Overview
- paper link (ACL submitted version)
- Accepted in ACL, 2019.
- Washington University & Allen Institute
- NLP area : Especially in NLI(Natural Language Inference)

Why I pick this paper?
- NLP is the field I am researching. Unlike recent studies with high model accuracy, this paper analyzes various cases to explore what should be studied to improve NLI capabilities during the earlier stages when model accuracy was not as high.
- Therefore, I became curious about the approaches taken in the past to enhance model capabilities.
- One of the authors, Prof. Yejin Choi, is someone I greatly respect, and I hope to use this opportunity to learn more about her research in detail.
Introduction

-
As shown in Fig. 1, when presented with a question like, "Imagine a woman chasing a dog around outside, trying to give it a bath. What might happen next?" people can easily come up with answers like "She’ll get the dog wet, and it will run away again." But can machine learning models do the same?
-
With the advent of language models like BERT (Devlin et al., 2018), ELMo (Peters et al., 2018), and OpenAI GPT (Radford et al., 2018), it became possible to achieve high performance on various NLP tasks. These models were especially anticipated to produce clear responses in commonsense natural language inference (NLI).
-
However, this paper argues that the commonsense NLI task remains unsolved. The research suggests that the high performance on existing tasks is due to the tasks not being sufficiently challenging and because fine-tuning has led models to learn the distribution of the training data rather than true commonsense reasoning.
-
To address this issue, this paper introduces a new benchmark, HellaSwag, created by applying an Adversarial Filtering (AF) technique to a Generator-Discriminator framework. This approach makes the task more challenging and aims to clarify points overlooked in previous research.
Background
To understand this study, it is necessary first to be familiar with the prior work, SWAG (Zellers et al., 2018), and the Adversarial Filtering (AF) technique used in that research, as they provide the necessary background knowledge.
SWAG
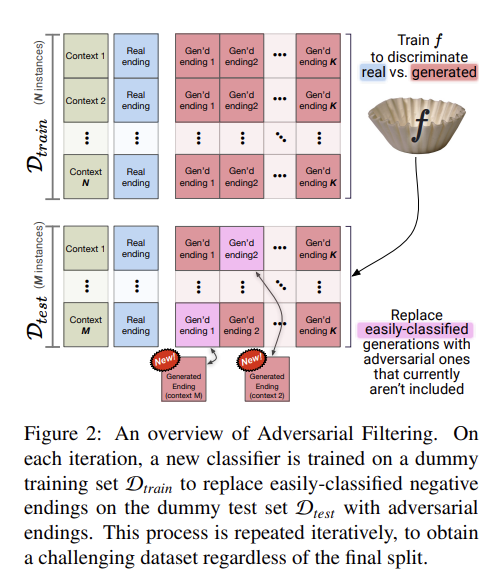
- ActivityNet (Yu et al., 2019) and the Large Scale Movie Description Challenge (LSMDC) (Rohrbach et al., 2016) are QA datasets where, given image captions and context, the task is to select the correct answer option related to the question.
- The authors believed these existing studies presented relatively easy QA tasks, so they applied AF to increase the difficulty of the original datasets, aiming to create more challenging tasks.
- First, the generator was used to create options based on existing choices that might seem straightforward to humans but could be confusing for machines. Next, the discriminator was tasked with answering the QA items that included these generated options. This process was carried out iteratively, filtering out the easy choices and leaving hard choices to build a final dataset with increased difficulty. The QA benchmark dataset constructed in this way is known as SWAG.
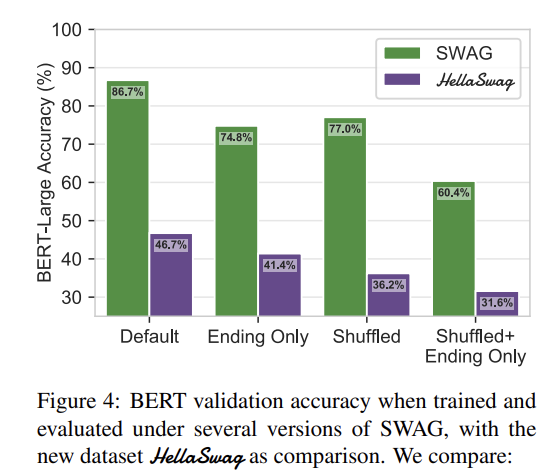
- BERT showed performance on SWAG that was nearly on par with human performance. In response, the authors conducted experiments to analyze the reasons behind this outcome. The results of these experiments can be seen in Fig. 4.
-
First, when they provided input without context (ending only), performance dropped by only 11.9 points. This result suggested that there might be biases within the answer choices themselves.
-
Additionally, performance did not significantly differ in a setting where the choices were shuffled. This raised the possibility that BERT might be learning patterns in sentences or words rather than understanding context.
-
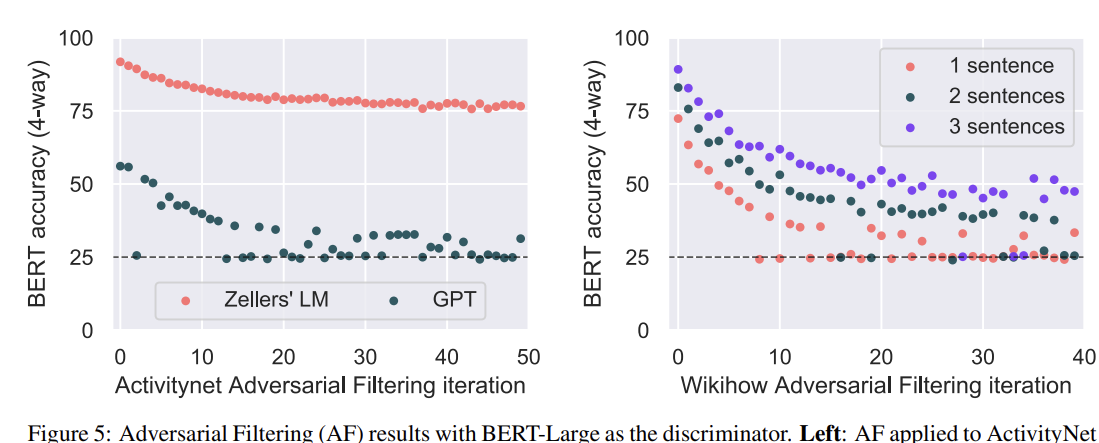
Finally, the authors argued that the generator (LSTM) used in SWAG performed poorly, resulting in generated choices that were still low-quality compared to human-written options, making the task less challenging. To address this, they aimed to improve the generator. Indeed, as shown in Fig. 5 (Left), when GPT was used as the generator, accuracy significantly dropped in the no-context setting, which is the desired outcome. (towards randomness)
HellaSwag
Therefore, in this paper, the authors created the HellaSwag benchmark to address the NLI problem by making the task more challenging through the use of high-quality generators and discriminators to produce options similar to human-written ones. The following process is carried.
-
First, the dataset was expanded to cover broader contexts and situations by incorporating descriptions of various scenarios collected from WikiHow (Koupaee, 2018) alongside the existing ActivityNet. As shown in Fig. 5 (right), this benchmark achieved the desired accuracy of 25% in the non-context setting, reaching the goal of random guessing. (In the non-context setting, the model ideally should not be able to solve the task; however, previous results showed that the model could still answer questions, revealing an issue where it was relying on word patterns rather than true contextual understanding.)
-
To demonstrate that the context and choices are of similar quality to human-written content, it is essential to confirm that humans achieve high performance while machines perform poorly. In the study, the authors used crowd workers for human filtering to extract a more realistic dataset.
Additionally, to verify model performance on out-of-domain or novel situations, the authors extracted "zero-shot" setting examples from categories not used during training then included them in the evaluation.
Experiment
- Dataset
- HellaSwag(In-domain & Out of domain settings)
- Activity Net
- WikiHow
- Model Usage
- Bert-Large : main baseline
- OpenAI GPT : pre-trained transformer based decoder model + fine-tuned
- Bert-base : smaller version of Bert
- ESIM+ELMo (Chen et al., 2017; Peters et al., 2018) : final output layer modified version of ELMo
- LSTM sentence encoder : two-layer bi-LSTM
- FastText (Joulin et al., 2017) : Bag-of-words text classification
Results
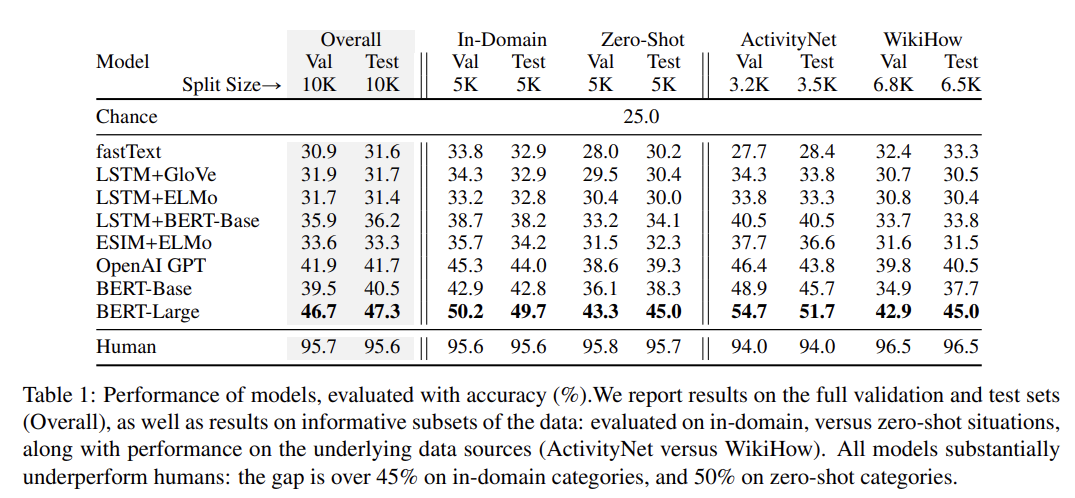
All results are shown in Table 1.
- As expected, it was observed that machine performance was lower than human performance across all datasets.
- BERT-Large was used as the discriminator model in AF for constructing HellaSwag. Nevertheless, its performance was not that high.
- As expected, performance dropped by more than 5% in the out-of-domain (zero-shot) setting, indicating that the model’s general commonsense reasoning ability is still limited.
Additional Experiment
- SWAG <---------------> HellaSwag
- Additionally, experiments were conducted to measure performance through transfer learning. In other words, models trained on SWAG were evaluated on HellaSwag, and vice versa. The results, shown in Fig. 9, further confirmed the model’s limited general commonsense reasoning ability.
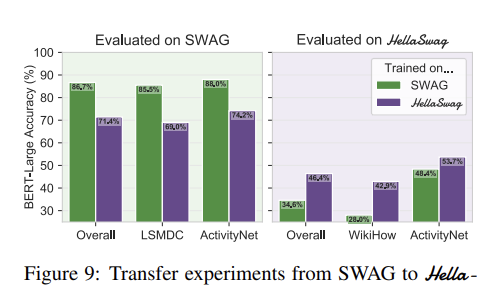
- Additionally, experiments were conducted to measure performance through transfer learning. In other words, models trained on SWAG were evaluated on HellaSwag, and vice versa. The results, shown in Fig. 9, further confirmed the model’s limited general commonsense reasoning ability.
Discussion & Personal Thought
- Discussion in Paper
- Future advanced Discriminator ? : As the difference in performance between BERT-Large and BERT-Base shows, improving the performance of the discriminator could significantly increase accuracy on this dataset.
- Using log-linear regression to analyze the relationship between pre-training time and overall accuracy, the authors predicted that it would take approximately GPU training hours to achieve human performance. They argue that, rather than merely designing models based on extensive pre-training, further research is needed to develop models that better understand context and identify patterns.
- My personal Thought
- Currently, with the advent of models like GPT-4, HellaSwag has surpassed human performance, achieving an accuracy of over 95%.
- It was impressive that the authors began with the idea of questioning whether the model might be memorizing word or sentence patterns rather than understanding the context of sentences, in order to create a challenging yet reasonable dataset.
- The main issue highlighted in this paper is the lack of general reasoning ability in models. Although techniques like in-context learning, RAG, and Chain-of-Thought (CoT) are currently being applied to enhance large language models (LLMs), it seems that a more architectural approach could be beneficial for the model to fully develop this capability.
Appendix
- Qualitative examples

- Current HellaSwag Leaderboard
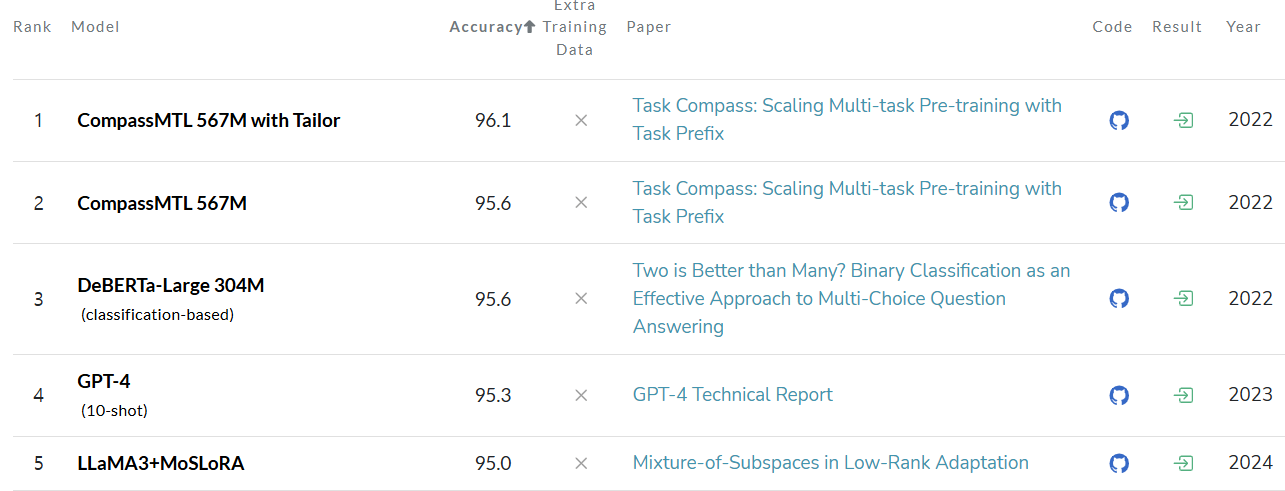
Reference : HellaSwag benchmark leaderboard
