아래 글에 대한 번역입니다. 오역이 있는 부분은 코멘트 주시면 감사하겠습니다.

상품 카테고리는 모든 온라인 쇼핑몰에 있어 중요한 핵심 뼈대입니다. 모든 상품을 정확한 카테고리에 분류하기란 여간 쉬운 작업이 아닙니다. 보통 엄청나게 많은 수의 카테고리가 관리되어야 하며 자주 변동됩니다. 아마존은 5만개 이상의 카테고리를 관리한다고 합니다. 이런 카테고리에 매일, 주기적으로 새로운 상품이 매핑되어야 합니다. 카테고리를 잘못 매핑한다는 것은 고객을 헷갈리게 하고 고객이 제대로 찾을 수 없기 때문에 이런 실수는 치명적입니다.
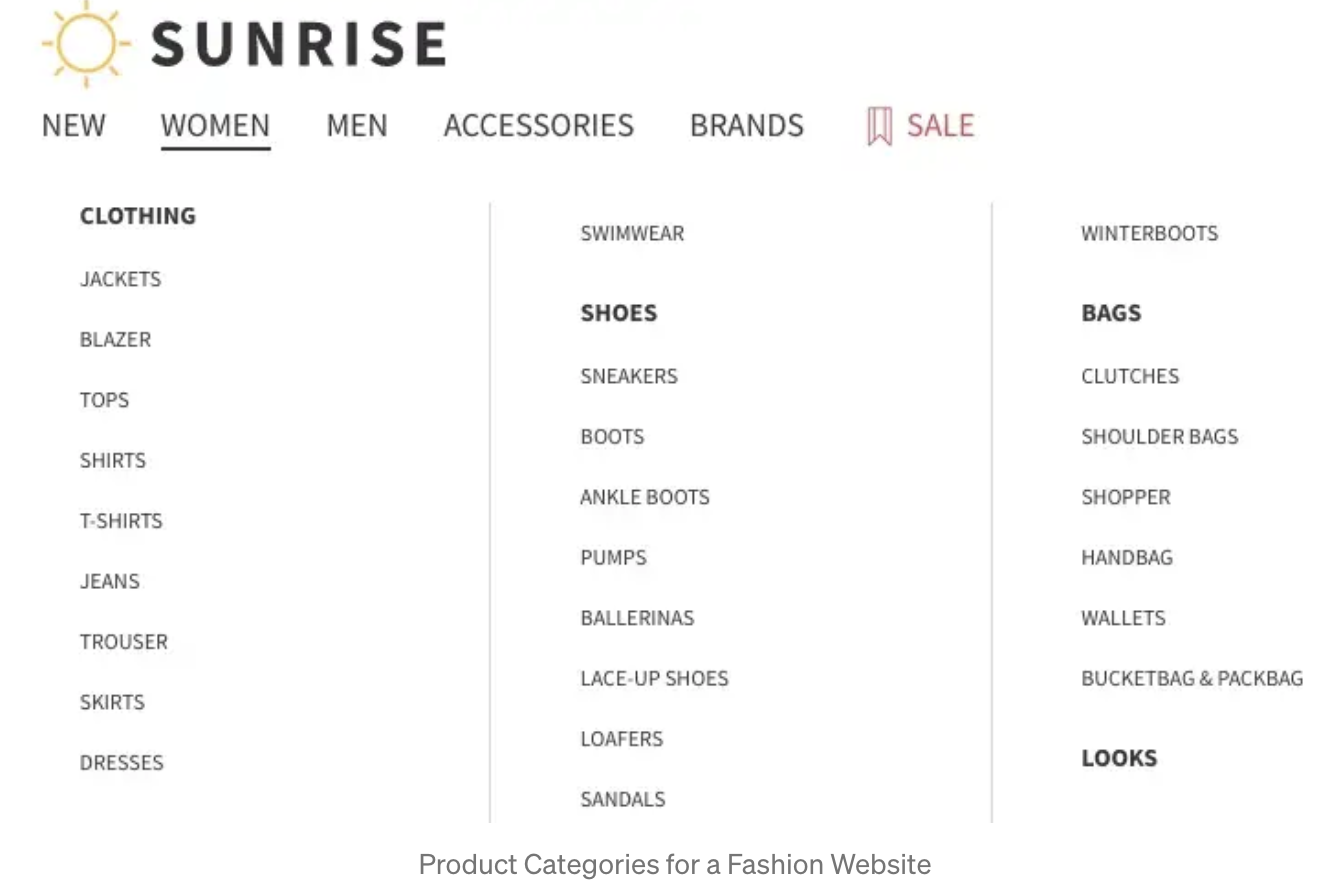
상품 카테고리화의 과정을 개선하기 위해 머신 러닝을 활용해보고자 합니다. 목표는 머신러닝 시스템을 개발하여 특정 상품이 어느 카테고리에 가장 잘 연결되는지를 찾아내는 것입니다. 이 블로그 글에서는 목표를 이루기 위해 해결해야 했던 문제들과 해결 방법들에 대해 소개해보고자 합니다.
도전과제, 제약
머신러닝의 관점에서 상품 카테고리를 예측하는 문제는 몇 가지 특징적인 도전 과제들이 있습니다.
1. 분류하고자 하는 클래스(class)가 매우 많습니다. 일반적인 머신 러닝 어플리케이션은 이메일이 스팸인지 아닌지 등 적은 수의 클래스만을 분류하면 됩니다. 하지만 이커머스에서는 보통 몇백, 백천개의 카테고리를 분류해야 합니다. 이런 모델을 학습하기 위해서는 학습 데이터가 엄청나게 많아야 합니다.
2. 상품 데이터는 광범위하고 불균형적이다. 하나의 상품은 다른 상품이 가지고 있지 않은 다양한 속성을 가지고 있을 수 있습니다. 예를 들어, 티셔츠의 옷 상품은 색상과 사이즈 라는 속성을 가질 수 있고 프레시, 음식 상품은 유통 기한 이라는 속성을 가질 수 있습니다. 따라서, "모든" 상품의 속성을 고려하면 누락된 값이 매우 많을 수 있고 모델의 정확도를 올리기 어렵습니다. 이런 문제를 해결하기 위해서 대부분의 상품이 가지고 있는 속성이면서도 의미가 충분히 있는 상품의 이름, 이미지, 그리고 설명 을 예측하는데 사용했습니다.
3. 모든 온라인 쇼핑몰은 각기 다른 카테고리 구조를 가지고 있다. commercetools 는 커머스 플랫폼을 관리할 수 있는 클라우드 기반의 API (상품, 주문, 고객, 카트, 결제 등) 를 제공합니다. API 는 유연성을 염두해두고 디자인 되었기에 패션업, 농업, 가구, 스포츠 등 다양한 산업에서 활용될 수 있습니다. 머신 러닝 시스템을 개발할 때, 쇼핑몰의 도메인에 맞게 카테고리를 추천을 해주어야 했습니다.
해결하는 한가지 방법은 각 쇼핑몰에서 판매하는 상품과 카테고리에 맞춰 별도 머신러닝 모델을 도출하면 됩니다. 하지만 이 방법은 몇 가지 문제점이 존재합니다. 어떤 쇼핑몰은 모델을 훈련하기 위한 상품 데이터가 충분하지 않을 수 있고, 클래스가 불균형적일 수 있습니다. (패션 카테고리에는 상품이 많지만 프레시 상품에는 많이 없을 수 있습니다) 또한, 모델은 새로운 카테고리가 추가될 때마다 자주 업데이트가 되어야 하며 이런 모든 과정을 관리하기 위한 인프라/플랫폼을 구축하는 것은 꽤나 어려운 일입니다.
이러한 이유들로 인해 다양한 범위의 카테고리를 커버할 수 있는 일반적인 모델 하나를 만들었습니다. 일반적인 카테고리에서 쇼핑몰에 특화된 카테고리로 매핑을 하기 위해서는 각 단어간 유사성을 수치화할 수 있는 다른 머신러닝 모델을 사용했습니다. 예를 들어, 일반적인 카테고리 "청바지"는 쇼핑몰 A 에서는 패션 > 남자 > 청바지에 매핑을 하고, 쇼핑몰 B 에서는 옷 > 바지에 매핑을 할 수 있습니다. 이런 접근 방법은 낮은 정확도의 단점을 보이지만 유연성을 더 가져올 수 있습니다. 또한, 불균형 데이터를 처리할 수 있고 유지비용이 훨씬 더 적게 듭니다.
목적을 다시 정리하자면, 상품의 이름, 이미지, 설명을 기반으로 광범위한 상품 카테고리를 예측하는 머신러닝 모델을 만들려고 합니다. 도출된 상품 카테고리는 다른 머신러닝 모델을 통해 각 쇼핑몰에 특화된 카테고리에 매핑이 됩니다. 파이썬으로 구현하고자 합니다.
Class Set
이 문제를 해결하기 위해 좋은 클래스 셋을 정의한다는 것은 거의 예술의 영역에 가깝다. 만약 클래스 셋이 너무 작다면, 특정 쇼핑몰에게는 중요한 카테고리를 놓쳐버릴 수 있다. 만약 너무 크다면 예측도가 많이 떨어질 것입니다. 723개의 카테고리를 위해 크고 작은 클래스 셋을 모두 테스트 해보았습니다. 클래스 셋은 보다 일반적이고 하나, 두개 정도의 단어만 포함하고 있는 단어로만 구성했습니다. 예시는 다음과 같습니다.
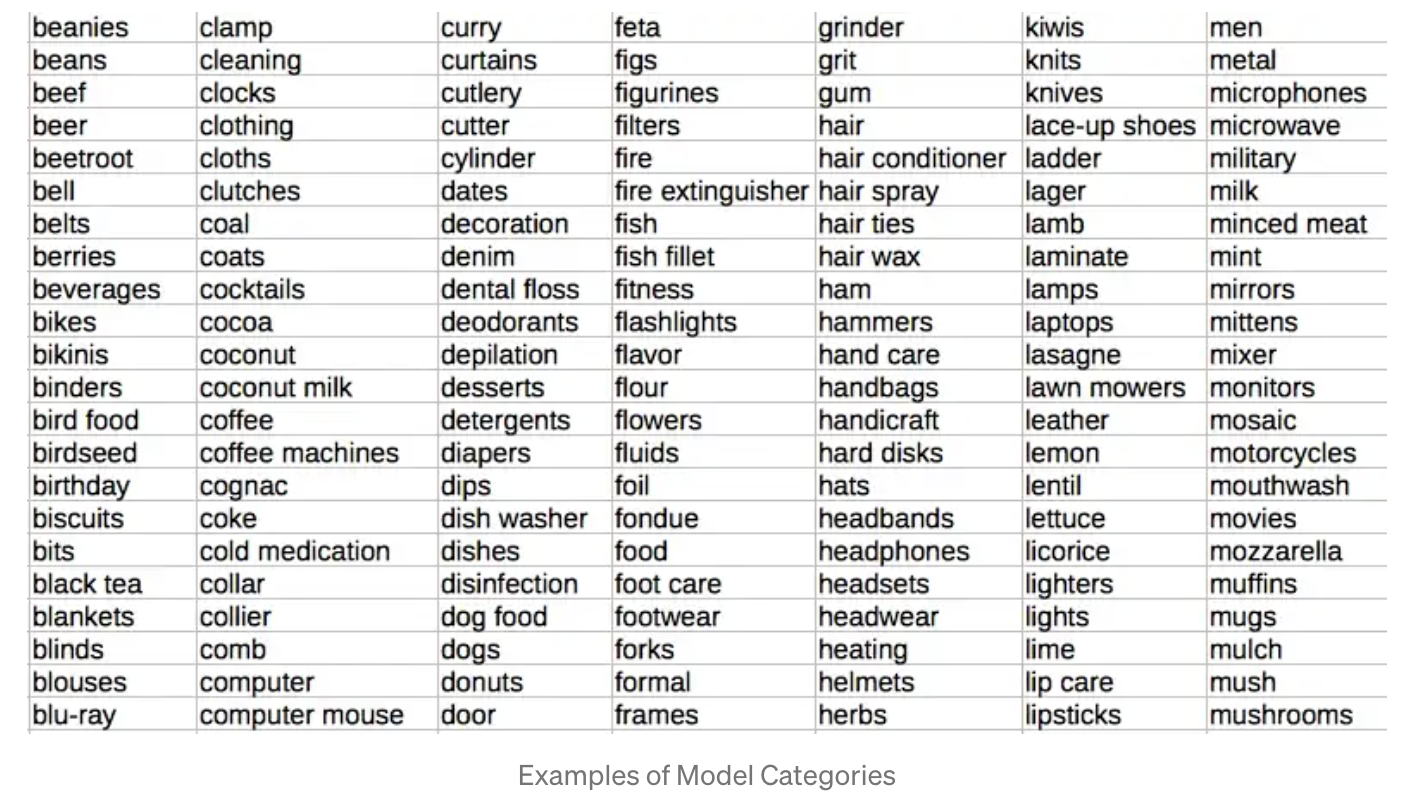
초기에는 되도록 넓은 예측 커버리지를 위해 최대한 많은 카테고리를 예측하고자 했습니다. 하지만 저희의 고객은 전체 카테고리 영역에 넓게 퍼져있는 것이 아니라 특정 산업에 집중되어 있었습니다. 데이터 사이언티스트의 본성에 어긋나는 것이지만 각각의 산업에 특화된 overfit 한 모델이 더 좋겠다고 판단했습니다. 모든 산업에서 고객의 요청이 오더라도 이런 방법으로는 충분히 대응할 수 있습니다.
이미지 분류기 (Image Classifier)

이미지 분류에서는 CNN (Convolutional neural networks) 를 사용하는 것이 거의 공식화 되어 있습니다. 왜냐하면 low-level 특징과 abstract feature 를 잘 구분하기 때문입니다. 인간의 뇌도 비슷한 메커니즘으로 작동하는 것을 보아 이 알고리즘은 뭔가 잘 되는 것이라 판단했습니다. CNN 알고리즘이 2012년에 세상에 나오고 나서 꾸준히 연구자들은 매년 진행되는 이미지넷 (ImageNet) 대회에서 CNN 의 성능을 개선해왔습니다. 2017년에는 상위 5개가 97.8%의 정확도를 보였습니다.
모든 상품 카테고리를 예측하는 모델을 만들기 위해 많은 데이터가 필요하다고 했던 것을 기억하시나요? transfer learning 이라는 방법을 사용해 살짝의 치팅을 해보도록 하겠습니다. CNN 을 아무것도 없는 상황에서 구현하기란 많은 시간이 필요한 작업입니다. 그래서 저희는 이미 많은 이미지 데이터 셋에서 사전 학습된 Inception v3 라는 모델을 사용하려고 합니다. 이 모델은 이미지 속성을 추출하고 합치는데 이미 학습이 되어 있습니다만 어떤 카테고리에 매핑이 되어야 하는지는 모릅니다. 이 모델을 입맛에 맞게 바꾸려면 최종 단계의 분류 layer 를 잘라내고 새로운 layer 를 추가해서 723개의 카테고리를 예측할 수 있도록 다시 학습하면 됩니다.
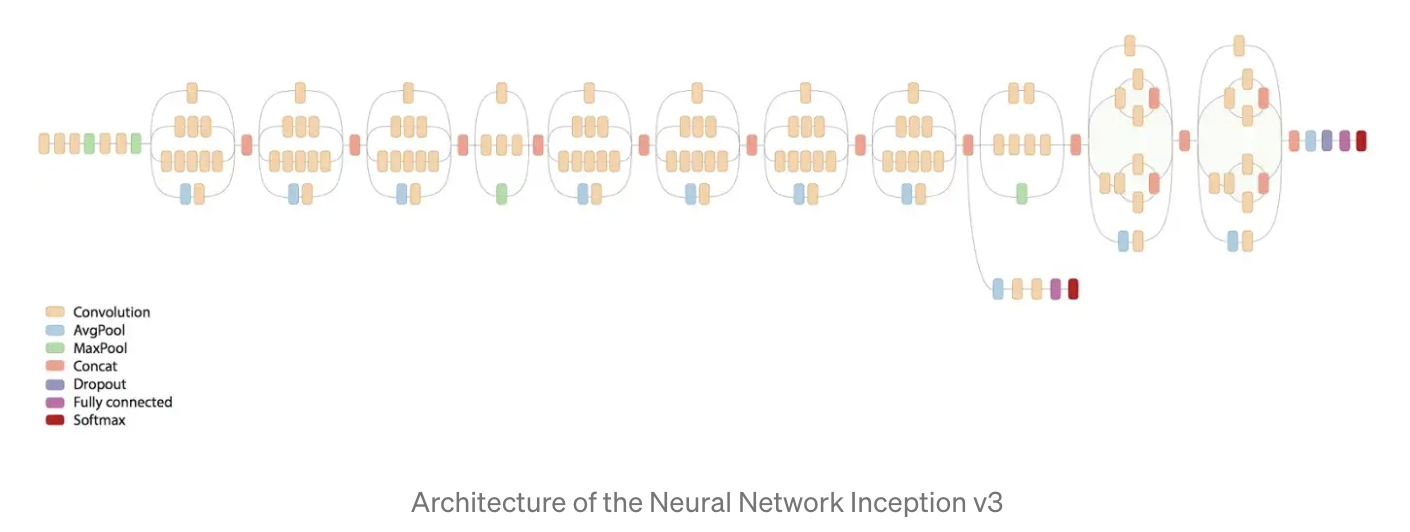
TensorFlow 라이브러리를 활용했고 모델은 Google Cloud ML Engine 에서 학습시켰습니다. URL 에서 이미지를 다운받고 JPEG 로 변환하고 이미지를 재조정하고 각 카테고리 아래의 하위 폴더로 정리했습니다. 그리고 중복을 없애고 유효하지 않은 파일도 삭제했으며 학습된 모델은 Google Storage 에 올렸습니다. 이 작업들은 여전히 사람의 손이 좀 필요한 작업들입니다.
텍스트 분류기 (Text Classifier)
다음은 상품명으로 분류를 해보겠습니다.

중복 제거, 의미없는 상품며여 제거, 카테고리별 개수를 맞추고 나니 23만개 정도의 샘플을 만들었습니다. (각 카테고리별 300개정도씩) 상품명을 좀 더 쉽게 처리할 수 있고 차원을 줄이기 위해 전처리 파이프라인을 만들었습니다. (re 와 spacy 라이브러리 사용)
- 소문자로 바꾸기
- 콤마, 점 등 punctuation 과 특수문자 없애기 (대신 하이픈 (-) 은 유지, "t-shirts" 가 있기 때문)
- stopwords 없애기 (the, and, in, ...)
- 동의어 사전 만들기 (apples 와 apple 은 같은 단어로 인식할 수 있도록)
되게 짧은 단어 (1-3 letters) 를 제거하고 스펠링을 맞추는 작업도 같이 포함시켜 예측 해보았는데 성능이 더 좋아지지 않아서 전처리 파이프라인에서 제거했습니다.
그 다음은 전처리한 텍스트를 숫자로 바꾸었는데 그 이유는 머신 러닝 모델은 숫자에 기반해서 작동하기 때문입니다. 몇가지 방법을 활용했는데:
- Bag-of-words: 특정 단어를 대표하는 n 개 차원의 벡터로 바뀌며 값은 그 단어가 해당 샘플에서 몇번 나타나는지를 보여주는 빈도수임. 쉽게 할 수 있지만 문법이 무시되고 되게 큰 sparse vectors 로 구성되게 된다 => 모델링 하기 어려워짐
- TF-IDF (term frequency-inverse document frequency): bag-of-words 와 비슷하지만 각 단어의 빈도수에 가중도를 주는 방식. 중요하지 않은 단어를 제거할 수 있고 따라서 벡터 스페이스를 좀 줄일 수 있음
- Word2Vec: 2개의 계층으로 문맥을 파악하게끔 훈련을 시키면서 sparsity 문제를 해결함. 예시: "Nike" 는 "shoes" 라는 단어가 "bananas" 라는 단어보다 더 자주 같이 등장함. 구현하기는 더 어렵지만 차원이 낮고 훈련하기에는 더 좋음
TF-IDF의 결과가 제일 좋았습니다. 단어들 사이에 좀 더 복잡한 문법을 가진 텍스트들에서는 Word2Vec 이 TF-IDF 를 훨씬 능가하지만 이번 사례에서는 TF-IDF 가 더 좋았습니다.
전처리와 벡터화를 하고 나서 이제 드디어 실제로 모델을 만들 수 있습니다. 예측도는 scikit-learn 라이브러리에서 제공하는 다양한 머신러닝 모델을 통해 테스트를 했습니다: Naive Bayes, Logistic Regression, k-Nearest Neighbors, Random Forests, Support Vector Machines, Gradient Boosting
Logistic Regression 과 TF-IDF 를 같이 사용해보니 제일 좋은 결과가 나왔습니다. 이는 더 복잡하고 멋져보이는 모델이 항상 더 좋은 결과를 가져오진 않는 다는 것을 보여줍니다.

카테고리 매칭
723개의 카테고리를 예측하기 위한 이미지, 상품명, 설명 기반의 분류기가 준비되었습니다. 여러 개의 예측 모델을 어떻게 통합할 수 있을까요? 보통은 앙상블 모델을 활용합니다. 하지만 저희의 목적에서는 각각의 모델을 통해 예측을 한 다음 평균값을 기반으로 최종 예측값을 계산하도록 합니다.
카테고리 예측을 하는 모델을 만들었지만 예측한 723개의 카테고리를 각 쇼핑몰의 카테고리에 맞게 매칭하는 것은 아직 해결하지 못했습니다. 만약 상품이 "팔찌" 카테고리에 분류되었다면 각 쇼핑몰에서 사용하는 카테고리로 매칭을 해야 합니다. 이걸 해결하기 위해 gensim 라이브러리를 사용해서 구글 뉴스 아티클 데이터로 Word2Vec 모델을 훈련시켰습니다. 시간이 좀 소요될 수 있는 작업이어서 데이터베이스에 매일 밤에 미리 만들어두었습니다.
카테고리 유사도 값을 0 에서 1 스케일로 맞추었고 0.6 이상되면 충분히 유사하다고 판단했습니다.
패션과 쥬얼리 업계에서 사용하는 카테고리에 대해서는 90% 이상의 정확도를 보였고, grocery/home supplies 업계에서는 다소 낮은 70-80% 정도의 정확도를 보였습니다. grocery/home supplies 업계는 훨씬 많은 카테고리와 다양성이 더 많기 때문에 정확도를 올리기가 쉽지 않습니다.
API
배포하기 위해서 flask 에 HTTP API 를 작성했습니다. 두 개의 endpoint 를 가지고 있고 하나는 예측 모델을 위한, 또 하나는 각 쇼핑몰별 예측을 위한 API 입니다. 첫 번째 endpoint 는 다른 이미지, 상품명, 설명에 대한 예측 모델을 테스트하기 위해 사용합니다.
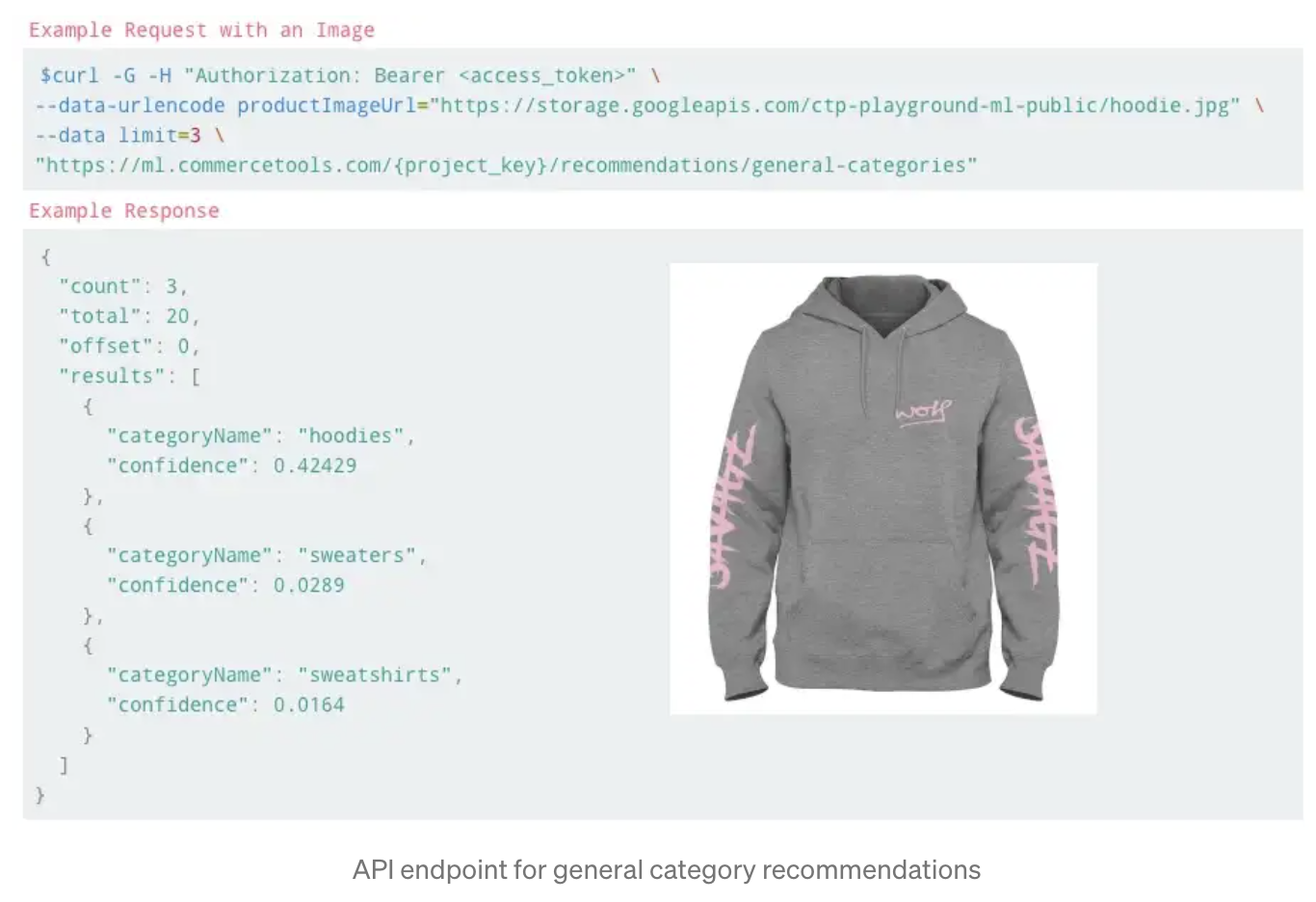
반대로 쇼핑몰별 예측을 위한 endpoint 는 다음과 같은 워크플로우로 동작합니다: 1) 쇼핑몰 key 값과 상품 id 를 input 으로 받습니다. 그 다음에는 이미지, 상품명, 설명 데이터를 찾아서 머신 러닝 모델에 넣습니다.
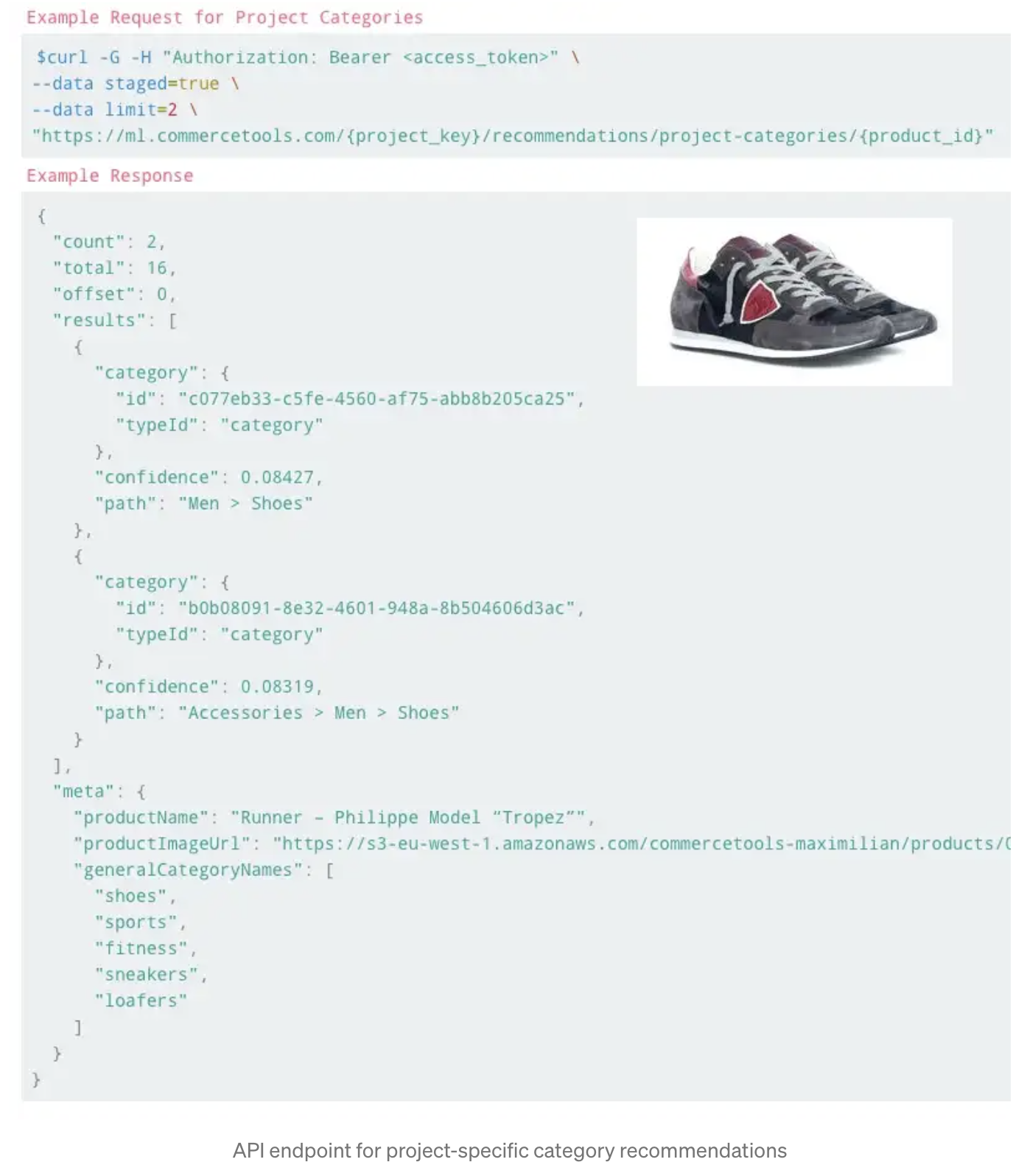
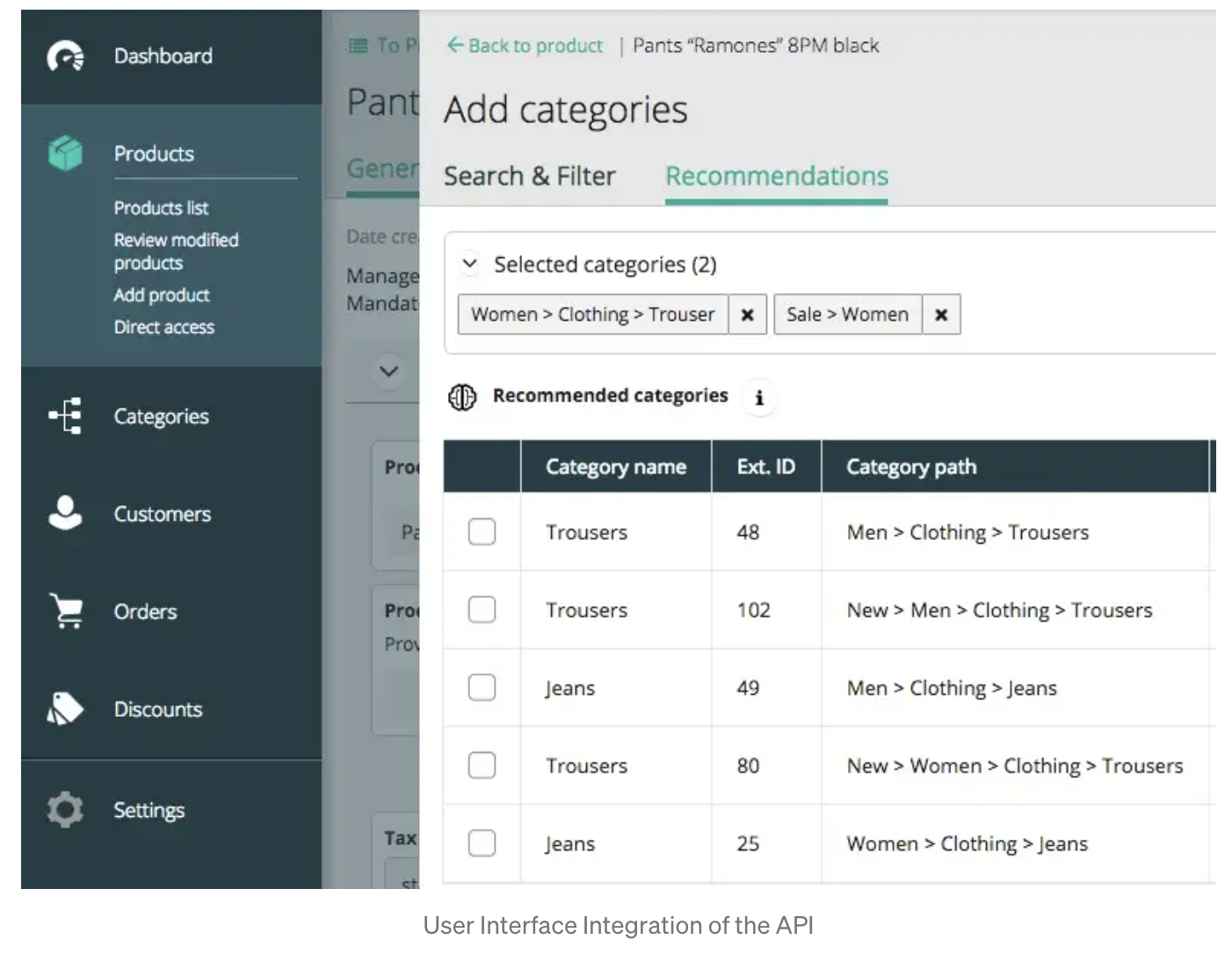
현재는 베타 테스트 중입니다.
참고 자료

1개의 댓글
- 예측하려는 범위가 너무 넓으면 좁혀서 진행하는 것이 좋다.