1. spark 객체 생성
먼저 환경은 colab 환경에서 진행하였다.
!pip install pyspark==3.0.1 py4j==0.10.9pyspark와 py4j 패키지 설치
py4j는 파이썬 프로그램에서 자바가상머신의 오브젝트들에 접근이 가능하게 해주는 패키지이다.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Taipei Housing Price Prediction") \
.getOrCreate()spark 객체를 생성한다.
데이터셋 설명
이번 모델의 데이터셋은 대만 타이베이 시의 신단 지역에서 수집된 주택 거래 관련 정보이다.
해당 데이터로 주택의 평당 가격을 예측하는 것이 목표이다.
컬럼 설명
X1: 주택 거래 날짜를 실수로 제공한다. 소수점 부분은 달을 나타낸다.
X2: 주택 나이 (년수)
X3: 가장 가까운 지하철역까지의 거리 (미터)
X4: 주택 근방 걸어갈 수 있는 거리내 편의점 수
X5: 주택 위치의 위도 (latitude)
X6: 주택 위치의 경도 (longitude)
Y: 주택 평당 가격
!wget https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/Taipei_sindan_housing.csv데이터를 불러온다.
data = spark.read.csv('./Taipei_sindan_housing.csv', header=True, inferSchema=True)데이터를 spark객체로 생성

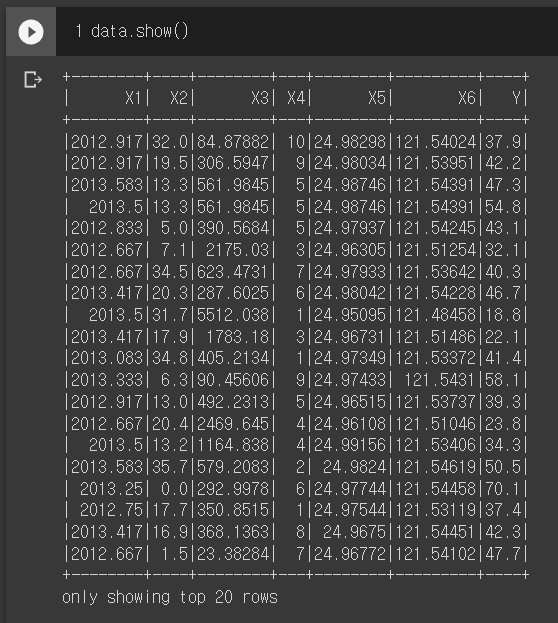
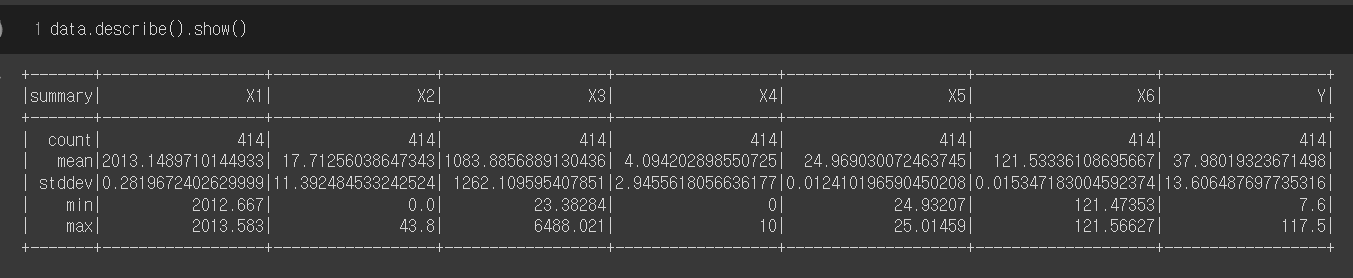
데이터에 결측된 값은 없어 보인다.
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import MinMaxScaler
from pyspark.ml import Pipeline
feature_columns = data.columns[:-1] ##예측값 제외
assembler = VectorAssembler(inputCols = feature_columns, outputCol = 'features')
scaler = MinMaxScaler(inputCol = 'features', outputCol = 'scaled_features')
pipeline = Pipeline(stages=[assembler, scaler])
scalerModel = pipeline.fit(data)
scalerData = scalerModel.transform(data) target 값인 Y를 제외하고 feature_columns로 지정해준다.
그 후 VectorAssembler를 사용해 벡터형태로 만든다.
그런다음 scaler로 MinMaxScaler를 지정 후 벡터를 정규화 한다.
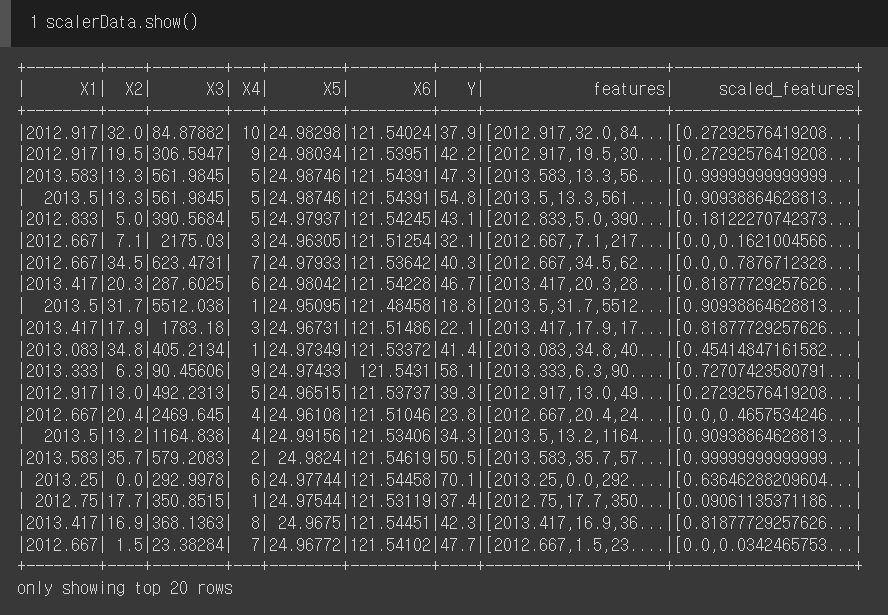
train, test = scalerData.randomSplit([0.7,0.3])학습데이터, 테스트데이터를 7대3 비율로 나눠준다.
algo = LinearRegression(featuresCol="scaled_features",labelCol="Y")
model = algo.fit(train)LinearRegression 모델로 진행한다.
feature vector와 label column을 설정해주고 학습시킨다.
evaluation_summary = model.evaluate(test)테스트 진행
결과 확인
evaluation_summary.rootMeanSquaredError
evaluation_summary.r2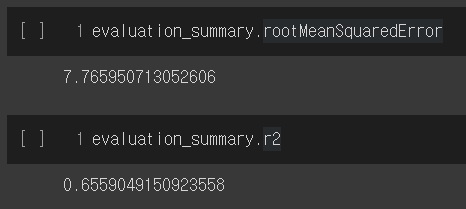
RMSE와 R2스코어
predictions = model.transform(test)
predictions.select("Y","prediction").show()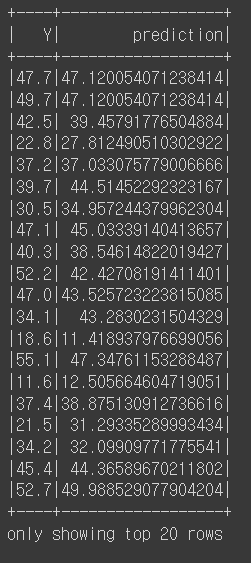
예측 값과 실제 값이다.
이상 Pyspark regression 기초 연습이었다.
