
도입
이 글을 쓰게 된 이유
평소 올리브영 테크 블로그를 자주 보며, 문제를 어떻게 푸는지 인사이트를 얻어왔다. 그중에서 올리브영은 3개월 주기로 진행되는 올영세일마다 대규모 할인 쿠폰을 발급하는데, 이 과정에서 발생하는 순간적인 트래픽을 어떻게 감당하는지를 재밌게 보고 있었다.
그러던 중 2025년 12월 15일, "올영세일 선착순 쿠폰, 미발급 0%를 향한 여정" 이라는 글을 통해 쿠폰 미발급률을 0%에 수렴했다는 이야기를 접했다. 이 소식을 듣고 올리브영에서 중요한 쿠폰 발급 시스템이 어떻게 성장해 왔는지를 하나의 글로 정리해 보면 재밌겠다는 생각이 들었다.
이에 이번 글에서는 올리브영 테크 블로그에 공개된 사례들을 중심으로, 올리브영의 쿠폰 시스템이 어떤 문제를 마주했고 이를 어떻게 해결하며 성장해 왔는지를 하나의 흐름으로 정리해 보고자 한다.
소소한 재미
올리브영 쿠폰 시스템의 성장 과정을 살펴보기에 흥미로운 배경도 있다. 올리브영의 IT 시스템은 과거에는 CJ올리브네트웍스가 담당했으나, 2019년을 기점으로 올리브영 내부에서 직접 개발하기 시작했다. 이후 2021년 7월경부터는 개발 조직을 본격적으로 강화하며, 서비스 확장과 개선을 집중적으로 하기 시작했다.
반갑게도 올리브영 테크 블로그에는 2022년 9월 28일부터 쿠폰 시스템 개선과 관련된 글들이 순차적으로 공개되어 있다. 덕분에 올리브영이 시스템 개선을 본격화하던 시기와 맞물려, 초기 개선부터 최근까지의 변화를 흐름대로 차근차근 따라가 볼 수 있을 것으로 기대한다.
최초의 구조
가장 먼저 최초의 구조를 알아보자.
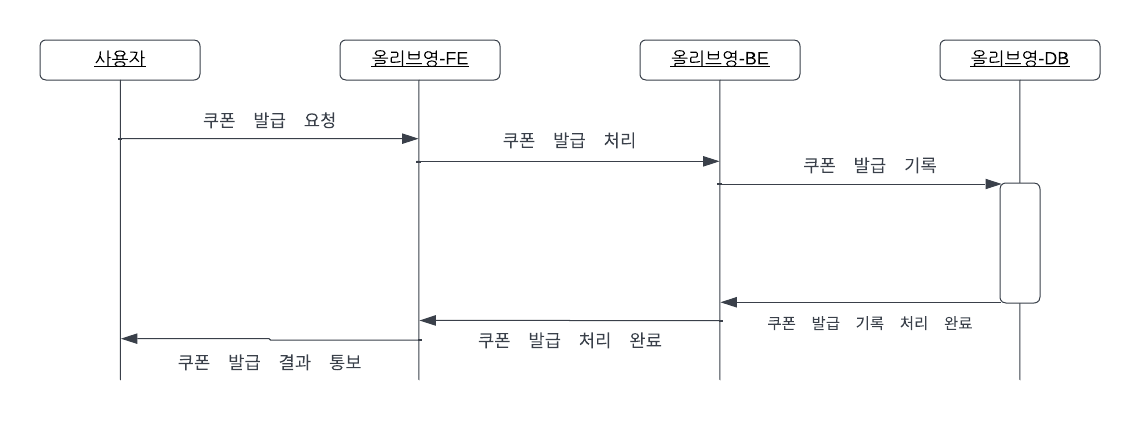
최초의 구조는 단순하게 DB를 조회하며 수량이 남아있는지 확인하고, 수량이 있다면 쿠폰을 발급하고 없다면 발급에 실패하는 구조이다.
1. 쿠폰 발급 수량 조회 개선 (22.09.28)
포인트
캐시 어사이드를 통해 DB의 과부하를 줄인다.
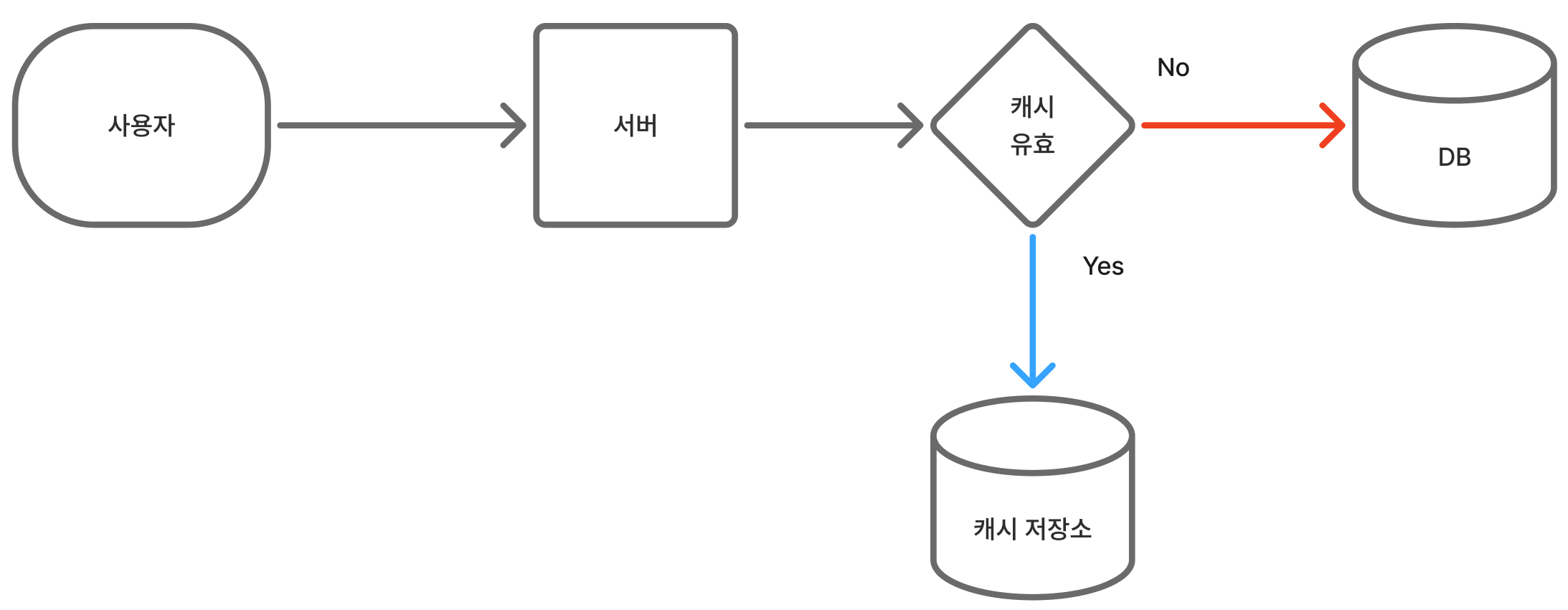
캐시 어사이드(Cache Aside) 전략이란?
캐시 어사이드는 데이터를 조회할 때 가장 많이 사용되는 캐싱 전략이다. 작동 방식은 다음과 같다.
- 캐시에서 데이터를 찾기
- 캐시에 데이터가 있으면 바로 사용
- 캐시에 데이터가 없으면 DB에서 조회한 후, 그 데이터를 캐시에 저장
왜 DB 부하가 줄어들까?
예를 들어, 올영세일 시작 시간인 00시에 100만 명이 동시에 같은 쿠폰을 조회한다고 가정해 보자.
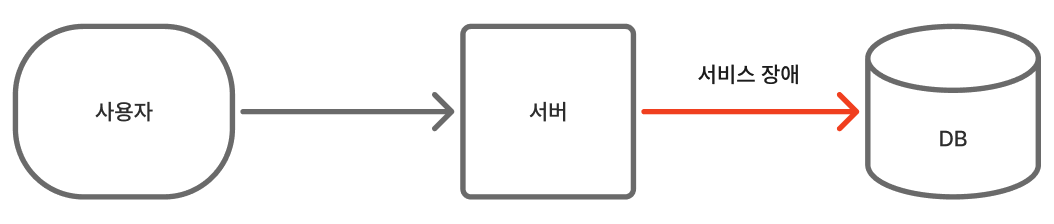
- 캐시가 없다면?
100만 번 모두 DB에 접근해야 한다. DB는 디스크에서 데이터를 읽어오기 때문에 속도가 느리고, 동시 접속자가 많으면 과부하로 서버가 다운될 수 있다.
- 캐시 어사이드 전략을 사용한다면?
첫 번째 사용자만 DB에 접근하고, 나머지 99만 9,999명은 캐시 저장소에서 데이터를 가져온다. 캐시 저장소는 보통 메모리에서 데이터를 읽기 때문에 DB보다 몇십 배 빠르며, DB에 가는 요청이 1/100만으로 줄어들어 과부하를 방지할 수 있다. 이 과정에서 캐시 저장소가 다운되더라도
DB는 살아 있으니 서비스에 장애가 발생하지는 않는다.
문제
올리브영은 2022년 6월 올영세일부터 할인 쿠폰 발급을 1회(00시) -> 2회(00시, 12시)로 늘렸다고 한다. 이로 인해 트래픽이 증가했고, 12시에는 쿠폰 이외의 트래픽도 많이 발생해서 기존 구조에서는 DB 과부하가 발생했다.
솔루션 비교
올리브영은 문제를 해결하기 위해 쿠폰 수량을 캐싱하는 전략을 선택했고, 캐시 저장소를 Redis와 Memcached 중에 어떤 것으로 선택할지 고민했다고 한다.
- Redis
- 데이터를 명시적으로 삭제 가능
- 다양한 자료구조
- 다양한 기능으로 복잡한 구조
- 메모리 파편화가 발생 가능성이 있음
- Memcached
- LRU 방식으로 데이터 자동 삭제
- Key-Value 형태만 지원
- 구조 단순
- 메모리 파편화가 발생 가능성이 낮음
이러한 상황에서 올리브영은 Redis를 선택했다. "다양한 자료구조 사용 가능"과 "명시적으로 데이터 삭제 가능"이라는 두 가지 이유 때문이다.
다양한 자료구조를 이용하면 Redis를 다양하게 사용할 수 있다. 또한 명시적으로 데이터를 삭제 할 수 있기 때문에, 트래픽이 많지 않을 때는 DB를 통해 조회할 수 있도록 할 수 있도록 만들 수도 있다.
해결
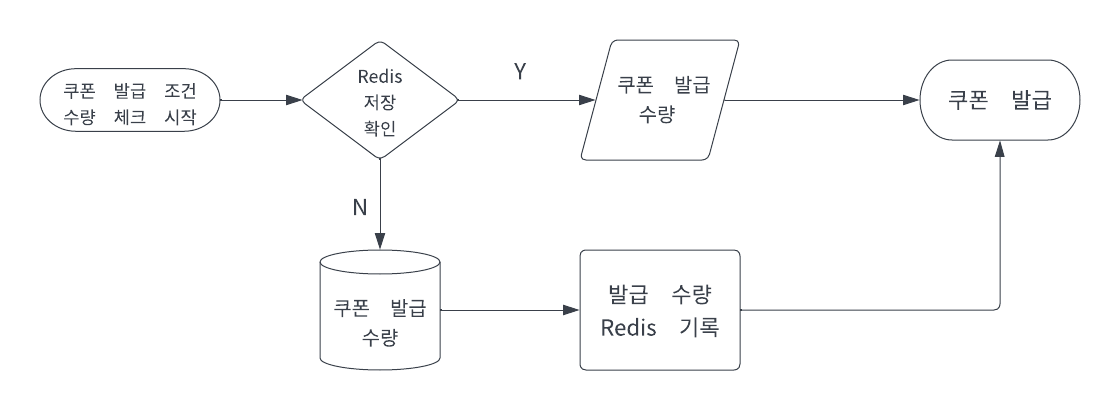
- 사용자의 쿠폰 발급 요청
- Redis에 쿠폰 수량이 저장되어 있는지 확인
- (Yes) Redis에서 수량 차감 후 쿠폰 발급
- (No) DB에서 조회해서 Redis에 저장 후 쿠폰 발급
결과
22년 9월 올영 세일부터는 안정적으로 쿠폰 수량 조회가 가능해졌다.
2. 발급 순서 개선 (23.08.07)
포인트
Redis Pub/Sub과 Worker를 통해 비동기 방식으로 변경한다.
동기 방식의 문제점
기존 동기 방식에서는 사용자가 쿠폰 발급을 요청하면, 서버가 그 작업을 완료할 때까지 사용자는 계속 기다려야 한다. 마치 은행 창구에서 한 명씩 순서대로 업무를 처리하는 것과 같다. 앞사람의 업무가 끝나야 다음 사람이 처리되기 때문에, 손님이 많아지면 대기 시간이 길어질 수밖에 없는 것이다.
Worker로 비동기 방식 구현
이러한 비동기 과정을 Worker를 여러 대 추가해서 비동기로 바꾸는 방식이다.
은행의 예시에서는 해야 할 업무와 데이터를 넘겨주면 자동으로 처리해 주는 AI가 은행에 도입됐다고 가정해보자.
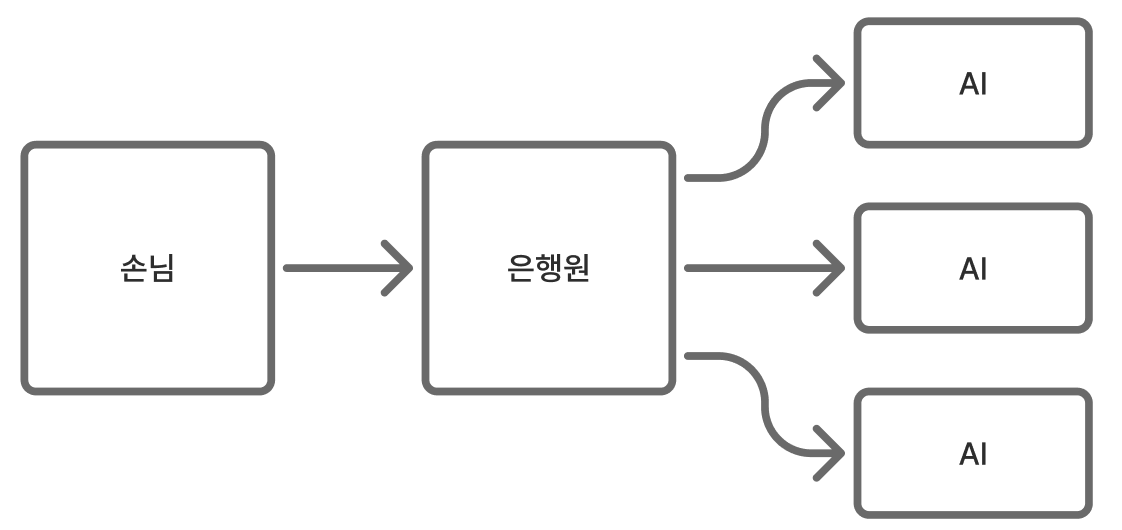
은행원은 오래 걸리는 핵심 작업을 AI(Worker)에게 넘기기 때문에, AI가 작업하는 동안 다른 손님을 응대할 수 있다.
Pub/Sub이란?
Pub/Sub은 'Publish(발행)/Subscribe(구독)'의 줄임말로, 메시지를 전달하는 방식 중 하나이다.
- Publisher(발행자): 특정 Topic(주제)으로 메시지를 발행
- Subscriber(구독자): 관심 있는 주제를 구독하고, 해당 주제로 메시지가 오면 받아서 처리
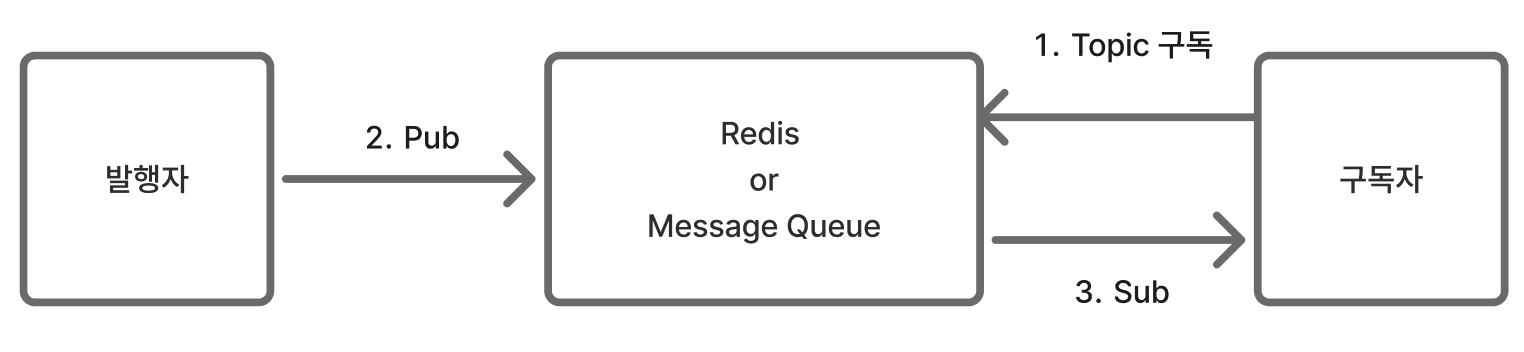
예를 들어, 사용자가 유튜브 "올영TV"를 구독하면, 올영TV에 새로운 영상이 올라 왔을 때 구독하고 있는 사용자들에게 영상이 올라왔다고 알려주는 방식이다.
위 그림에 대입하면, 발행자는 올영TV, Redis나 Message Queue는 유튜브, 구독자는 올영TV를 구독한 사용자이다.
문제
올리브영의 쿠폰 발급 시스템은 선착순이기 때문에, 요청한 순서대로 처리해야 했고 이를 구현하기 위해 동기(Sync) 방식으로 동작하고 있었다. 그렇다 보니 트래픽이 몰리면 쿠폰 발급 시 많은 시간을 기다려야 했고, 이는 사용자의 불편으로 이어지는 문제가 있었다.
솔루션 탐색
올리브영은 Redis의 Pub/Sub을 중심으로 솔루션을 탐색했다.
(필자의 추측) : Redis Pub/Sub을 중심으로 탐색한 이유는 기존에 쿠폰 시스템에서 Redis를 사용하고 있었기 때문이 아닐까 생각한다.
가장 먼저 "Redis Pub/Sub + Worker"를 이용한 방식이었다.
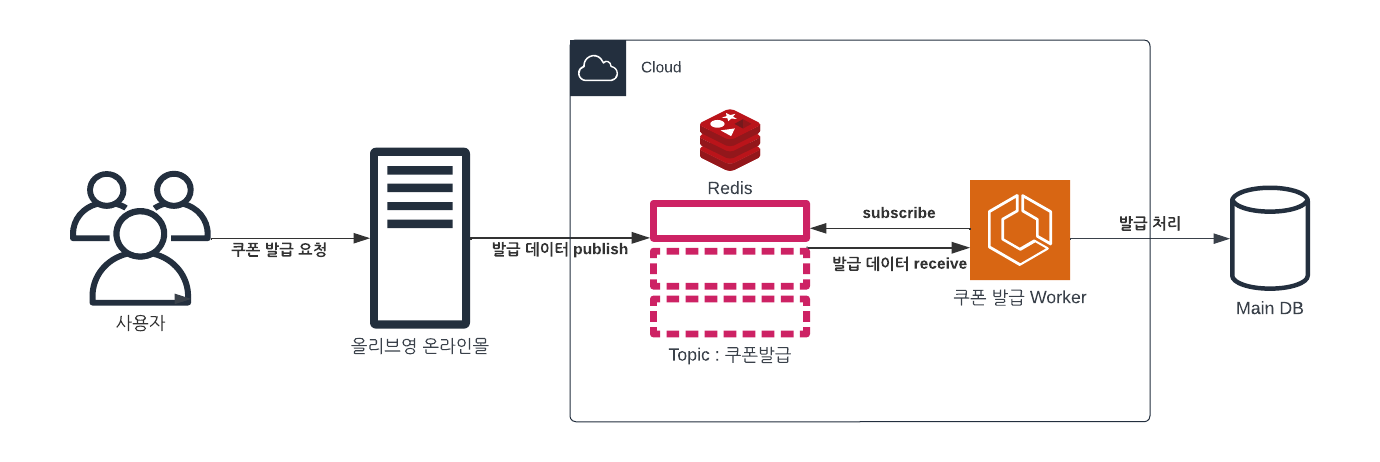
- 쿠폰 발급 Worker가 실행되면 Redis의 "쿠폰 발급" Topic을 Sub
- 사용자가 쿠폰 발급을 요청
- 서비스가 "쿠폰 발급" Topic으로 Redis에 Pub
- 쿠폰 발급 Worker가 Topic을 감지해서 쿠폰을 발행
하지만 위와 같은 방법으로 개선하고, 부하 테스트를 하는 과정에서 2개의 문제가 발생했다고 한다.
쿠폰 중복 발급 문제 발생
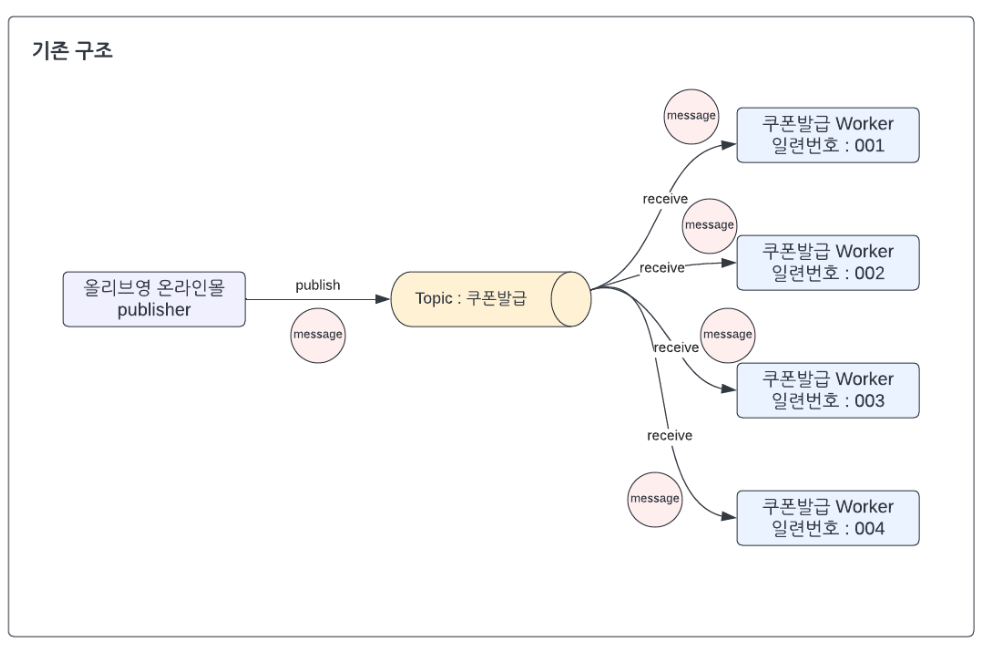
그림과 같이 Worker를 여러 개 사용하는 상황이라면, 발급된 Topic이 어떤 Worker에게 가는지 구분할 수 없어서, 모든 Worker에게 전달되게 된다. 그래서 1번 발급 요청 당 Worker의 개수만큼 쿠폰이 발급되는 문제가 생긴 것이다.
쿠폰 미발급 문제 발생
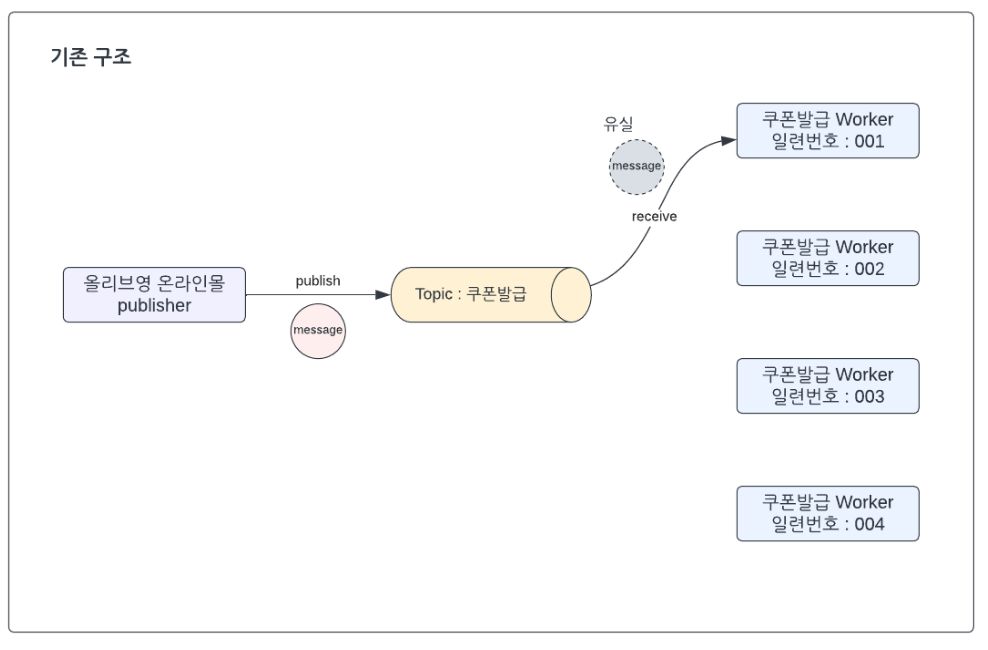
두 번째로는 Redis Pub/Sub을 사용할 때는 데이터의 전송이 100% 보장되지 않는다는 점을 주의해야 한다. 이로 인해 발급 메시지가 유실되는 문제가 발생했다.
해결 과정
이를 해결하기 위해 Redis의 List 자료구조를 사용했다고 한다. 쿠폰 발급 Worker 별로 저장소를 List로 구현했다. 그리고 여기에 관련된 쿠폰 발급 데이터를 저장하는 방식이다.
예를 들어, 일련번호가 "cp-0"인 Worker가 처리해야 할 데이터는 List의 0번에 넣는다.
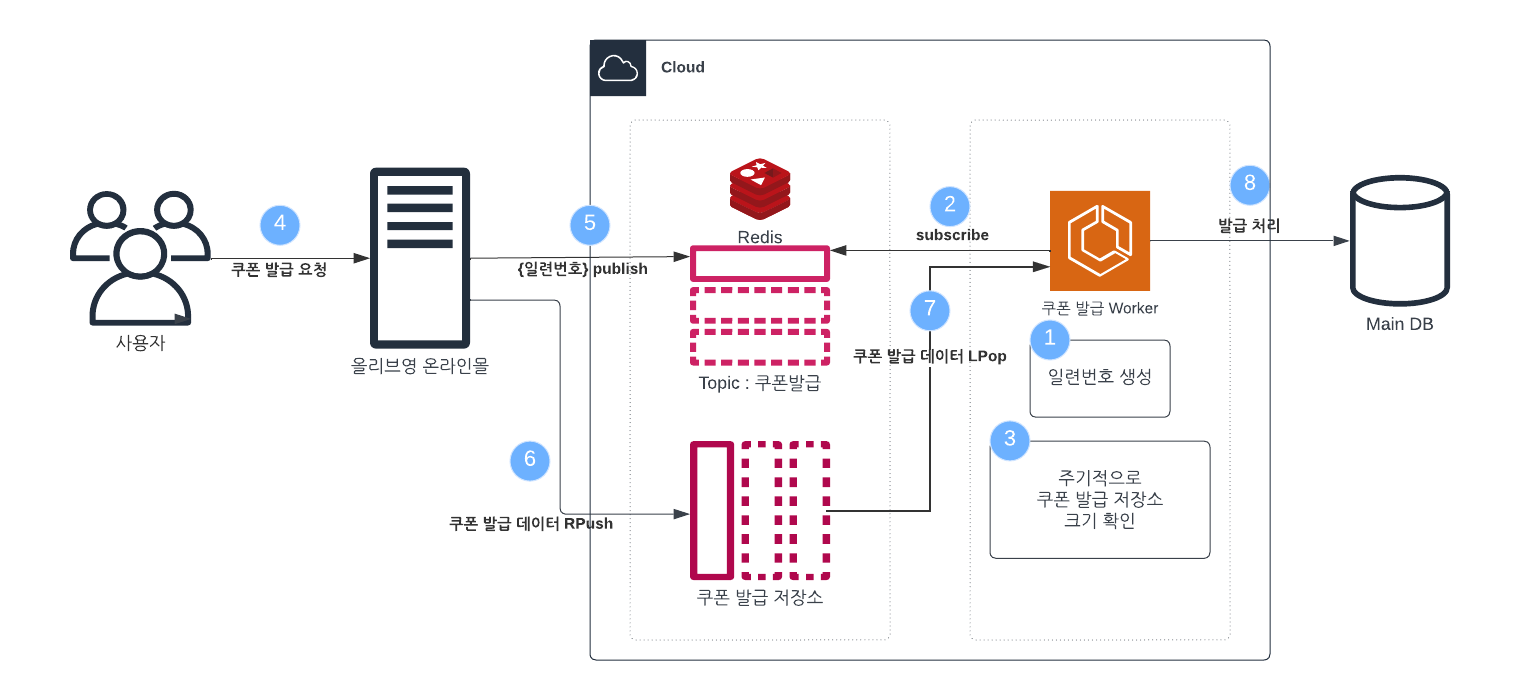
기존에 사용하던 Pub/Sub으로는 어떤 워커로 가야 하는지 일련번호를 발급받고, 실제 쿠폰 발급 관련 데이터는 List에 넣는 방식이다.
이 방식은 사전 준비와 실시간 동작으로 나뉜다.
사전 준비 (쿠폰 발급 Worker가 구동될 때)
- 쿠폰 발급 Worker 별로 일련번호를 생성
- "쿠폰 발급" Topic을 Sub
- 주기적으로 List에서 담당 구역의 크기가 0이 넘는지를 확인 (0이 넘는다면 이를 가져와서 발급 작업 실행)
실시간 동작 (사용자가 쿠폰 발급을 요청했을 때)
- 사용자가 쿠폰 발급을 요청
- Redis에 "쿠폰 발급" Topic을 Pub
- Pub/Sub을 통해 Worker로부터 일련번호를 발급
- 일련번호를 바탕으로 List에 쿠폰 발급 데이터를 저장
- Worker는 자신의 담당 구역의 크기가 0을 넘었기 때문에 해당 데이터를 바탕으로 쿠폰 발급 작업을 진행
결과
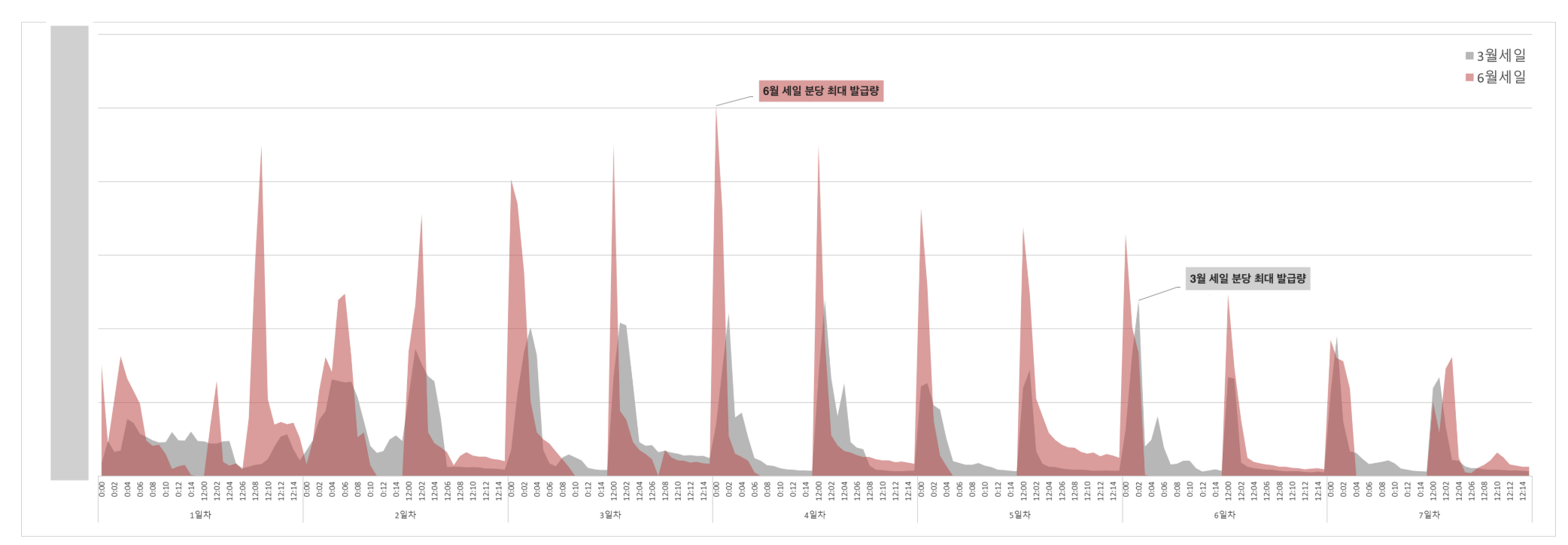
2023년 3월 올영세일 대비 분당 최대 쿠폰 발급량이 2.2배에 달하는 속도 개선이 있었다고 한다.
필자의 추가적인 궁금증
그렇다면 Redis Pub/Sub은 왜 데이터의 전송이 100% 보장되지 않을까? 구조가 매우 단순해서 publish 한 메시지는 따로 보관되지 않으며 subscriber가 수신했는지 확인하지 않아서 그렇다는데.. 왜 그렇게 설계했을까?

테크 블로그 작성자이신 "어푸님"께서 친절히 Redis 공식 홈페이지 링크를 걸어주셨지만...!
2026년 1월 현재 404가 뜨고 있기 때문에 직접 공부해 봤다.
Redis Pub/Sub에 대해 알아보자 - 왜 이렇게 설계했을까?
3. 더 큰 안정성과 확장성을 위하여 (23.09.19)
포인트
Message Queue로 문제를 해결한다.
Message Queue란?
Message Queue는 애플리케이션 간에 데이터를 주고받을 때 사용하는 중간 저장소이다. 마치 우체통처럼 발신자가 메시지를 넣어두면, 수신자가 준비됐을 때 꺼내서 처리하는 방식으로 동작한다.
왜 필요할까?
일반적으로 시스템 A가 시스템 B에게 작업을 요청할 때, A는 B가 작업을 완료할 때까지 기다려야 한다. 만약 B가 느리거나 문제가 생기면 A도 멈춰버린다. 메시지 큐를 사용하면 이런 문제를 해결할 수 있다.
예를 들면, 스타벅스에서 손님이 주문하면(메시지 전송) 바리스타가 즉시 음료를 만들 때까지 카운터에서 기다리지 않는다. 대신 주문서가 쌓이고(메시지 큐), 바리스타는 순서대로 하나씩 처리한다. 손님이 갑자기 몰려도 주문은 계속 받을 수 있고, 바리스타는 자신의 속도로 일할 수 있다.
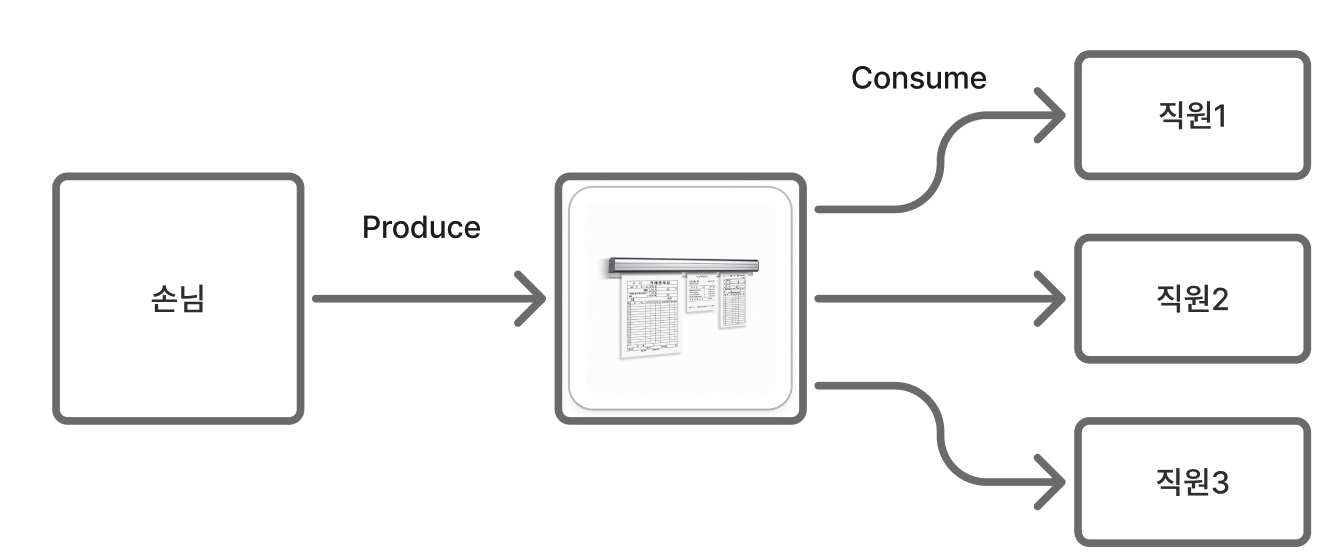
문제
기존의 Redis Pub/Sub + List + Worker 방식에는 크게 2가지 단점이 있었다.
- 확장성이 낮음
- 초대량의 트래픽 환경에서는 간혹 문제 발생
솔루션 탐색
올리브영은 Redis Pub/Sub + List + Worker 방식의 단점을 Message Queue로 해결하기로 했다. Message Queue로 사용할 기술은 RabbitMQ와 Kafka 중에 고민했다고 한다. 이때 확장성을 중심으로 고민했다.
일반적으로 대용량 데이터 처리 지표는 Kafka가 높은 것으로 알려져 있다. 하지만 올리브영은 정기 세일 기간이나 특정 마케팅 이벤트 시 트래픽이 급증하는 특성을 가진 이커머스 서비스이다. 이러한 환경에서는 피크 타임에 맞춰 시스템을 확장했다가, 평상시에는 다시 축소하는 유연한 운영이 필요하다.
Kafka의 경우 트래픽 증가에 대응해 파티션을 늘릴 수는 있지만 이벤트가 끝난 후 다시 줄일 수 없다. 이는 불필요한 리소스 비용을 계속 발생시키며 비즈니스의 변동성에 탄력적으로 대응하기 어렵게 만든다. 또한 RabbitMQ를 어떻게 활용하냐 따라서 Kafka보다 유용하게 사용할 수 있을 것이라고 생각해서 RabbitMQ를 채택했다고 한다.
해결 과정 및 결과
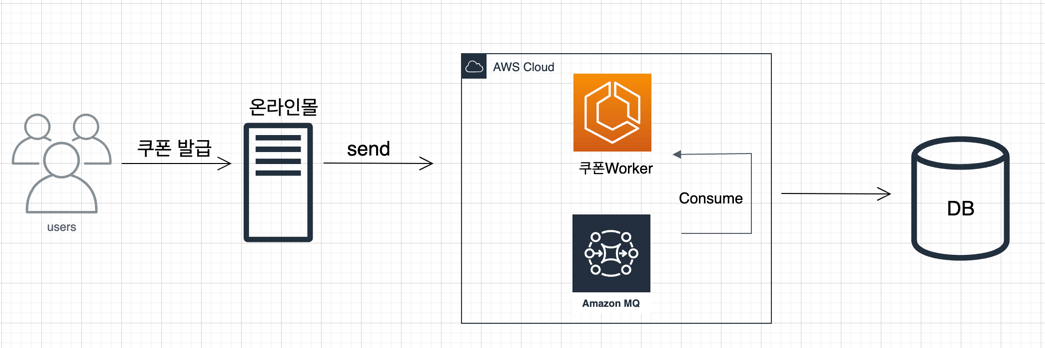
기존에 Redis Pub/Sub + List 구조가 하던 역할을 RabbitMQ로 대체했다. 기존에는 비동기 처리를 위해서 List 구조를 사용했지만, RabbitMQ는 내부적으로 concurrency를 이용하기 때문에 구조가 간결해졌다고 한다.
또한 이러한 구조를 올영세일 기간뿐만 아니라, 다양한 이벤트 기간과 기타 쿠폰 발급 시에도 적용해서 안정적인 발급 시스템을 만들 수 있었다고 한다.
4. 초대량 쿠폰 발급 개선 (24.12.11)
포인트
Message Queue의 Exchange 방식을 바꾸자.
용어정리
먼저 RabbitMQ의 동작을 설명할 수 있는 Publish, Exchange, Route, Queue, Consume에 대한 정리를 해보자.
| 역할 | 용어 |
|---|---|
| Publish | 메시지를 전송 |
| Exchange | 메시지를 수신 |
| Route | 메시지 분배 작업 |
| Consume | 메시지를 사용 |
쉽게 말하면, 메시지를 보내고(Publish) → 받아서(Exchange) → 어디로 보낼지 결정하고(Route) → 대기열에 쌓아두고(Queue) → 처리하는(Consume) 과정이다.
여러 Exchange 방식이 있지만, 이번 개선에서 주목해야 하는 것은 Direct Exchange와 Fanout Exchange이다
Direct Exchange란?

특정 Routing Key를 가진 메시지를 해당 Key에 연결된 Queue에만 전달한다. 즉, 지정된 하나의 Queue에만 메시지가 쌓이는 방식이다.
예를 들어, "쿠폰-발급-cp0"이라는 Key로 메시지를 보내면, "쿠폰-발급-cp0" Queue에만 메시지가 전달된다.
Fanout Exchange란?
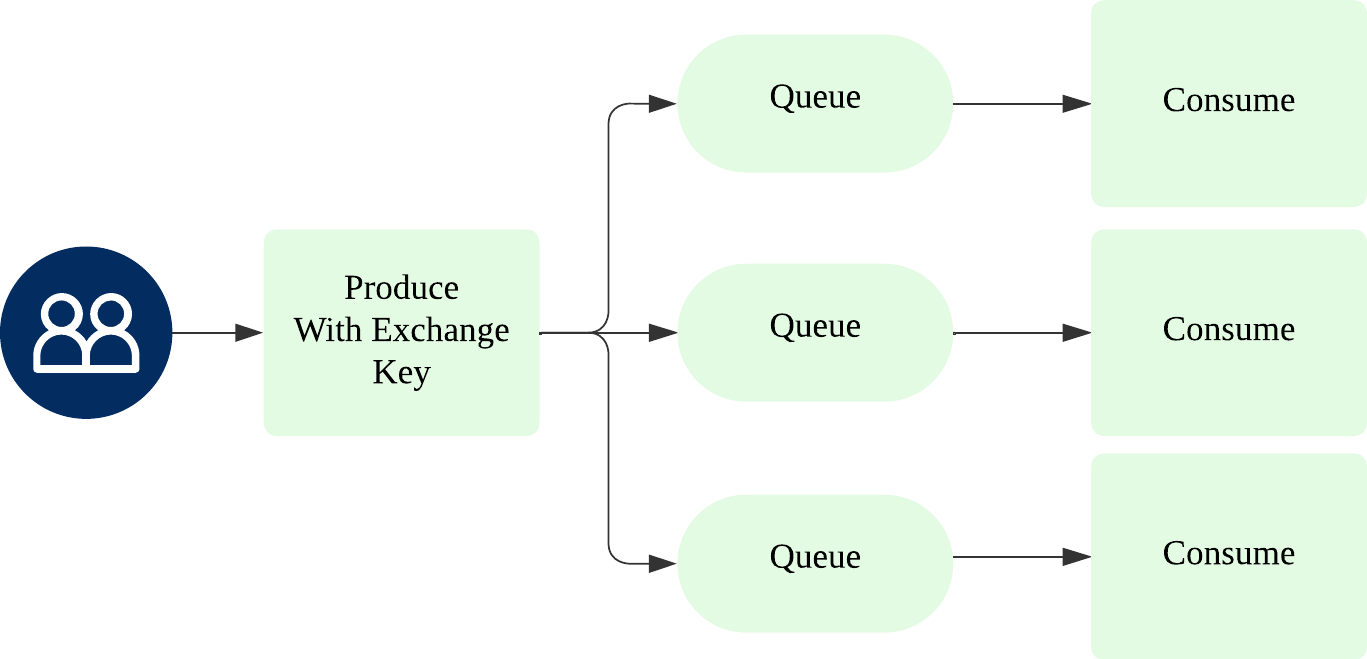
Routing Key에 상관없이 연결된 모든 Queue에 메시지를 전달한다.
예를 들어, 메시지 하나를 보내면 Queue1, Queue2, Queue3 등 연결된 모든 Queue에 동시에 전달된다.
문제
올리브영은 매월 멤버십 등급별로 제공되는 쿠폰인 "멤버십 승급 쿠폰"이 존재한다.
올리브영에는 많은 고객들이 존재하고, 가장 많은 BABY 등급은 1,000만 명 이상이 있다고 한다. 매월 BABY 등급의 고객들에게 쿠폰을 발급하는 과정에서만, 12~15시간이 소요되고 있었다고 한다.
이렇게 발급이 오래 걸리는 문제로 또 다른 문제가 발생했다고 한다.
1. 백오피스 성능 저하 문제
멤버십 승급 쿠폰 발급은 백오피스 시스템에서 담당하고 있었다. 그런데 쿠폰 발급이 오래 걸리면서 시스템 리소스가 쿠폰 발급에 집중적으로 소모되어, 백오피스에서 처리해야 하는 다른 업무들의 성능이 저하될 수 있다.
2. 시스템 배포 등의 안정성에 불편 발생
쿠폰 발급 과정이 백오피스 시스템에서 이루어지기 때문에 긴급 배포와 같은 시스템 변경이나, 다른 작업에도 영향을 받게 된다. 쿠폰 발급이 끝나기 전까지(최소 15시간)는 다른 작업을 못 하는 것이다.
3. 발급 과정이 끝나길 기다리는 내부 인력의 리소스가 불필요하게 소모됨
쿠폰 발급 시간이 오래 걸리다 보니, 발급 완료 이후에 해야하는 처리를 기다리는 담당자들도 다른 업무에 집중할 수 없어 생산성이 저하된다.
4. 지연이 생기기 때문에 고객 경험이 부적절함
쿠폰 발급이 오래 걸리기 때문에 고객의 입장에서는 승급은 했지만, 쿠폰 발급이 이루어지지 않는 (뒤늦게 발급되는) 현상이 발생할 수 있다. 이로인해 사용자 경험이 부정적으로 바뀐다.
솔루션 탐색
올리브영은 이 문제가 어디서 발생하는지 찾기 위해 기존 시스템을 분석했다.
기존 시스템은 다음과 같이 동작했다.
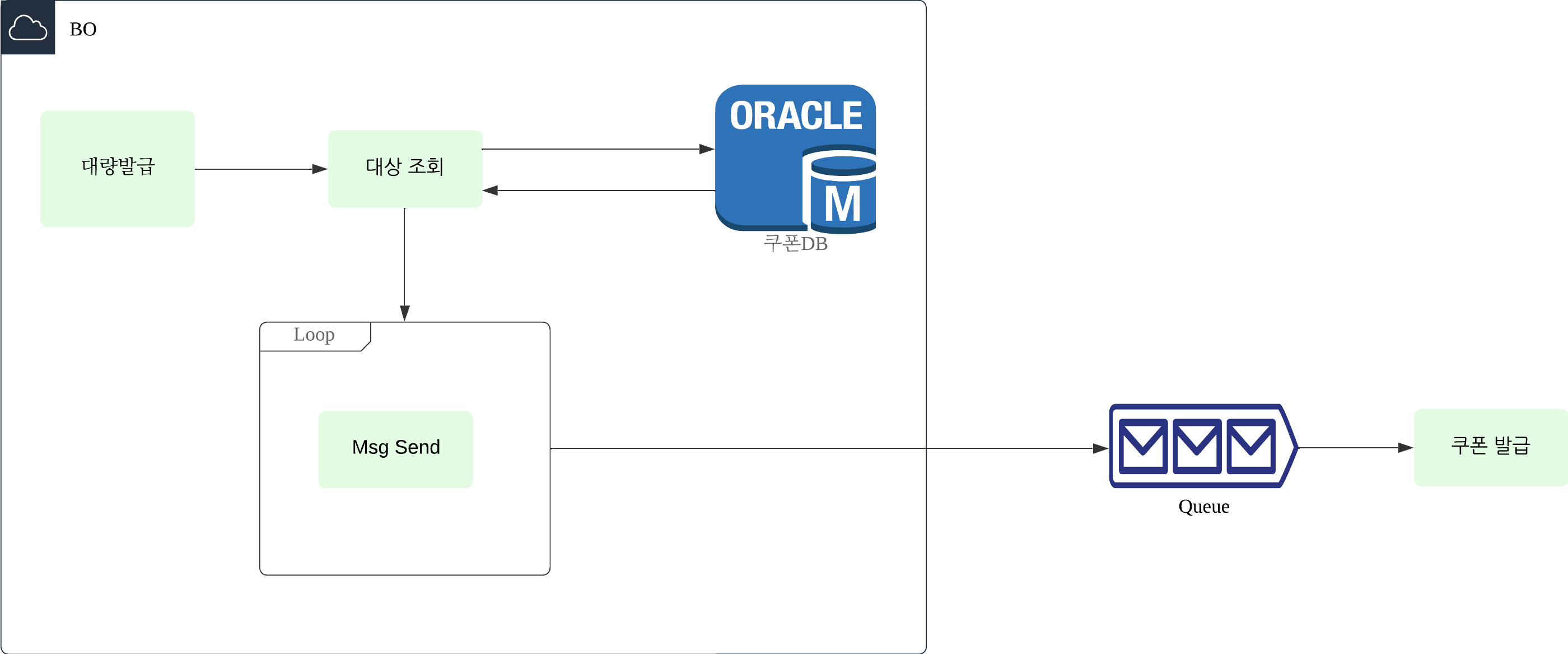
- 백오피스에서 쿠폰 대량 발급 요청
- 백오피스가 직접 발급 대상 조회
- 반복문을 돌면서 Queue에 메시지 전달
- 쿠폰 발급
올리브영은 이 구조에서 두 가지 문제점을 발견했고, 이를 개선하기 위해 두 가지 핵심 방향을 설정했다.
처리 방식의 변경
기존 Direct Exchange 방식으로는 지정된 하나의 Queue에만 메시지가 쌓였다. 이로 인해 처리 속도에 한계가 있었다. 발급 대상 조회하기 위해서 기다리는 되는 시간을 최소화하고, 더 빠르게 발급하여 전체 작업 시간을 단축할 필요가 있었다.
작업 주체의 변경
기존 구조는 백오피스는 운영 상황에 따라 긴급 배포나 다른 작업의 영향을 받는다. 이런 변수들이 대량 쿠폰 발급의 안정성을 해칠 수 있었다. 따라서 발급 대상 조회와 전송 역할을 백오피스에서 분리하여 독립된 환경을 구성할 필요가 있었다.
해결 과정
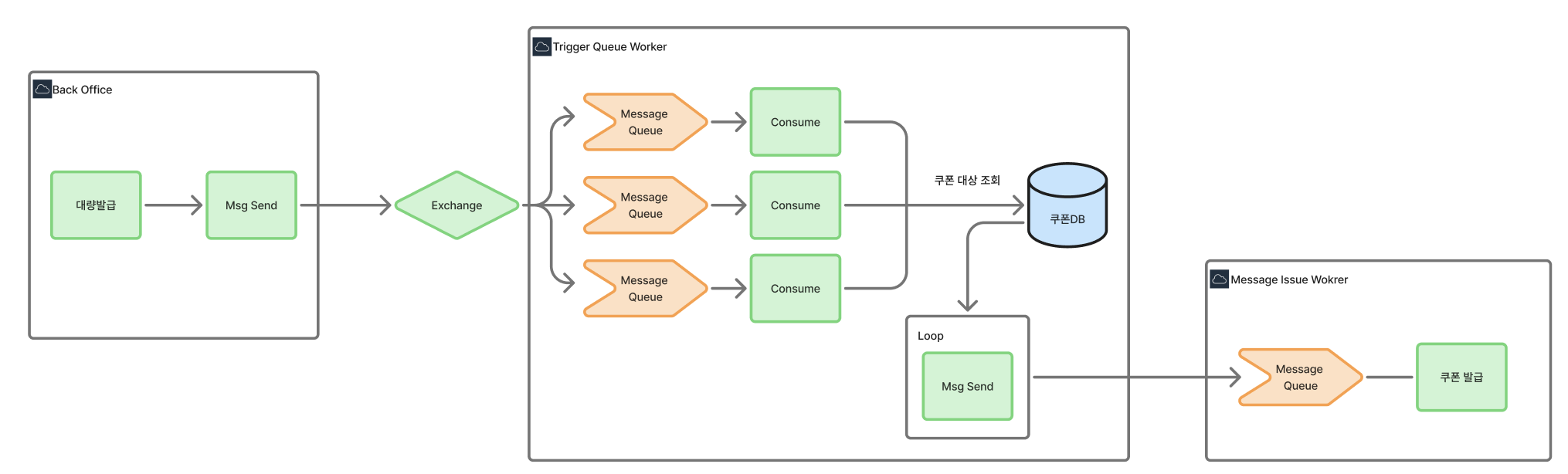
처리 방식의 변경 - Exchange 방식 변경 (Direct → Fanout)
기존에는 Direct Exchange를 사용해서 메시지가 하나의 Queue에만 전달되던 구조를 Fanout Exchange로 변경하여 여러 개의 Queue에 동시에 메시지를 보낼 수 있게 변경했다. 이를 통해 발급 대상 조회되는 시간을 단축했다.
예를 들어 1,000만 명에게 쿠폰을 발급한다고 가정하면, 기존에는 하나의 Queue에서 1,000만 개의 메시지가 차례대로 처리해야 했다. 이제는 Queue를 5개 만들어서, 각 Queue에 200만 개씩 나눠서 처리 할 수 있다.
하지만 여기서 한가지 궁금증이 생겼다.
Fanout Exchange면 중복된 메시지를 전달할 텐데, 중복 처리는 어떻게 했지?
올리브영은 쿠폰 발급 ID 값에 따라 별도로 Queue 별로 분기되어 처리하도록 설정해서 중복 문제를 해결했다고 한다.
예를 들면, Queue가 5개 있다면 'ID값 % 5' 연산을 통해 각 메시지가 적재될 Queue를 사전에 결정하는 방식인 것이다. (필자의 예시 일뿐, 실제로 올리브영에서는 어떻게 처리했을지는 모른다)
작업 주체의 변경 - 독립적인 Worker 구성
백오피스에서 담당하던 발급 대상 조회 및 전송 역할을 별도의 Trigger Worker로 분리했다.
기존에는 백오피스가 모든 일을 담당했다. 쿠폰을 받을 고객 목록을 조회하는 것부터 메시지를 Queue에 넣는 것까지의 모든 쿠폰 발급 프로세스와 기본적인 관리자 페이지의 기능을 전부 백오피스가 했다. 이제는 쿠폰 발급 프로세스의 역할을 "Trigger Worker"라는 별도의 독립적인 시스템으로 분리했다.
개선된 구조는 다음과 같이 동작한다.
[백오피스 담당]
- 백오피스에서 관리자가 "쿠폰 대량 발급 시작" 버튼을 누름
- 백오피스는 Fanout Exchange에 "이제 쿠폰 발급을 시작하겠다"라는 신호만 보냄
[Trigger Worker 담당]
- 데이터베이스에서 "이번 달에 이 고객은 어떤 쿠폰을 받을 것인가?"를 조회
- 회원 목록을 반복문으로 돌면서 쿠폰 발급 메시지를 만들어서 발급 Worker에게 전송
- 발급 Worker는 쿠폰 발급 처리를 진행
이러한 구조를 통해 백오피스는 대량 발급 시 실행만 담당하게 되고, 실제 대상 조회 및 발급은 Trigger Worker에서 진행한다. 이를 통해 쿠폰 발급 작업이 다른 작업에 영향을 주지 않는다. 서로 독립적으로 움직이기 때문에 한쪽에 문제가 생겨도 다른 쪽에 영향을 주지 않는다.
결과
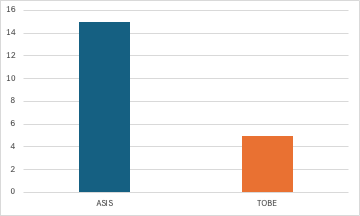
작업 시간 대폭 단축
기존에 12~15시간 걸리던 작업이 5~6시간으로 줄어들었다. 이를 통해 승급과 쿠폰 발급 사이의 시간 간격이 줄어들어 고객 경험이 크게 개선되었다.
안정적인 운영 환경 구축
백오피스에서 독립적인 구조로 변경되어, 긴급 배포나 다른 작업의 영향을 받지 않고 쿠폰 발급을 진행할 수 있게 되었다. 또한 자원 사용량과 운영 상황을 모니터링할 수 있는 환경도 더욱 원활하게 구성되었다.
5. RabbitMQ 장애 개선 (25.10.28)
포인트
RabbitMQ의 Queue 방식을 Quorum Queue로 변경하자.
클러스터란?
컴퓨터 한 대가 고장 나면 전체 서비스가 중단되는 것을 막기 위해, 여러 대의 서버를 마치 하나의 시스템처럼 묶어서 운영하는 방식을 클러스터라고 한다.
예를 들어, 주방장이 한 명뿐인 식당은 그가 다치는 순간 문을 닫아야 한다. 하지만 주방장이 세 명이라면 한 명이 자리를 비우더라도 남은 두 명이 운영을 이어갈 수 있다.
RabbitMQ에서는?
RabbitMQ 클러스터에서 데이터를 안전하게 보관하기 위해 Classic Mirrored Queue를 사용한다.
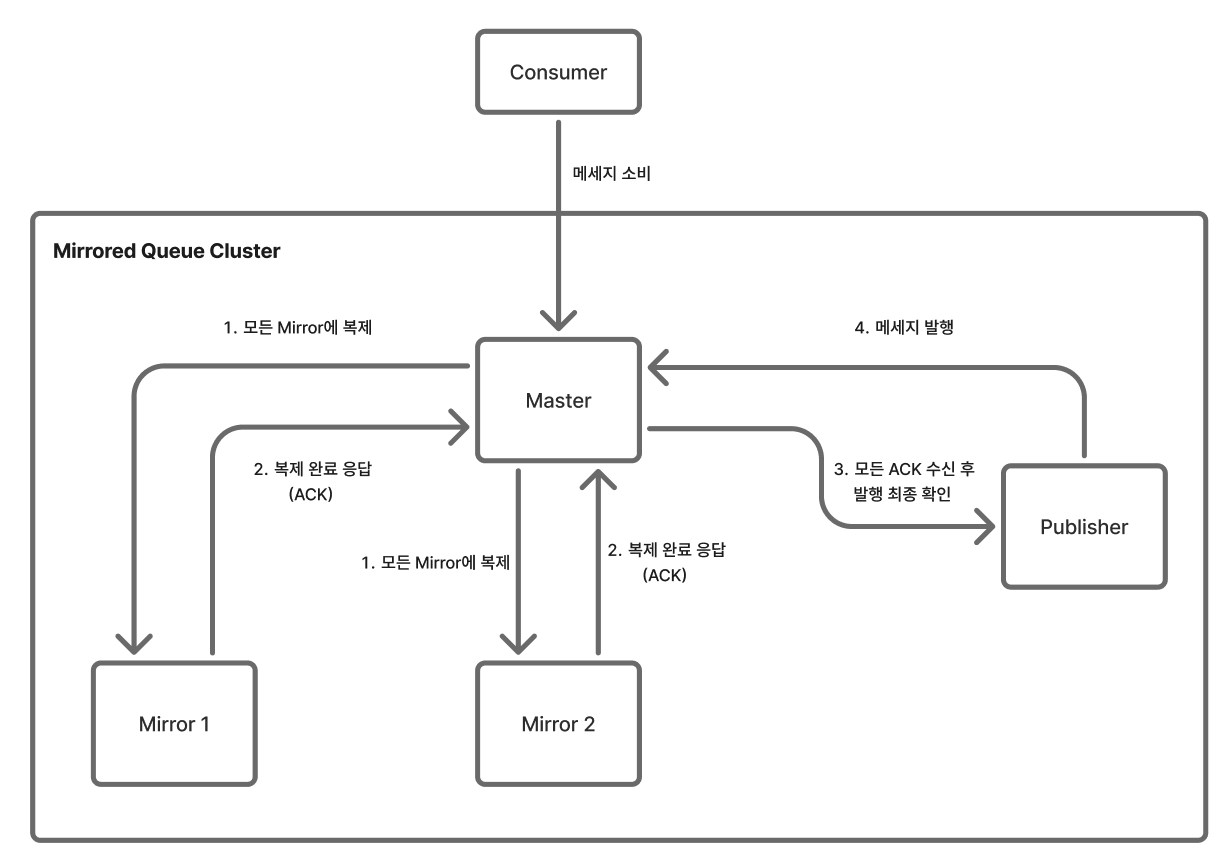
Classic Mirrored Queue는 고가용성을 보장하기 위해 Master 노드와 Mirror 노드 간의 동기화 구조로 동작한다. Master 노드는 실제로 일을 처리하는 메인 노드이다. Mirror 노드는 Master의 백업 역할을 하는 보조 노드이며, Master와 똑같은 데이터를 계속 복사해서 가지고 있는다.
Classic Mirrored Queue의 한계
Classic Mirrored Queue는 동기화 실패 시 전체가 중단되는 한계가 있다.
- Master 노드 메시지 수신
- Mirror 노드에 복제 요청
- Mirror 노드 메모리 부족 -> 복제 실패
- 메모리 부족 노드는 out of sync(Unsynchronized)상태로 변경
이 과정에서 RabbitMQ는 데이터 안전성을 위해 out of sync가 해결되기 전까지는 전체 메시지의 Publish가 중단된다고 한다.
AWS MQ 공식 문서에 따르면, RabbitMQ는 메모리 사용량이 임계점에 도달할 경우 Memory Alarm을 작동시켜 새로운 메시지 수신을 차단한다고 한다.
이런 보수적인 방식은 데이터 무결성 측면에서 안전을 보장하기 위함이라고 한다.
문제
2025년 1월, 올리브영은 새해를 맞이하여 1,500만 장의 대량 쿠폰 발급을 진행했다고 한다. 그 과정에서 RabbitMQ 클러스터의 메모리 과다 점유로 쿠폰 발급이 중단됐다. 이는 곧장 고객 불편과 직결된 문제였고, 관련 문의가 폭주하면서 실질적인 매출 손실로 이어질 수 있는 상황이었다.
대응
실제 Live 되고 있는 서비스였기 때문에 서비스 안정화를 위해 장애에 우선적으로 대응하는 게 중요했고, 쿠폰 발급 시스템 안정화를 위해 다음과 같이 대응했다.
1단계 (기본 지표 확인)
장애 발생 시 기본이 되는 지표인 DB, 트래픽, WAS의 상태부터 점검하기 시작했다고 한다.
- DB → 정상
- 트래픽 → 정상
- WAS → 정상
모든 것이 정상인데 쿠폰 발급만 안 되는 이상한 상황이었기에 쿠폰 관련 리소스들 점검하기 시작했다고 한다.
2단계 (쿠폰 관련 리소스 확인)
쿠폰 관련 시스템을 하나씩 점검하던 중 RabbitMQ 상태 이상을 발견했다고 한다. 메모리가 과다하게 사용되면서 브로커가 Critical 상태로 변경되었고, 특정 노드가 Unsynchronized 상태로 전환되면서 메시지 처리가 완전히 멈춰 있었다고 한다.
3단계 (인프라 리소스 증설)
RabbitMQ의 메모리 과다 사용이 보였기 때문에 인프라 리소스를 증설해 보았다고 한다.
- 인스턴스 증설 시도 → 효과 없음
- 메모리 증설 시도 → 효과 없음
서버를 더 추가해 보았지만 효과가 없었다. 메모리도 늘려봤지만 Unsynchronized 상태는 그대로였다. RabbitMQ의 미러링 메커니즘은 한 번 out of sync 상태가 되면, 모든 노드가 다시 동기화될 때까지 Unsynchronized 상태를 유지한다. 즉, 리소스를 늘리는 것만으로는 근본적인 해결책이 되지 못했다.
4단계 (Message Queue 조작)
인프라 리소스 증설이 효과가 없으니, RabbitMQ와 관련된 조작을 시도해 봤다고 한다.
- 브로커 재시작 시도 → 불가능
- Queue Purge 시도 → 제한적
브로커를 재시작하려 했지만 AWS MQ 서비스에서 Memory Alarm이 해소된 후에야 재시작이 가능하다는 안내가 있었다. AWS와 같은 관리형 서비스 특성상 즉시 재시작이 제한되는 것이었다.
또한, Queue에 쌓여있는 메시지를 지우는 Purge도 시도했지만, Purge는 Admin UI로만 가능했고 Force Purge는 지원하지도 않았다.
5단계 (임시 조치)
복구가 계속 지연되면서 비즈니스 영향이 커지는 상황에서, 기존 서버를 고치는 대신 새로운 RabbitMQ 브로커를 기존과 같은 설정으로 만들기로 했다고 한다.
대신 복잡한 클러스터 재구성 대신 독립 운영 방식을 선택했고, 기존 메시지의 손실을 방지하기 위해 점진적으로 트래픽을 전환한 결과 30분 만에 메시지 처리가 정상화되어 쿠폰 발급 서비스가 복구됐다고 한다.
원인 파악
임시 조치를 했기 때문에 근본적인 문제를 찾아 해결해야 했다.
당시 상황을 조사해 본 결과 세 가지 작업이 동시에 진행되고 있었다.
- 1,500만 건 규모의 전체 회원 대상 대량 발급
- 전체 매장 대상 쿠폰의 동시 발급 및 사용 처리
- 평상시 트래픽
이런 작업들이 겹치면서 Queue 메시지가 급격히 쌓인 상황이었다.
병목 지점들을 분석해 보니 1,500만 건 대상자를 조회하는 과정에서 DB에 부하가 발생했고, count-up 로직에서 지연이 누적되면서 메시지 처리 속도가 떨어졌다. 결국 처리 속도보다 메시지가 쌓이는 속도가 더 빠르기 때문에 메모리 사용량이 급증한 것이었다.
올리브영은 AWS MQ와 같은 구조를 만든 뒤에 테스트를 통해 문제의 원인을 찾으려고 했다.
1차 테스트
1차 테스트는 일반 쿠폰 발급 + 대용량 쿠폰 발급 요청을 하면서 1시간 동안 모니터링을 실행했다고 한다.
1. 일반 쿠폰 발급 진행 (점진적 증가)
2. 대량발급 약 1,500만 건 일괄 요청
3. 대량발급 Queue 메시지 적재 상태 확인
4. 일반 쿠폰 발급 지속 유입
5. 1시간 정도 계속 모니터링하지만 Mirror 노드의 Unsyncronized는 확인됐지만, 시간이 지나면서 자연스럽게 해결되는 것을 확인할 수 있었다고 한다.
2차 테스트
2차 테스트는 1차 테스트 + 브로커 재시작을 진행했다고 한다.
1. 일반 쿠폰 발급 진행
2. 대량발급 약 1,500만 건 일괄 요청
3. 대량발급 Queue 메시지 적재 확인
4. 일반 쿠폰 발급 지속 유입
5. 1시간 정도 모니터링 진행
6. Consumer 처리 중 broker 강제 재시작
7. 재시작 후 동기화 상태 모니터링놀랍게도 재시작 이후에 Unsyncronized 상태에서 돌아오지 않는 현상이 발생했다고 한다.
이를 통해 메모리 부족 + 브로커 재시작 = Unsynchronized 상태라는 공식이 확정됐다고 한다.
원리는 재시작 과정에서 브로커가 일시적으로 메인터넌스(휴식) 모드로 전환되고, 클러스터 내에서 노드 역할이 재배치되면서 누적된 메시지를 처리하는 과정에서 순간적으로 메모리가 급증한다고 한다. 이때 클러스터 내 노드 간 복제본 동기화 과정에서 타임아웃이 발생하는 것이 문제의 핵심이었다고 한다.
== (필자의 생각) ==
글을 읽으면서, 재시작이 언제 실행됐지..?라는 생각을 했다.
긴급 대응 때는 재시작을 시도 했지만, Memory Alarm이 해소되어야 재시작이 가능하다는 안내를 받으면서 재시작을 하지 못했다.
그럼 글에서 나오는 배경 이전에 재시작을 시도했는지를 고민했지만, 나와 있지 않아 알 수 없었다.
재부팅이 치명적인 것은 자명하지만, 재부팅이 없더라도 Unsyncronized 상태에서 변하지 않는 문제가 발생할까?
스스로 알아봤다
Mirror 노드의 메모리 사용량이 임계치를 넘으면, 리소스를 보호하기 위해서 Memory Alarm이 울리고 이후 부터는 저속 모드와 같이 동작한다고 한다. 위에서 설명했던 Publish 중단과 함께, Mirror 노드의 처리 속도가 느려진다.
이렇게 되면, Mirror 노드의 동기화 상태 확인 프로세스에도 문제가 생길 수 있다. 동기화 상태 확인을 위한 요청을 보냈는데, Mirror 노드는 처리 속도가 느려서 Timeout이 발생하는 것이다. 이로인해 동기화 상태가 바뀌지 않고 Unsyncronized 상태를 유지하기 때문에, 동기화 상태 확인 프로세스가 멈춘 것처럼 보이는 게 아닌가하고 생각했다.
1. Mirror 노드의 동기화 상태 확인 요청에 응답하려면 일정 처리 속도가 있어야 함
2. Memory Alarm이 울렸기 때문에, Mirror 노드의 처리 속도가 느려져서 timeout
3. 처리 속도를 올리기 위해서는 Memory Alarm을 풀어야하는데, 풀기 위해서는 동기화 상태 확인 요청에 응답해야 함위와 같은 상황으로 데드락과 같은 상황이 벌어졌다고 예상한다.

실제로 글을 쓰신 "포덕님"께서도 동기화 상태 확인 프로세스가 중단되는 문제가 발생할 수도 있다고 언급하셨다.
해결 과정
올리브영은 AWS TAM과 함께 해당 문제를 해결하기 위해 노력했고, RabbitMQ의 버전 업데이트와 Claasic Mirror Queue 대신 Quorum Queue를 사용하는 것을 솔루션으로 도출했다고 한다.
RabbitMQ 버전 업그레이드
AWS TAM은 이 현상은 RabbitMQ 3.11.28 버전에서 확인된 알려진 이슈일 가능성이 높다고 했다. Classic Mirrored Queue의 메모리 관리와 동기화 로직에서 발생하는 구조적 한계로, 고부하 상황에서 브로커 재시작 시 더욱 자주 발생할 수 있고 했다. 올리브영은 권고에 따라 바로 RabbitMQ 브로커 버전을 3.11.28에서 3.12.14로 업그레이드했다. 주요 개선 사항으로는 메모리 알람 처리 로직 개선과 미러링 동기화 안정성 강화가 있다고 한다.
동일한 테스트 시나리오로 다시 검증해 본 결과, Unsynchronized 상태가 지속되는 문제가 발생하지 않는 것을 확인했다고 한다.
Quorum Queue로 변경
버전 업그레이드로 당장의 위험은 해소되었지만, 장기적인 안정성을 위해 Quorum Queue 전환을 결정했다고 한다.
Quorum Queue는 1개의 리더 노드와 N개의 팔로워 노드로 이루어져 있다. 1개의 Master 노드와 N개의 Mirror 노드로 구성된 Classic Mirror Queue와 비교했을 때 차이가 없어 보이지만, 동기화를 하는 과정이 다르다.
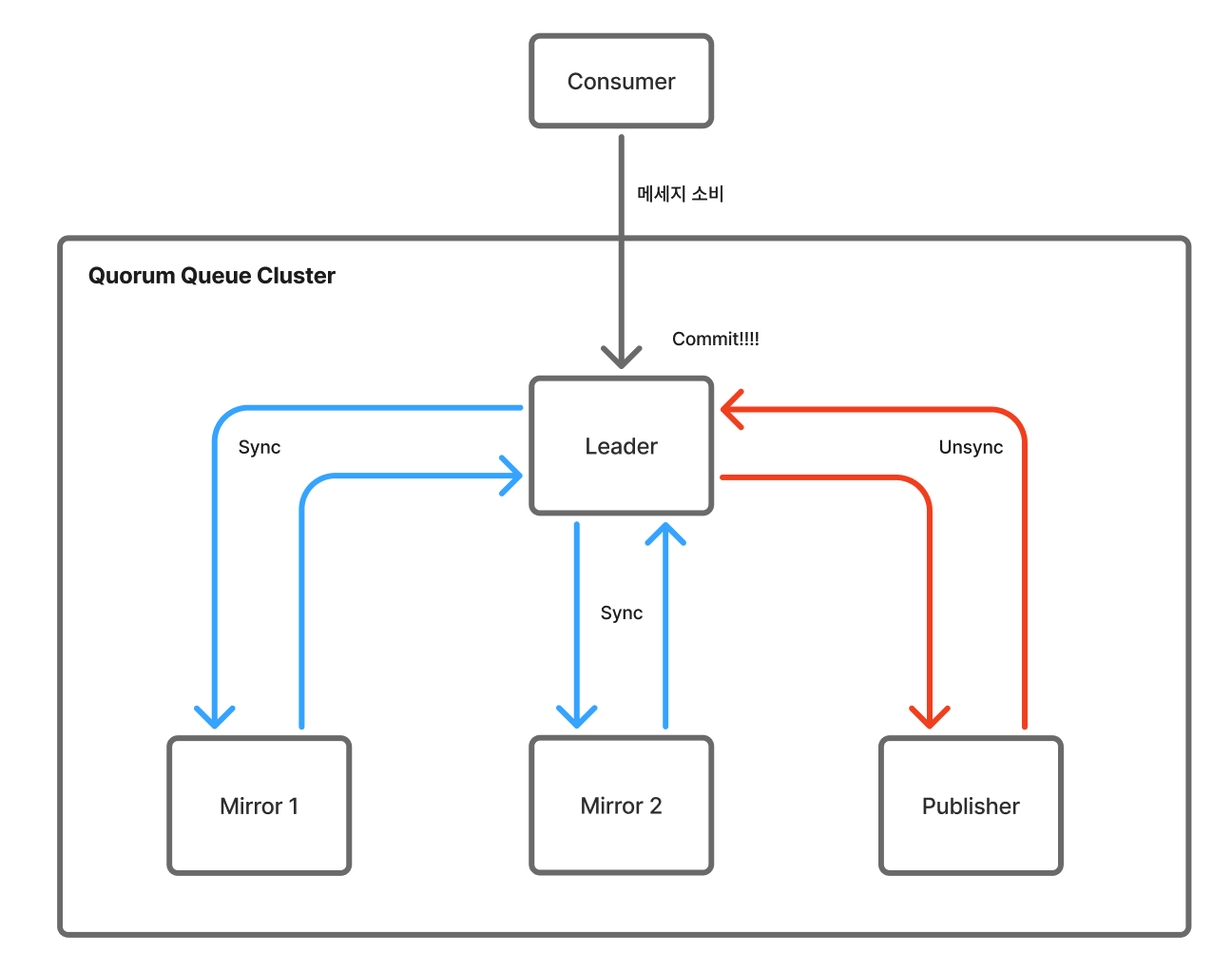
Classic Mirror Queue는 모든 Mirror 노드가 Sync 상태여야 커밋을 하지만, Quorum Queue는 팔로워 노드 중 과반수 이상만 Sync여도 커밋을 하게 된다.
이 방식으로 인해, 기존에 특정 Mirror 노드가 Unsyncronized 상태여서 쿠폰 발급 시스템이 정지되는 문제는 발생되지 않을 것이다.
(이렇게 과반수를 중심으로 동작하는 알고리즘을 RAFT Consensus 알고리즘이라고 한다.)
추가로 리더 노드 장애 시 즉시 새로운 리더 선출로 서비스 연속성을 보장하고 장애 노드 복구 시 자동으로 클러스터에 재참여하고, 네트워크 분할 상황에서도 과반수 원칙으로 안정성을 유지한다.
이를 통해 운영 관점에서는 수동 개입 없이 자동 장애 복구가 가능하고, 문제의 원인이었던 동기화 상태 관리가 필요 없어진다.
결과
- 월 평균 2-3회 발생하던 장애가 전환 후 0회로 감소
- 평균 메시지 처리 지연시간이 150ms -> 120ms로 20% 단축
- 이전에 문제가 되었던 1,500만 건 규모의 대량 쿠폰 발급을 무장애로 처리 가능
- Memory Critical 알람 월 평균 5-7건 -> 0건
6. Redis 명령어의 원자성 개선 (25.12.15)
포인트
Redis의 GET과 INCREASE의 원자성을 보장하자
원자성이란?
원자성은 "전부 아니면 전무(All or Nothing)" 원칙을 따르는 특성이다. 어떤 작업이 원자적이라는 것은, 그 작업이 완전히 성공하거나 완전히 실패하거나 둘 중 하나만 가능하다는 것을 의미한다.
일상생활의 비유
ATM에서 돈을 이체하는 상황에서 ATM은 잔액을 조회하는 기능(GET)과 출금하는 기능(DECREASE)이 있다.
올리와 브영이가 동시에 같은 계좌에서 10만원씩 출금하려고 한다.
1. 올리: GET → 잔액 15만원 확인
2. 브영: GET → 잔액 15만원 확인
3. 올리: DECREASE 10만원 차감 → 잔액 5만원
4. 브영: DECREASE 10만원 차감 → 잔액 -5만원각 과정이 ms단위로 실행된다면, 계좌에는 -5만원이 남아서 심각한 문제가 될 것이다.
문제
2025년 6월 올영세일, 7일간의 대규모 선착순 쿠폰 행사를 운영하면서, 사용자에겐 쿠폰이 발급됐다고 안내됐지만 실제로 쿠폰이 발급되지 않는 문제가 발생했다고 한다.
모든 요청은 "[온라인몰] 제한 수량 유효성 검사(1차) -> Message Queue로 메시지가 발행 -> [발급 워커] 제한 수량 유효성 검사(2차) -> 쿠폰을 최종 발급"의 과정을 거친다.
6월 올영세일에서는 발급 워커의 2차 유효성 검사가 실패해 이와 같은 문제가 발생했다.
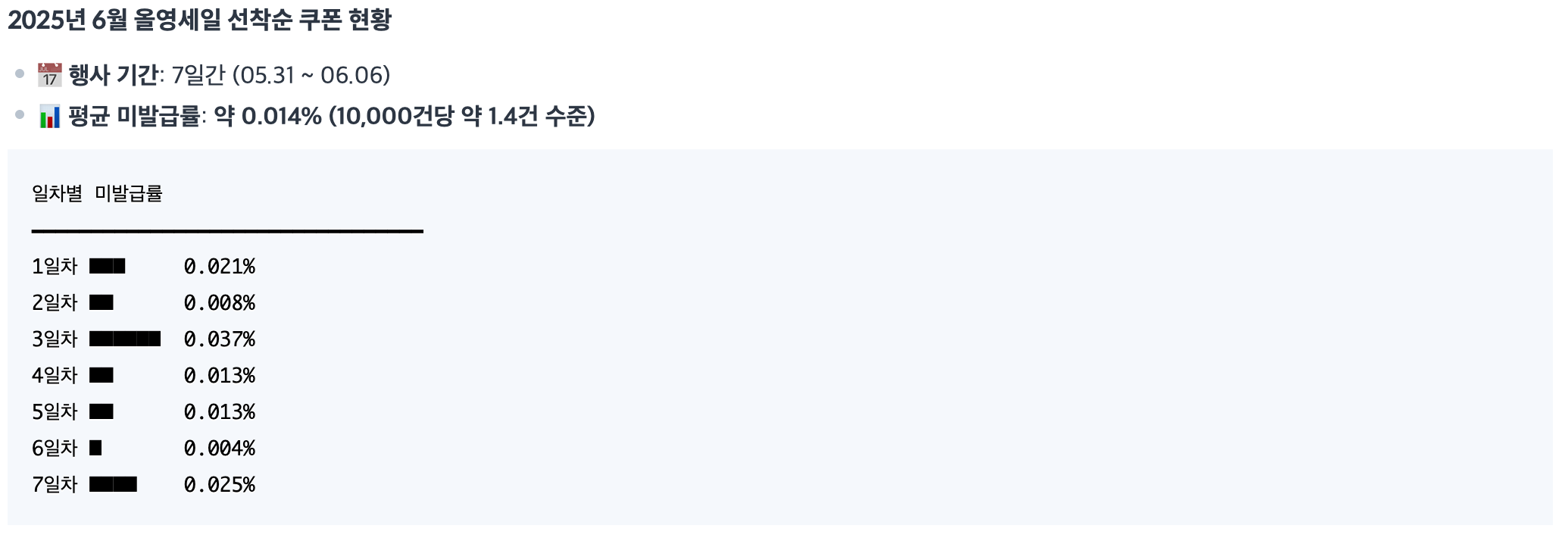
미발급률이 평균 0.014%이지만 고객 입장에선 선착순 쿠폰을 발급받은 줄 알았는데, 실제로 쿠폰은 없었기에 곧바로 CS 문의로 이어지는 치명적인 문제였다. 또한 고객이 올리브영이라는 브랜드에 신뢰를 잃게 만들 수 있는 상황이었다.
원인 파악
올리브영의 기존 쿠폰 발급 구조는 다음과 같았다.
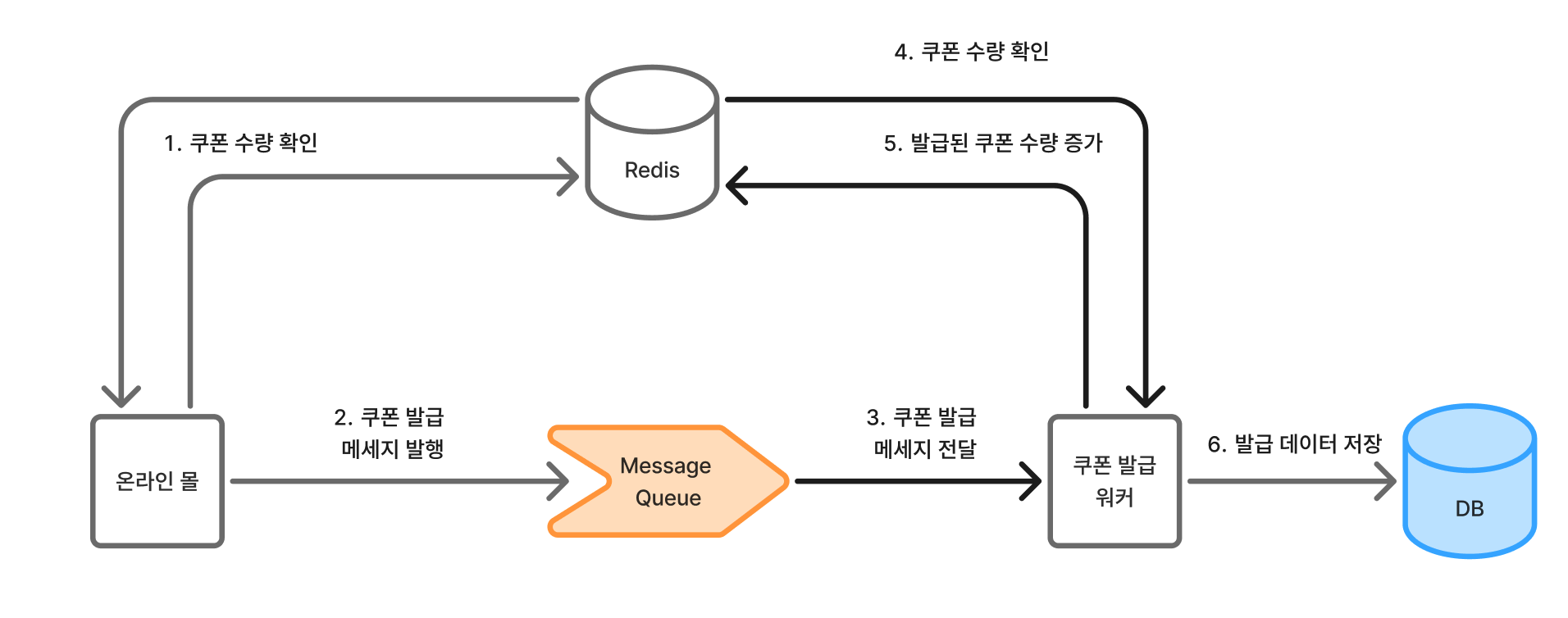
올리브영의 쿠폰 발급 시스템은 쿠폰 발급 요청은 "온라인 몰 시스템"에서 하고, 이후 실제 발급 작업은 Message Queue에 담아 "발급 워커"가 담당한다. 이때, 온라인 몰과 발급 워커는 다른 시스템이기 때문에 발급의 신뢰성을 위해 양쪽에서 모두 쿠폰 수량에 대한 유효성 검사를 하게 된 것이다.
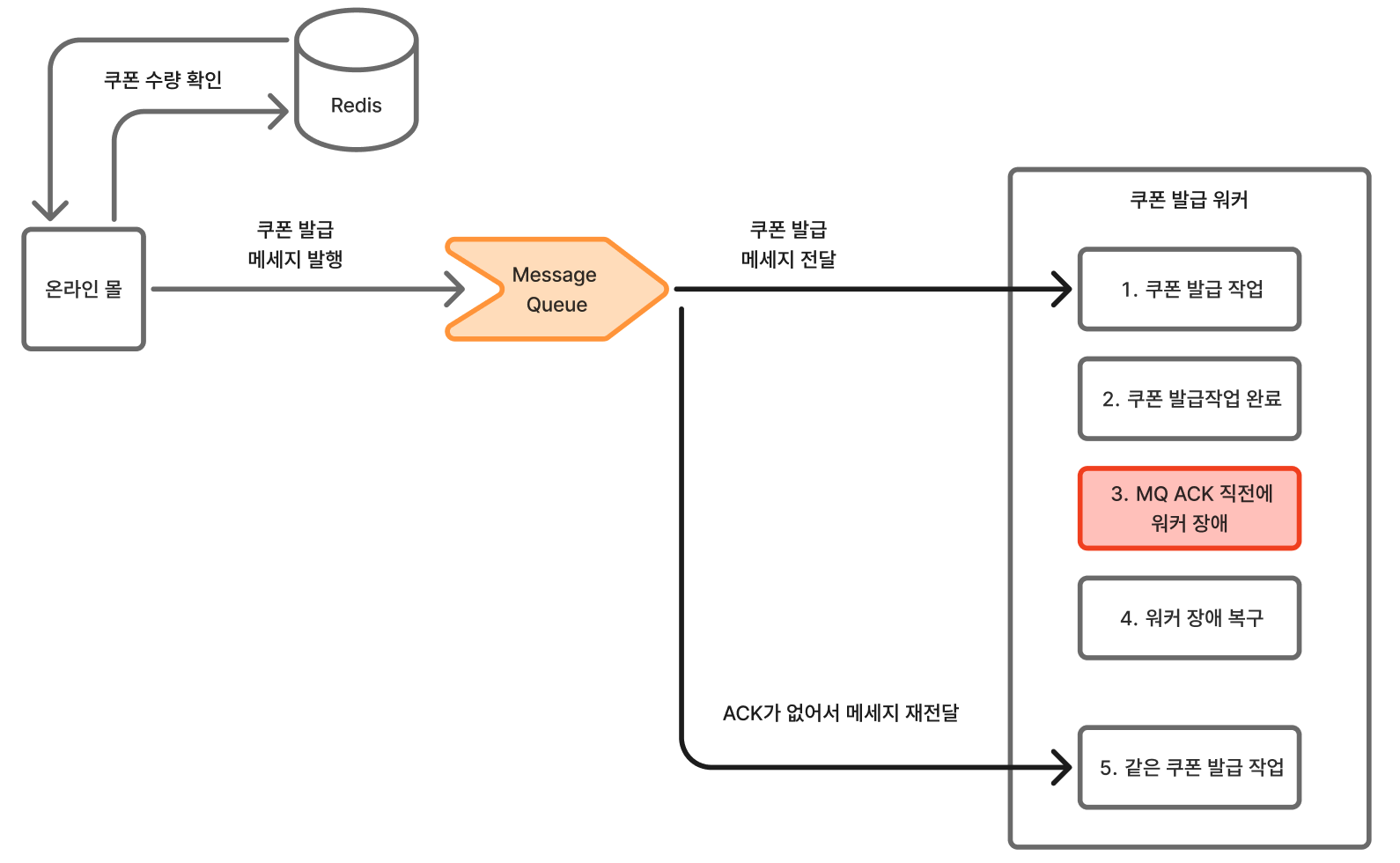
양쪽 모두에서 유효성 검사를 하지 않으면 쿠폰 중복 발급의 위험도 있기 때문이다.
올리브영은 이 구조로 인해 다음 문제가 발생할 수 있다고 생각했다.
1. Time Gap (시간 간극)
T0: Redis GET (count=99) → 통과 ✅
T1: MQ 발행 (10ms)
T2: Worker 수신 (50ms)
T3: Redis GET (count=101) → 실패 ❌ <- T0와 T3 사이의 간극!첫 번째 검증(T0)과 워커의 재검증(T3) 사이에는 MQ 지연 시간을 포함한 시간 간극이 발생한다. 그 짧은 간격 사이에 수백 건의 요청이 동시에 몰리면서 T0의 검증은 무의미해진다.
2. Redis GET/INCR 원자성(Atomicity) 부재
// 문제가 되는 코드 패턴
val currentCount = redisTemplate.opsForValue().get(key) // GET
if (currentCount < maxCount) {
redisTemplate.opsForValue().increment(key) // INCR (별도 명령)
// ⚠️ GET과 INCR 사이에 다른 요청이 끼어들 수 있음! (이 짧은 간극 사이에 경합 발생)
}Redis의 개별 명령('GET', 'INCR')은 원자적으로 동작하지만, 이들을 조합한 기능은 원자적으로 동작하지 않았다. GET과 INCR 사이에 수백 건의 또 다른 요청이 들어오면서 원자성이 깨지는 것이다.
솔루션 탐색
올리브영은 문제를 해결하기 위해 총 3개의 솔루션을 비교했다.
1. 발급 수량 선차감 (시간 간극 줄이기)
첫 번째 문제였던 "1차 수량 검증 시점과 수량 반영 시점의 시간 차이"가 존재하기 때문에, 그 간격을 없앤다면 문제가 발생하지 않을 것이라는 가설이다.
이를 위해, 기존에 발급 워커가 담당하던 수량 반영을 온라인 몰에서 담당하도록 수정했다.
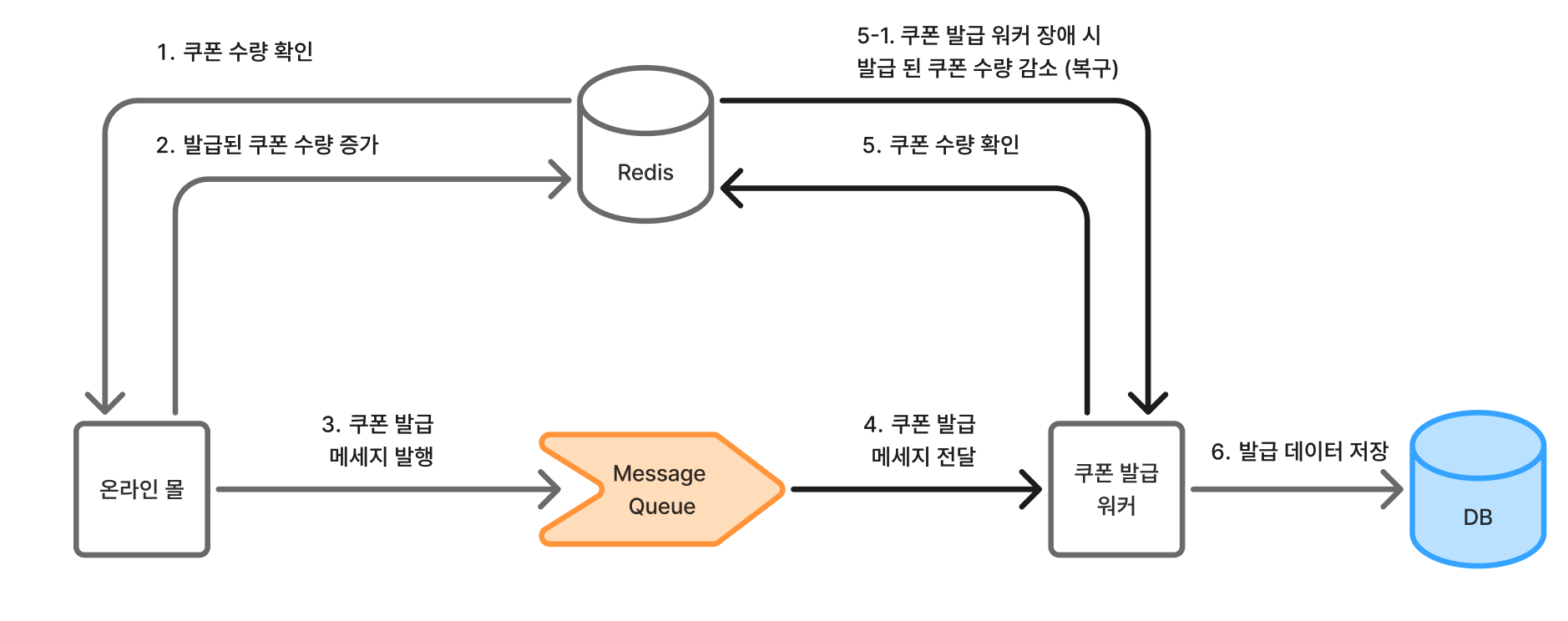
이렇게 되면, 온라인 몰에서 수량을 조회하자마자 쿠폰 수량을 반영할 수 있어서 시간 간극을 줄일 수 있다. 또한 발급 워커에서 장애가 발생했을 경우 수량을 복구하게 처리한다면, 신뢰성도 유지할 수 있다.
해당 구조로 테스트한 결과, 미발급 건수가 줄어들긴 했지만 여전히 기존과 동일한 문제가 남아 있었다.
이는 시간 간극은 줄었지만, 여전히 원자성이 보장되지 않았기 때문에 아무리 적은 순간에도 또 다른 요청이 들어올 수 있기 때문이었다.
2. Lua 스크립트 적용 (원자성 확보)
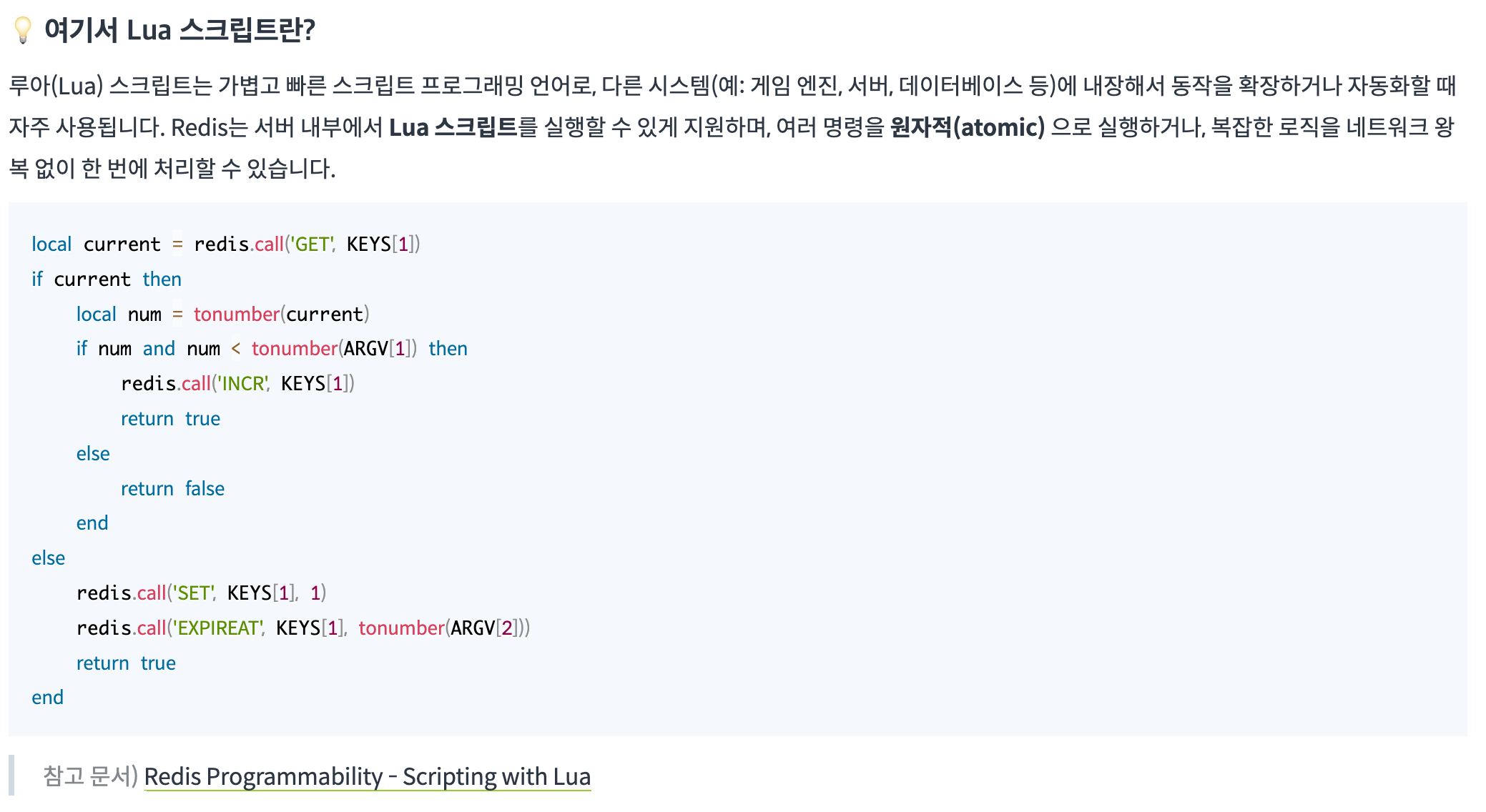
Redis에서 Lua 스크립트를 이용하면 여러 개의 기능을 하나의 트랜잭션처럼 묶어서 처리할 수 있다고 한다. 하지만 Redis는 단일 스레드 구조이기 때문에 스크립트를 수행하는 동안 다른 요청은 모두 대기하게 된다. 이러한 특징 때문에 성능 저하를 불러올 수 있고, 실제 부하 테스트 결과 미발급은 0건이었지만 기존 대비 약 21% 정도의 성능 저하가 발생했다고 한다.
3. 이중 카운터 전략 (원자성 확보)
원자성 보장과 성능 유지라는 두 마리 토끼를 잡기 위해 올리브영이 생각한 방법은 바로 이중 카운터 전략이다. 이 전략은 실제 쿠폰 발급 제한 수량을 관리하는 키 외에, 발급 요청 수량 관리를 위한 별도의 Redis 키를 추가하여 유효성 검사를 이중화하는 방식이다.
| Redis Key | 용도 |
|---|---|
| C001-count | 최종 쿠폰 발급 제한 수량 제어 (DB 정합성에 사용) |
| C001-countReq | 쿠폰 발급 요청 수량 제어 (경합 상태 방지) |
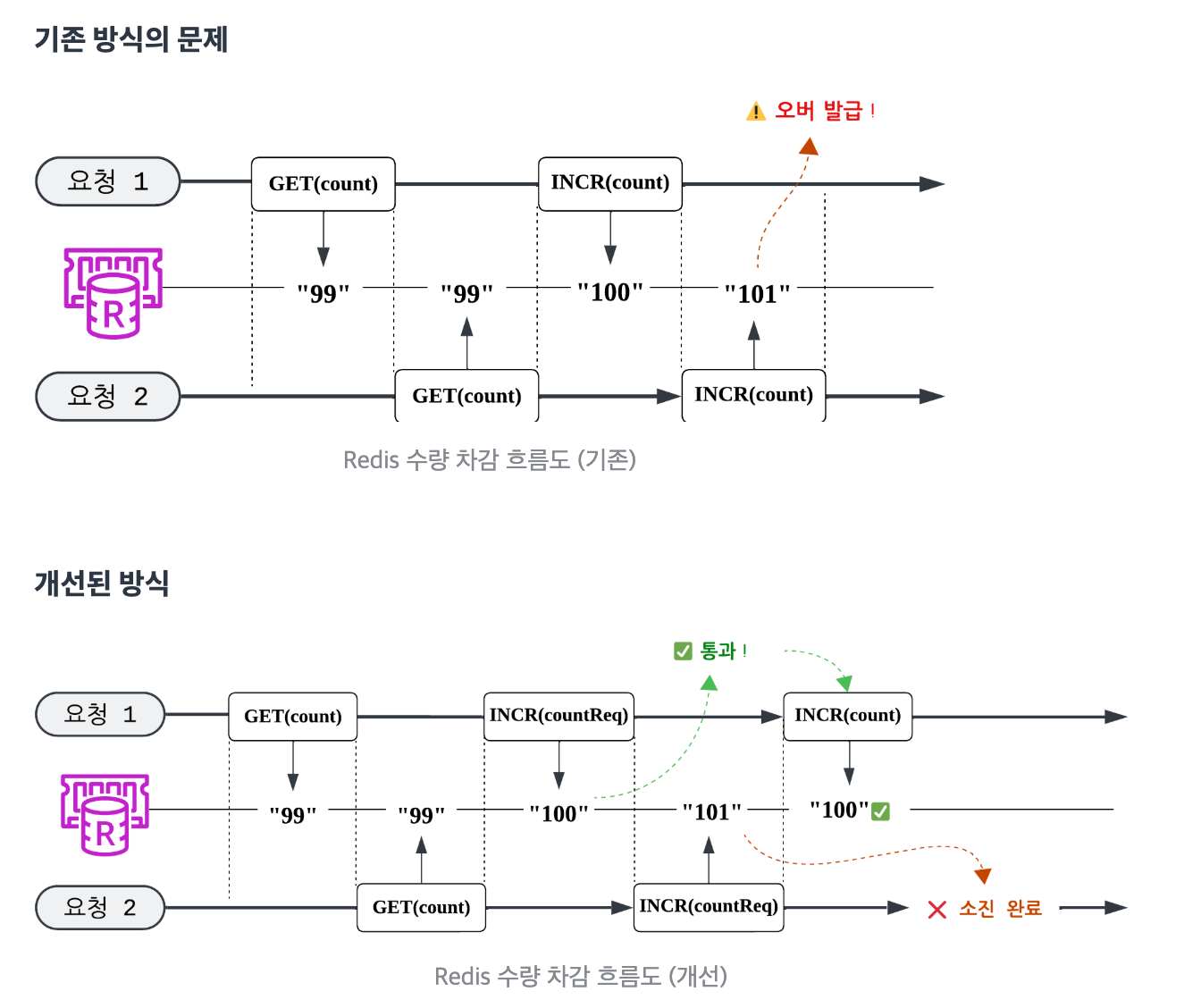
쉽게 말해서 1차 검증 때는 실제 쿠폰 발급량만 확인하고, 2차 검증 때는 지금까지 온 쿠폰 발급 요청량을 확인해서 유효하면 실제 쿠폰 발급량에 반영하는 방식이다.
실제로 작성자이신 "라이트님"이 참고하신 Redis Docs를 보면, Redis에서 원자성을 보장하기 위해 사용하는 Counter 패턴이라는 게 있다는 것을 볼 수 있다.

이 방법을 통해 실제 수량이 초과될 상황이 원천 차단되었으며, 워커로 넘어가는 초과 발급 건수는 모두 0건으로 완벽히 해소되었다. 하지만 기존 대비 8%의 성능저하가 발생했다.
(필자의 생각)
여기서 8%의 성능저하가 발생한 이유는 Redis와 통신하는 횟수가 늘어났기 때문이라고 생각한다.
기존에는 총 3번의 Redis 통신이 발생한다.
- [온라인 몰] : 쿠폰 count 조회
- [발급 워커] : 쿠폰 count 조회
- [발급 워커] : 쿠폰 count 증가
하지만 개선 이후에는 총 4번의 Redis 통신이 발생한다.
- [온라인 몰] : 쿠폰 count 조회
- [발급 워커] : 쿠폰 countReq 조회
- [발급 워커] : 쿠폰 countReq 증가
- [발급 워커] : 쿠폰 count 증가
해결
올리브영은 3가지 방법의 장단점을 비교하며 최종 솔루션을 도출했다.
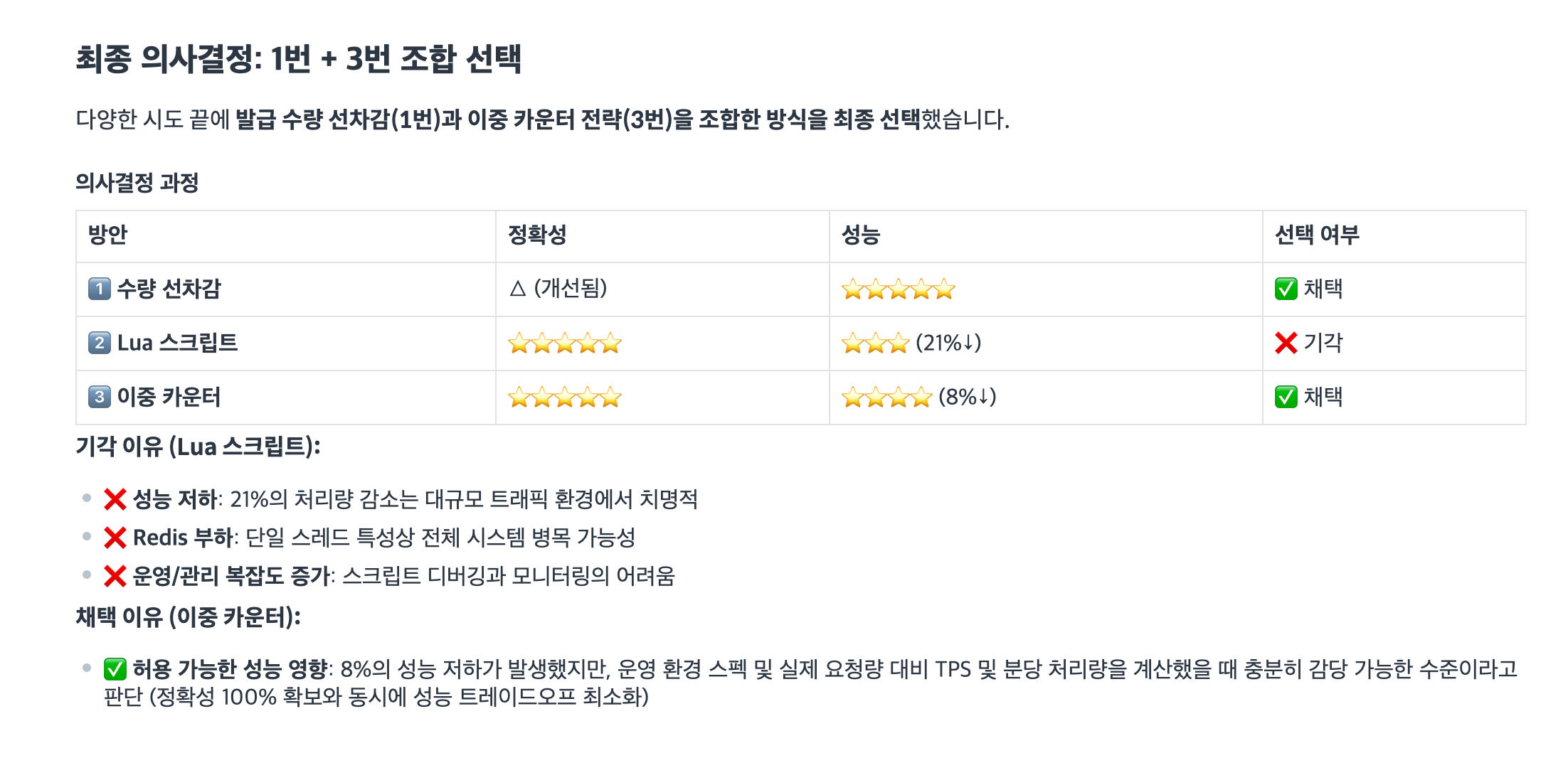
1번 방법은 성능은 유지되고, 정확성도 개선됐지만 여전히 100% 보장하지 못한다는 단점이 있었다. 반대로 2번 방법은 정확성은 100% 보장하지만, 성능이 기존대비 21%나 저하됐다. 마지막으로 3번째 방법은 정확성을 100% 보장하지만, 기존대비 8%의 성능저하가 나타났다.
이렇게 장단점을 비교했을 때, 정확성이 보장되지 못해서 발생하는 문제는 기업에게 너무나도 큰 손실을 가져온다. 그 때문에 100% 정확도를 위해서 8%의 성능저하는 감안할 수 있는 부분이라고 생각된다. 이러한 이유로 올리브영도 3번 방식을 적용해 문제를 해결했다.
결과
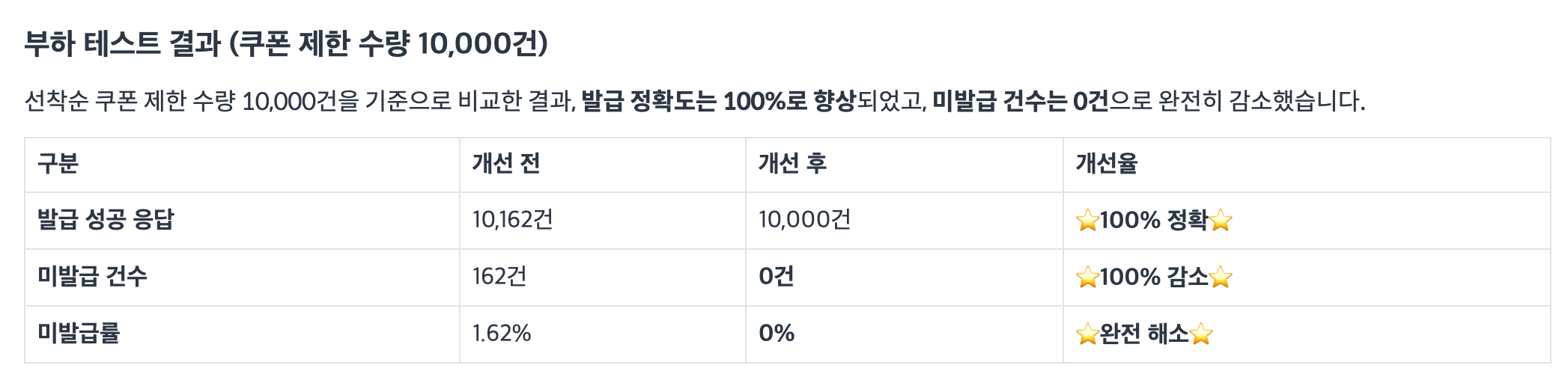
부하 테스트 결과, 미발급 건수도 0건이고 오버해서 발급되는 건수도 사라졌다고 한다.
또한 25년 9월 올영 세일의 실제 운영에서도 미발급 건수는 0건을 기록했다. 그리고 단점이었던 8% 성능 저하 역시 실전에서는 미미한 영향력을 보이면서 6월 대비 처리량의 저하 없이 안정적으로 유지되었다고 한다.
후기
이렇게 올리브영 테크 블로그에 있는 총 6개의 쿠폰 개선기를 모두 살펴보았다.
"포덕님"께서 작성하신 RabbitMQ의 Queue Type 관련 개선 글을 보면, 쿠폰 시스템의 아키텍처와 관련된 글도 작성하실 예정인 것 같다. 지금 내 수준에서 이해하려면 훨씬 더 어렵겠지만 그래도 궁금하니 어서 올려주셨으면 좋겠다.
앞에 도입에서도 말했지만, 처음 올리브영 쿠폰 시스템 개선 관련 글을 접했을 때는, 관심 있던 회사의 시스템이 어떻게 성장해 왔는지를 시리즈로 볼 수 있다는 점이 흥미로워 비교적 가볍게 읽기 시작했다. 실제 서비스에서 발생한 문제와 그에 대한 개선 과정이 담겨 있다는 점만으로도 충분히 재미있었다. 하지만 읽다 보니 Message Queue와 관련된 개념들이 등장했고, 그에 대한 사전 지식이 거의 없던 나는 중간에서 이해가 끊기며 몇 번이나 글을 덮었다.
그렇게 완전히 이해하지 못한 상태로 시간이 지나던 중 여러 시행착오 끝에 쿠폰 미발급률 0%를 달성했다는 이야기를 접하게 되었다. 자연스럽게 이전에 이해하지 못했던 부분들을 포함해 이 개선 과정 전체를 제대로 이해해 보고 싶다는 생각이 들었다. 그리고 흩어져 있는 이야기들을 하나의 흐름으로 정리해 보고 싶다는 마음도 생겼다.
그래서 처음 이 글을 쓰기 시작했을 때의 목표는 비교적 단순했다. 쿠폰 시스템의 개선 과정을 이해하고 그것을 하나의 글로 정리해 보자는 것이었다. 하지만 내용을 하나하나 따라가며 공부하다 보니, 나와 비슷하게 이 주제에 흥미는 있지만 기술적인 배경지식이 부족해 글을 끝까지 읽기 어려웠을 사람들도 있을 것이라는 생각이 들었다. 그래서 개선 과정을 이해하는 데 필요한 지식들을 함께 설명하면서 최대한 쉽게 풀어 설명하고자 했다. 그 때문에 이 글이 누군가에게는 복잡하게 느껴졌던 쿠폰 개선 과정을 이해하는 작은 디딤돌이 되고, 또 다른 누군가에게는 시스템을 바라보는 새로운 관점이나 인사이트를 전해줄 수 있기를 바란다.
그리고 언젠가는 올리브영에 합류해서 나도 이런 고민과 배움을 담은 글을 테크 블로그에 남겨보고 싶다는 생각도 들었다.
혹시 이 글을 읽으며 잘못 이해했거나 놓친 부분이 있다면 언제든지 짚어주시면 정말 환영이다. 그 과정 또한 또 하나의 배움이 될 것이고, 이 글을 더 나은 방향으로 다듬는 계기가 될 것이라 생각한다.
마지막으로 좋은 내용을 테크 블로그를 통해 공유해 주신 올리브영의 [레이, 어푸, 포덕, 라이트]님께 감사하다고 전하고 싶다. 언젠가 이 글을 보시게 된다면, 덕분에 올리브영의 쿠폰 시스템의 개선 과정을 재밌게 이해할 수 있었다고 꼭 전하고 싶다.
내용 출처 및 참고
올리브영 쿠폰 발급 개선 이야기 (2022.09.28) - 레이님
Redis Pub/Sub을 활용한 쿠폰 발급 비동기 처리 (2023.08.07) - 어푸님
쿠폰 발급 RabbitMQ도입기 (2023.09.18) - 포덕님
올리브영 초대량 쿠폰 발급 시스템 개선기 (2024.12.11) - 포덕님
RabbitMQ Classic Queue 메모리 장애와 Quorum Queue 전환기 (2025.10.28) - 포덕님
올영세일 선착순 쿠폰, 미발급 0%를 향한 여정 (2025.12.15) - 라이트님
