1. 분류의 개요 - Classification
- 지도학습 : 명시적인 정답이 있는 데이터가 주어진 상태에서 학습하는 머신러닝 방식
→ 학습 데이터로 주어진 데이터의 피처와 레이블 값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델 생성, 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
분류의 알고리즘
- 나이브 베이즈 : 베이즈 통계와 생성 모델에 기반
- 로지스틱 회귀 : 독립변수와 종속변수의 선형 관계성 기반
- 결정 트리 : 데이터 균일도에 따른 규칙 기반
- 서포트 벡터 머신 : 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 역할
- 최소 근접 (Nearest Neighbor) : 근접 거리를 기반 (KNN으로 많이 사용)
- 신경망 : 심층 연결 기반
- 앙상블 : 서로 다른(or 같은) 머신러닝 알고리즘 결합
앙상블 기법
-
분류에서 가장 각광을 받는 분야 중 하나, 정형 데이터의 예측 분석 영역에서는 매우 높은 예측 성능을 자랑함
-
앙상블의 분류
- 배깅 : 랜덤 포레스트가 대표적
- 부스팅 : Gradient Boosting, XGBoost, LightGBM등이 대표적, 기존보다 수행성능을 높이면서, 수행시간은 단축시키는 알고리즘이 계속 등장
-
결정 트리 : 앙상블의 기본 알고리즘으로 일반적으로 사용함.
- 장점 : 쉽고, 유연함, 사전 데이터 가공의 영향이 매우 적음
- 단점 : 예측 성능을 향상시키기 위해서는 복잡한 구조를 가져야 하는데, 이로 인해서 오히려 과적합이 발생할 수 있음.
→ 그런데, 앙상블에서는 이것이 오히려 장점으로 연결됨
앙상블의 개념 : 매우 많은 여러개의 약한 학습기 (예측이 상대적으로 떨어지는 학습 알고리즘)을 결합해 확률적 보완, 오류가 발생한 부분에 대한 가중치를 계속 업데이트하면서 예측 성능 보완
2. 결정 트리
- 결정 트리 : 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 규칙을 만드는 것
- 구현 방식 : If - Else 과 유사
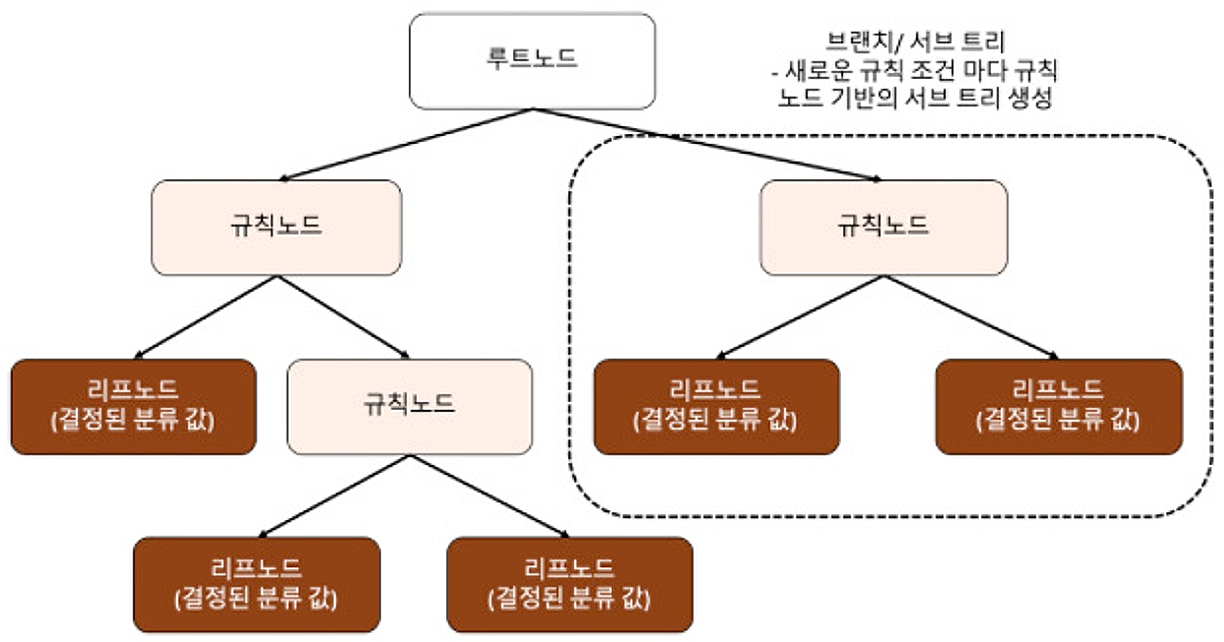
- 규칙 노드 : 규칙 조건이 되는 노드
- 리프 노드 : 결정된 클래스 값
- 서브트리 : 새로운 규칙 조건마다 생성
→ 데이터 세트에 피처가 있고, 이러한 피처가 결합해 규칙 조건을 만들 때마다 규칙 노드가 만들어짐.
→ 규칙이 많을 수록, 분류를 결정하는 방식이 복잡해지고, 과적합으로 이어지기 쉬움
→ 트리의 깊이가 깊어질수록 결정 트리의 예측 성능이 저하될 가능성이 높음
- 적은 결정 노드 → 높은 정확도를 위한 조건
- 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 함.
- → 최대한 균일한 데이터 세트를 구상하는 것이 중요함
💡퀴즈
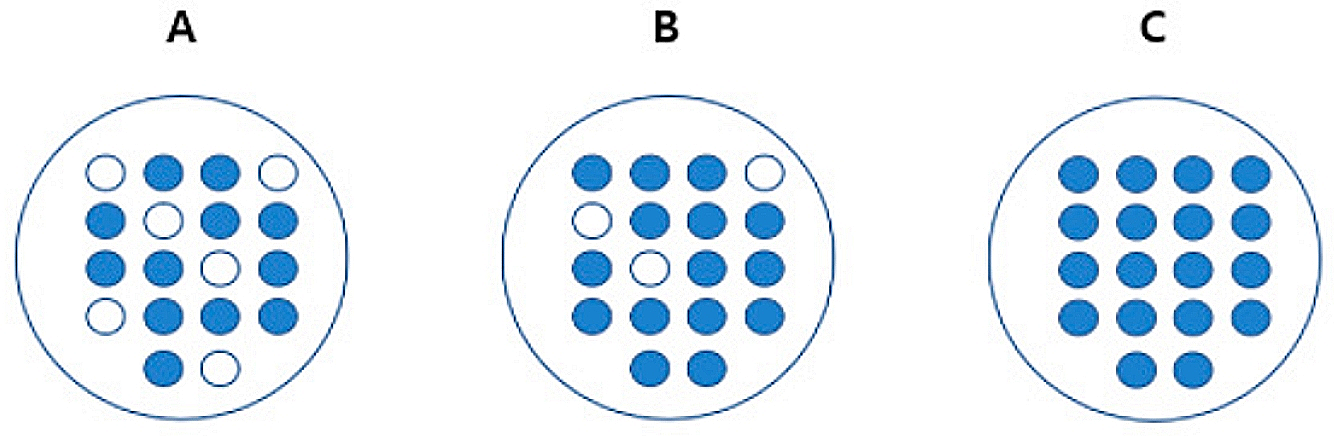
A, B, C 중 어떤 순서로 균일도가 가장 높을까?
└> C > B > A
설명 : C는 모두 파란 공으로 구성되어있으므로 데이터가 가장 균일함. A는 파란 공과 하얀 공의 비율이 비슷하기 때문에 균일도가 가장 낮음.
📍 . If, 위 데이터셋에서 무작위로 공을 뽑는다면?
◾ C - 별 다른 정보 없이도 '파란 공'이라고 쉽게 예측 가능
◾ A - 상대적으로 혼잡도가 높고 균일도가 낮아 같은 조건에서 데이터를 판단하는데 있어 더 많은 정보(조건)이 필요.
- 결정 노드의 역할 : 정보 균일도가 높은 데이터 세트를 선택할 수 있도록 규칙 조건을 만듦. → 정보 균일도가 데이터 세트로 쪼개질 수 있도록 조건을 찾아 서브 데이터 세트를 만들고, 다시 이 데이터 세트에서 균일도가 높은 자식 데이터 세트를 쪼개는 방식으로 반복
-
정보 이득 지수
-
엔트로피를 기반
💡 엔트로피 : 주어진 데이터 집합의 혼잡도 → 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮음.
-
공식 : 1 - 엔트로피
-
결정 트리는 정보 이득 지수로 분할 기준을 정하는데, 정보 이득이 높은 속성을 기준으로 분할
-
정보 이득 지수가 높을수록, 엔트로피가 낮을수록 균일하고 좋은 데이터
-
-
지니 계수
- 불평등 지수를 나타낼 때 사용. 0으로 갈 수록 평등, 1로 갈수록 불평등
- 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 판단
- 최대값은 0.5
2.1 결정트리 모델의 특징
- 결정 트리의 장점
- 정보의 ‘균일도’라는 룰을 기반으로 하고 있기 때문에, 알고리즘이 쉽고 직관적임.
- 균일도만 신경을 쓰면 되기 때문에, 특정한 경우를 제외하면 각 피처의 스케일링과 정규화 같은 전처리 작업도 필요 없음.
- 결정 트리의 단점
- 과적합으로 정확도가 떨어짐 → 서브 트리를 계속 만들면, 피처가 많고, 균일도가 다양하게 존재할 수록 트리의 깊이가 커지고 복잡해질 수 밖에 없음.
→ 트리의 크기를 사전에 제한하는 것이 오히려 성능을 높이는데 도움이 됨.
2.2 결정트리 파라미터
| 항목 | 설명 |
|---|---|
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터 수, 과적합을 제어하기 위해 사용 |
| min_samples_leaf | - 리프 노드가 되기 위한 최소한의 샘플 데이터 수 - 되도록이면 작게 설정하는 것이 좋음 |
| max_features | - 최적의 분할을 위해 고려할 최대 피처 개수 |
| max_depth | - 트리의 최대 깊이 지정 - 너무 깊으면 과적합이 발생할 수 있으므로 조정 필요 |
| max_leaf_nodes | - 리프 노드의 최대 개수 |
2.3 결정트리 모델의 시각화
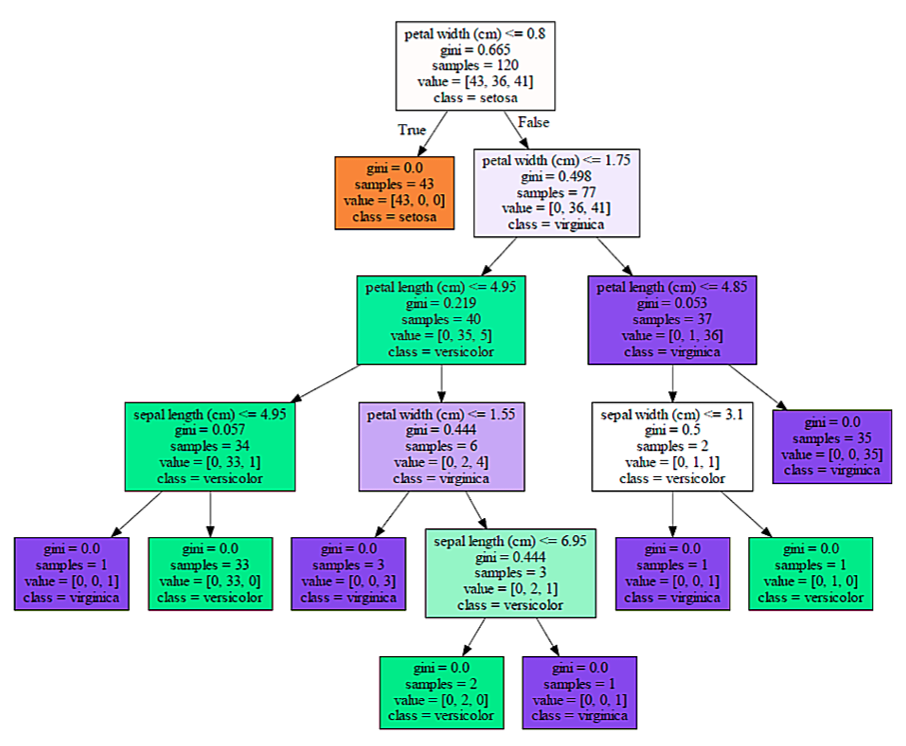
설명
- petal length(cm) <=2.45 -> 피처 조건
- 자식 노드를 만들기 위한 규칙 조건
- 이 조건이 없으면 리프 노드임
- gini -> 지니 계수
- value =[]에서 주어진 데이터들의 분포의 균일성을 나타냄
- samples -> value의 총 개수
- value = [] -> 총 데이터를 클래스별로 나눈 것
- 붓꽃 데이터셋의 클래스 값은 [0,1,2]이며, 순서대로 [Setosa, Versicolor, Virginica]이다.
- 만약 value [20, 30, 1]이면 Setosa는 20개, Versicolor는 30개, Virginica는 1개로 데이터가 구성돼있다는 뜻.
feature_importances__를 이용해 피처의 중요도를 파악할 수 있음
- feature_importances__의 특징:
- ndarray형태로 피처 순서대로 값을 반환함.
- 값이 높을수록 해당 피처 중요도가 높다는 뜻.
2.4 결정트리 과적합 (Overfitting)
- visualize_boundary() : ML이 클래스 값을 예측하는 결정 기준을 색상과 경계로 나타내서 모델이 어떻게 데이터 세트를 예측하고 분류하는지 이해할 수 있게 도와주는 함수
1) 특정한 트리 생성 제약없는 결정 트리의 Decsion Boundary 시각화.
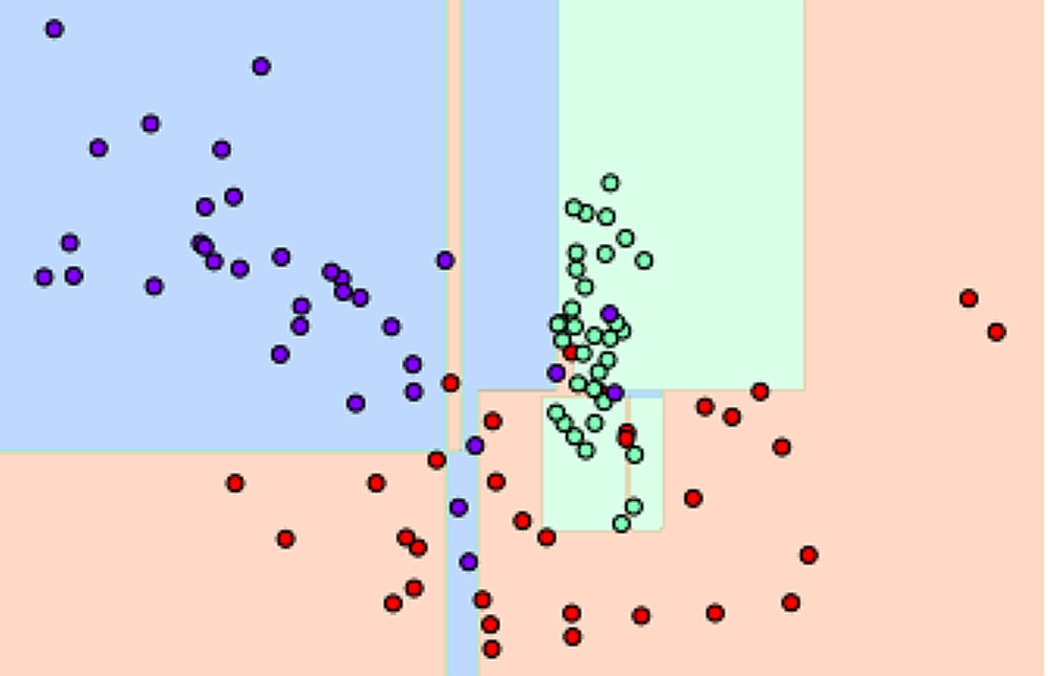
2) min_samples_leaf=6 으로 트리 생성 조건을 제약한 Decision Boundary 시각화
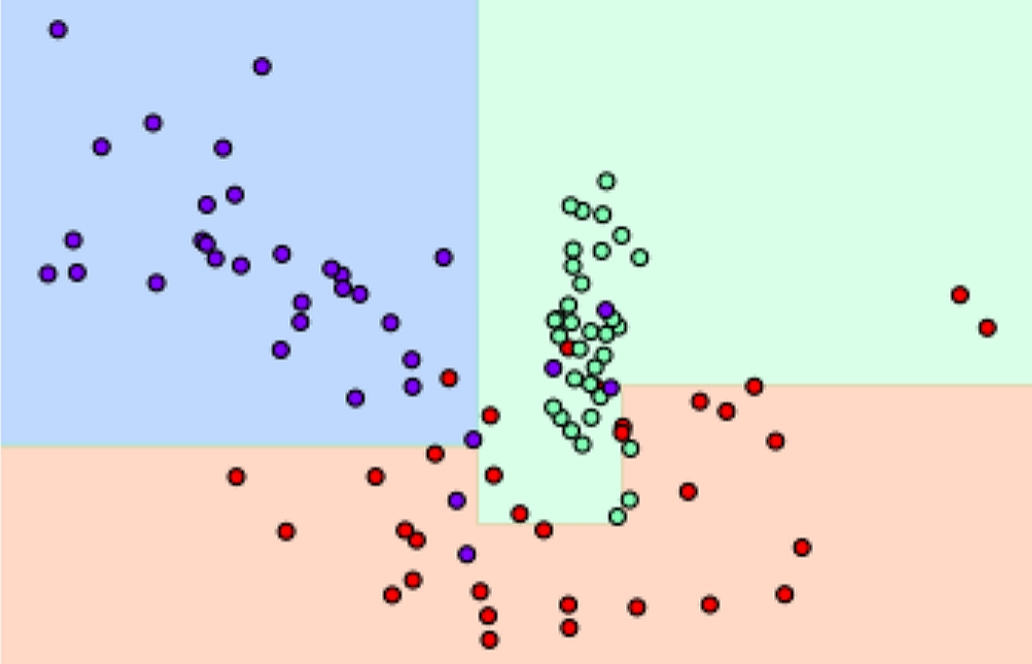
📌 제약이 없으면 min_samples_leaf=6처럼 제약조건을 다는 것 보다 과적합 가능성이 높다.
