맞은데 바로 맞으면 별로 안 아프거든요?(경험담) 약간 그런 느낌으로 오히려 Lec2보다 숨이 쉬어졌습니다.
지난 시간 linear classification에서 파라미터 w를 배웠습니다.
이번 시간에는 이 w를 정량화해서 평가할 수 있게 하려고 합니다. 즉 어떤 w가 좋은지 판단하기 위함이죠.
w가 얼마나 더 좋은지가 아닌, 덜 구린지를 나타낸 것이 Loss function입니다.
이 loss를 구하는 방법은 두가지가 있습니다.
1.SVM
2.Softmax Classification
입니다.
svm
먼저 SVM를 봐보면
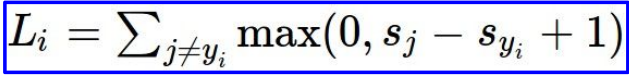
-
위의 식처럼 Loss를 정의합니다.
max(a, b)는 a와 b중에서 큰 값을 고른다는 이야기입니다.
그렇다면 여기서는 우항이 음수이면 항상 loss는 0으로만 나오겠네요. -
그리고 Sj = 잘못된 label's score
Syi = corrected label's score
입니다.
마지막에 1은 safety margine인데 아래 설명을 보면 이해가 더 잘 될겁니다.
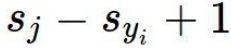 를 Sj-(Syi-1)의 식으로 보면 "Syi가 Sj가 1 이상 크면 항상 loss는 0이 된다"로 이해할 수 있습니다.
를 Sj-(Syi-1)의 식으로 보면 "Syi가 Sj가 1 이상 크면 항상 loss는 0이 된다"로 이해할 수 있습니다.
즉, loss가 제일 덜 구린게 0인데 잘못된 label's score와 corrected label's score의 gap에 1의 마진을 준 것이죠.
Q1:What happens to loss if scores change a bit?
SVM에서는 약간의 스코어 변화가 있다고 하더라고 별로 변하는 것이 없습니다.
Q2:What is the min/max possible loss?
SVM의 loss식 자체가 0을 포함한 max식이기 때문에 min=0이고 Sj는 이론상 무한대이기 때문에 max=infinty입니다.
Q3:At initializatioln W is small so all s (almost)= 0. What is the loss?
처음에는 w를 매우매우 작은 수로 초기화하기 때문에 score가 0에 근사한 값을 가집니다. 그래서
Sj-Syi+1 = 0-0+1 으로 볼 수 있어서, class가 3개인 지금은 loss가 2로 나옵니다.
- 여기서 이러한 성질을 이용해서 처음에 loss 값이 n(class)-1의 값으로 나온다면 '아, 학습이 잘 시작되었구나'하고 확인할 수 있고, 이 것은 "Sanity check"이라고 합니다.
Q4:What if the sum was over all classes?
이때까지는 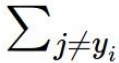
j=yi인 스코어는 더하지 않았는데,
어짜피 스코어가 같은 때는 Sj-Syi+1에서 1만 살아남아서 모든 loss가 1씩만 커집니다.
Q5:What if we used mean instead of sum?
별 의미가 없습니다. Loss는 목적이 아닌 수단입니다. loss를 minimize하는 parameter를 구함임을 잊지말라고 준 질문 같습니다.
Q6:What if we uesd sum of square?
제곱을 하면 none liner 해서 차이는 생기지만, 결과에는 영향이 없습니다.
그렇다면 굳이 수를 커지게해서 bit을 많이 이용할 필요가 없겠죠?
그렇다면 SVM's loss function 은 완벽할까요?
Nope. loss 를 0이게 하는 w값이 유일하지 않기 때문에 어떤 w가 더 좋은 파라미터인지 알 수가 없기 때문입니다.
Weight Regulation
그래서 Weight Regulation을 도입합니다. Unique한 w를 결정하기 위해서요.
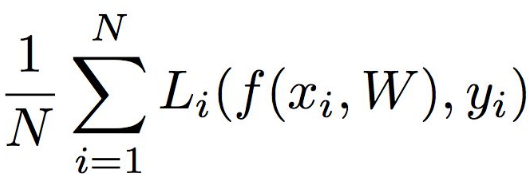
는 data loss입니다.
학습용 data에 최적화 할려고 하죠.
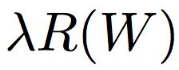
는 regularization loss입니다.
test set쪽에 최대한 일반화하려고 하는 거죠. 즉 training data에 대한 정확도는 떨어지지만 test set에서의 performance는 더 좋아지게 합니다.
이 두가지 loss는 상충됩니다.
그래서 두 loss를 잘 조절하면 학습용 data에도 fit하고 test에서도 최적화된 unique한 w를 구할 수 있게 합니다.
Regularization is a way of trading off training loss and generalization loss on test set.
Regularization 중 L2는 최대한 spread out 되어서 모든 input features를 고려할 수 있는 w를 더 선호합니다.
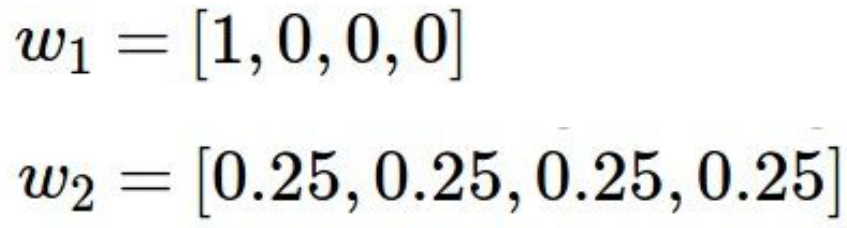
이 경우에는 모든 x vector를 반영할 수 있는 w2를 더 선호하겠네요.
Softmax Classification
그런데 regularization이 필요없이 loss를 구하는 방법도 있습니다.
Softmax Classification입니다.
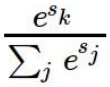
이 softmax function을 통해 score를 구합니다.
- 여기서 지수화는 linear clssifier를 통해 도출된 score를 모두 양수로 만들기 위함입니다.
- 왜 양수로 만드냐구요? 좀 이따가 log 함수에 넣어서 값을 비교할거라서요.
- 왜 log함수에 넣느냐구요? 큰 수부터 작은 수까지 비교하기 원래 수를 비교하는 것보다 용이하기 때문입니다.
위의 function에서 볼 수 있듯이 score는 확률입니다.
우리는 이 확률이 커지길 바랍니다.
하지만 Loss Function의미가 덜 구린 값을 표현해야하기 때문에 음수로 취하는 것입니다.
조작 순서를 보겠습니다.
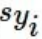
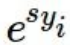
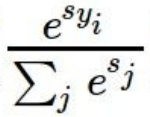
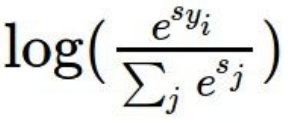
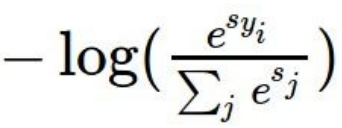
차례대로 식을 보면서 이유를 읊을 수 있으면 잘 이해하신 것 같습니다.
Q1:What is the min/max possible loss L_i?
이 질문의 답을 얻으면 왜 이렇게 많은 조작이 필요했는지 이해할 수 있습니다.
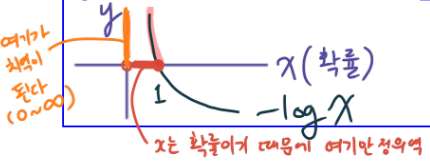
나는 진짜 그래프 잘 그려(감탄)
Q2:Usually at initialization W is small so all s (almost)= 0. What is the loss?
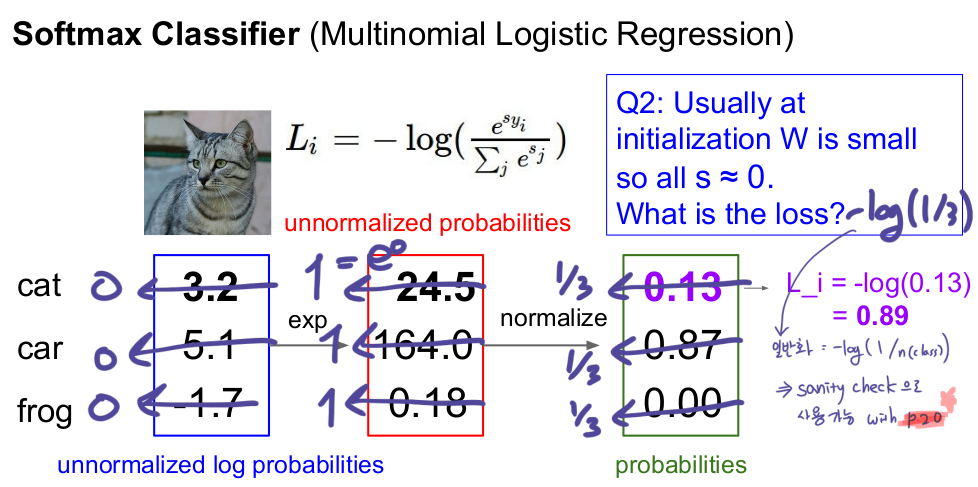
가장 간단히 정리하자면
SVM은 매우 둔감(그래프도 liner함)
Softmax는 매우 민감(모든 input을 챙기니까)
혹시 제가 잘못 이해한게 있다면 댓글로 알려주시면 정말 감사하겠습니다.
Thanks for
끝으로 Kyosoek Song 님 정말 감사합니다.
Thank you Song much!!
https://www.youtube.com/watch?v=KT4iD6yiqwo



꼼꼼하게 잘 작성하셨습니다 ~~ 고맙습니다 ㅎㅎ