
INTRO
회사에서 농협 식품 사업 전략 컨설팅을 하고 있다. 기존에 농업 비즈니스 모델을 개선하기 위해서 해결해야 할 문제는 다음과 같다.
농협 은 경제지주로 이루어져 있어 실적별로 비례해서 가져가기 보다는 서로 균등하게 분배한다.
이 특성으로 인해 지역별 제품의 질 차이가 크고 소비자 선호도의 차이가 뚜렷한 제품임에도 불구하고 그만큼의 부가가치를 생산해내지 못한다.
이걸 해결하기 위해 로컬 브랜딩 을 할 필요성이 제기됐다.
지역별로 소비자가 느끼는 가치를 등급화해서 선별적으로 리소스를 투여하자는 것이다. 예) 청송사과 > 밀양사과 면 청송사과 를 더 비싸게 쳐주고 확실하게 마케팅을 해주자
내가 해야하는 것
어느 지역이 더 브랜드 가치가 있는 지 정의하고 알아보기
필요한 데이터 정의
등급을 나누는 여러가지 방법이 있겠지만 우선 가장 간단한 방법으로 브랜드 인지도를 기준으로 삼았다. 간단하게 사람들 입에서 더 자주 오르내리는 브랜드가 더 괜찮은 등급이라는 전제를 깔고 시작했다.
이렇게 어떤 데이터가 필요한지 대충 정해졌으면 어떤 방법으로 데이터를 뽑아낼건지 생각해야한다.
보통 사람들이 제품을 말할 때 지역별 특성이 잘 나타나는 품목은 해당 제품 앞에 이름을 붙인다. ex)영광 굴비, 우한 폐렴
근데 이렇게 데이터를 수집해서 앞에 명사만 때면 해당 단어가 지역인지 조직인지 사람이름인지 가게명인지 알 수가 없다.
이 데이터를(지역이름이 아닌 명사) 처리하기 위해서 버트 언어모델을 사용했다.
필터링 하기 위한 모델
나는 SKT 에서 pre -training 시킨 BERT 를 썻다 (감사합니다) 아래 링크 들어가시면 모델을 사용할 수 있다.
해당 모델을 이용하면 사람이름, 지역명, 조직명, 등등에 따라 단어를 분류할 수 있다. 다음으로 데이터 수집하고,분석 시각화 작업을 진행했다.
데이터 수집은 네이버블로그, 뉴스, 인스타그램, 유튜브를 이용했다. 파이썬기반에서 bs4, 필요에 따라 selenium 을 이용했고 전처리를 위해 mecab 형태소 분석기를 사용 시각화는 Tableua와 mysql을 연동하여 진행하였다. 수집 전처리 시각화 과정은 추후에 따로 자세하게 다루겠다.
분석한 데이터 시각화 해보기
해당 데이터를 이용해 TABELAU 로 시각화 한 자료입니다.
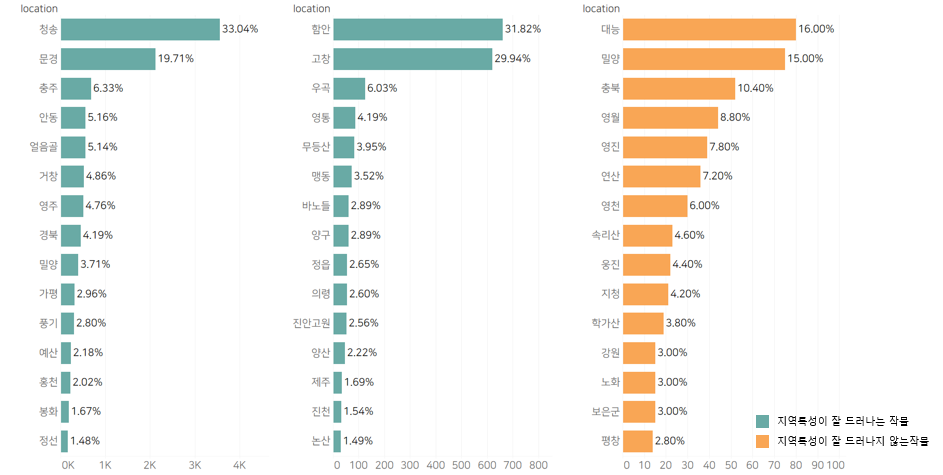
해당 데이터를 이용해 TABELAU 로 시각화 한 샘플
(지역별 특성이 드러나는 제품을 브랜딩에 적용하면 될듯.)
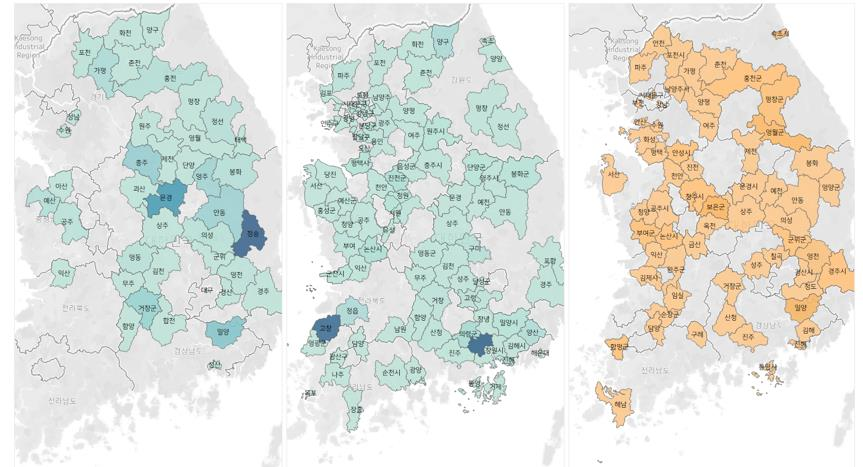
해당 데이터를 이용해 TABELAU 로 시각화 한 샘플.
(보통 상위 20%가 거의 대부분을 차지하는거 같음)
결론
사과나 수박같은 제품은 지역별로 차등이 심해서 높은 비율 지역에 대한 부가가치를 측정할 수 있을거란 생각이 들었음. 실제 가격이랑 연관성을 측정해보고 오프라인 조사도 해서 SNS 데이터 자체에 대한 신뢰성 확보가 필요하다고 생각들었음.
코드공개
아래 링크를 통해 내가 분석을 위해 작성한 코드를 공개하였다.
kobert-ner 을 이용한 개체명 추출 by kjyggg
mysql 을 이용하여 수집한 데이터를 적재하고 해당 데이터를 전처리, 모델을 이용하여 필터링 최종 분석 데이터를 csv 파일로 저장하는 프로세스로 진행된다.

혹시 이 코드를 현재 돌려도 잘 돌아가시나요?
main 실행 시
TypeError: dropout(): argument 'input' (position 1) must be Tensor, not list
자꾸 이런 에러가 뜨네요 ㅜ