Anticipating Accidents in Dashcam Videos
by Fu-Hsiang Chan, Yu-Ting Chen, Yu Xiang, Min Sun
Asian Conference on Computer Vision 2016 Oral
Attention mechanism을 이용해 도로주행 상황 속 오브젝트에 집중한 LSTM 기반 교통사고 예측 모델 DSA-RNN
Introduction
Emerging Self-driving cars
두 가지 중요한 문제를 해결해야 한다.
-
How to drive safely with other "human drivers"
- 현재 개발 중인 자율주행 자동차 시범 운행 중 발생한 교통사고 대부분 사람이 운전하는 차량이 원인이었다.
- 인간과 함께 안전하게 운전할 수 있는 autopilot 시스템을 구축할 필요성
-
How to scale-up the learning process
- 얼마나 다양한 교통사고 케이스들을 학습할 수 있는가?
- 러시아, 대만, 한국에서 널리 사용되는 블랙박스 (dashcam) 영상을 이용해 비교적 낮은 비용으로 다양한 교통사고 시나리오를 학습할 수 있는 방법론을 제안한다.
In this paper...
-
아래 요소를 사용한 교통사고 예측 모델 DSA-RNN 을 제안한다.
- Dynamic-spatial-attention
- RNN for sequence modeling
- Exponential loss
-
기존 도로 데이터셋에 비해 움직이는 물체가 많고 복잡한 표지판 및 광고판이 존재하는 도로 상황에서 촬영된 영상을 이용해 난이도가 높은 고화질 블랙박스 데이터셋을 구축하고 학습에 사용하였다.
Method
Preliminaries: RNN and LSTM
TODO: 따로 개념 정리하기
Problem Formulation
Observations and accident label for video
Dynamic Self-Attention
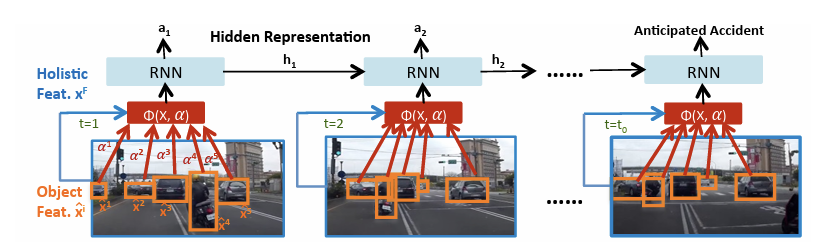
모델이 시간에 따른 비디오 속 오브젝트 (자동차, 오토바이, 보행자 등) 단위 관찰에 집중하도록 하는 방법으로 사용한다.
-
각 프레임 (spatial location) 에서 얻은 J개의 object observation
-
각 observation의 위치
-
attention weights
별도의 파라미터를 학습하여 spatial attention을 계산한 후, 이를 정규화하는 과정을 거친다. Regular grid로 나누어 spatial-attention을 계산했던 기존 방법론과 달리, 각 오브젝트별 영역에 대하여 적용하였음을 차별점으로 강조한다. -
Dynamic weighted-sum of spatially-specific object observation
이렇게 얻은 는 LSTM의 입력으로 사용된다. 두 가지 방법으로 full-frame feature와 합쳐져 모델에 전달될 수 있다.
1. Concatenation:
2. Weighted-sum: full-frame을 가장 큰 하나의 오브젝트로 보고 위의 메커니즘을 동일하게 적용하여 하나의 feature를 만들어냄
Training Procedure
Anticipation loss
아주 가까운 프레임에 발생하는 사고를 예측하지 못했을 때 먼 프레임의 경우보다 높은 페널티를 적용한다. 즉, 손실함수 값이 프레임 간 거리에 반비례하도록 한다.는 사고가 발생한 프레임, 은 t번째 프레임에서 예측된 사고가 일어날 확률 값이다.
사고가 발생하지 않는 negative frame의 경우 standard cross-entropy loss를 적용한다. 은 t번째 프레임에서 예측된 사고가 발생하지 않을 확률 값이다.
최종 손실함수 식은 위에서 언급한 두 개의 손실함수의 합이다.
학습에는 SGD with standard back-prop through time (BPTT) algorithm, learning rate=0.0001, max 40 epoch, 10 batch size를 사용했다.
Experiments
Dashcam Accident Dataset
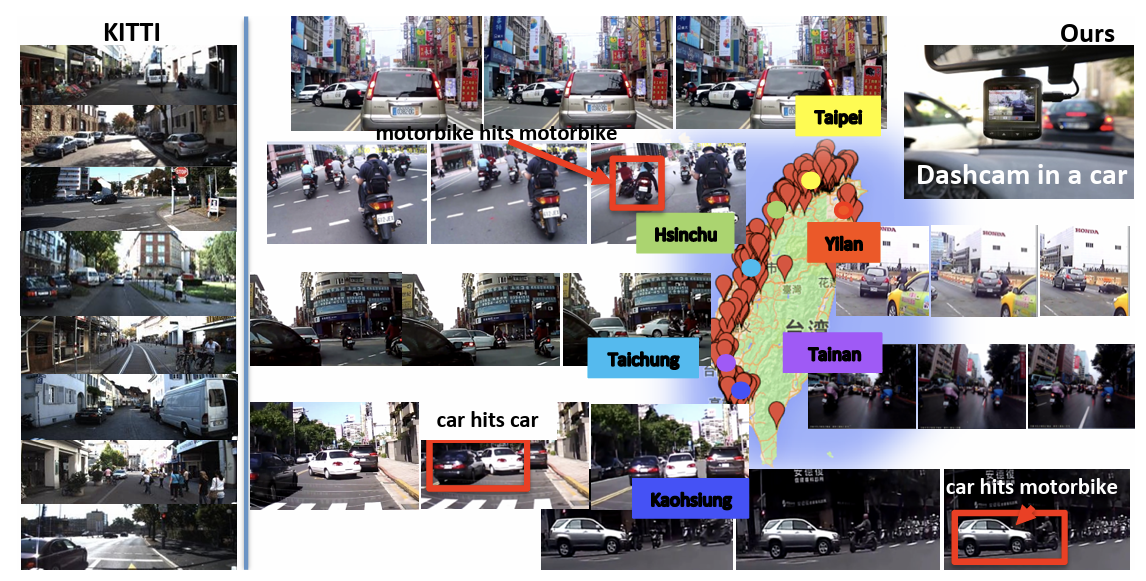
기존 도로주행 데이터셋인 KITTI에 비교해 난이도가 어렵다.
- Complicated road scene: 데이터가 주로 수집된 지역인 대만의 도로 표지판과 광고판이 복잡함
- Crowded streets: 영상에 등장하는 차량, 오토바이, 보행자의 수가 많음
- Diverse accidents: 다양한 교통사고 시나리오
총 678개의 블랙박스 영상을 온라인으로 수집한 후, 58개의 비디오는 직접 annotation해서 object detector를 학습시키는 데 사용했다. 남은 620개의 비디오에서 100프레임 길이의 1750개 클립 영상을 샘플링하여 데이터셋을 구성하였다. 그 중 620개는 사고가 발생한 (positive) 경우, 나머지는 사고가 발생하지 않은 (negative) 경우이다.
Implementation Details
Features
Single-frame-based appearance와 Clip-based local motion feature 함께 사용했다.
-
Capturing appearance: pre-trained VGG
- 20fps로 각각의 프레임을 4096차원의 feature로 뽑아낸다.- full-frame과 object 단위 feature 모두 뽑아낸다.
-
Capturing motion: improved dense trajectory (IDT) feature
- 5개의 연속적인 프레임에 대해 feature 뽑아낸다.
- PCA를 이용해 100차원으로 줄임
- 64개 클러스터로 Gaussian-Mixture-Model을 학습시킨다.
- 1st order statistic of fisher vector encoding을 사용해 6400차원의 feature를 뽑아낸다.
- full-frame feature만 뽑아낸다.
- Relativity-Motion (RM) features
- 가까운 물체들 간 relative 2D motion을 이용해 feature 뽑아낸다.
- 5x5 median motion encoding
Candidate objects
해당 논문에서 구축한 비디오 데이터셋을 이용하여 파인튜닝된 Faster R-CNN을 이용해 최대 20개까지의 candidate object region을 예측하여 각 object에 대하여 soft-attention을 시행한다.
Evaluation Metric.
- True Positive (TP): confidence >= threshold, an accident video
- False Positive (FP): confidence >= threshold, a non-accident video
- True Negative (TN): confidence < threshold, a non-accident video
- False Negative (FN): confidence < threshold, an accident video
위 Metric을 사용해 Precision과 Recall을 계산한다.
또한, 예측된 사고 시점과 GT 사고 시점 사이의 차이를 Time-to-accident (ToA)로 설정하여 TP 상황에 대해 평균 값을 계산한다.
Baseline Methods
- Dynamic-Spatial-Attention RNN
- (D) no full-frame features, only attention on object candidates
- (F+D-sum) weighted sum of full frame feature with object-specific features
- (F+D-con) concatenate full-frame faeture with object features - Average-Attention RNN: replace DSA with average attention, baseline
- (avg.-D) only the average attention feature
- (F+avg.-D-con) concatenate full-frame feature - Frame-based RNN (F): full-frame feature only
- Average-Attention Single-frame Classifier (SFC): replace RNN with SFC
- Maximum-Probability Single-frame Classifier (SFC): replace average-attention with the maximum accident anticipation probability
- Frame-based Single-frame Classifier (SFC): start from F, replace RNN with SFC
Results
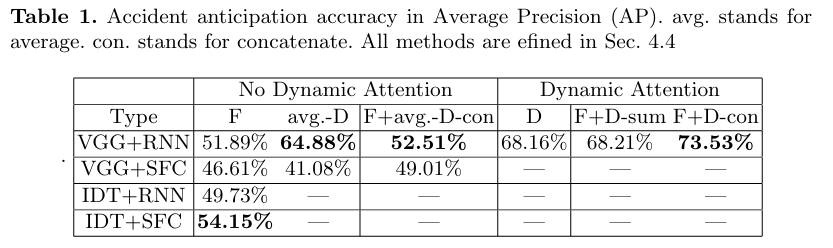
DSA를 사용한 VGG+RNN+F+D-con variant가 가장 좋은 성능을 기록했다.
Thoughts
- Faster R-CNN (당시 SOTA) 사용해서 object detection을 수행했다. 최근에 나온 더 좋은 모델을 이용하면 더 좋은 annotation을 생성할 수 있을 것이다.
- 오래된 논문이다 보니 RNN 아키텍처를 사용했다. Attention 개념을 도입한 점이 이 논문의 핵심 중 하나이기도 하니, 이 메커니즘을 중심적으로 활용하는 Transformer 아키텍처를 도입해볼 수 있을 것 같다.
- 다른 도로주행 데이터셋
- Urban scenes:
CamVid,Daimler Urban Segmentation - Driving scenes:
KITTI
- Urban scenes:
