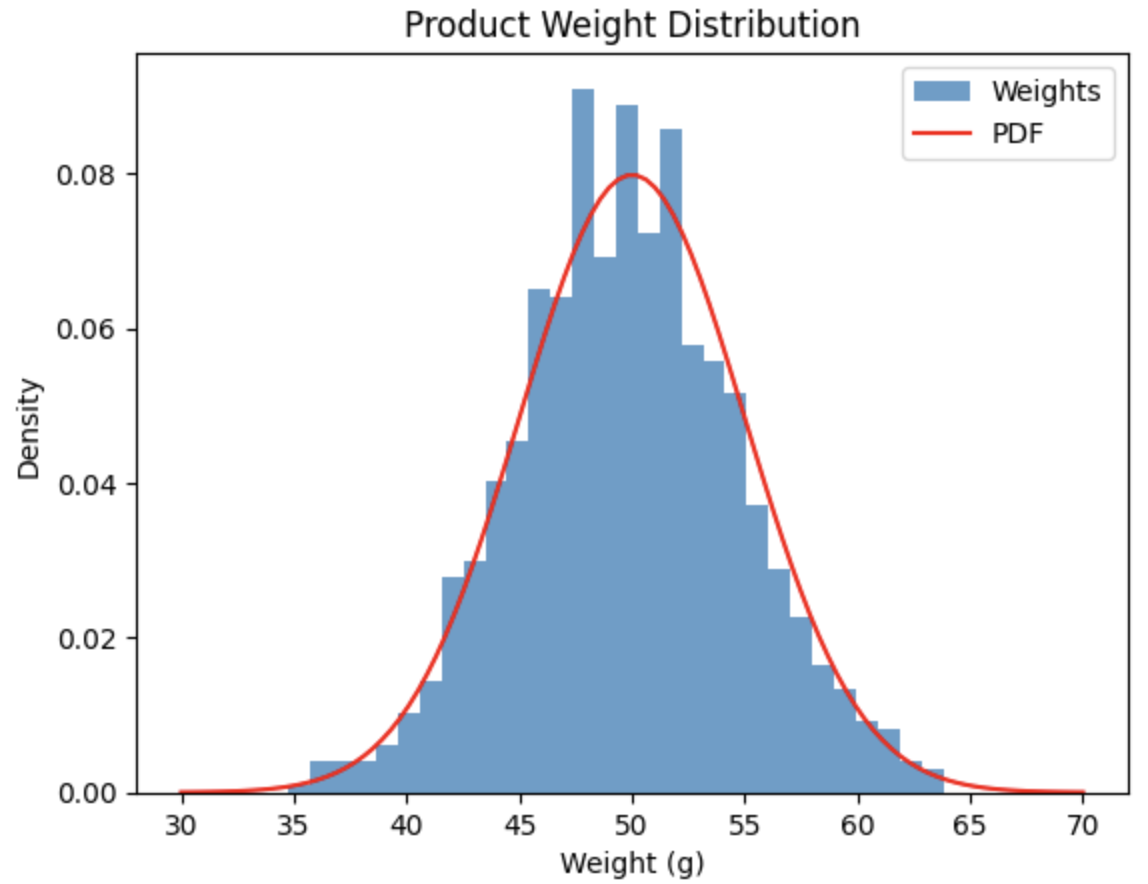
45g 이상 55g 이하의 비율은
평균이 에서 와 사이의 비율과 같다.
정규분포에서 이 비율은 약 34.1%*2=68.2%인데, 정규분포로 샘플링한 데이터에서도 비슷한 비율로 나옴을 확인할 수 있다.
정리해 보면,
- 균등분포는 특정 구간에서 균일하게 확률이 분포된 데이터를 생성하는 데 활용된다.
- 베르누이분포는 성공/실패가 명확한 단일 사건을 모델링할 때 유용하다.
- 이항분포는 베르누이 사건의 반복으로, 시험이나 클릭 횟수와 같은 이벤트를 분석할 때 활용된다.
- 정규분포는 대량의 자연 현상 데이터를 설명하는 데 가장 기본적인 도구로 쓰인다.
확률분포를 직접 구현하면서 이해하면, 이론으로만 접했던 개념들이 실제 문제 상황에서 어떻게 활용되는지 명확히 파악할 수 있다.
