
본 포스팅은 이번주 초 ServeTheHome에 올라온, Supermicro 산호세 본사에서 진행한 B300/GB300 기반 컴퓨팅 인프라 솔루션 리뷰글을 토대로 내가 재해석한 정리글이다. 현 AI시대에서, 가장 핵심 플레이어인 NVIDIA가 아키텍쳐를 제시하면, 서버 Vendor들이 1-2년 뒤 이를 실현해 솔루션을 내놓는 Flow를 본 포스팅을 통해 확실히 짚어보고 싶다.
원글의 포인트
글의 주제 의식을 미리 먼저 요약하면 결국 다음과 같다.
최신 AI 서버 환경은 GPU 성능뿐 아니라 Supporting 인프라 (e.g., 네트워킹, 전력, 액체 냉각, 소프트웨어)가 함께 진화했고, 그 변화가 너무 빨라 “무엇이 달라졌는지 따라가기 어렵다.”
그래서 이번 본사 투어를 통해 **오늘날 AI Factory를 구성하는 주요 시스템과 인프라 컴포넌트**를 한 번에 정리해 보자는 흐름이다. B300, GB300을 중심으로!
이 글의 또 다른 큰 축은 Vertical integration, 즉, 수직 통합이다. Supermicro가 단순히 서드파티 부품을 Chassis에 조립하는 수준이 아니라, 서버 노드, Cold Plate, Cooling Manifold, In-row CDU, 랙 후면 Heat Exchanger, 전력 Shelve, 야외 쿨링 타워까지 Full Stack으로 설계/제조하려 한다는 점을 강조한다.
 Supermicro GPU SuperServer SYS 822GS NBRT Front [link]
Supermicro GPU SuperServer SYS 822GS NBRT Front [link] 참고로 서버 제조사별로 HGX B300에 대한 각기 다른 솔루션을 제공하고, 본 글에선 Supermicro 솔루션만 다루고 있다.
원본 글과 영상 (참고로, STH는 유튜브도 열심히 올린다)에 보다 상세한 디테일이 나와 있으니 본 포스팅을 통해 흥미가 생긴 사람은 STH 글을 직접 보길 바란다.
세대 비교의 핵심은 Board-Integrated ConnectX-8
B200에서 B300으로 넘어오면서 가장 눈으로 즉시 보이는 세대 차이는 바로 Front 레이아웃 변화다. NVIDIA는 HGX B300의 아키텍쳐를 아래와 같이 소개한바 있는데,
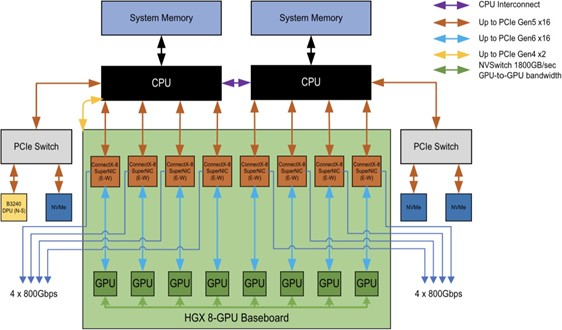 NVIDIA HGX B300 System Architecture [link]
NVIDIA HGX B300 System Architecture [link] 이렇게 생겼다. NIC를 Baseboard 내부 상단에 배치한게 특징인데, GPU/NVSwitch에 최대한 가깝게 배치하려는 의도이다. 이렇게 하면 GPU-direct 네트워크 트래픽을 최적화가 되는데,
CPU
├ NIC
└ GPUGPU → PCIe Switch/CPU → NIC → Network
이런 전통적 Architecture에서,
GPU fabric
├ NIC (GPU communication)
└ CPU (control plane)GPU → NVSwitch → NIC → Network
이런식으로 GPU 중심의 네트워킹을 의도한게 핵심이라고 볼 수 있다. 이 변화는 서버 Chassis에도 직접적으로 드러나게 되는데,
 Supermicro GPU SuperServer SYS 822GS NBRT Front
Supermicro GPU SuperServer SYS 822GS NBRT Front 이전 세대인 B200 세대 공랭 HGX 서버는 전면 하단에 8개의 분리형 NIC (=GPU당 1개, 1:1 페어링 구조)가 보이고, 각 NIC는 400Gbps로 동작하는 구조였다면,
 Supermicro GPU SuperServer SYS 822GS NB3RT Front
Supermicro GPU SuperServer SYS 822GS NB3RT Front 위 사진에서 서버 전면 하단 중앙에 있던 OSFP 포트 8개가 전면 상단에 고루 분포하는 형태로 재배치되었음을 알 수 있다.
現 SOTA인 B300 세대 공랭 HGX 서버는 전면에서 8개의 분리형 NIC가 사라졌음을 알 수 있다. 위와 같이, HGX B300 8-GPU 베이스보드가 네트워킹을 ‘보드 통합’으로 가져왔기 때문으로, ConnectX-8가 전면 슬롯을 차지하지 않게 하여 해당 공간을 공랭을 위한 추가 공간으로 확보하고 대신 800Gbps OSFP 포트를 시스템 상단 쪽에 노출시키게 된 것이다.
뭐 당연한거지만, 아키텍쳐의 변화가 서버의 와꾸(?)를 바꾸는 전형적인 모습이라고 해석할 수 있다.
What If a Liquid-Cooling Is Applied ?
Supermicro에서는 최근 흐름에 맞게 수랭 버전의 솔루션도 같이 제공하고 있는데, B200 수랭 HGX는 공랭 때와 동일하게 분리형 400Gbps NIC 슬롯 (ConnectX-7)이 전면에 존재하는 구조였다면, B300 수랭 HGX는 전면 NIC가 사라지고 GPU당 1개 통합 800Gbps 인터페이스 (Aggregated --> 6.4Tbps)로 바뀌었다.
 Supermicro GPU SuperServer SYS 422GS NB3RT ALC Front
Supermicro GPU SuperServer SYS 422GS NB3RT ALC Front 이러한 서버 와꾸를 계속 강조하면서 글이 말고자 하는 바는 결국 B300 세대의 체감 변화는 HBM 세대/용량(192GBto288GB)뿐만 아니라 네트워킹 아키텍쳐의 변화도 상당한 포션을 차지하고, 이게 실제로도 성능에도 영향을 미칠 수 있음인거 같다.
ORV3 HGX B300 NVL8
Open Rack Version 3 (ORV3)는 Open Compute Project에서 정의한 데이터센터용 서버 랙 표준으로, 48V 전원과 21인치 (--> 서버 보드가 더 넓게 설계될 수 있음) 랙 구조를 채택한게 특징이다.
Supermicro에서는 ORV3 Chassis에 맞춘 HGX B300 솔루션을 아래와 같이 제공한다.
 Supermicro GPU SuperServer SYS 222GS NB3OT ALC Top
Supermicro GPU SuperServer SYS 222GS NB3OT ALC Top 2U ORV3 NVL8 섀시는 48U ORV3 랙에 최대 144 GPU를 수용할 수 있다고 한다 (아래 사진 중앙 랙처럼). 이렇게 구축한 ORV3 랙스케일 인프라는 NVL72와 공유/호환될 수 있다고 한다.

 "Nvidia's DGX GB200 NVL72 is a rack scale system that uses NVLink to mesh 72 Blackwell accelerators into one big GPU" [link]
"Nvidia's DGX GB200 NVL72 is a rack scale system that uses NVLink to mesh 72 Blackwell accelerators into one big GPU" [link] GB300 NVL72 Rack-Scale Computing Platform
요즘 핫한 NVL72는 Rack-Scale Computer를 표방한다. 가장 차세대는 얼마전 공개된 Vera Rubin (VR) NVL72/144인데, 그건 내후년 즈음에 실제 Deploy될 터이니, 현시점에서 실 운영 환경에서의 SOTA는 GB300 NVL72라고 보면 된다.
GB300 NVL72는 72개의 Blackwell Ultra GPU + Grace CPU가 18개의 컴퓨트 노드로 구성된다. 한 Rack에는 NVLink 스위칭 패브릭, ConnectX-8, 전력 인프라, 액체 냉각이 포함되고, 이 전체가 하나의 통합 형태로 서비스된다.
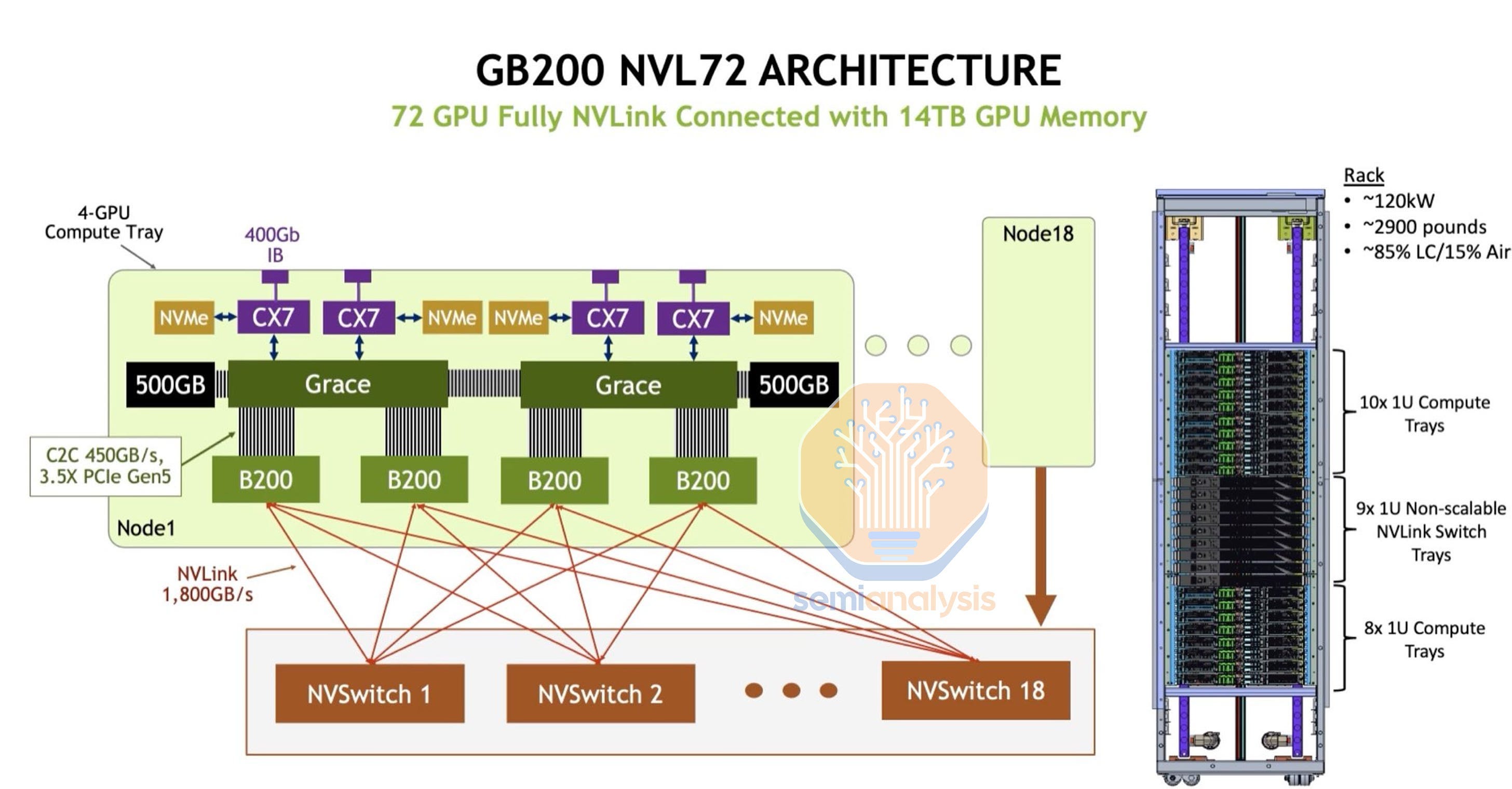 GB200 NVL72 아키텍쳐 [link]
GB200 NVL72 아키텍쳐 [link] 한 세대 전 아키텍쳐긴 하지만 기본적으로는 유사하기 때문에 그냥 갖고 와봤다. 한 컴퓨팅 노드에 2 개의 Grace CPU, 4개의 B200 GPU가 있고, ConnectX-7 4개가 Paired 구조로 배치되어 400Gbps 대역폭을 각 제공한다. Local NVMe도 들어 있다. 이런 컴퓨팅 노드 18개 한 ORV3 Rack에 NVLink Switch와 함께 들어가는게 바로 NVL72다.
슈퍼마이크로에서 이러한 GB300 NVL72 솔루션을 설계/구현/검증을 완료했다고 한다 (아래 사진).
 The Supermicro NVIDIA GB300 NVL72 Rack [link]
The Supermicro NVIDIA GB300 NVL72 Rack [link] NVL72 Network Breakdown
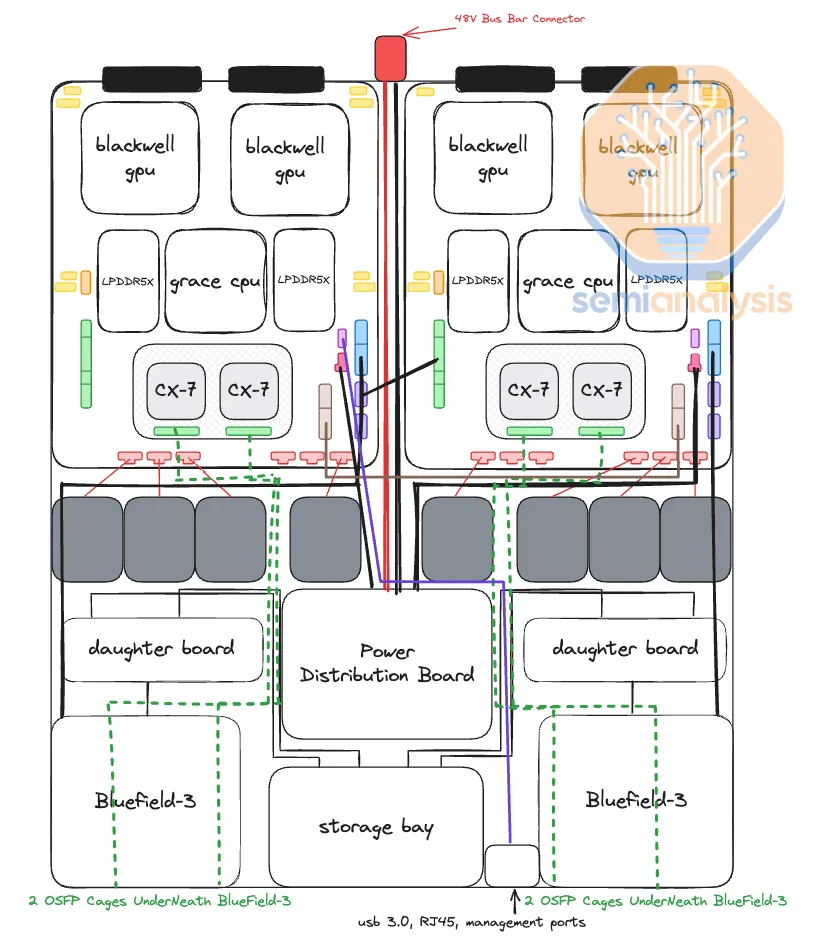 GB200 NVL72 Compute Tray 내부 Architecture [link]
GB200 NVL72 Compute Tray 내부 Architecture [link] 마찬가지로 한 세대 전이긴 하지만, NVL72의 기본적 철학은 GB200부터 GB300, 그리고 차세대인 VR까지 크게 변화하는건 없다. 두 개의 핵심 유닛이 있고 각 유닛엔 2개 GPU와 1개 Arm CPU가 부착된다. LPDDR이 CPU Memory 역할을 한다. 두 유닛 외에 섀시 안에 BlueField DPU와 NVMe SSD가 꼽힐 수 있다.
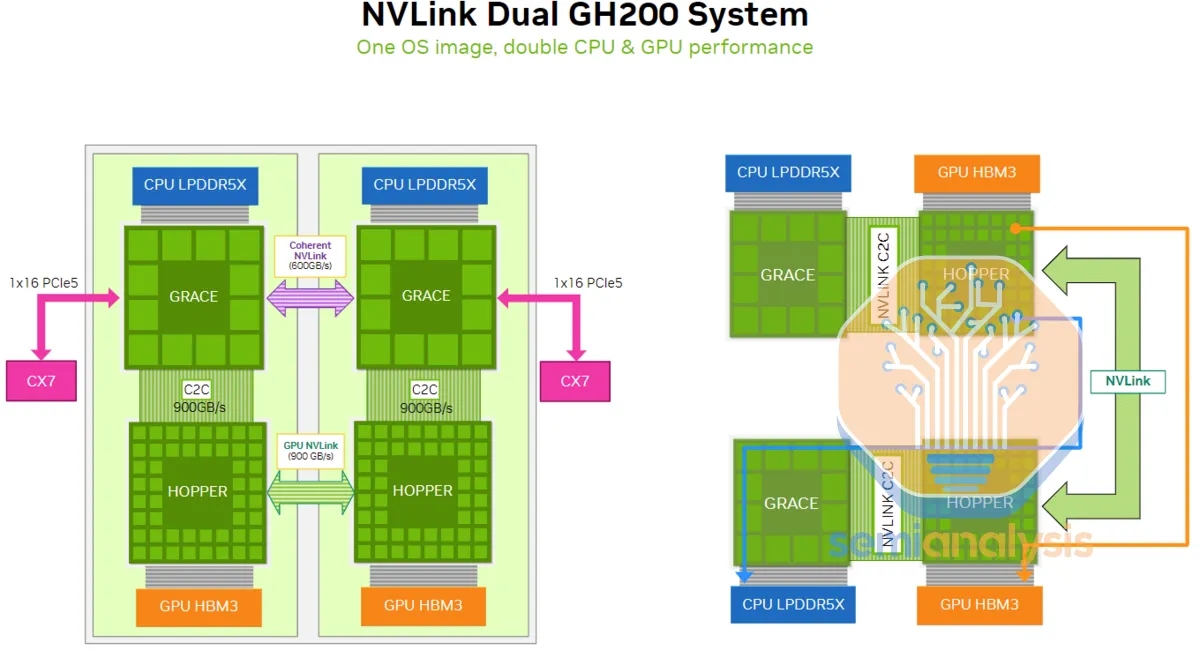 NVLink Dual GH200 System [link]
NVLink Dual GH200 System [link] 이것은 GH200 시절 그림이지만 역시 크게 변한건 없다. 위에서 말한 핵심 유닛 내부의 NVLink, ConnectX, C2C Inteconnect의 역할을 명확히 이해할 수 있다.
GB300 NVL72의 핵심 네트워킹 역할을 정리해보면 다음과 같다.
- NVLink (랙 내부 / 노드 내부): Rack 관점에서 보면 NVL72 랙 후면의 NVLink 스파인이 72 GPU를 단일 패브릭으로 묶어 하나의 큰 GPU처럼 동작하게 만든다. 노드 관점에서는 한 컴퓨트 유닛 내에 두 GPU간 통신에 쓰인다.
- ConnectX-8 (랙-대-랙 Scale-Out / east‑west 확장): 각 컴퓨트 노드는 ConnectX-8 네트워킹을 갖고 있고, 한 랙이 부족할 때 랙 간을 고속 스위치로 연결해 논리적 GPU 경계를 여러 랙으로 확장한다.
- Spectrum-4 / Spectrum‑X (Ethernet 스위칭 패브릭): 위에서 따로 언급은 안했지만 NVL72에는 Spectrum‑4 스위치도 들어간다. GB300 NVL72 기준 64포트 800GbE이다 (2×400Gbps 분할 가능).
- 이 스위치가 랙 내 ConnectX-8 업링크를 Aggregation해 외부/추가 랙으로 연결하는 역할을 수행한다.
- BlueField‑3 (north‑south: 스토리지 접근): 위 그림처럼 BlueField‑3 DPU도 컴퓨트 노드에 탑재될 수 있는데, 그 경우 NVL72 랙에서 north‑south 트래픽을 담당한다. 이는 GPU 클러스터 바깥의 스토리지 접근 시 사용된다.
- 즉, east‑west는 NVLink+ConnectX-8, north‑south는 BlueField‑3 역할 분담 형태임.
- 관련해서, 이전 ICMS 포스팅과 연결해서 이해해보면 좋다.
GB300 NVL72 공개 시점에선 ICMS가 알려진 상태가 아니었기에 이 BlueField-3 DPU의 존재 역할이 애매했던게 사실이다. 사실 외부 스토리지 접근은 당연하게도 그냥 ConnectX 붙여서 처리해도 되기 때문이다.
이전 포스팅에서도 언급했지만, 올초 공개된 ICMS는 바로 이런 N년간의 여러 의문에 NVIDIA가 명확한 Usecase를 제시한 사례라고 볼 수 있다.
 NVIDIA NVL144 Reference Systems [link]
NVIDIA NVL144 Reference Systems [link] 최좌측의 4개의 Rack은 Spectrum-X CPO 스위치로 Backend RDMA Fabric으로서 랙간 통신을 통제한다. 중간의 8개 Rack은 VR200 NVL144이다 (CPX라는 새로운 칩 기반의 추론 전용 NVL인데, 본 포스팅에서 추가 설명은 생략한다. 학습까지 하는 클러스터라고 보면 이게 그냥 NVL72라고 보면 된다, 세대 구분 없이). 그 다음 우측 두 랙이 바로 ICMS 기반의 Enclosure들이 붙는 위치라고 보면 된다.
NVL72 냉각 시스템
슈퍼마이크로 솔루션에서 냉각은 다음 요소들이 담당한다.
- Manifold / Blind-mate
- 랙 내부에서 냉각수를 각 서버로 분배하는 배관 구조.
- 블라인드-메이트는 서버를 밀어 넣으면 자동으로 냉각수와 전원이 연결되게 하는 구조.

- In-row CDU (Cooling Distribution Unit)
- 여러 랙을 묶어 냉각수 순환을 관리하는 중앙 장치.
- 펌프·온도·유량·pH 등을 관리하며 클러스터 단위 수랭 시스템의 핵심 역할을 한다.

- Rear Door Heat Exchanger
- 수랭 이후에도 남는 공기 열(잔열)을 잡는 장치.
- 랙 뒤에서 공기를 통과시키며 2차 냉각수로 열을 회수한다.

- Liquid-to-Air Sidecar
- 수랭 인프라가 없는 데이터센터에서도 사용할 수 있게 수랭 → 공랭으로 열을 변환해주는 장치.

- 수랭 인프라가 없는 데이터센터에서도 사용할 수 있게 수랭 → 공랭으로 열을 변환해주는 장치.
- Cooling Tower
- 데이터센터 밖에서 최종적으로 열을 외부 공기로 방출하는 단계.
- 가열된 시설수를 식혀 다시 냉각 루프로 보내는 역할.

NVIDIA - 서버 Vendor - 소비자
AI 서비스를 자체 환경을 구축해 구동하고 싶은 소비자는 시스템 설계 하는데에 많은 고민을 할 수 밖에 없다. 그것이 곧 직접적인 Cost로 돌아오기 때문이다.
NVIDIA는 그러한 소비자들의 고민, 걱정을 포착해 몇년전부터 Rack-Scale 플랫폼, 즉, 아예 통째로 답을 제공하는 그림을 그려오고 있다. 이에 맞춰 서버 Vendor들도 발빠르게 솔루션을 내놓았다.
물론, 본 포스팅에서 알 수 있듯 랙스케일 외에도 개별 전통적 솔루션들이 많이 있다. 즉, 여전히 내 입맛에 맞춰서 클러스터를 구성하고 설계할 수 있다.
이제 선택권은 소비자에게 있다. 무엇이 경제적 아키텍쳐, 시스템일지는 그들이, 또는 그들이 의뢰한 데이터센터 구축자들이 판단하게 될 것이다. 앞으로 어떤 시장 흐름이 펼쳐지게 될지 흥미로운 포인트이다.
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
