CSAPP Chapter 9.6-9.7 - 주소 변환과 Intel Core i7 사례 연구 정리
9.6 주소 변환 (Address Translation)
주소 변환의 기본 개념
주소 변환의 목표
하드웨어가 가상 메모리를 지원하는 역할을 이해하고, 구체적인 예제를 손으로 계산할 수 있는 수준의 상세한 설명을 제공합니다.
주소 변환 기호 요약
| 기호 | 설명 |
|---|---|
| 기본 매개변수 | |
| N = 2^n | 가상 주소 공간의 주소 수 |
| M = 2^m | 물리 주소 공간의 주소 수 |
| P = 2^p | 페이지 크기 (바이트) |
| 가상 주소 (VA) 구성 요소 | |
| VPO | 가상 페이지 오프셋 (바이트) |
| VPN | 가상 페이지 번호 |
| TLBI | TLB 인덱스 |
| TLBT | TLB 태그 |
| 물리 주소 (PA) 구성 요소 | |
| PPO | 물리 페이지 오프셋 (바이트) |
| PPN | 물리 페이지 번호 |
| CO | 캐시 블록 내 바이트 오프셋 |
| CI | 캐시 인덱스 |
| CT | 캐시 태그 |
주소 변환의 수학적 정의
공식적 정의
주소 변환은 N개 요소의 가상 주소 공간(VAS)과 M개 요소의 물리 주소 공간(PAS) 사이의 매핑입니다.
MAP: VAS → PAS ∪ ∅
여기서:
MAP(A) = A' (가상 주소 A의 데이터가 물리 주소 A'에 있는 경우)
MAP(A) = ∅ (가상 주소 A의 데이터가 물리 메모리에 없는 경우)MMU를 통한 주소 변환 과정
페이지 테이블을 사용한 주소 변환
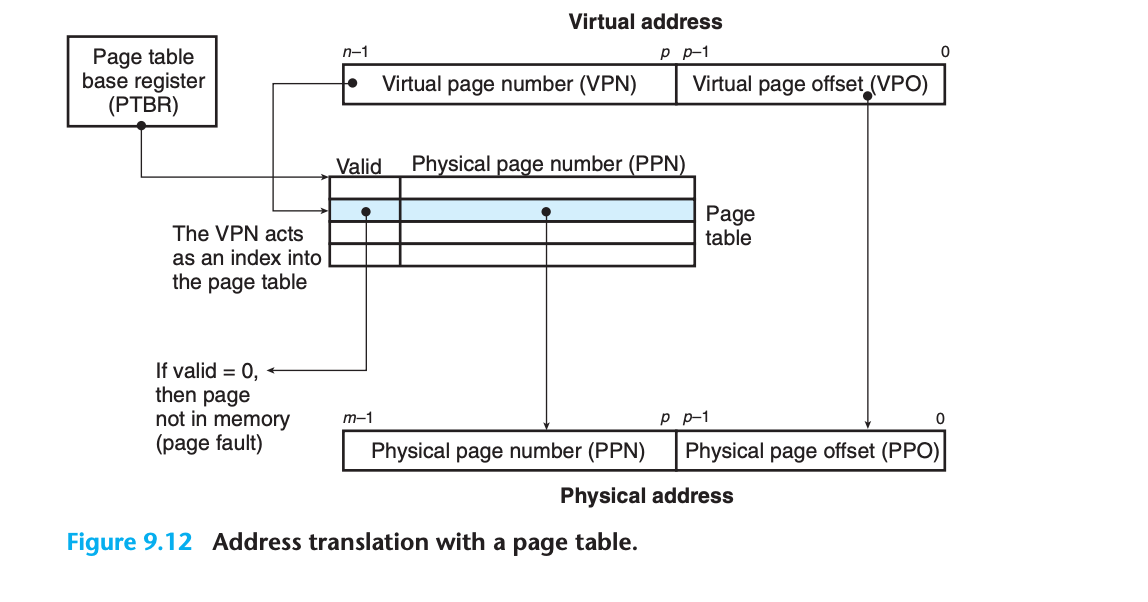
주소 변환의 핵심 구성 요소
1. 페이지 테이블 베이스 레지스터 (PTBR)
- CPU의 제어 레지스터
- 현재 페이지 테이블을 가리키는 포인터
2. 가상 주소 구성
n비트 가상 주소 구성:
┌─────────────────┬─────────────────┐
│ VPN (n-p 비트) │ VPO (p 비트) │
│ 가상 페이지 번호 │ 가상 페이지 오프셋 │
└─────────────────┴─────────────────┘3. MMU의 동작 과정
1. VPN을 사용하여 적절한 PTE 선택
- VPN 0 → PTE 0
- VPN 1 → PTE 1
- ...
2. 물리 주소 구성
- PTE에서 PPN 추출
- 가상 주소에서 VPO 추출
- PPN + VPO = 물리 주소
3. PPO = VPO (물리/가상 페이지 크기가 동일하므로)페이지 히트와 페이지 폴트 처리
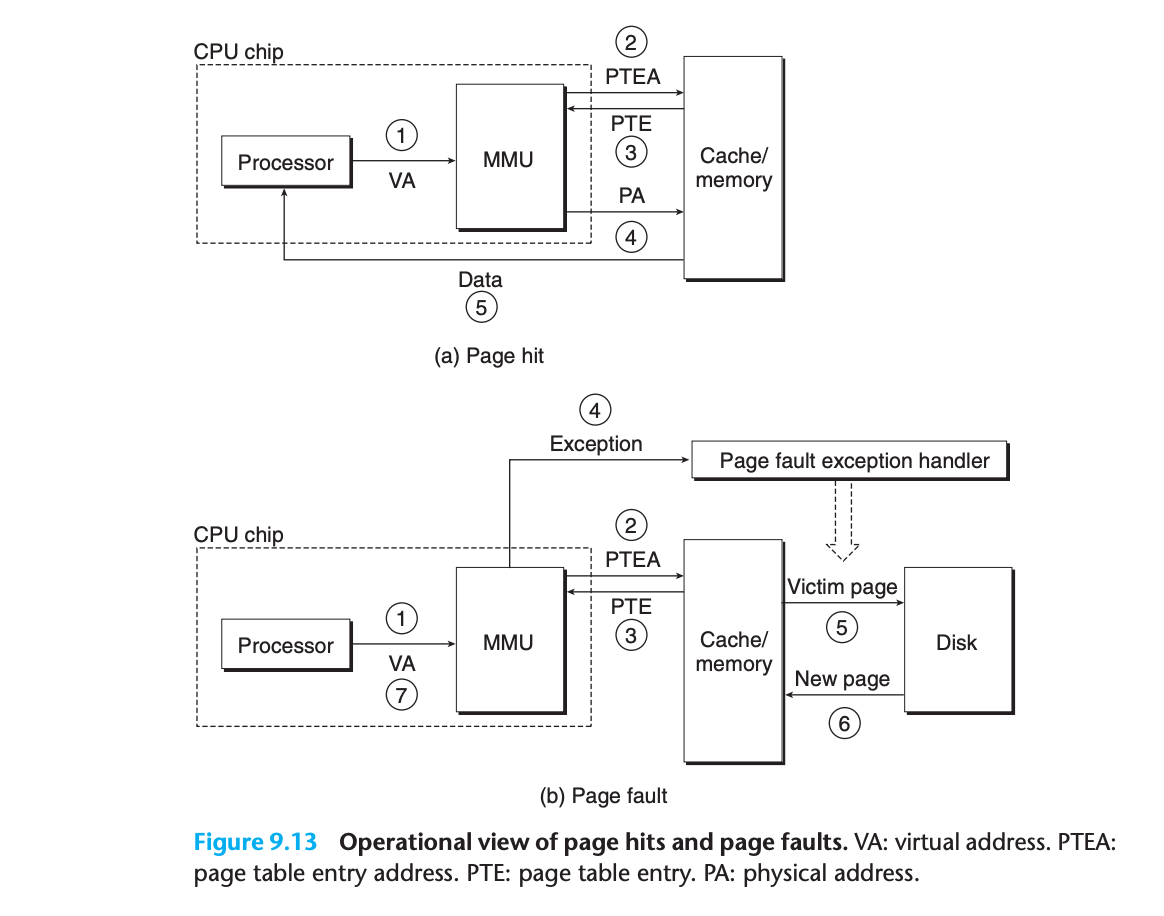
페이지 히트 처리 과정 (하드웨어만 처리)
페이지 히트 처리 단계:
1단계: 프로세서가 가상 주소 생성하여 MMU로 전송
↓
2단계: MMU가 PTE 주소 생성하여 캐시/메인 메모리에 요청
↓
3단계: 캐시/메인 메모리가 PTE를 MMU로 반환
↓
4단계: MMU가 물리 주소 구성하여 캐시/메인 메모리로 전송
↓
5단계: 캐시/메인 메모리가 요청된 데이터 단어를 프로세서로 반환페이지 폴트 처리 과정 (하드웨어 + 운영체제 협력)
페이지 폴트 처리 단계:
1-3단계: 페이지 히트의 1-3단계와 동일
↓
4단계: PTE의 valid bit가 0이므로 MMU가 예외 트리거
↓
5단계: 폴트 핸들러가 물리 메모리에서 희생자 페이지 식별
↓
6단계: 희생자 페이지가 수정되었다면 디스크로 페이지 아웃
↓
7단계: 새 페이지를 페이지 인하고 메모리의 PTE 업데이트
↓
8단계: 폴트 핸들러가 원래 프로세스로 반환
↓
9단계: CPU가 폴트를 발생시킨 명령어 재시작
↓
10단계: 이제 가상 페이지가 캐시되어 정상적인 페이지 히트 처리9.6.1 캐시와 VM 통합
가상 주소 vs 물리 주소 캐시 접근
핵심 문제
가상 메모리와 SRAM 캐시를 모두 사용하는 시스템에서 가상 주소 vs 물리 주소 중 어떤 것을 사용하여 SRAM 캐시에 접근할지 결정해야 합니다.
대부분의 시스템 선택: 물리 주소 지정
물리 주소 지정의 장점
물리 주소 지정의 이점:
1. 여러 프로세스가 동시에 캐시에 블록을 가질 수 있음
2. 동일한 가상 페이지의 블록을 공유 가능
3. 캐시가 보호 문제를 처리할 필요 없음
- 접근 권한은 주소 변환 과정에서 검사됨물리 주소 캐시와 VM 통합
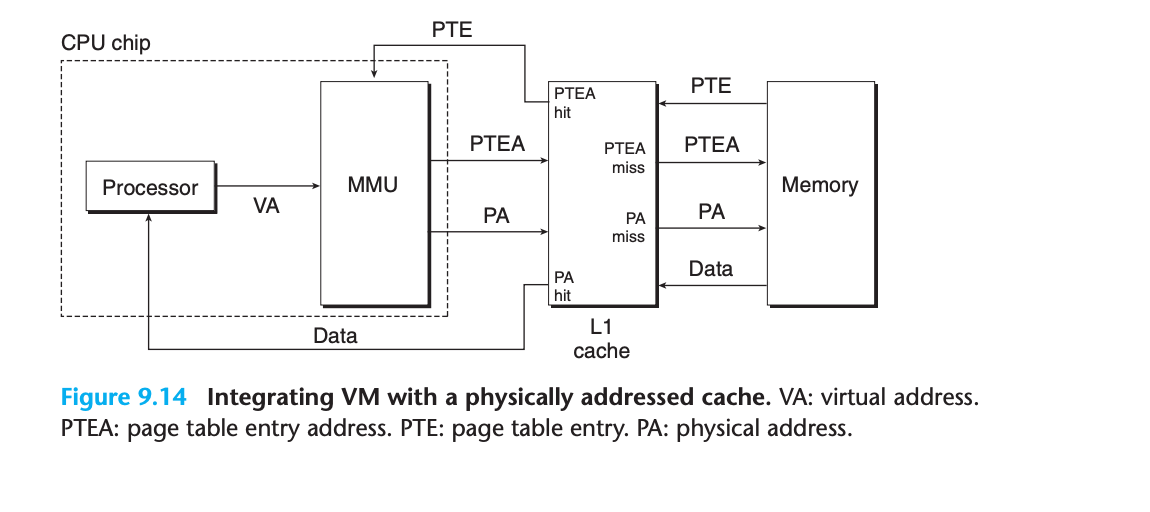
페이지 테이블 엔트리 캐싱
- PTE도 다른 데이터 단어처럼 캐시 가능
- 캐시 계층 구조의 일부로 처리
9.6.2 TLB를 통한 주소 변환 가속
TLB의 필요성
주소 변환의 성능 문제
매번 가상 주소 생성 시 MMU가 PTE를 참조해야 함
→ 최악의 경우: 메모리에서 추가 페치 필요 (수십~수백 사이클)
→ L1 캐시 히트 시: 몇 사이클로 감소TLB (Translation Lookaside Buffer) 솔루션
MMU 내부의 작은 PTE 캐시로, 이 비용도 제거하려는 시도
TLB 구조
TLB의 특징
TLB 특성:
- 작은 크기의 가상 주소 캐시
- 각 라인이 단일 PTE로 구성된 블록 보유
- 높은 연관도 (high degree of associativity)TLB 주소 구성

TLB 히트와 미스 처리
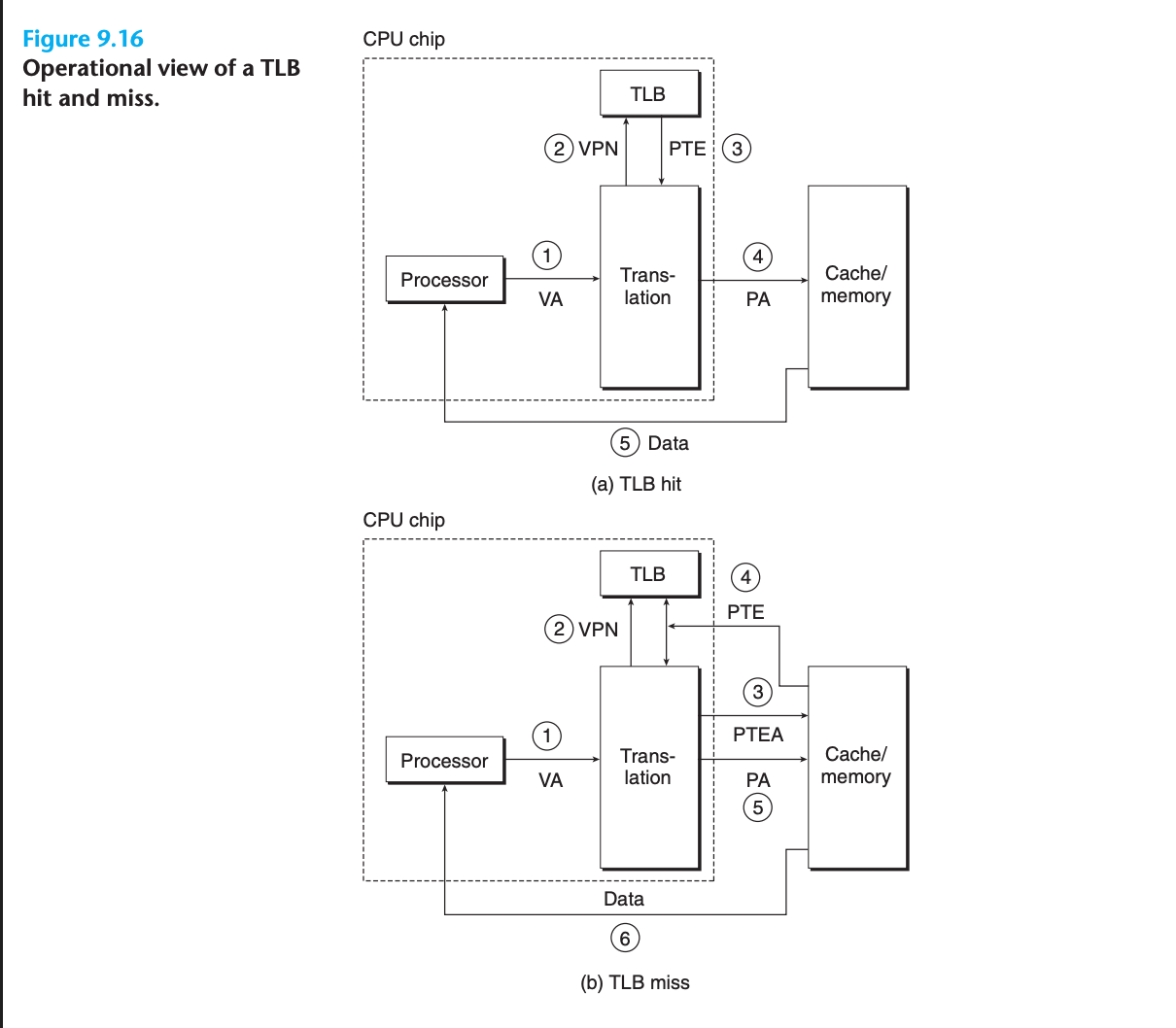
TLB 히트 처리 (일반적인 경우)
TLB 히트 처리 단계:
1단계: CPU가 가상 주소 생성
↓
2-3단계: MMU가 TLB에서 적절한 PTE 페치
↓
4단계: MMU가 가상 주소를 물리 주소로 변환하여 캐시/메인 메모리로 전송
↓
5단계: 캐시/메인 메모리가 요청된 데이터 단어를 CPU로 반환
→ 모든 주소 변환 단계가 온칩 MMU 내부에서 수행되어 빠름TLB 미스 처리
TLB 미스 처리:
1. MMU가 L1 캐시에서 PTE 페치 필요
2. 새로 페치된 PTE를 TLB에 저장
3. 기존 엔트리 덮어쓰기 가능9.6.3 다단계 페이지 테이블
단일 페이지 테이블의 문제점
메모리 요구량 문제
32비트 주소 공간, 4KB 페이지, 4바이트 PTE 예시:
- 필요한 페이지 테이블 크기: 4MB
- 애플리케이션이 작은 가상 주소 공간만 참조해도 항상 메모리 상주 필요
- 64비트 주소 공간에서는 문제가 더욱 심각다단계 페이지 테이블 솔루션
계층적 페이지 테이블 구조
단일 페이지 테이블 대신 페이지 테이블의 계층을 사용하여 메모리 요구량을 줄이는 방법
2단계 페이지 테이블 예제
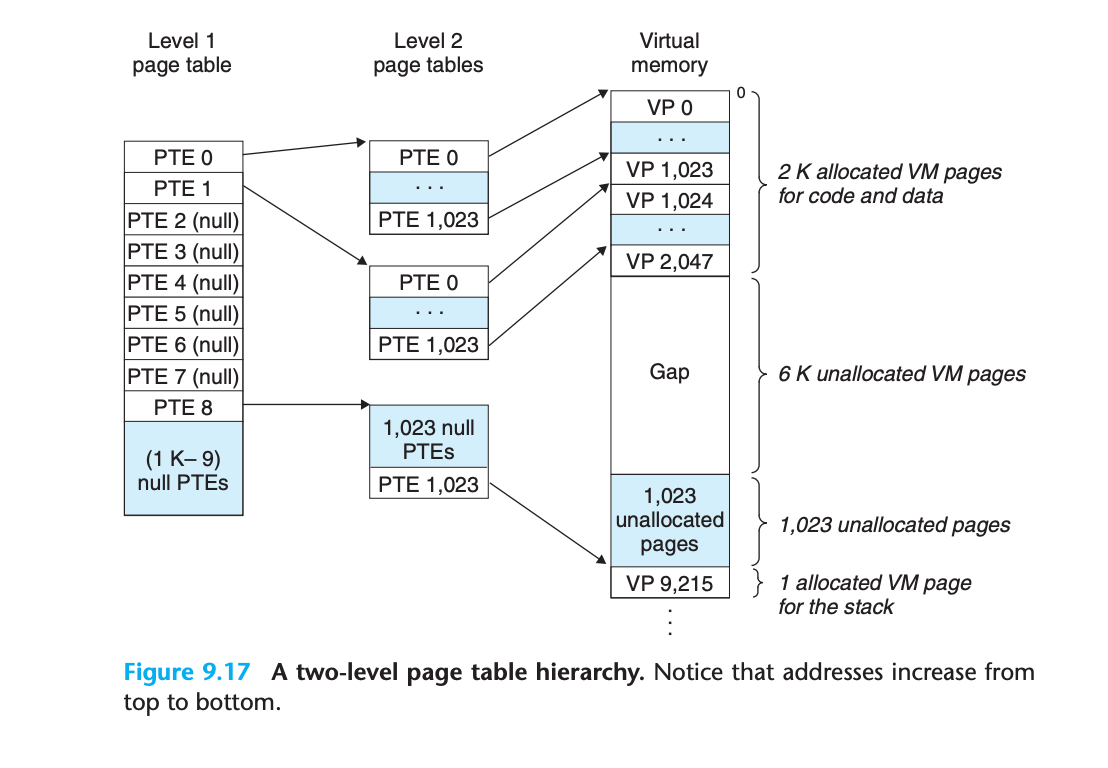
32비트 가상 주소 공간, 4KB 페이지, 4바이트 PTE 시스템:
가상 주소 공간 구성:
- 첫 2K 페이지: 코드와 데이터용 할당
- 다음 6K 페이지: 할당되지 않음
- 다음 1,023 페이지: 할당되지 않음
- 다음 1 페이지: 사용자 스택용 할당레벨 1 테이블 구조
레벨 1 테이블의 각 PTE:
- 4MB 청크의 가상 주소 공간 매핑 담당
- 각 청크는 1,024개의 연속된 페이지로 구성
- PTE 0: 첫 번째 청크 매핑
- PTE 1: 두 번째 청크 매핑
- ...
4GB 주소 공간 → 1,024개의 PTE로 전체 공간 커버할당 상태에 따른 처리
청크 i의 모든 페이지가 할당되지 않은 경우:
- 레벨 1 PTE i = null
청크 i의 최소 하나의 페이지가 할당된 경우:
- 레벨 1 PTE i가 레벨 2 페이지 테이블의 베이스를 가리킴레벨 2 테이블 구조
레벨 2 페이지 테이블의 각 PTE:
- 4KB 가상 메모리 페이지 매핑 담당
- 단일 레벨 페이지 테이블과 동일한 역할
4바이트 PTE → 각 레벨 1, 2 페이지 테이블 = 4KB (페이지 크기와 동일)메모리 요구량 감소 효과
1. 조건부 존재
레벨 1 테이블의 PTE가 null이면:
- 해당 레벨 2 페이지 테이블이 존재할 필요 없음
- 전형적인 프로그램의 4GB 가상 주소 공간 대부분이 할당되지 않음
- 상당한 메모리 절약 가능2. 동적 로딩
- 레벨 1 테이블만 항상 메인 메모리에 상주
- 레벨 2 페이지 테이블은 필요에 따라 VM 시스템이 생성/페이지 인/아웃
- 메인 메모리 압박 감소
- 가장 많이 사용되는 레벨 2 페이지 테이블만 메인 메모리에 캐시k단계 페이지 테이블 주소 변환
가상 주소 구성
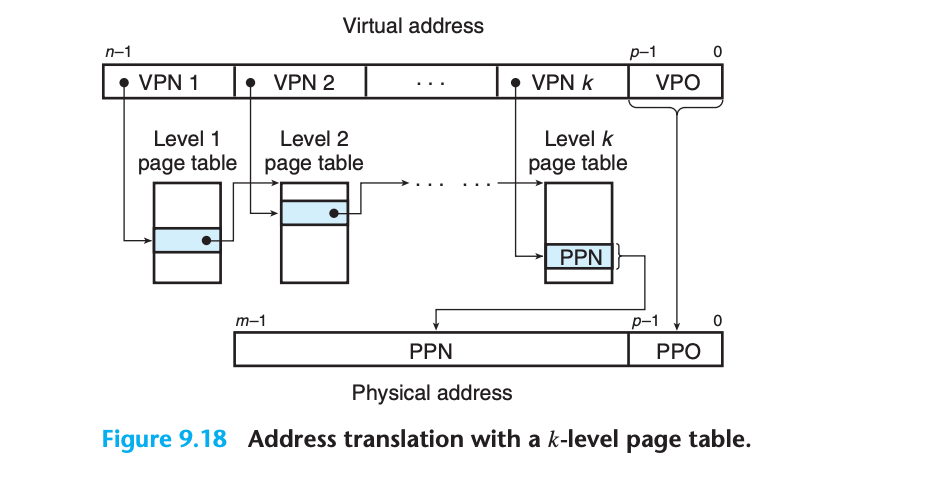
주소 변환 과정
1. 각 VPN i (1 ≤ i ≤ k)는 레벨 i의 페이지 테이블에 대한 인덱스
2. 레벨 j 테이블의 각 PTE (1 ≤ j ≤ k-1)는 레벨 j+1의 페이지 테이블 베이스를 가리킴
3. 레벨 k 테이블의 각 PTE는 물리 페이지의 PPN 또는 디스크 블록 주소 포함
4. 물리 주소 구성: MMU가 k개의 PTE에 접근한 후 PPN 결정
5. PPO = VPO (단일 레벨 계층과 동일)성능 고려사항
TLB의 구원 역할
k개 PTE 접근이 비싸고 비현실적으로 보일 수 있지만:
- TLB가 다양한 레벨의 페이지 테이블에서 PTE를 캐시
- 실제로는 다단계 페이지 테이블이 단일 레벨보다 크게 느리지 않음9.6.4 전체 주소 변환 과정: 엔드투엔드 예제
시스템 설정
가정 조건
시스템 매개변수:
- 메모리: 바이트 주소 지정
- 메모리 접근: 1바이트 단어 (4바이트 아님)
- 가상 주소: 14비트 (n = 14)
- 물리 주소: 12비트 (m = 12)
- 페이지 크기: 64바이트 (P = 64)
- TLB: 4-way set associative, 총 16개 엔트리
- L1 d-cache: 물리 주소 지정, direct mapped, 4바이트 라인 크기, 총 16개 세트주소 형식
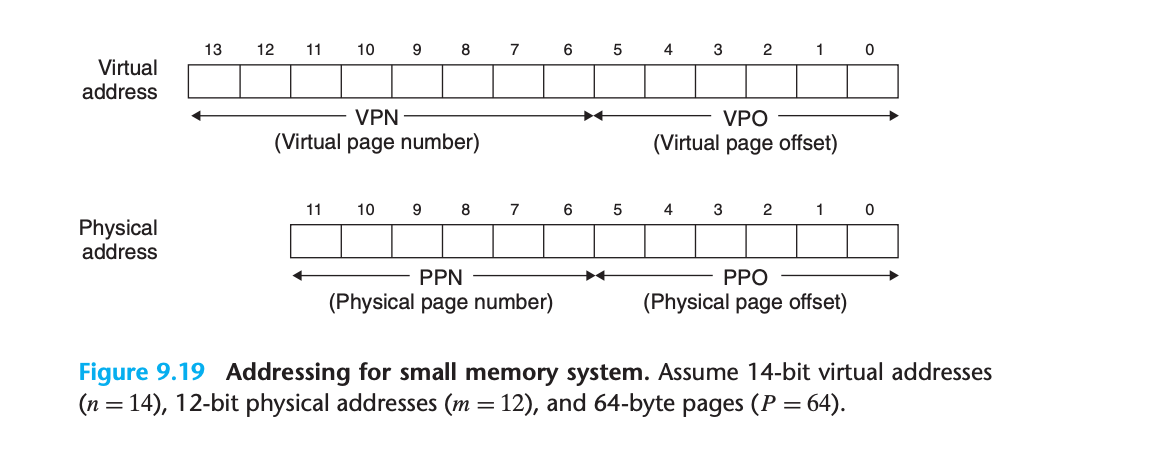
메모리 시스템 스냅샷
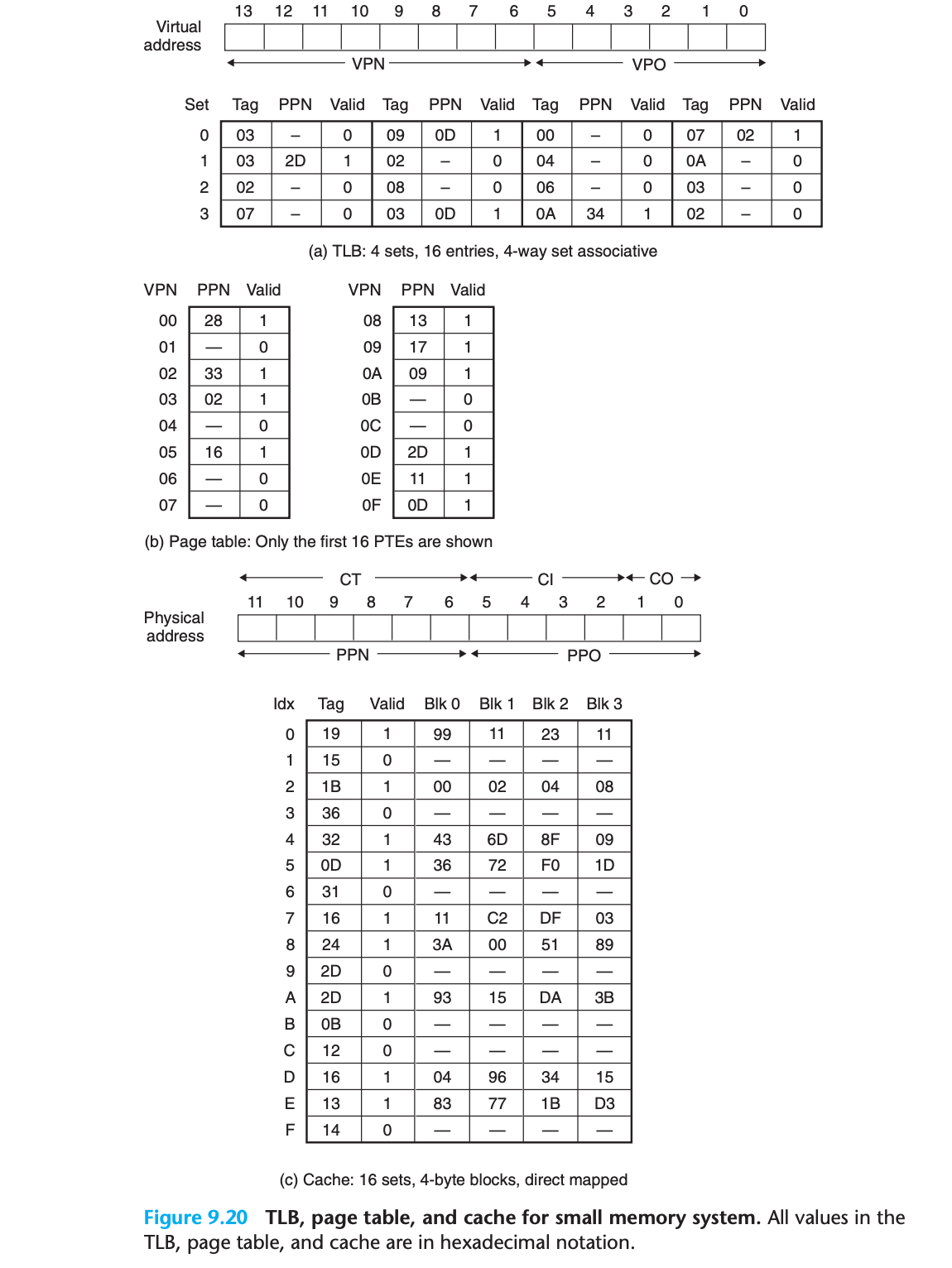
TLB 구조
TLB: 4개 세트, 16개 엔트리, 4-way set associative
- VPN의 하위 2비트가 세트 인덱스 (TLBI)
- VPN의 상위 6비트가 태그 (TLBT)페이지 테이블 구조
단일 레벨 페이지 테이블: 총 2^8 = 256개 PTE
- 관심 있는 것은 처음 16개 PTE만
- 각 PTE는 해당하는 VPN으로 라벨링
- 무효한 PTE의 PPN은 대시(-)로 표시캐시 구조
Direct-mapped 캐시: 물리 주소의 필드로 주소 지정
- 각 블록: 4바이트 → 하위 2비트가 블록 오프셋 (CO)
- 16개 세트 → 다음 4비트가 세트 인덱스 (CI)
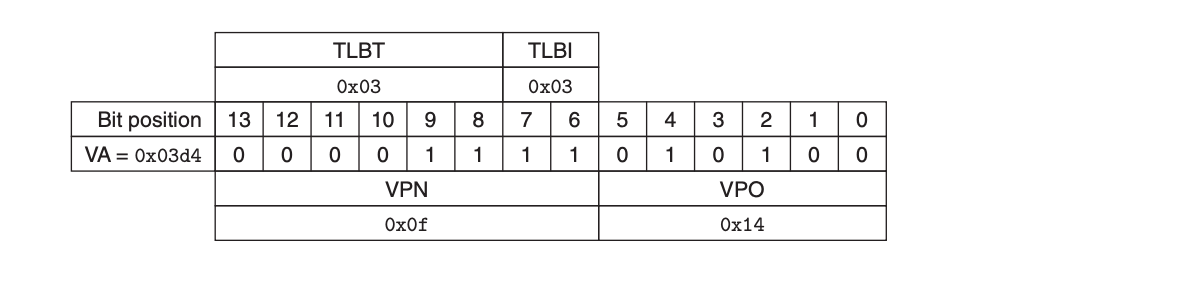
- 나머지 6비트가 태그 (CT)주소 변환 시뮬레이션: 0x03d4 접근
1단계: 가상 주소 분석
VA = 0x03d4 = 0000 0011 1101 0100 (2진수)
비트 위치 분석:
13 12 11 10 9 8 7 6 5 4 3 2 1 0
0 0 0 0 0 0 1 1 1 1 0 1 0 1 0 0
│ VPN (0x0F) │ │ VPO (0x14) │
│ TLBT (0x3) │ │ TLBI (0x3) │2단계: TLB 조회
MMU가 VPN (0x0F) 추출
TLB에서 TLB 인덱스 (0x03)와 TLB 태그 (0x3) 추출
세트 0x3의 두 번째 엔트리에서 유효한 매치 히트
캐시된 PPN (0x0D)을 MMU로 반환3단계: 물리 주소 구성
MMU가 물리 주소 구성:
- PTE에서 PPN (0x0D) 추출
- 가상 주소에서 VPO (0x14) 추출
- 물리 주소 = 0x3544단계: 캐시 접근
5단계: 캐시 히트 처리
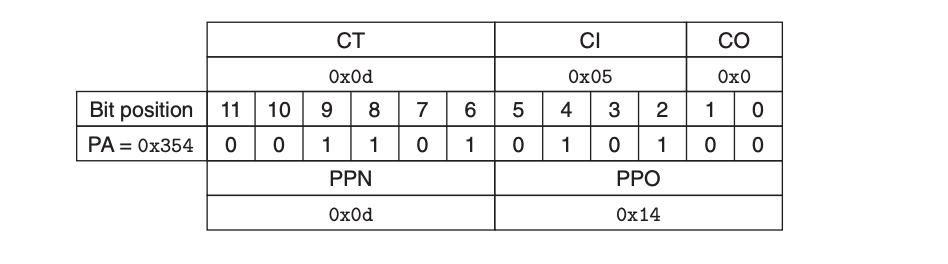
세트 0x5에서 태그가 CT와 매치
캐시가 오프셋 CO에서 데이터 바이트 (0x36) 읽기
MMU를 통해 CPU로 반환다른 경로들
TLB 미스 시나리오
1. MMU가 페이지 테이블에서 PPN 페치 필요
2. 추가 메모리 접근으로 인한 지연페이지 폴트 시나리오
1. 결과 PTE가 무효한 경우
2. 페이지 폴트 발생
3. 커널이 적절한 페이지를 페이지 인
4. 로드 명령어 재실행캐시 미스 시나리오
1. PTE는 유효하지만 필요한 메모리 블록이 캐시에서 미스
2. L2, L3 캐시 또는 메인 메모리에서 데이터 페치9.7 사례 연구: Intel Core i7/Linux 메모리 시스템
Core i7 메모리 시스템 개요
시스템 특성
Core i7 메모리 시스템 특징:
- Haswell 마이크로아키텍처 기반
- 64비트 가상/물리 주소 공간 지원 가능
- 현재 구현: 48비트 (256TB) 가상 주소 공간, 52비트 (4PB) 물리 주소 공간
- 32비트 (4GB) 가상/물리 주소 공간 호환 모드 지원프로세서 패키지 구성
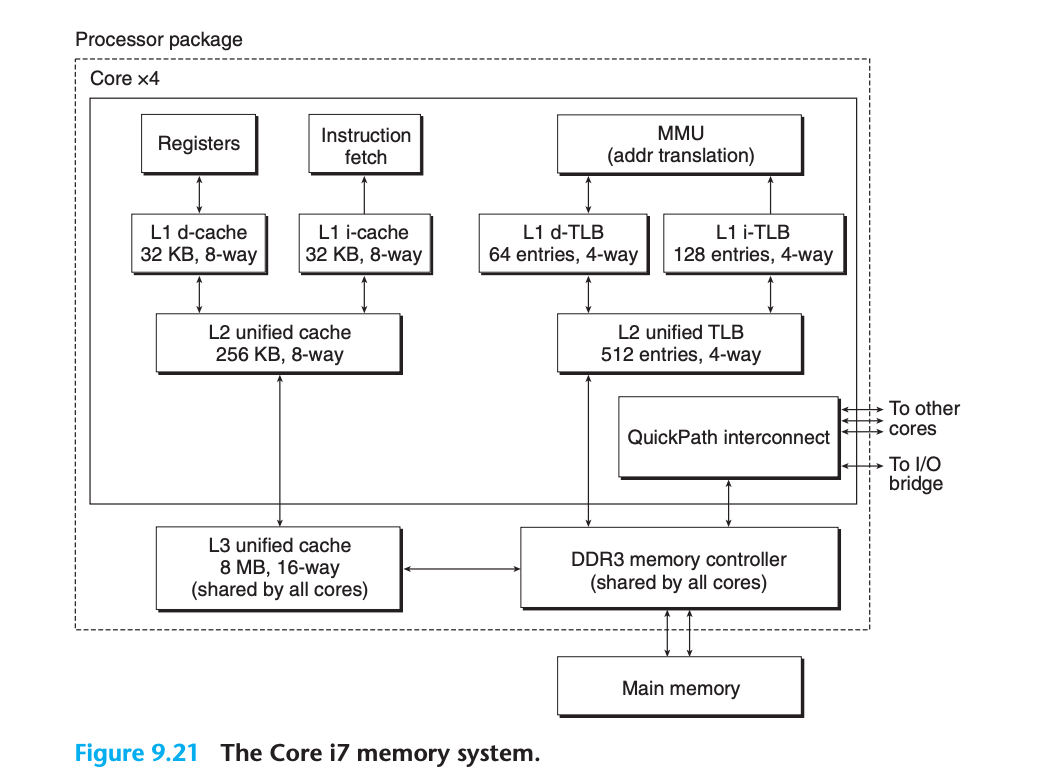
캐시 및 TLB 특성
캐시 계층 구조:
- TLB: 가상 주소 지정, 4-way set associative
- L1, L2, L3 캐시: 물리 주소 지정, 64바이트 블록 크기
- L1, L2: 8-way set associative
- L3: 16-way set associative
페이지 크기: 시작 시 4KB 또는 4MB로 구성 가능 (Linux는 4KB 사용)9.7.1 Core i7 주소 변환
4단계 페이지 테이블 계층
전체 주소 변환 과정
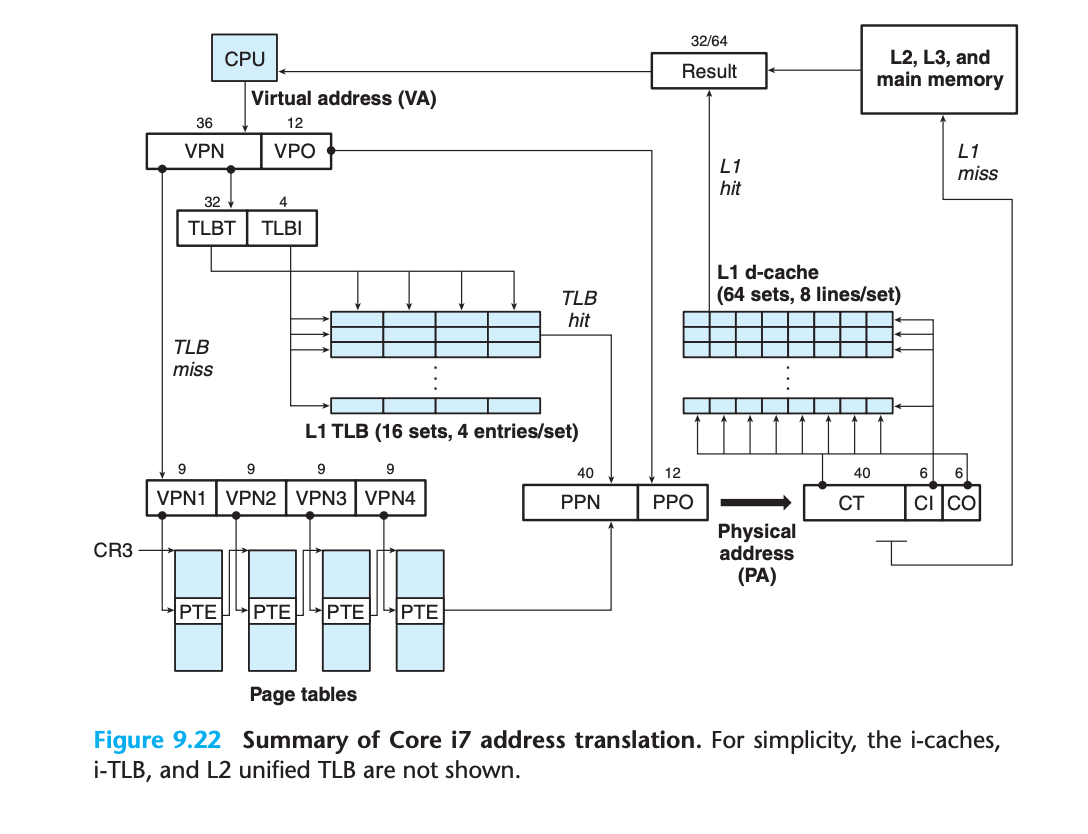
프로세스별 페이지 테이블
각 프로세스가 고유한 페이지 테이블 계층 보유
Linux 프로세스 실행 시: 할당된 페이지와 연관된 페이지 테이블이 모두 메모리 상주
Core i7 아키텍처: 페이지 테이블 스왑 인/아웃 허용
CR3 제어 레지스터: 레벨 1 (L1) 페이지 테이블의 시작 물리 주소 포함페이지 테이블 엔트리 형식
레벨 1, 2, 3 페이지 테이블 엔트리
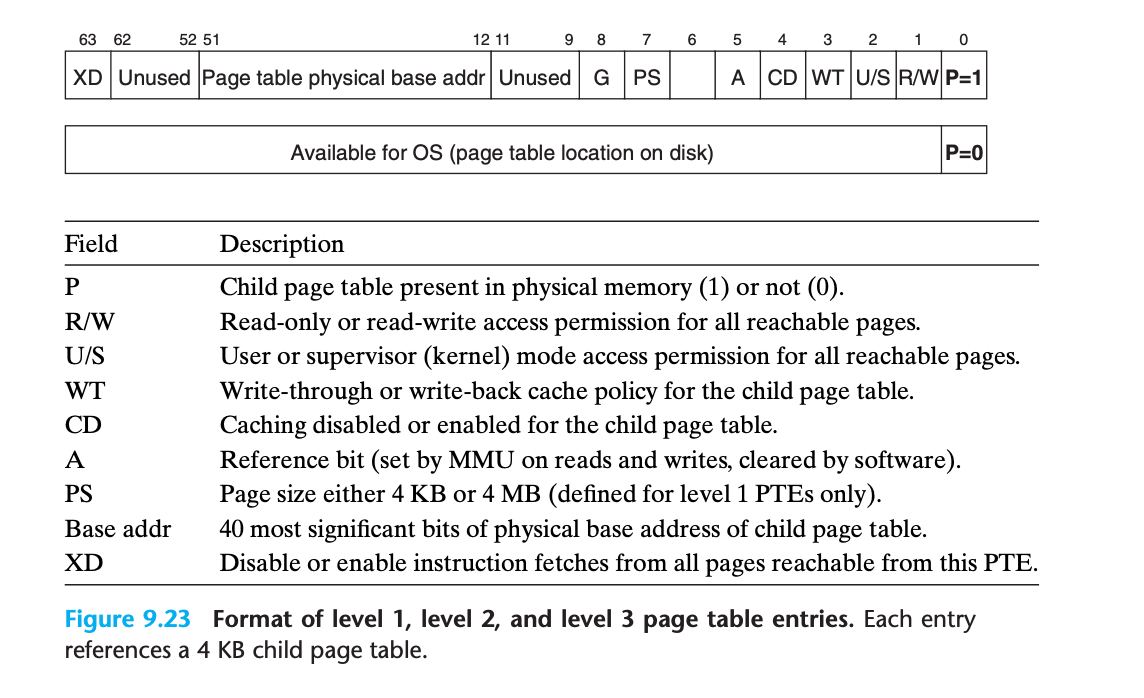
필드 설명
| 필드 | 설명 |
|---|---|
| P | 자식 페이지 테이블이 물리 메모리에 있음(1) 또는 없음(0) |
| R/W | 모든 도달 가능한 페이지에 대한 읽기 전용 또는 읽기/쓰기 접근 권한 |
| U/S | 모든 도달 가능한 페이지에 대한 사용자 또는 수퍼바이저(커널) 모드 접근 권한 |
| WT | 자식 페이지 테이블에 대한 라이트스루 또는 라이트백 캐시 정책 |
| CD | 자식 페이지 테이블에 대한 캐싱 비활성화 또는 활성화 |
| A | 참조 비트 (MMU가 읽기/쓰기 시 설정, 소프트웨어가 클리어) |
| PS | 페이지 크기 4KB 또는 4MB (레벨 1 PTE에만 정의) |
| Base addr | 자식 페이지 테이블의 물리 베이스 주소의 상위 40비트 |
| XD | 이 PTE에서 도달 가능한 모든 페이지에서 명령어 페치 비활성화 또는 활성화 |
레벨 4 페이지 테이블 엔트리

추가 필드 설명
| 필드 | 설명 |
|---|---|
| D | 더티 비트 (MMU가 쓰기 시 설정, 소프트웨어가 클리어) |
| G | 글로벌 페이지 (태스크 스위치 시 TLB에서 제거하지 않음) |
권한 비트와 보호
3가지 권한 비트
권한 비트 시스템:
1. R/W 비트: 페이지 내용의 읽기/쓰기 또는 읽기 전용 여부 결정
2. U/S 비트: 사용자 모드에서 페이지 접근 가능 여부 결정
- 운영체제 커널의 코드와 데이터를 사용자 프로그램으로부터 보호
3. XD 비트 (64비트 시스템에서 도입): 개별 메모리 페이지에서 명령어 페치 비활성화
- 버퍼 오버플로우 공격 위험 감소를 위한 중요한 기능
- 읽기 전용 코드 세그먼트로 실행 제한MMU 자동 업데이트 비트
MMU가 자동으로 업데이트하는 비트:
1. A 비트 (참조 비트): 페이지 접근 시마다 설정
- 커널의 페이지 교체 알고리즘 구현에 사용
2. D 비트 (더티 비트): 페이지 쓰기 시마다 설정
- 수정된 페이지를 더티 페이지라고 함
- 희생자 페이지를 교체 페이지로 복사하기 전에 디스크에 쓰기 여부 결정4단계 페이지 테이블 주소 변환
가상 주소 구성

주소 변환 과정
4단계 주소 변환 과정:
1. CR3 레지스터: L1 페이지 테이블의 물리 주소 포함
2. VPN 1: L1 PTE에 대한 오프셋 제공 → L2 페이지 테이블 베이스 주소
3. VPN 2: L2 PTE에 대한 오프셋 제공 → L3 페이지 테이블 베이스 주소
4. VPN 3: L3 PTE에 대한 오프셋 제공 → L4 페이지 테이블 베이스 주소
5. VPN 4: L4 PTE에 대한 오프셋 제공 → 물리 페이지의 PPN
6. 최종 물리 주소: PPN + VPO9.7.2 Linux 가상 메모리 시스템
Linux 프로세스 가상 메모리 구조
프로세스별 가상 주소 공간
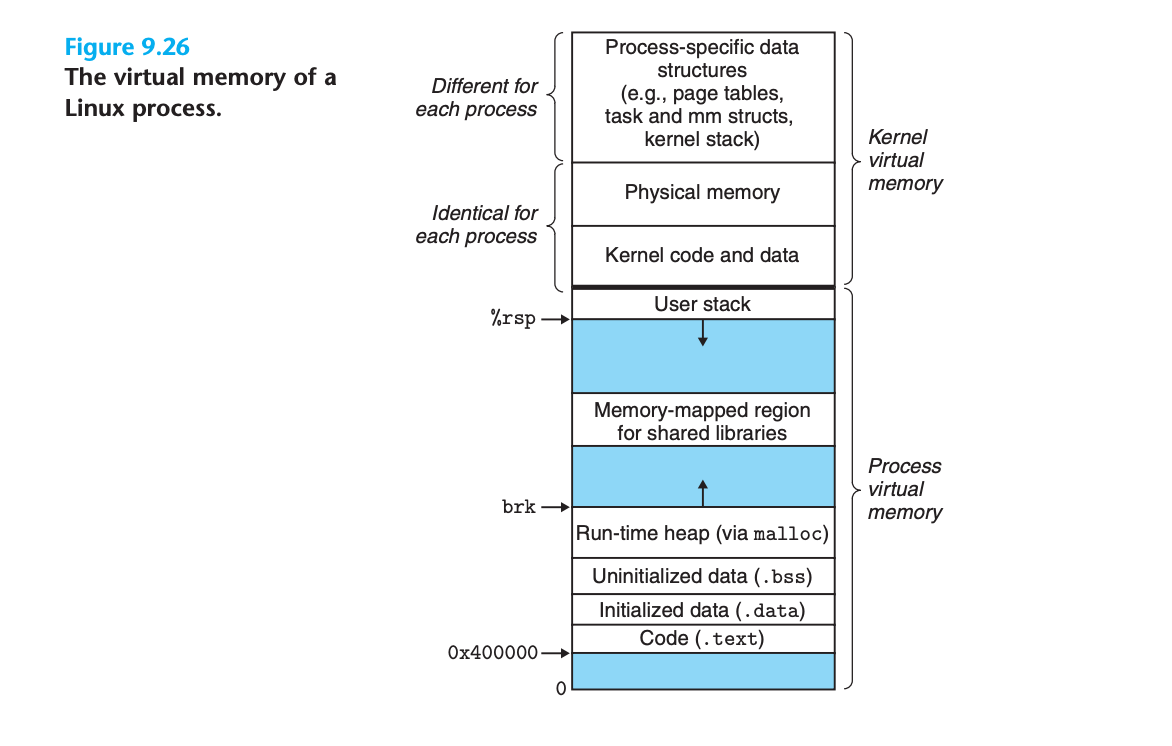
커널 가상 메모리 구성
공유 영역
모든 프로세스가 공유하는 커널 영역:
- 커널의 코드와 전역 데이터 구조
- 연속된 가상 페이지 집합을 연속된 물리 페이지에 매핑
- 시스템의 총 DRAM 크기와 동일한 크기
- 커널이 물리 메모리의 특정 위치에 접근할 수 있는 편리한 방법 제공프로세스별 영역
각 프로세스마다 다른 데이터:
- 페이지 테이블
- 프로세스 컨텍스트에서 커널이 실행할 때 사용하는 스택
- 가상 주소 공간의 현재 구성을 추적하는 다양한 데이터 구조Linux 가상 메모리 영역
가상 메모리 영역 개념
가상 메모리 영역 (Virtual Memory Areas):
- 연속된 기존(할당된) 가상 메모리 청크의 컬렉션
- 페이지들이 어떤 방식으로든 관련된 영역
- 코드 세그먼트, 데이터 세그먼트, 힙, 공유 라이브러리 세그먼트, 사용자 스택 등
- 기존 가상 페이지는 어떤 영역에 포함되어야 함
- 영역의 일부가 아닌 가상 페이지는 존재하지 않으며 프로세스가 참조할 수 없음영역 개념의 중요성
영역 개념의 이점:
1. 가상 주소 공간에 갭 허용
2. 존재하지 않는 가상 페이지 추적 불필요
3. 메모리, 디스크, 커널 자체에서 추가 리소스 소비 없음커널 데이터 구조
가상 메모리 추적 구조
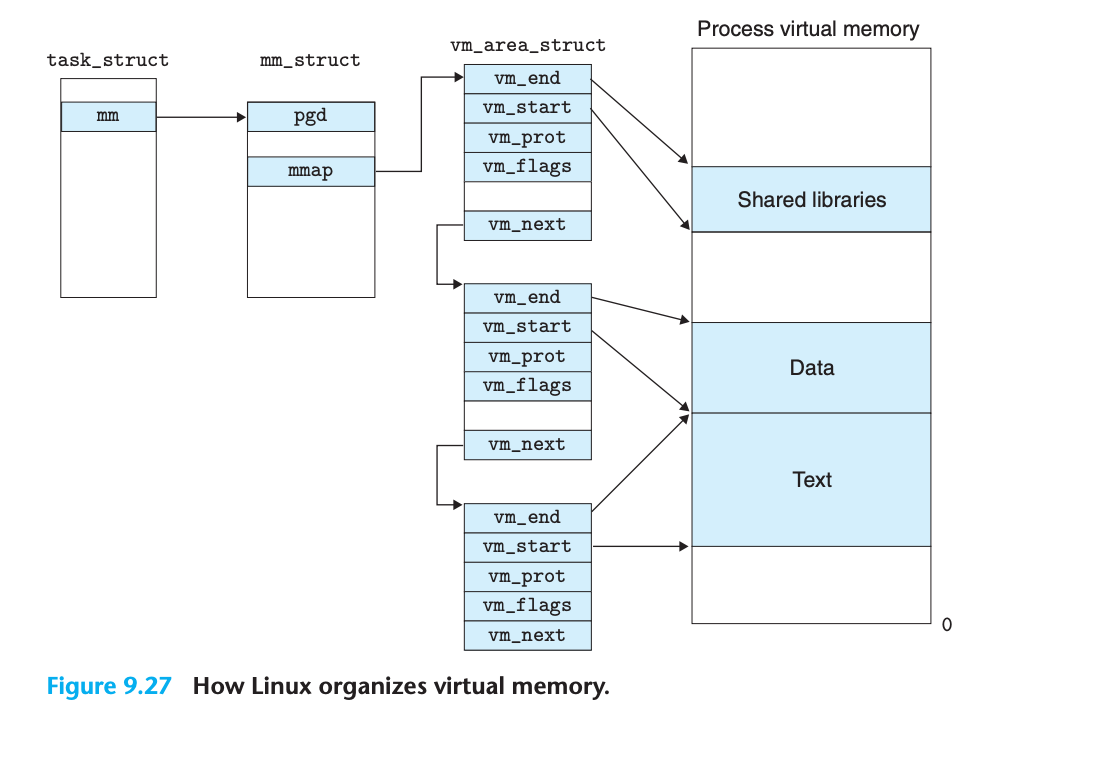
태스크 구조체 (task_struct)
각 프로세스의 고유한 태스크 구조체:
- PID, 사용자 스택 포인터, 실행 가능한 객체 파일 이름, 프로그램 카운터 등
- 커널이 프로세스를 실행하는 데 필요한 모든 정보 포함 또는 가리킴메모리 관리 구조체 (mm_struct)
가상 메모리의 현재 상태를 특성화:
- pgd: 레벨 1 테이블(페이지 글로벌 디렉토리)의 베이스 포인터
- mmap: vm_area_struct 리스트 포인터
- 커널이 이 프로세스를 실행할 때 pgd를 CR3 제어 레지스터에 저장영역 구조체 (vm_area_struct)
특정 영역을 특성화하는 필드들:
- vm_start: 영역의 시작을 가리키는 포인터
- vm_end: 영역의 끝을 가리키는 포인터
- vm_prot: 영역에 포함된 모든 페이지의 읽기/쓰기 권한
- vm_flags: 영역 내 페이지가 다른 프로세스와 공유되는지 또는 이 프로세스에 개인적인지 등
- vm_next: 리스트의 다음 영역 구조체를 가리키는 포인터Linux 페이지 폴트 예외 처리
페이지 폴트 처리 단계
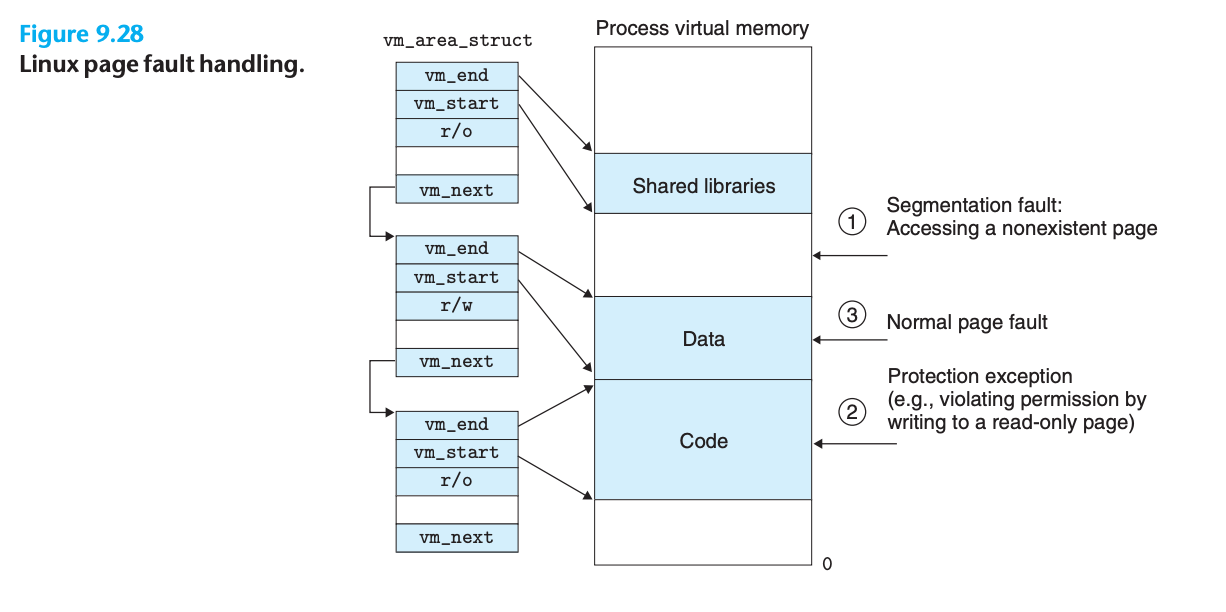
Linux 페이지 폴트 처리 과정:
1단계: 가상 주소 A가 합법적인가?
- A가 어떤 영역 구조체에 의해 정의된 영역 내에 있는가?
- 영역 구조체 리스트를 검색하여 A를 각 영역 구조체의 vm_start, vm_end와 비교
- 합법적이지 않으면 세그멘테이션 폴트 트리거하여 프로세스 종료
2단계: 시도된 메모리 접근이 합법적인가?
- 프로세스가 이 영역의 페이지를 읽기, 쓰기, 실행할 권한이 있는가?
- 예: 읽기 전용 페이지에 쓰기 시도, 사용자 모드에서 커널 가상 메모리 읽기 시도
- 합법적이지 않으면 보호 예외 트리거하여 프로세스 종료
3단계: 이 시점에서 커널은 페이지 폴트가 합법적인 작업과 합법적인 가상 주소에서 발생했음을 알음
- 희생자 페이지 선택
- 더티한 경우 희생자 페이지 스왑 아웃
- 새 페이지 스왑 인
- 페이지 테이블 업데이트
- 페이지 폴트 핸들러 반환 시 CPU가 폴트를 발생시킨 명령어 재시작
- 이번에는 MMU가 A를 정상적으로 변환하여 페이지 폴트 없이 처리최적화된 검색
영역 구조체 검색 최적화:
- 프로세스가 임의의 수의 새 가상 메모리 영역 생성 가능 (mmap 함수 사용)
- 순차 검색이 매우 비용이 클 수 있음
- 실제로는 Linux가 트리를 리스트에 중첩하여 검색 수행종합 요약
9.6 주소 변환의 핵심 개념
주소 변환의 수학적 기반
- 공식적 매핑: VAS → PAS ∪ ∅
- 페이지 테이블 기반 변환: VPN → PTE → PPN
- 하드웨어-소프트웨어 협력: MMU와 운영체제의 긴밀한 협력
성능 최적화 기법
- TLB: PTE 캐싱을 통한 주소 변환 가속
- 물리 주소 캐시: 주소 변환 후 캐시 접근으로 일관성 보장
- 다단계 페이지 테이블: 메모리 효율성을 위한 계층적 구조
엔드투엔드 주소 변환
- 14비트 가상 주소 → 12비트 물리 주소 변환 과정
- TLB 히트/미스, 캐시 히트/미스의 다양한 경로
- 실제 하드웨어 동작을 손으로 시뮬레이션 가능한 수준의 이해
9.7 Intel Core i7/Linux 실제 시스템
Core i7 아키텍처 특징
- 4단계 페이지 테이블 계층: 48비트 가상 주소 공간 지원
- 통합 캐시 계층: L1, L2, L3 캐시와 TLB의 효율적 통합
- 권한 비트 시스템: R/W, U/S, XD 비트를 통한 세밀한 보호
Linux 가상 메모리 관리
- 프로세스별 독립 주소 공간: 격리와 보호의 기반
- 가상 메모리 영역: 효율적인 메모리 관리 추상화
- 페이지 폴트 처리: 3단계 검증을 통한 안전한 메모리 접근
핵심 교훈
가상 메모리의 복잡성과 우아함
- 하드웨어와 소프트웨어의 완벽한 협력
- 성능과 기능성의 균형
- 투명성과 자동화로 프로그래머 부담 최소화
실제 시스템의 설계 원칙
- 계층적 구조: 복잡성을 관리하기 위한 자연스러운 해결책
- 캐싱: 성능 향상을 위한 보편적 기법
- 보호: 시스템 안정성을 위한 필수 요소
가상 메모리는 현대 컴퓨터 시스템의 가장 정교한 메커니즘 중 하나로, 이론적 개념이 실제 하드웨어와 소프트웨어에서 어떻게 구현되는지를 보여주는 완벽한 예시입니다.
아 또 인텔 홍보하넹 CSAPP