CNN(Convolutional neural network), 합성곱 신경망
시각적 영상 분석에 주로 적용된다. 영상 및 동영상 인식, 추천 시스템, 영상 분류, 의료 영상 분석 및 자연어 처리 등에 응용된다.
한 사진은 3차원, 여러 사진 4차원일 때 사진 데이터를 1차원 형식으로 만든다. 겹겹이 쌓이는 층으로 구성된다.
합성곱 신경망은 크게 합성곱층(Convolution layer)과 풀링층(Pooling layer)으로 구성된다.
합성곱층은 이미지 특징을 추출하는 역할이며, 풀링층은 필터를 거친 여러 특징 중 가장 중요한 특징 하나를 골라냅니다. 덜 중요한 특징을 버리기에 차원이 감소한다.
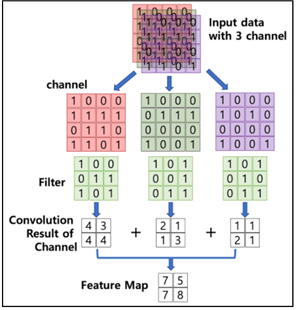
위의 그림에서 input data는 (4,4,3)->필터는 총 (3,3,3), 각각의 필터는 (3,3)-> 피처맵 (2,2)X3
-> 총 피처맵 (2,2)
출력값 channel 늘리기 위해서는 개수를 늘린다. 여기서말하는 개수는 필터가 (3,3,3)X5 일 때 피처맵은 (2,2)X5가 된다. 개수는 5를 뜻한다.
-
커널 또는 필터
필터를 통해 이미지 특징을 추출한다. 합성곱 연산은 입력데이터에 필터를 적용한다. 입력과 필터에서 대응하는 원소끼리 곱한 후 총합을 구한다. 이를 통해 이미지 feature map을 만들 수 있다.
이미지가 필터를 거친 것->Filter map(특징 맵)-> 활성화 함수를 이용해서 특징 추출
필터를 0~1 사이로 초기화(시키면 컴퓨터가 알아서 위에 사진처럼 만들어줌) 후 image에 필터 입히면 feature map 된다. -
stride
움직임 값을 조절하는 값 -
풀링층
추출한 특징을 값 하나로 추려내서 특징 맵의 크기를 줄여주고 중요한 특징을 강조하는 역할이다. 보통 평균이나 최댓값을 가져온다. 겹치지 않게 움직인다. pooling layer는 선택적인 레이어다. 학습 파라미터가 없고, 채널 수 변경이 없다. -
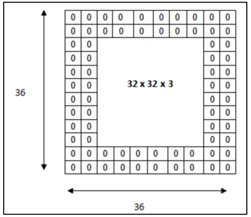
패딩
출력 크기가 줄어드는 것을 방지하기 위해 사용된다. 원데이터의 크기를 늘리는 것. 이미지는 합성곱을 통해 차원이 축소되기에 원데이터 이미지크기를 0을 넣어서 늘려줘야 한다.
ex) a*1/2=b라고 가정할 때, b값은 무조건 작아질 수 밖에 없잖아! 그럼 이걸 되풀이하다보면 출력 크기가 1이 되어 문제가 될 수 있다.
CNN 모델 케라스 코드
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
model = Sequential()
model.add(Conv2D(12, kernel_size=(5, 5), activation='relu', input_shape=(120, 60, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(16, kernel_size=(5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(20, kernel_size=(4, 4), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(4, activation='softmax'))계산방법
convolution layer 출력 데이터 크기
outputheight=((input height2padding size- filter height)/stride size)+1
outputweight=((input weight2padding size- filter weight)/stride size)+1
pooling layer 출력 데이터 크기
output row size=input row size/ pooling size
output col size= input col size/ pooling size
- convolution layer
입력데이터 shape=(120,60,1)
입력채널=1
필터 (5,5)
출력채널 =12
stride=1
convolution layer 1의 activation map 크기 계산
row size=((120-5)/stride)+1=116
col size=((60-5)/stride)+1=56
출력데이터 shape은 (116,56,12)
학습파라미터는 300개 (1X5 X5 X12) 입력채널수X 필터 폭 X필터높이 X출력채널수
- max pooling layer
입력데이터 shape=(116,56,12)
max pooling size=(2,2)
row size=116/2=58
col size=56/2=28
출력 데이터 shape은 (58,28,12) * max pooling layer에서 학습파라미터가 없다.
-
colvoluton layer –앞과 똑같은 계산
입력채널 12
출력채널 =16
.
.
. -
flatten layer
ex) 입력데이터 shape=(2,1,80)
출력데이터 shape=(160,1) -
softmax layer
출력데이터 : (4,1) *분류클래스가 4개이기 때문에
