
본 블로그 글은 박동민·강영민 저자님의 으뜸파이썬 교재를 참고하여 만들어진 글임을 밝힙니다.
넘파이 (Numpy)
- 파이썬에서 과학 계산을 위한 대표적인 라이브러리이다.
- 다차원 배열 객체인
ndarray를 제공하며, 이를 기반으로 다양한 수학, 통계, 선형대수 연산을 효율적으로 수행할 수 있도록 설계되어있다. - 주로 대규모 데이터 처리와 배열 연산(내부적으로 C로 구현되어 있기 때문)을 빠르게 수행해야 하는 경우에 사용된다.
- pandas, matplotlib, skit-learn, tensorflow, pytorch 등 numpy 배열 기반으로 동작
실습
라이브러리 설치
pip install numpyndarray 생성 및 사용
- ndarray 속성 목록
속성 설명 반환값 예시 ndarray.ndim배열의 차원(랭크)을 반환함. 1차원, 2차원 등 배열의 구조를 나타냄 1 (1차원 배열), 2 (2차원 배열) ndarray.shape배열의 크기를 튜플로 반환함. 각 차원의 크기를 나타냄 (3, 4) (3행 4열의 2차원 배열) ndarray.size배열의 총 원소 개수를 반환함, shape의 모든 값을 곱한 값과 동일12 (총 원소 개수: 3 × 4) ndarray.dtype배열 원소의 데이터 타입을 반환함 int32,float64,bool등ndarray.itemsize배열의 각 원소가 차지하는 메모리 크기(바이트 단위) 4 (int32), 8 (float64) ndarray.nbytes배열 전체가 차지하는 메모리 크기(바이트 단위). size * itemsize와 같음48 (3×4 배열, 원소당 4바이트) ndarray.T배열의 전치(transpose) 결과를 반환함, 행과 열을 바꿈 [[1, 3], [2, 4]] (전치 행렬) ndarray.flat배열의 원소를 1차원으로 펼쳐 반환하는 이터레이터(iterator) [1, 2, 3, 4](1차원 형태)ndarray.real배열의 실수(real) 부분만 반환함, 복소수 배열에서 유용함 [1.0, 2.0](실수만 출력)ndarray.imag배열의 허수(imaginary) 부분만 반환함 [0.0, 1.0](허수부 출력)
import numpy as np
a = np.array([1,2,3]) # 벡터 생성
print(a) # array([1, 2, 3])
print(a.shape) # (3,)
print(a.ndim) # 1
print(a.dtype) # dtype('int32')
print(a.itemsize) # 4
print(a.size) # 3- np.array(object, dtype)
- ndarray 생성 시 반드시, 리스트와 튜플 같은 시퀸스 자료값을 넘겨 줘야한다.
- dtype의 값으로 배열 원소의 데이터 타입을 명시적으로 지정이 가능하다.
벡터와 행렬 연산
- vectorization 연산 : 원소끼리의 연산이 이루어지는 것
- 배열의 크기가 같아야 하며, 동일한 위치의 원소끼리 계산
- 연산: 덧셈(
+), 뺄셈(-), 곱셈(*), 나눗셈(/) 등
- broadcasting 연산 : 모든 원소에 대해 같은 연산을 적용
- 배열의 크기가 다를 때도 연산이 가능하도록 작은 배열을 자동으로 확장
- 작은 배열의 크기를 큰 배열의 크기에 맞춰 자동 확장하여 연산
- Matrix Multiplication 연산 : 첫 번째 행렬의 행(row)과 두 번째 행렬의 열(column) 간의 내적(dot product)을 계산하여 새로운 행렬을 생성하는 연산
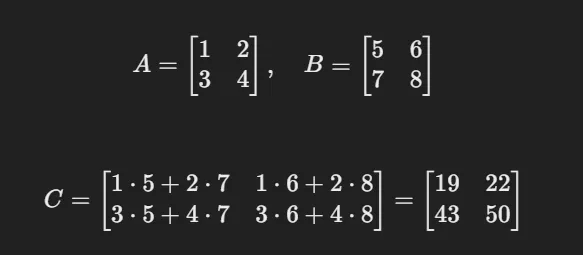
- @ 연산자 또는 np.matmul() 사용
# vectorization 연산 예시
import numpy as np
math_score = np.array([80, 73, 20, 100])
english_score = np.array([40, 33, 30, 60])
total_score = math_score + english_score
avg_score = total_score / 2
print(total_score) # [120 106 50 160]
print(avg_score) # [60. 53. 25. 80.]# broadcasting 연산 예시 : 배열과 스칼라 간 연산
arr = np.array([1, 2, 3, 4])
result = arr + 10 # 모든 원소에 10을 더함
print("Broadcasting Result:", result) # [11 12 13 14]# 행렬 곱
A = np.array([[1, 2], [3, 4]]) # 2x2 행렬
B = np.array([[5, 6], [7, 8]]) # 2x2 행렬
result = A @ B # 또는 np.matmul(A, B)
print("Matrix Multiplication Result:\n", result)
# [[19 22]
# [43 50]]
ndarray 메소드
min(): 최솟값 반환max(): 최댓값 반환mean(): 평균값 반환sum(): 특정 축을 따라 배열의 원소합을 계산
min, max, mean, sum 등의 경우 축을 기준으로 연산이 가능
- axis = 0 : 열 방향으로 값들로 계산
- axis = 1 : 행 방향으로 값들로 계산
flatten(): 행렬을 1차원 배열로 평탄화
numpy 함수
np.append(): 기존 배열에 새로운 원소를 추가하여 새로운 배열을 반환axis=None(기본값) :배열을 1차원으로 평탄화(flatten)한 후 값 추가axis=0: 열 방향으로 값 추가axis=1: 행 방향으로 값 추가
주의: axis를 지정하면 추가할 값의 차원이 기존 배열과 일치해야 함
np.linspace(): 지정된 구간에서 등간격의 숫자를 생성하여 배열로 반환np.arange(): 주어진 범위 내에서 등차수열을 생성하여 배열로 반환
- range()와 동일하지만, step에 실수를 사용할 수 있다.
np.reshape(): 배열의 형태(shape)를 변경하여 새로운 배열을 반환
- 원본 배열의 데이터는 그대로 유지되며, 새로운 형태로 재배치
- 주어진 차원 크기의 곱은 원본 배열의 원소 개수와 일치해야 함
np.transpose(): 전치 행렬을 만든다.np.insert(): 지정한 위치에 값을 삽입하여 새로운 배열을 반환
- np.insert(arr, obj, values, axis=None) 형태
| **매개변수** | **설명** |
| --- | --- |
| **`arr`** | 원본 배열 |
| **`obj`** | 값을 삽입할 위치 (인덱스 또는 인덱스의 리스트) |
| **`values`** | 삽입할 값 (스칼라, 리스트 또는 배열) |
| **`axis`** | 삽입할 축. **`None`**이면 배열을 평탄화한 후 삽입. 기본값은 **`None`** |random 모듈
random.rand(): 0과 1 사이의 균등분포(Uniform Distribution)를 따르는 난수를 생성- 주어진 형태(차원)의 배열에 난수를 생성하여 반환
random.random()과 기능적으로는 동일
random.randn(): 평균이 0이고 표준편차가 1인 정규분포(Normal Distribution)를 따르는 난수를 생성구분 random.randomrandom.rand난수 생성 범위 [0, 1) [0, 1) 차원 지정 방식 size=(dim1, dim2, ...)로 지정차원을 위치 인수로 직접 지정 스칼라 생성 size=None인수 없이 호출 다차원 배열 생성 방식 명시적으로 size인수에 튜플 전달위치 인수로 차원을 전달 random.randint(): start와 end-1 사이에 해당하는 size 개수만큼 생성
다양한 ndarray 행렬 생성
np.zeros((n, m)): 초기값을 0으로하는 n x m 배열 생성np.ones((n, m)): 초기값을 1로 하는 n×m 배열 생성np.full((n, m), x): 초기값을 x로 하는 n×m 배열 생성np.eye(n): 초기값을 단위 행렬로 하는 n×n 배열 생성 (identity matrix)
(참고) 헷갈리는 행, 열 표현 정리
- 데이터 분석과 배열 연산에서 "행", "열", "가로", "세로" 등의 용어는 자주 사용되지만, 서로 혼용되거나 문맥에 따라 달리 사용될 수 있어 혼란을 줄 수 있다.
- 아래는 NumPy 배열에서 차원이 증가함에 따라 축(Axis)과 방향을 정리한 표이다.
차원 축 번호 (Axis) 설명 방향 정의 1차원 axis=0배열의 유일한 축 가로 (왼쪽 → 오른쪽) 2차원 axis=0배열의 행(row)이 늘어나는 방향 세로 (위 → 아래) axis=1배열의 열(column)이 늘어나는 방향 가로 (왼쪽 → 오른쪽) 3차원 axis=0배열의 깊이(depth)가 늘어나는 방향 층 방향 (앞 → 뒤) axis=1배열의 행(row)이 늘어나는 방향 세로 (위 → 아래) axis=2배열의 열(column)이 늘어나는 방향 가로 (왼쪽 → 오른쪽) 4차원 axis=0배치(batch)가 늘어나는 방향 배치 방향 (가장 바깥쪽) axis=1채널(channel)이 늘어나는 방향 깊이 (앞 → 뒤) axis=2행(row)이 늘어나는 방향 세로 (위 → 아래) axis=3열(column)이 늘어나는 방향 가로 (왼쪽 → 오른쪽)

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.