Learning Prototype via Placeholder for Zero-shot Recognition 제1부
Learning Prototype via Placeholder for Zero-shot Recognition
Abstract
Zero-shot learning (ZSL) aims to recognize unseen classes by exploiting semantic descriptions shared between seen classes and unseen classes.
Current methods show that it is effective to learn visual-semantic alignment by projecting semantic embeddings into the visual space as class prototypes. However, such a projection function is only concerned with seen classes. When applied to unseen classes, the prototypes often perform suboptimally due to domain shift. In this paper, we propose to learn prototypes via placeholders, termed LPL, to eliminate the domain shift between seen and unseen classes. Specifically, we combine seen classes to hallucinate new classes which play as placeholders of the unseen classes in the visual and semantic space. Placed between seen classes, the placeholders encourage prototypes of seen classes to be highly dispersed. And more space is spared for the insertion of well-separated unseen ones. Empirically, well-separated prototypes help counteract visual-semantic misalignment caused by domain shift. Furthermore, we exploit a novel semantic-oriented fine-tuning to guarantee the semantic reliability of placeholders. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of LPL over the state-of-the-art methods. Code is available at https://github.com/zaiquanyang/LPL
ZSL(Zero-shot learning)은 보이는 클래스와 보이지 않는 클래스 간에 공유되는 의미론적 설명을 활용하여 보이지 않는 클래스를 인식하는 것을 목표로 합니다.
현재 방법은 시맨틱 임베딩을 클래스 프로토타입으로 시각적 공간에 투영하여 시각적-의미적 정렬을 학습하는 것이 효과적임을 보여줍니다. 그러나 이러한 프로젝션 함수는 표시된 클래스에만 관련됩니다. 보이지 않는 클래스에 적용할 때 프로토타입은 종종 영역 이동으로 인해 최적이 아닌 성능을 발휘합니다. 본 논문에서는 보이는 클래스와 보이지 않는 클래스 사이의 도메인 이동을 제거하기 위해 LPL이라고 하는 자리 표시자를 통해 프로토타입을 학습할 것을 제안합니다. 구체적으로, 우리는 보이는 클래스를 결합하여 시각적 및 의미론적 공간에서 보이지 않는 클래스의 자리 표시자 역할을 하는 새로운 클래스를 환각시킵니다. 표시된 클래스 사이에 배치된 자리 표시자는 표시된 클래스의 프로토타입이 많이 분산되도록 합니다. 그리고 잘 분리된 보이지 않는 삽입을 위해 더 많은 공간이 확보됩니다. 경험적으로 잘 분리된 프로토타입은 영역 이동으로 인한 시각적-의미적 불일치를 방지하는 데 도움이 됩니다. 또한 자리 표시자의 의미론적 신뢰성을 보장하기 위해 새로운 의미론적 미세 조정을 활용합니다. 5개의 벤치마크 데이터 세트에 대한 광범위한 실험은 최첨단 방법에 비해 LPL의 상당한 성능 향상을 보여줍니다. 코드는 https://github.com/zaiquanyang/LPL에서 사용할 수 있습니다.
1 Introduction
Inspired by the human cognitive system, zero-shot learning (ZSL) was proposed to identify unseen classes by utilizing semantic embeddings (e.g., attributes [Lampert et al., 2009] or text descriptions [Reed et al., 2016] ) to transfer knowledge from seen domain to unseen domain. The ZSL can be categorized into conventional and generalized settings according to the different classes that a model sees in the test phase. In conventional ZSL, the test images from the unseen domain will be recognized. And the more challenging generalized ZSL (GZSL) [Xian et al., 2017] aims to predict the test images belonging to both the seen and unseen domains.
인간 인지 시스템에서 영감을 받은 ZSL(Zero-shot Learning)은 시맨틱 임베딩(예: 속성[Lampert et al., 2009] 또는 텍스트 설명[Reed et al., 2016])을 활용하여 보이지 않는 클래스를 식별하여 전송하도록 제안되었습니다. 보이는 영역에서 보이지 않는 영역으로의 지식. ZSL은 모델이 테스트 단계에서 보는 다양한 클래스에 따라 기존 설정과 일반 설정으로 분류할 수 있습니다. 기존 ZSL에서는 보이지 않는 도메인의 테스트 이미지가 인식됩니다. 그리고 더 어려운 일반화 ZSL(GZSL) [Xian et al., 2017]은 보이는 영역과 보이지 않는 영역 모두에 속하는 테스트 이미지를 예측하는 것을 목표로 합니다.
Domain shift [Fu et al., 2015] is an intractable problem in ZSL, due to the underlying difference between data distributions of seen domain and unseen domain. Only built on seen domain, the visual-semantic alignment is often distorted and loses desired discrimination especially for semantically similar categories of unseen domain. Early ZSL methods [Bucher et al., 2016] learn projecting visual features into semantic space to improve semantic representative capability of the features and eliminate the domain shift. However, some pioneers argue that taking semantic space as the projection space is less discriminating due to the hubness problem [Radovanovic et al., 2010]. When high-dimensional visual features are mapped to a low-dimensional semantic space, the shrink of feature space would aggravate the hubness problem that some instances in the high-dimensional space become the nearest neighbors of a large number of instances [Liu et al., 2020]. To tackle these problems, CVCZSL[Li et al., 2019] proposes mapping semantic embeddings to visual space and treats the projected results as class prototypes. Though the prototypes of seen classes are highly discriminative, it is still suboptimal due to the lack of unseen classes in the training phase.
도메인 이동[Fu et al., 2015]은 보이는 도메인과 보이지 않는 도메인의 데이터 분포 간의 근본적인 차이로 인해 ZSL에서 다루기 힘든 문제입니다. 보이는 영역에만 구축된 시각적-의미적 정렬은 종종 왜곡되며 특히 보이지 않는 영역의 의미론적으로 유사한 범주에 대해 원하는 식별을 잃습니다. 초기 ZSL 방법[Bucher et al., 2016]은 시각적 특징을 의미론적 공간에 투사하여 특징의 의미론적 표현 능력을 향상시키고 영역 이동을 제거하는 방법을 학습합니다. 그러나 일부 선구자들은 의미 공간을 프로젝션 공간으로 취하는 것이 허브성 문제로 인해 덜 차별적이라고 주장합니다[Radovanovic et al., 2010]. 고차원의 시각적 특징이 저차원의 의미 공간에 매핑될 때 특징 공간의 축소는 고차원 공간의 일부 인스턴스가 많은 수의 인스턴스의 가장 가까운 이웃이 되는 허브성 문제를 악화시킬 것입니다 [Liu et al. , 2020]. 이러한 문제를 해결하기 위해 CVCZSL[Li et al., 2019]은 시맨틱 임베딩을 시각적 공간에 매핑하고 투영된 결과를 클래스 프로토타입으로 처리할 것을 제안합니다. 보이는 클래스의 프로토타입은 매우 차별적이지만 훈련 단계에서 보이지 않는 클래스가 없기 때문에 여전히 차선책입니다.
Since the deep neural network (DNN) tends to predict with a subset of the most predictive features [Huang et al., 2020], embedding-based methods are limited to learning visualsemantic alignment of seen classes and generally obtain prototypes of seen classes located in a confined space as shown in Figure 1 (left). Being constricted in such a limited space, prototypes of unseen classes can easily lose the discrimination due to the disruption of the domain shift and cannot be well adapted to recognize unseen classes in ZSL setting or distinguish the unseen from seen classes in GZSL setting. As a result, to cope with the domain shift, the prototypes of unseen classes require more space for highly separable arrangements.
DNN(심층 신경망)은 가장 예측 가능한 기능의 하위 집합으로 예측하는 경향이 있기 때문에 [Huang et al., 2020] 임베딩 기반 방법은 표시된 클래스의 시각적 의미 정렬을 학습하는 것으로 제한되며 일반적으로 다음 위치에 있는 표시된 클래스의 프로토타입을 얻습니다. 그림 1(왼쪽)과 같이 밀폐된 공간. 이러한 제한된 공간에 제한되어 보이지 않는 클래스의 프로토타입은 도메인 이동의 중단으로 인해 쉽게 식별력을 잃을 수 있으며 ZSL 설정에서 보이지 않는 클래스를 인식하거나 GZSL 설정에서 보이지 않는 클래스와 보이는 클래스를 구별하는 데 잘 적응할 수 없습니다. 결과적으로 도메인 이동에 대처하기 위해 보이지 않는 클래스의 프로토타입은 분리 가능성이 높은 배치를 위해 더 많은 공간이 필요합니다.
In this work, we propose to learn prototypes via placeholders for zero-shot recognition (LPL) to mitigate the domain shift. Figure 1 indicates the motivation of our method. Building upon the idea that the unseen class usually share semantics with several seen classes, e.g., zebra is black and white animals (as gaint panda) with four legs (as tiger) and horse shape body (as horse). LPL utilizes the combination of seen classes to hallucinate both visual and semantic embeddings for new classes scattering among seen classes. As shown in Figure 1 (right), taking hallucinated classes as placeholders for unseen classes, LPL learns highly dispersed prototypes of seen classes. Thus, more space is spared to insert prototypes of unseen classes and tackle the impact of domain shift.
이 작업에서는 영역 이동을 완화하기 위해 제로 샷 인식(LPL)을 위한 자리 표시자를 통해 프로토타입을 학습할 것을 제안합니다. 그림 1은 우리 방법의 동기를 나타냅니다. 보이지 않는 클래스는 일반적으로 여러 보이는 클래스와 의미론을 공유한다는 생각을 기반으로 합니다. 예를 들어 얼룩말은 네 개의 다리(호랑이)와 말 모양의 몸(말)을 가진 흑백 동물(게인트 판다)입니다. LPL은 보이는 클래스의 조합을 활용하여 보이는 클래스 사이에 흩어져 있는 새로운 클래스에 대한 시각적 및 의미론적 임베딩을 환각시킵니다. 그림 1(오른쪽)에서 볼 수 있듯이 환각 클래스를 보이지 않는 클래스의 자리 표시자로 사용하여 LPL은 보이는 클래스의 고도로 분산된 프로토타입을 학습합니다. 따라서 보이지 않는 클래스의 프로토타입을 삽입하고 도메인 이동의 영향을 해결하기 위해 더 많은 공간이 절약됩니다.
Specifically, an effective two-steps hallucination strategy is proposed. First, we blend visual and semantic embeddings of multiple seen classes on a similarity graph respectively and control the hallucination classes to distribute around seen classes without significantly deviating from the original data.
Second, to obtain abundant classes as placeholders for unseen classes, we further interpolate between elementary hallucinated classes obtained in the previous step and the original seen classes. To prevent the semantic ambiguity of the hallucinated classes from weakening the effect of placeholders, a semantic-oriented fine-tuning strategy is proposed for preliminary visual-semantic alignment which promotes the feasibility of placeholders.
구체적으로 효과적인 2단계 환각 전략을 제안한다. 첫째, 우리는 유사도 그래프에서 여러 개의 본 클래스의 시각적 및 의미적 임베딩을 각각 혼합하고 환각 클래스가 원본 데이터에서 크게 벗어나지 않고 본 클래스 주변에 분포하도록 제어합니다.
둘째, 보이지 않는 클래스에 대한 자리 표시자로 풍부한 클래스를 얻기 위해 이전 단계에서 얻은 기본 환각 클래스와 원래 본 클래스 사이를 추가로 보간합니다. 환각 클래스의 의미적 모호성이 플레이스홀더의 효과를 약화시키는 것을 방지하기 위해 플레이스홀더의 타당성을 촉진하는 예비 시각적-의미적 정렬을 위한 의미론적 미세 조정 전략을 제안합니다.
Our contribution is three-fold: (1) We propose placeholder-based prototype learning for zero-shot recognition (LPL), which hallucinates new classes playing as placeholders of unseen classes and encourages learning wellseparated prototypes for unseen classes recognition. (2) With the proposed semantic-oriented fine-tuning, we prevent generating substandard hallucinated classes that trigger semantic ambiguity, which promotes the faithfulness of the placeholders. (3) With extensive experiments and ablation study on five benchmarks, we demonstrate that the proposed LPL achieves new state-of-the-art ZSL performance.
우리의 기여는 세 가지입니다. (1) 우리는 새로운 클래스가 보이지 않는 클래스의 플레이스홀더 역할을 하는 것을 환각시키고 보이지 않는 클래스 인식을 위해 잘 분리된 프로토타입 학습을 장려하는 LPL(zero-shot recognition)을 위한 플레이스홀더 기반 프로토타입 학습을 제안합니다. (2) 제안된 의미론적 미세 조정을 통해 의미론적 모호성을 유발하는 표준 이하의 환각 클래스 생성을 방지하여 자리 표시자의 충실성을 촉진합니다. (3) 5개의 벤치마크에 대한 광범위한 실험 및 제거 연구를 통해 제안된 LPL이 새로운 최첨단 ZSL 성능을 달성함을 입증합니다.
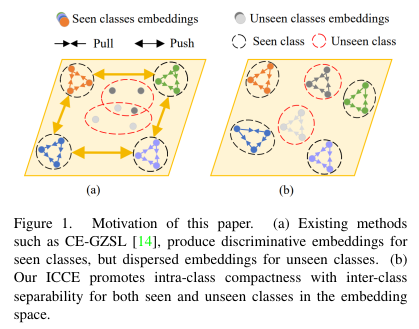
Motivation of this paper. (a) Existing methods such as CE-GZSL [14], produce discriminative embeddings for seen classes, but dispersed embeddings for unseen classes. (b) Our ICCE promotes intra-class compactness with inter-class separability for both seen and unseen classes in the embedding space.
이 논문의 동기. (a) CE-GZSL[14]과 같은 기존 방법은 보이는 클래스에 대해서는 차별적인 임베딩을 생성하지만 보이지 않는 클래스에 대해서는 분산된 임베딩을 생성합니다. (b) 당사의 ICCE는 임베딩 공간에서 보이는 클래스와 보이지 않는 클래스 모두에 대해 클래스 간 분리성을 통해 클래스 내 압축성을 촉진합니다.
