들어가며
오늘은 다양한 트랜스포머 모델들을 소개할 예정이다. 본격적으로 트랜스포머 모델들을 알아보기 이전에 트랜스포머 모델이 무엇인지가 궁금하면 아래의 링크를 통해서 살펴볼 수 있을 것이다.
이러한 트랜스포머 모델의 구조는 크게 세가지로 나눌 수 있다. 인코더, 인코더-디코더, 디코더이다. 각각 구조에는 아래의 가계도와 같이 여러 모델들이 있다. 지금부터 본격적으로 이 모델들에 대해서 알아보도록 하겠다.
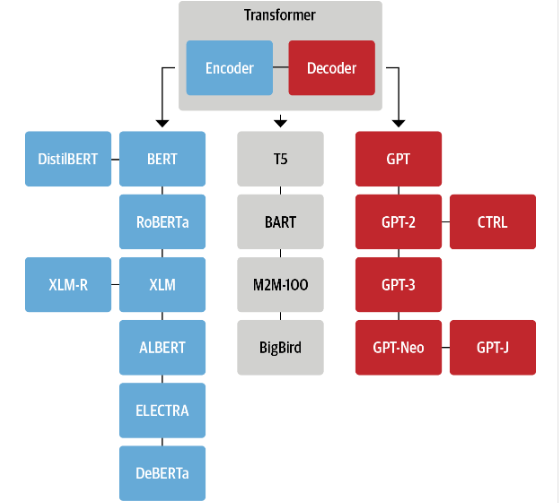
1. 인코더 구조
인코더 구조의 대표적인 모델은 바로 BERT이다. BERT는 공개될 당시 GLUE 벤치마크에서 최상의 모델을 모두 능가했었다. 이러한 인코더 구조의 모델은 자연어를 이해하는 NLU 작업에 지배적으로 적용된다. 대표적인 Task로는 개체명 인식, 텍스트 분류, Q&A가 있다.
BERT
가장 먼저 알아볼 모델은 인코더 구조의 대표적인 모델인 BERT이다. BERT의 사전 훈련 목표는 두가지로 나뉜다. 첫번째는 마스크드 언어 모델링(MLM)로 텍스트에서 마스킹된 토큰을 예측하는 것이다. 두번째는 다음 문장 예측(NSP) 한 텍스트 구절이 다른 텍스트 구절 뒤에 나올 확률을 판단하는 것이다.
DistilBERT
DistilBERT는 BERT의 모델의 크기가 크기 때문에 시간이 오래걸린다는 단점을 보완한 모델이다. 사전 훈련 과정에서 지식 정제라는 기술을 사용해서 BERT보다 40% 더 적은 메모리를 사용하고 60% 더 빠르면서 BERT 성능의 97%를 달성했다. 따라서 지연시간이 짧아야 되는 환경에서 유용하게 모델을 배포할 수 있을 것이다.
RoBERTa
RoBERTa는 BERT보다 더 많은 데이터와 더 큰 배치에서 더 오래 모델 훈련을 진행하여 성능을 크게 향상시켰다. 참고로 여기서 NSP 기법은 사용하지 않았다.
XLM
XLM(cross-lingual language)은 BERT의 MLM과 GPT 유사 모델의 자기회귀 언어 모델링을 포함해 다중 언어 모델을 만들기 위한 사전 훈련 방법으로 연구되었다. 추가로 MLM을 다중 언어 입력으로 확장한 TLM(translation language modeling)도 발표했다.
XLM-RoBERTa
XLM에 RoBERTa 개념을 적용하여 훈련 데이터를 대규모로 확장하여 다중 언어 사전 훈련을 한 모델이다. XLM과 다른점이 있다면 데이터셋에서 상대 텍스트(번역)가 없는 데이터만 포함하기 때문에 TML 목표가 제외되었다.
ALBERT
이 모델은 인코더 모델 구조 자체를 개선하여 보다 더 효율적으로 만들었다.
- 은닉 차원에서 토큰 임베딩 차원을 분리해 임베딩 차원을 줄여 어휘사전이 큰 경우 파라미터가 절약된다.
- 모든 층이 동일한 파라미터를 공유함으로써 실제 파라미터 개수를 크게 줄인다.
- NSP 목표를 문장 순서 예측으로 바꾼다. 즉 모델은 두 문장이 함께 속해 있는지가 아니라 연속된 두 문장의 순서가 바뀌었는지를 예측한다.
이로인해 더 적은 파라미터로 더 큰 모델을 훈련할 수 있다.
ELECTRA
ELECTRA는 기존의 표준적인 MLM 사전 훈련이 각 훈련 스텝에서 마스킹된 토큰 표현만 업데이트되고 그 외 입력 토큰은 업데이트 되지 않는다는 제약을 개선한 모델이다. 이를 개선하기 위해서는 두 개의 모델을 사용한다. 첫 번째는 기존과 같이 표준화된 MLM처럼 마스킹된 토큰을 예측한다. 두 번째 모델은 판별자라고 불리는데 첫 번째 모델의 출력에 있는 트큰 중에 어떤 것이 원래 마스킹된 것인지 예측한다. 이러한 판별자는 모든 토큰에 이진 분류를 수행하고 이를 통해서 훈련 효율을 30배 높이게 된다. 판별자는 후속 작은을 위해 표준 BERT 모델처럼 미세튜닝된다.
DeBERTa
DeBERTa는 각 토큰이 두 개의 벡터로 표현되고, 토큰 디코딩 헤드의 소프트맥스 층 직전에 절대 위치 임베딩을 추가하였다. 각 토큰을 두개의 벡터로 표현한 이유는 콘텐층과 상대 위치를 위한 것으로 분리하기 위함이다. 이렇게 되면 셀프 어텐션 층이 인접한 토큰 쌍의 의존성을 더 잘 모델링하게 된다. 그리고 마지막으로 토큰 디코딩 헤드의 소프트맥스 층 직전에 절대 위치를 임베딩해준 것이다.
2. 디코더 구조
디코더 구조의 모델이라하면 가장 먼저 떠오르는 것은 chatGPT이다. 이런 모델은 문장에서 다음 단어를 예측하는데 뛰어나 대부분 텍스트 생성 작업에 사용된다. openAI에서 모델과 데이터의 크기를 계속해서 늘리며 엄청난 속도로 발전하고 있는 분야이다.
GPT
GPT는 디코더 구조와 전이 학습을 결합해 이전 단어를 기반으로 다음 단어를 예측하도록 훈련된다. GPT는 초기버전으로 시간이 지나면서 GPT-2, GPT-3까지 나왔으며 곧 GPT-4가 출시될 예정인데 소문으로는 100조개의 파라미터를 사용했으며 텍스트 데이터를 넘어 비디오, 음성, 이미지등 다양한 데이터를 활용했다고 한다.
GPT-2
GPT의 모델 파라미터와 데이터를 확장해서 만든 모델이다. GPT-2의 특징으로는 일관성 있는 긴 텍스트 시퀀스를 만든다는 것이다.
CTRL
GPT-2와 같은 모델은 입력 시퀀스(prompt)의 뒤를 잇는다. 하지만 생성된 시퀀스의 스타일은 거의 제어하지 못한다. 그래서 나온 것이 CTRL이다. 이 모델은 시퀀스 시작 부분에 '제어 토큰'을 추가해 생성 문장의 스타일을 제어해 다양한 문장을 생성한다.
GPT-3
GPT-3는 계산량, 데이터셋 크기, 모델 크기, 언어 모델 성능의 관계를 관장하는 거듭제곱 규칙을 발견한 것에 착안해 GPT-2를 100배 늘려 1750억 개의 파라미터를 사용하여 만들었다. 이 모델은 현재 chatGPT의 기반이 되었으며 퓨샷학습능력도 갖췄다.
GPT-Neo/GPT-J-6B
이 모델은 GPT유사 모델이다. 기존의 GPT-3의 규모가 너무 크기 때문에 이를 더 작은 버전인 13억 개, 27억 개, 60억 개 파라미터등으로 줄인 것이다.
3. 인코더-디코더 구조
seq2seq 구조로 원래 트랜스포머 모델의 정석 구조이다. 이를 통해 NLU와 NLG 모든 분야에서 사용이 용이하다.
T5
T5 모델은 모든 NLU와 NLG 작업을 text2text작업으로 변환해 통합한다. 이 모델은 대규모로 크롤링된 C4 데이터셋을 사용하며 text2text 작업으로 변환된 SuperGLUE 작업과 마스크드 언어 모델링으로 사전 훈련된다.
BART
BART는 인코더에는 BERT, 디코더에는 GPT를 사용하여 입력 시퀀스에서 간단한 마스킹, 문장 섞기, 토큰 삭제, 문서 순환등 다양한 변환 중 하나를 거친다. 그리고 변경된 입력이 인코더를 통과하면 디코더는 원본 텍스트를 재구성한다. 이는 모델을 더 유연하게 만들어 NLU와 NLG 작업에 모두 사용할 수 있다.
M2M-100
M2M-100은 100개 언어를 번역하는 최초의 번역 모델이다. 희귀하거나 잘 알려지지 않은 언어에서 고품질의 번역을 구행한다. 이 모델의 특징으로는 접두어 토큰을 사용해 소스 언어와 타킷 언어를 나타낸다.
BigBird
트랜스포머 모델은 최대 문맥 크기라는 제약이 있다. 어텐션 메커니즘에 필요한 메모리가 시퀀스 길이의 제곱에 비례하기 때문이다. BigBird는 선형적인 크기가 늘어나는 희소 어텐션을 사용해 이 문제를 해결했다. 그래서 문맥 크기가 대부분 BERT 모델에서 사용한느 512토큰에서 4,096으로 크게 늘어난다. 특히 텍스트 요약과 같이 긴 의존성을 보존해야 할 때 유용하다.
마치며
지금까지 다양한 Modern NLP 모델들에 대해서 살펴보았다. 이를 기반으로 앞으로 다양한 Task를 사용하게 될 것인데 Task에 맞는 적절한 모델들을 선택하는 데 도움이 되었으면 좋겠다.
