기초 수학과 해석 기초(1)
함수
극한(limit)
연속성(Continuity)
미분(Differentiation)
적분(Integration)
테일러 전개(Taylor Series)
근사
- 개념 : 복잡한 수학적 대상을 간단한 형태로 대략적으로 표현하는 방법
=> 정확한 계산이 불가능하거나 비효율적인 경우 실제값에 "충분히 가까운"값을 찾는 과정 - 머신러닝 관련 근사
- 손실 함수의 최적화(2차 근사 사용)
근사의 주요 유형
선형 근사(Linear Approximation)
- 미분 가능한 함수를 접선으로 근사
- 점 x=a에서의 접ㅈ선 방정식

다항식 근사(Polynomial Approximation)
- 테일러 급수(Taylor Series)활용
- 고차 다항식으로 함수 근사
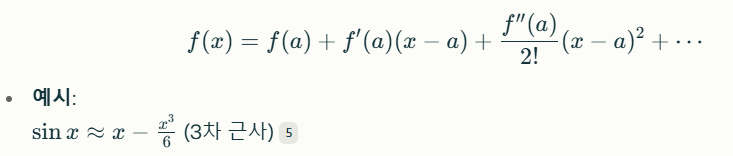
수치적 근사(Numerical Approximation)
- 유한 차분법, 수치 적분 등 알고리즘 기반 근사
- 컴퓨터 계산에서 필수적 (ex. 미분 방정식의 수치 해석)
근사의 핵심 원리
1. 국소성(Locality)
- 특정 점 주변에서만 정확하며, 범위가 넓어질수록 오차 증가
2. 오차 관리
- 나머지항을 통해 오차 추정(라그랑주 나머지)
3. 실용적 절충
- 계산 복잡성과 정확도 사이의 균형
왜 근사가 필요할까?
머신러닝에서의 2차 근사는 손실 함수(loss function)를 2차 다항식으로 근사화하여 최적화 과정을 가속화하는 기법입니다. 이는 1차 미분(기울기)뿐 아니라 2차 미분(곡률) 정보를 활용해 더 정확한 파라미터 업데이트를 가능하게 합니다.

=> 이해하기 쉽게 설명
-
문제: 머신러닝 모델은 종종 수백만 개의 계산을 수행해야 합니다.
(예: 고양이 사진을 인식하려면 "눈, 귀, 털" 등 수천 개의 패턴 분석 필요) -
해결책: 정확한 계산 대신 "충분히 비슷한" 추측으로 효율성을 높입니다.
→ "근사"는 정확성 vs 효율성의 절충입니다.
머신러닝 근사의 주요 유형
(1) 확률 분포 근사
상황: 주사위를 100번 던져 각 눈금의 확률을 알고 싶을 때
정확한 방법: 모든 경우의 수 계산 ( 6의 100승
→ 계산 불가능)
<근사 방법>
MCMC : 주사위를 실제로 여러 번 던져 경험적 확률 추정
Variational Inference : "확률은 대충 이럴 것이다"라고 가정하고 계산
(2) 함수 근사
상황: 집 값 예측 모델에서 "방 개수 → 가격" 관계를 찾을 때
정확한 방법: 모든 가능한 수학적 관계 시도
<근사 방법>
선형 회귀 : "방 개수가 늘수록 가격이 일정 비율로 오른다"고 가정
신경망 : 복잡한 관계를 여러 개의 간단한 계산 조합으로 표현
확률 분포 근사
1. MCMC(Markov Chain Monte Carlo)
- 확률분포에서 샘플링 -> 분포를 추정
- 마르코프 체인(Markov Chain)을 이용해 점진적으로 목표 분포에 수렴
주사위 확률 계산 시, 실제로 여러 번 던져 경험적 확률 추정
- 장점: 충분히 오래 실행하면 정확한 결과 도출 가능
- 단점: 계산 시간이 길고, 수렴 여부 확인이 어려움
2. Variational Inference (변분 추론)

단순한 분포(예: 정규분포)를 가정 → KL 발산 최소화로 근사
- 최적화(Optimization) 기반 접근
고양이 사진의 복잡한 분포를 "평균값과 표준편차"로 표현
- 장점: 계산이 빠름
- 단점: 가정한 분포가 틀리면 큰 오차 발생
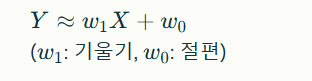
함수근사
1. 선형 회귀(Linear Regression)
기본 개념
"직선으로 데이터를 설명"
입력 변수(X)와 출력 변수(Y)의 선형 관계를 가정
예시: 집 크기(㎡) → 집 값 예측
동작 원리
손실 함수(Loss Function):
예측값과 실제값의 차이(오차) 제곱의 합
최적화:
- 경사하강법(Gradient Descent)으로 W1, W0 조정
- 오차가 최소화되는 직선 찾기
실제 머신러닝 사례
(1) 이미지 인식
문제: 고양이 사진을 인식하는 규칙을 수학적으로 정의 불가
근사 전략:
신경망: "고양이 = 눈 2개 + 삼각형 귀 + 수직 줄무늬" 같은 단순 패턴 조합으로 학습
(2) 추천 시스템
문제: 모든 사용자의 취향을 정확히 파악 불가
근사 전략:
행렬 분해: "A 사용자와 B 사용자는 비슷한 영화를 좋아하니, 비슷한 추천을 주자"
