배열을 이용하여 리스트를 구현하면 순차적인 메모리 공간이 할당되므로, 이것을 리스트의 순차적 표현이라고 한다.
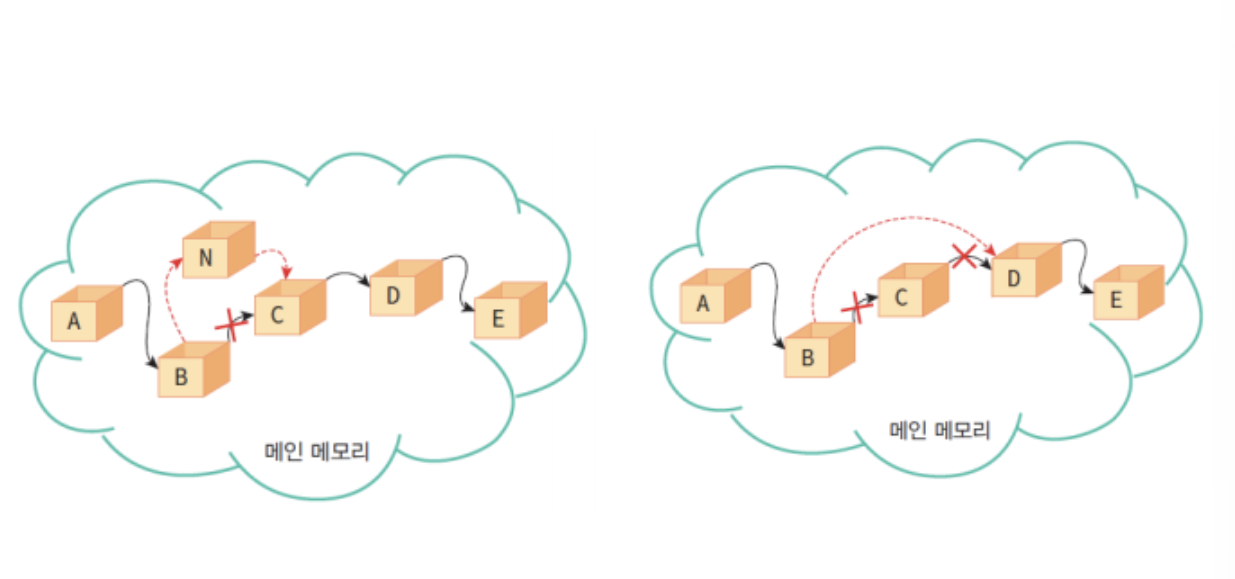
배열의 중간에 데이터를 삽입하기 위해서는 처음이나 끝에서 이동해야 하는 불필요한 연산이 발생한다.
💡 이러한 Sequential 표현에서 데이터 이동의 문제점을 해결할 수 있는 방법이 바로 연결 리스트(Linked list)
⛓️연결 리스트 (linked list)
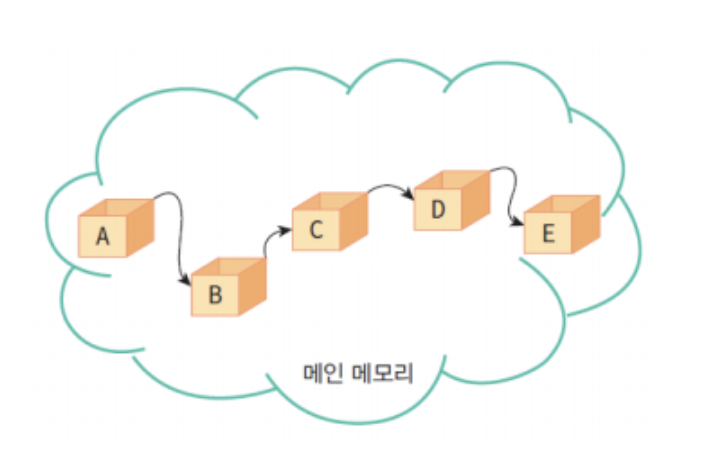
동적 할당으로 데이터를 저장하는 방법
연속한 메모리 물리주소에 원소의 순서를 표현하는 것이 아닌, 각 원소에 저장되어 있는 다음 원소의 주소에 대한 참조에 의해 연결되는 방식!
리스트의 항목들을 노드(node)라고 하는 곳에 분산하여 저장
노드는 데이터 필드와 링크 필드로 구성 (노드 = 데이터 + 링크)
- 데이터 필드 - 리스트의 원소, 즉 데이터 값을 저장하는 곳. 저장할 원소의 형태에 따라서 하나 이상의 필드로 구성하기도 한다.
- 링크 필드 - 다른 노드의 주소 값을 저장하는 장소 (포인터)
👾 노드의 정의
typedef struct ListNode {
int data;
struct ListNode *link; //자기참조구조체
} ListNode;삽입과 삭제
장단점
-
장점
- 삽입, 삭제가 보다 용이하다.
- 연속된 메모리 공간이 필요 없다.
- 유연하고 효율적인 메모리 사용
- 크기 제한이 없다.
-
단점
- 참조를 위해 추가적인 메모리 공간 필요
- 데이터들이 메모리 물리주소에 연속으로 위치하지 않아 특정 원소의 접근이 오래 걸린다.
- 구현이 어렵다.
- 오류가 발생하기 쉽다.
연결리스트의 종류
- 단순 연결 리스트
- 원형 연결 리스트
- 이중 연결 리스트
🔎 해당 리스트들을 살펴보자
1. 단순 연결 리스트
노드가 하나의 링크 필드를 이용하여 다음 노드와 연결되는 구조
마지막 노드의 링크 값은 NULL

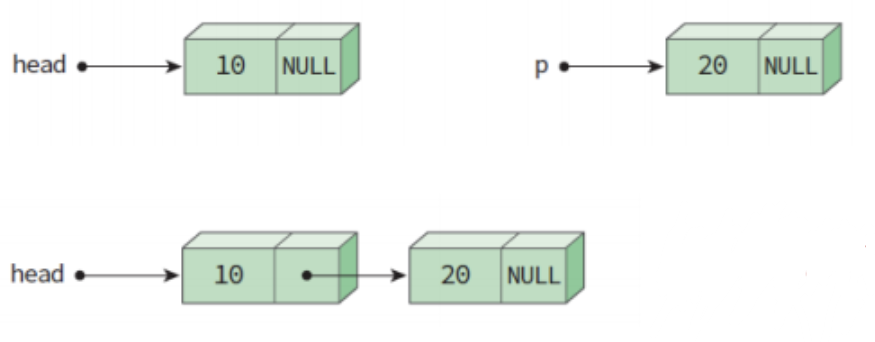
노드 생성
링크드 리스트 클래스 생성
ListNode *head = NULL; head=(ListNode *)malloc(sizeof(ListNode));2번째 노드 생성
ListNode *p; p = (ListNode *)malloc(sizeof(ListNode)); p->data = 20; p->link = NULL;노드의 연결
head->link = p;
연산
- insert_first() : 리스트의 시작 부분에 항목을 삽입하는 함수
ListNode * insert_first(ListNode *head, int value){
ListNode *p = (ListNode*)malloc(sizeof(ListNode));
p->data=value;
p->link=head;
head=p;
return head;
}- insert() : 리스트의 중간 부분에 항목을 삽입하는 함수
//노드 pre 뒤에 새로운 노드 삽입
ListNode* insert(ListNode *head, ListNode *pre, int value){
ListNode *p = (ListNode *)malloc(sizeof(ListNode));
p->data=value;
p->link=pre->link;
pre->link=p;
return head;
}- delete_first() : 리스트의 첫 번째 항목을 삭제하는 함수
ListNode* delete_first(ListNode *head){
ListNode *removed;
if (head==NULL) return NULL;
removed=head;
head=removed->link;
free(removed);
return head;
}- delete() : 리스트의 중간 항목을 삭제하는 함수
ListNode* delete(ListNode *head, ListNode *pre){
ListNode *removed;
removed=pre->link;
pre->link=removed->link;
free(removed);
return head;
}- print_list() : 리스트를 방문하여 모든 항목을 출력하는 함수
void print_list(ListNode *head){
for (ListNode *p = head; p!=NULL; p=p->link)
printf("%d->",p->data);
printf("NULL \n");
}2. 원형 연결 리스트
마지막 노드의 링크가 첫 번째 노드를 가리키게 하여 리스트의 구조를 원형으로 만든 연결 리스트
링크를 따라 순회하면 이전 노드에 접근 가능
즉, 한 노드에서 다른 모든 노드로 접근이 가능!
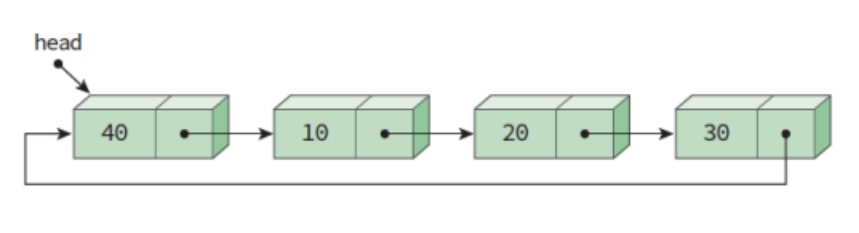
보통 헤드포인터가 마지막 노드를 가리키게끔 구성하면 리스트의 처음이나 마지막에 노드를 삽입하는 연산이 단순 연결 리스트에 비하여 용이
연산
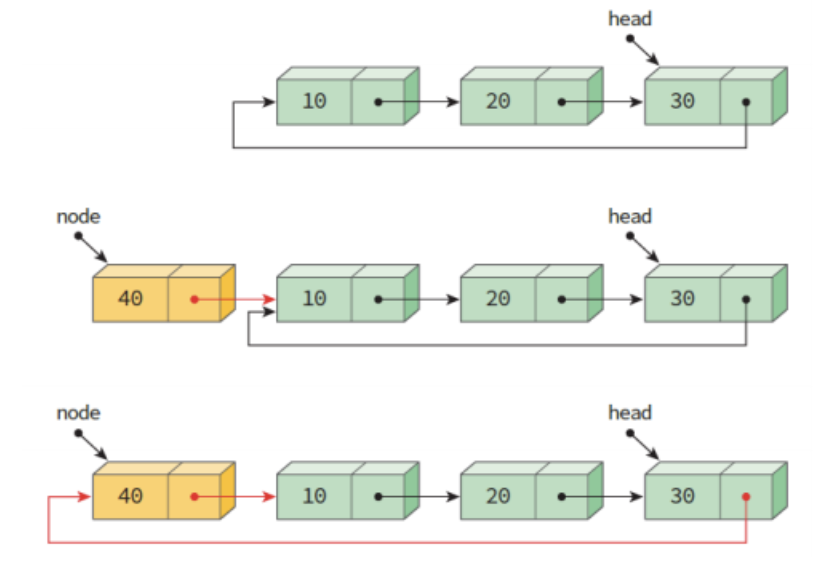
- insert_first()
ListNode* insert_first(ListNode* head, int data){
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
if (head==NULL){
head = node;
node -> link = head;
}
else {
node->link = head->link;
head->link = node;
}
return head;
}
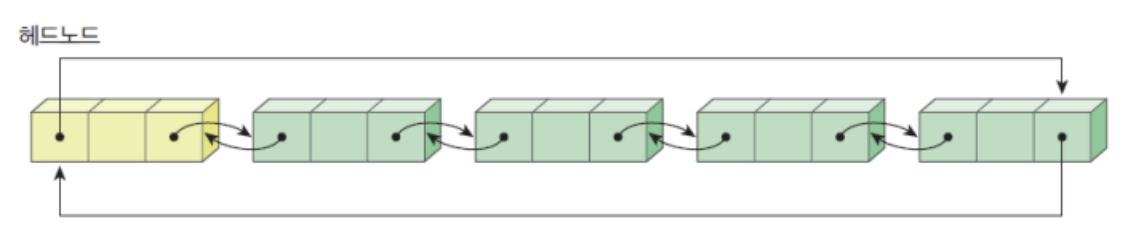
- insert_last()
ListNode* insert_first(ListNode* head, int data){
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->data = data;
if (head==NULL){
head = node;
node -> link = head;
}
else {
node->link = head->link;
head->link = node;
head = node; //insert_head와 이 부분만 바뀜
//새로 들어간 부분이 새로운 마지막이 되기 때문에 head 포인터를 옮겨준다.
}
return head;
}
3. 이중 연결 리스트 (double linked list)
단순 연결 리스트의 문제점 : 선행 노드를 찾기가 힘들다
해결 -> 원형 연결 리스트의 문제점 : 전체 리스트를 한바퀴 순회해야 한다.
해결 -> 이중 연결 리스트!하나의 노드가 선행 노드와 후속 노드에 대한 양쪽 방향의 링크를 가지는 리스트
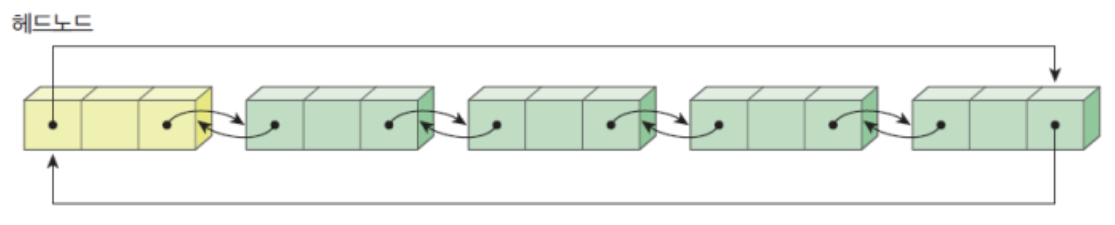
헤드 노드
: 데이터를 가지지 않고 단지 삽입, 삭제 코드를 간단하게 할 목적으로 만들어진 노드
헤드 포인터와의 구별 필요
공백 상태에서는 헤드 노드만 존재
👾 노드의 구조
typedef struct DlistNode{
int data;
struct DlistNode *llink;
struct DlistNode *rlink;
} DlistNode;단점
- 공간을 많이 차지하고 코드가 복잡
연산
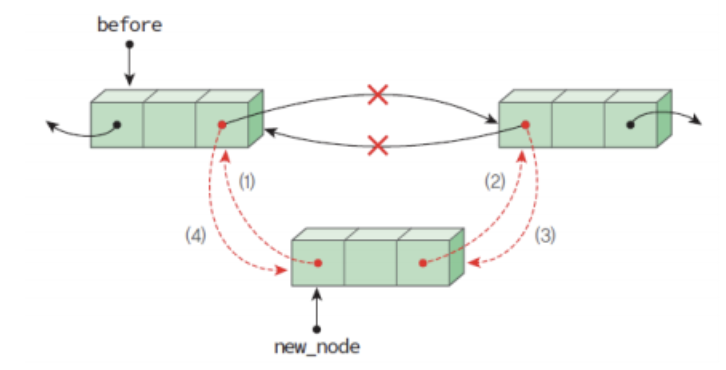
- dinsert()
void dinsert(DListNode *before, int data){
DListNode *newnode = (DListNode *)malloc(sizeof(DListNode));
strcpy(newnode->data, data);
newnode->llink = before;
newnode->rlink = before->rlink;
before->rlink->llink = newnode;
before->rlink = newnode;
}
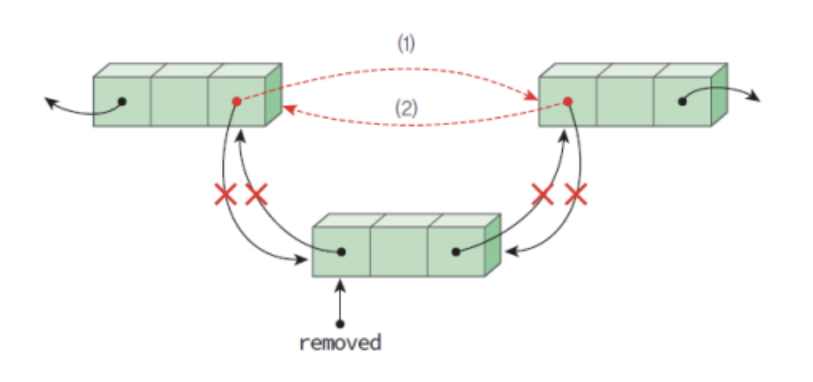
- ddelete()
void ddelete(DListNode* head, DListNode* removed){
if (removed==head) return; //지울 것이 없는 상태
removed->llink->rlink = removed->rlink;
removed->rlink->llink = removed->llink;
free(removed);
}
출처 : 이승수 교수님의 자료구조 ppt
문제풀이
[위의 코드는 모두 c언어지만 문제풀이는 c++ 로 해보았다.]
#include <iostream>
#include <string>
using namespace std;
class Node {
public:
char data;
Node* llink;
Node* rlink;
};
// L 포인터를 왼쪽으로 옮김
// D 포인터를 오른쪽으로 옮김
// B 왼쪽 Node 삭제
// P $ 왼쪽에 Node 추가
Node* init(Node* temp) {
temp = new Node();
temp->llink = NULL;
temp->rlink = NULL;
temp->data = 0;
return temp;
}
Node* leftcursor(Node* cursor) {
if (cursor->llink == NULL) {
return cursor;
}
cursor = cursor->llink;
}
Node* rightcursor(Node* cursor) {
if (cursor->rlink == NULL) return cursor;
cursor = cursor->rlink;
}
Node* put(Node* cursor, int data) {
if (cursor == NULL) {
cursor = init(cursor);
cursor->data = data;
return cursor;
}
Node* newnode = new Node();
newnode->data = data;
newnode->llink = cursor;
newnode->rlink = cursor->rlink;
cursor->rlink = newnode;
return newnode;
}
Node* insert(Node* cursor, int data) {
if (cursor == NULL) {
cursor = init(cursor);
cursor->data = data;
return cursor;
}
Node* newnode = new Node();
newnode->data = data;
newnode->llink = cursor;
newnode->rlink = cursor->rlink;
newnode->llink->rlink = newnode;
if (newnode->rlink !=NULL) newnode->rlink->llink = newnode;
return newnode;
}
Node* remove(Node* cursor) {
if (cursor->llink == NULL) {
return cursor;
}
else if (cursor->rlink == NULL) {
cursor = cursor->llink;
}
Node* removed = cursor;
removed->llink->rlink = cursor->rlink;
if (cursor->rlink !=NULL) cursor->rlink->llink = removed->llink;
cursor = removed->llink;
free(removed);
return cursor;
}
void print_list(Node* cursor) {
Node* current = cursor;
while (current->llink != NULL) {
current = current->llink;
}
while (current->rlink != NULL) {
cout << current->data;
current = current->rlink;
}
cout << current->data <<'\n';
}
int main() {
string s;
int num;
Node* cursor = new Node();
cin >> s >> num;
for (int i = 0; i < s.size(); i++) {
cursor = put(cursor, s[i]);
}
cursor = put(cursor, 0);
char command;
for (int i = 0; i < num; i++) {
cin >> command;
switch (command) {
case 'P':
char word;
cin >> word;
cursor = insert(cursor, word);
break;
case 'L':
cursor = leftcursor(cursor);
break;
case 'B':
cursor = remove(cursor);
break;
case 'D':
cursor = rightcursor(cursor);
break;
}
}
print_list(cursor);
}완벽한 백준 풀이는 아니다. NULL처리를 하는 것이 아닌 헤드노드 하나로 처음과 끝을 다뤄야하지만 나는 처음과 끝 노드를 따로 넣어주어 틀렸다고 결과가 나온다. C++로는 이렇게 푸는구나하고 아는 것에 의의를 둔다.
