1. 불균형 데이터 문제
모델링을 할 때 가장 중요한 것은 데이터의 품질인 것 같다.
무턱대고 데이터를 때려넣고 모델을 만들었던 과거의 나..

현 회사 인턴으로 있을 때, Classification 모델을 만들었는데 정확도가 너무 높게 나와서 멘탈이 탈탈 털렸던 경험이 있다..
그 원인을 찾았을 때 얼마나 허무+민망 하던지;
같이 인턴하던 석사출신 멋진 언니가 불균형 데이터를 해결하는게 중요하다는 것을 알려주셨고,
오늘은 그 방법 중 하나인 오버샘플링에 대해 공부해보는걸로!
https://blog.linewalks.com/archives/7686
관련 정보를 찾다가, 오버샘플링을 잘 정리한 블로그가 있어서 이걸 참고해서 공부했다.
불균형 데이터 문제란 정상 범주의 관측값 수와 이상 범주의 관측값 수가 균등하게 분포하지 않는다는 것이다. 가령, 이진 분류 모델을 만들 때 정답 레이블이 0 또는 1로 설정되어 있고, 모델이 이를 학습할 때 10,000개의 row 중 0이 90% 이상을 차지하는.. 아주 극단적인 상황이 발생하게 되는 경우! 데이터 불균형 문제가 생겨난다. (이때 모델은 새로운 데이터가 들어왔을 때 다 0으로 뱉어버려도 정확도가 90% 나와버리는 대참사가 발생..)
분류 모델은 전체적인 오분류를 줄이기 위해, 다수 범주에 해당하는 레이블로 분류하는 경향으로 학습하는 문제가 생긴다. 결국 이는 성능에 대한 왜곡 현상을 야기하게 된다는 것..!
오늘 공부할 샘플링 기법을 활용한다면 이 문제를 조금이나마 해결할 수 있다고 한다. (짝짝)
2. 샘플링 기법
2-1. 샘플링 기법이란?
샘플링 기법
다수의 범주에 속하는 데이터 또는 소수의 범주에 속하는 데이터의 수를 조정하는 것
샘플링 기법은 정상 데이터에서 일부분을 추출하거나, 이상 데이터를 추가로 생성해 수를 늘리는 방식을 취한다. 전자의 경우 언더샘플링(Undersampling), 후자의 경우 오버샘플링(Oversampling)이라고 한다.
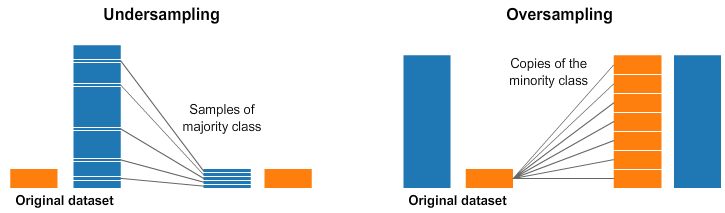
언더샘플링은 어떤 데이터를 없앨지 고민해야 하는데, 어렵게 얻은 데이터 중 어떤 것을 남기고 어떤 것을 버릴지 고르는 과정이 쉽지만은 않을 것 같다. 그중 랜덤 언더샘플링은 데이터를 랜덤으로 제거해 가며 원하는 비율이 될 때까지 진행하는데, 정보가 많은 데이터가 사라진다면 궁극적으로는 분류기의 성능이 저하될 수 있다는 것..
이와 반대로 랜덤 오버샘플링은 소수 클래스 샘플을 랜덤하게 선택해 그 수를 늘린다. 데이터의 단순 복제를 의미! 그러나 이 방법은 새로운 데이터에 제대로 동작하지 않는 과적합 문제가 발생할 수 있다..

2-2. SMOTE 알고리즘
그럼에도! 랜덤 샘플링의 단점을 보완할 수 있는 SMOTE 알고리즘이 있다! SMOTE 기법은 새로운 데이터를 합성하는 방식으로 소수 클래스의 데이터 수를 늘리는 오버샘플링 방식이다. 소수 데이터 객체를 단순히 복제해서 발생하는 과적합 문제를 줄이기 위해 등장한 알고리즘이다.
SMOTE(Synthetic Minority Oversampling Technique)
1. 소수 클래스 데이터 중 무작위로 한 점을 선택
2. 이 점에서 가장 가까운 k개의 소수 클래스 데이터를 탐색
3. 이 중 하나를 무작위로 선택
4. 두 데이터를 잇는 선을 긋고
5. 그 선분 위의 임의의 점을 선택하여 합성 데이터 생성
6. 원하는 만큼의 데이터가 생성될 때까지 반복
그러나 이 알고리즘에도 한계점이 존재했나니..
소수 클래스 데이터 사이에서 생성되는 방식은 결국 이들만의 특성을 반영하고, 노이즈 데이터에 취약하다는 한계가 존재한다. 이런 한계점을 극복하기 위해 나온 SMOTE의 변형 Borderline-SMOTE! 새로운 데이터의 출발지를 소수 클래스가 아닌 특정 집단으로 분류하는 과정이 추가됐다는 점이 가장 큰 특징이다.
2-3. Borderline-SMOTE
Borderline-SMOTE
1. 각각의 소수 클래스 데이터에서 가장 가까운 k개의 데이터를 탐색
2. 그 중 다수 클래스에 해당하는 데이터의 수 세기
3. 데이터 분류
ㅤㅤa) 모두 다수 클래스 -> Noise
ㅤㅤb) 절반 이상이 다수 클래스 -> Danger
ㅤㅤc) 절반 미만이 다수 클래스 -> Safe
4. 데이터 선택 또는 제외
ㅤㅤa) Noise 제외: 노이즈로 보고 무시하자!
ㅤㅤb) Danger 선택: 위험한 영역에 있으니 집중적으로 생성하자!
ㅤㅤc) Safe 제외: 비교적 안전한 곳에 있어 굳이 합성할 필요가 없겠다!
5. Danger에 해당하는 소수 클래스 데이터에 대해서만 SMOTE 진행
다수 클래스와 소수 클래스의 경계선(Borderline)이 형성되는 지점에 새로운 데이터의 합성이 집중된다! 쉽게 말하자면, 너무 다수 클래스에 붙어 있어도, 너무 소수 클래스에 붙어 있어도 선택받지 못한다는 점. (데이터의 밸런스 유지..)
그러나 이 방법은 다수 데이터의 존재를 고려하지 않는다는 한계가 있다. 그러나, 놀 랍 게 도 다수 데이터까지 고려하여 데이터를 합성할 수 있는 방식인 Radius-SMOTE 방식이 존재한다고 한다. 글이 매우 길어졌으니.. 이건 다음에 포스팅 하는걸로..! Radius-SMOTE는 논문도 직접 보고, 캐글 데이터 기반으로 코드도 구현할 수 있으면 해봐야겠다. 빠2 =)
