이번에 정리할 논문은 LIME(Local Interpretable Model-Agnostic Explanation) 기법을 제안한 “Why Should I Trust You?” Explaining the Predictions of Any Classifier 입니다.
LIME은 모델의 종류와 무관하게(model agnostic) 각 instance 주변에 국소적으로 해석가능한 sparse linear model로 근사해(Local Interpretable) 각 instance에서 모델의 inference를 설명합니다(Explanation).
LIME의 설명력을 입증하기 위해서 다른 ML논문처럼 inference 결과의 metric을 비교하는 정도가 아니라, 다양한 설정으로 실험을 했는데 이 점이 흥미롭게 느껴졌습니다.
Introduction
본 논문에서는 2가지의 관점에서 trust의 정의를 제시합니다.
trusting a prediction
개별적인 Prediction이 의사결정의 근거로 사용될 수 있는지에 대한 측면입니다.
사람들은 각자가 생각하는 task에 대한 prior knowledge를 바탕으로 model의 prediction결과를 수용할지 말지를 결정하게됩니다.
trusting a model
학습에 사용되지 않은 real world의 데이터에 대해서 reasonable하게 행동할 것인가에 대한 측면입니다. Data Leakage, Dataset Shift, metric <-> real 목표의 mismatch과 같은 상황에서 문제가 발생할 수 있습니다.
Explanation
본 논문의 Explanation은 아래 3가지 특징을 가집니다.
Interpretable Representation : 기존의 feature의 복잡도를 낮추어 이해하기 쉽게하기 위해서 task에 적합한 binary vector로 변환하여 모델에 사용합니다.
- image classification task : 이미지의 전체 pixel을 보다 grouping한 super pixel로 변환해 one hot 형식으로 활용 (확인)
- text classification task : 각 word의 존재 여부에 대한 binary vector
local fidelity: 모델의 모든 prediction을(global) faithful하게 설명하는 것은 거의 불가능한 일이기 때문에 local faithful한 설명을 하는 것을 목표로 설정합니다.
global perspective : trusting a model을 위해서 개별 데이터가 아닌 전체 데이터에 대한 설명이 필요합니다. 전체 데이터를 대표할 수 있는 데이터를 선정해 이에 대한 설명을 제시하는 방식으로 접근합니다.
LIME
Fidelity-Interpretable Trade-off
위 수식에서 은 local fidelity를, 는 model complexity를 의미합니다. 따라서 두 항의 합을 minimize하는 g는 두 항의 trade-off사이에서 결정됩니다.
Local Fidelity
local fidelity는 설명해야할 함수 f를 해석가능한 함수 g가 x 근방에서 얼마나 잘 근사하는지를 의미합니다.
수식에서 는 f(z)와 g(z)의 차이를 의 가중치를 적용해 집계하는 함수입니다.
따라서 는 x로부터 멀어질 수록 감소하는 함수가 활용됩니다.
또 함수 f의 경우에는 원래 feature 그대로 z가 대입되지만, g의 경우에는 z의 Interpretable Representation인 z'가 대입되는 것을 확인할 수 있습니다.
Model Complexity
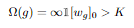
Model Complexity는 위 식처럼 다뤄질 수 있는데, 은 L0 norm으로 벡터의 크기 즉 parameter의 개수를 의미하고,
1은 indicator function으로 복잡도를 제한하기 위해서 설정한 K를 넘는 경우 아닌 경우 0의 값을 가지는 식입니다.
K개의 feature를 선정하기 위해서 K-Lasso와 같은 알고리즘이 활용될 수 있습니다.
Sparse Linear Explanations

전체적인 과정은 N개의 인접한 sample에 대해서 K-Lasso 알고리즘을 통해 얻은 coefficient로 feature importance를 계산하는 과정이였습니다.
Submodular Pick
Formulation
전체 데이터셋에 대해서 모델의 작동을 설명할 수 있는 대표성을 가지는 sample을 선정하기 위한 과정입니다.
- budget : B, set of instances : X
- explanation matrix :
- global importance
- coverage for pick =
- Pick :
값은 single instance 에서의 j번째 explanation 변수의 importance입니다.
따라서 는 j번째 explanation 변수의 global importance이고(task에 따라 달리 정의될 수 있음),
는 선정한 instance V의 explanation(g) 중 feature j가 선정된 경우에만 해당 feature의 global importance를 합산합니다.
즉 importance가 높은 순으로 더 많은 feature를 선정한 instance가 선정될수록 높게 계산되는 함수입니다.
Algorithm

위의 를 순차적으로 greedy한 방식으로 찾아내는 방식을 제안했습니다.
Simulated User Experiment
Are explanation faithful to the model?
본 논문에서는 faithful of explanation을 측정하기 위해서 interpretable한 정도를 평가했습니다.
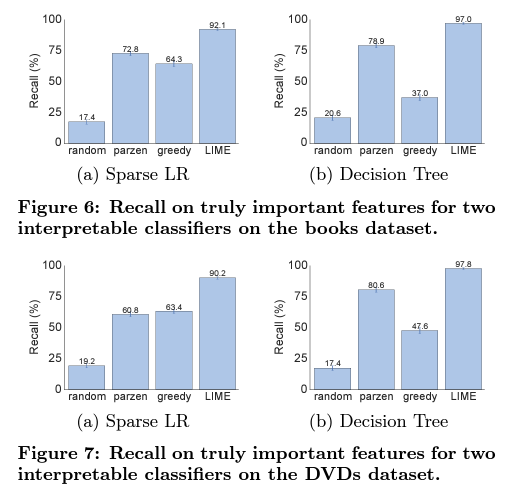
사전에 모델에서 중요하게 여겨야 할 gold set of feature를 train set에서 파악하고, test set에서 생성한 explanation에 대해서 gold set에 속하는 feature가 등장하는지 여부를 관찰해 분류지표를 평가했습니다.
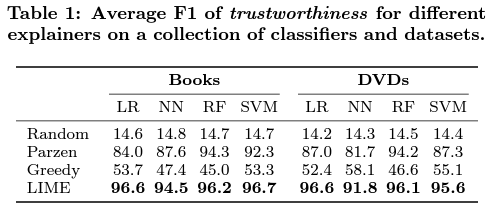
Should I trust this prediction?
untrustworthy feature를 무작위로 전체 중 25% 선정했습니다.
untrustworthy label은 위 feature를 제거하고 prediction을 얻었을 때 그 결과가 변경된 경우로 정의하였습니다. 그리고 학습 기법들이 K개의 feature를 선정했을 때 이들을 포함했는 지를 관찰해 분류지표로 평가했습니다.
Can I trust this model?
10개의 noisy한 feature를 중요해보이게끔 등장시켜서 추가해 학습 기법들이 K개의 feature를 선정했을 때 이들이 포함했는지를 관찰하고 분류지표로 평가했습니다.
Evaluation with Human Subject
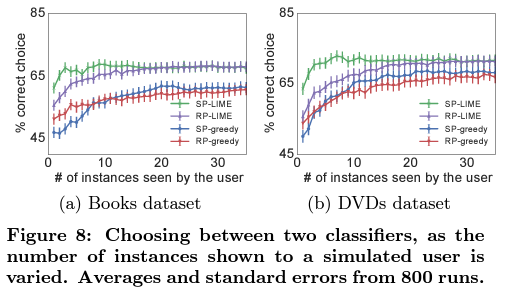
Can users select the best classifier?
explanation은 잘 일반화될 수 있는 모델을 고를 수 있게 도움을 주어야 합니다.
본 논문에서는 1) original dataset으로 학습한 모델과 2) 일반화될 수 없는 단어를 제거한 cleaned dataset으로 학습한 모델을 비교했습니다.
validation accuarcy는 1)이 높았지만, test accuarcy는 2)가 높았습니다. 이는 accuracy와 같은 하나의 지표만으로 모델을 비교했을 때 잘못 선택할 수 있음을 의미합니다.
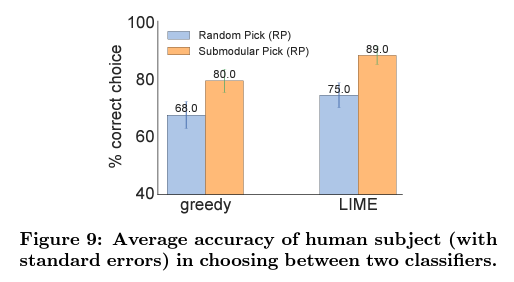
데이터셋에 대한 배경지식을 가진 사람들을 대상으로 각 기법에 대해서 설명과 함께 1)과 2)를 구분하는 task를 제시했을 때 LIME기법을 활용한, 또 Submodular로 sample을 선정한 경우 더 잘 구분할 수 있었습니다.
Do explanation lead to insights?

데이터 셋을 배경을 바탕으로 선택해 배경에 눈이 있으면 "wolf"로 예측하고 아닌 경우에 "Husky"로 예측하는 bad classifier를 추가로 학습시켰습니다.
그 뒤 10개의 test 결과와 explanation을 제시해 아래를 조사했다고 합니다.
(1) 믿을 수 있는 classifier 인지?
(2) 왜 그렇게 생각하는지?
(3) 모델이 어떻게 작동한다고 생각하는지?
이때 lime을 통해 생성된 설명이 같이 제시되었을 때 prediction과 label만 있을 때에 비해
bad model을 신뢰하는 비율을 낮추고, 눈을 잠재적인 feature로 알게된 비율이 높아져 효과가 있음을 보였습니다.
