1. 다변량 회귀 분석
- 여러 개의 독립 변수가 종속 변수에 미치는 영향을 동시에 파악
- 그 관계를 수학적인 모델로 표현하는 기법

회귀 분석 ?
- 회귀 분석은 한 가지(또는 여러 개)의 독립 변수(예측 변수)가 종속 변수(목표 변수)에 어떠한 영향을 미치는지, 그 관계를 수식으로 나타내려는 시도
종속변수: 결과나 예측하려는 대상(독립변수로 부터 영향을 받음)독립변수: 결과에 영향을 줄 것으로 생각되는 원인 or 요인
2. 주성분 분석(PCA)
- 고차원의 데이터를 몇 개의 주요한 축(주성분)으로 변환하여 데이터의 구조와 분산을 효율적으로 설명하는 기법
- 많은 변수들이 동시에 존재하는 데이터를 보다 간단한 구조로 요약하면서, 전체 데이터의 분산(변동성)을 최대한 보존하는 데 있음
차원 축소
- 데이터를 몇 개의 주성분으로 변환함으로써, 원래 변수들 사이의 상관성을 반영하고 데이터의 핵심 구조(정보)를 잃지 않으면서 차원을 축소
비지도 학습
- PCA는 별도의 목표 변수(종속 변수)를 필요로 하지 않습니다. 즉, 데이터에 내재한 분산과 상관 관계만을 이용하여 새로운 축을 찾는 비지도 학습의 한 방법
<주성분의 해석과 응용>
분산의 기여도
각 주성분이 설명하는 분산의 비율은 해당 주성분의 고유값을 전체 고유값의 합으로 나누어 계산할 수 있습니다. 예를 들어, 첫 번째 주성분이 전체 분산의 50%를 설명한다면, 이 축이 데이터를 요약하는 데 매우 중요한 역할을 한다고 볼 수 있습니다.
변수 기여도(loading)
각 주성분이 만들어질 때, 각 원래 변수들이 일정 가중치(loading)를 가집니다. 이 loading 값은 원래 변수들이 주성분 형성에 얼마나 기여하는지를 보여줍니다.
예를 들어, “빨강 4%, 파랑 30%”라는 표현은 특정 주성분을 만들 때 각 변수(여기서는 비유적으로 색깔로 표현)가 차지하는 비율을 의미합니다.
응용 분야
데이터 시각화
복잡한 고차원 데이터를 2차원 또는 3차원 공간에 투영하여 시각적으로 분포나 군집 패턴을 파악할 수 있습니다.
잡음 제거(노이즈 필터링)
데이터의 주요 분산을 보존하면서 잡음이나 불필요한 변동성을 제거할 수 있습니다. 덜 중요한 주성분(분산이 작은 축)들은 노이즈에 기여하는 경우가 많기 때문입니다.
특성 추출(Feature Extraction)
새로운 주성분들을 변수로 사용하여, 원래의 다수 변수보다 더 간결한 특성 집합으로 모델링하거나 분류, 군집화 등 다른 분석에 활용할 수 있습니다.
예시
- 이미지 압축 : PCA를 통해 이미지의 주요 패턴(예: 얼굴의 주요 특징)을 추출하면, 원래의 수많은 픽셀 정보를 몇 개의 주성분으로 요약
- 금융 데이터 분석 : PCA를 통해 금융 지표(주가, 거래량, 변동성 등)를 몇 개의 주성분으로 압축하면, 시장 동향(예: 경기 호황/불황)을 보다 간결하게 이해
3. 요인 분석(Factor Analysis)
- 여러 관찰 변수들 사이에 존재하는 공통된 패턴이나 구조—즉, 잠재 요인(latent factors)을 찾아내어 변수들 간의 상관 관계를 설명하는 다변량 통계 기법
<목적 및 필요성>
잠재 요인의 발견
관찰 변수(예: 심리 검사 문항, 설문 문항 등)들이 실제로는 몇 개의 공통된 요인에 의해 설명될 수 있다고 가정합니다. 이때 “요인”은 직접적으로 측정되지 않지만, 여러 변수 간의 공통 변동성을 설명하는 잠재 변수입니다.
상관 관계의 설명
관찰 변수 간에 보이는 높은 상관 관계는 이들 변수들이 공통된 요인에 의해 영향을 받기 때문이라고 보고, 이러한 잠재 요인을 추출해 변수 간의 관계를 해석할 수 있습니다.
차원 축소
많은 변수들을 소수의 요인으로 요약함으로써 데이터를 단순화하고, 해석과 응용에 용이하도록 합니다.
공통 요인(Common Factor)
여러 관찰 변수들이 공유하는 부분으로, 변수 간 상관을 설명합니다. 예를 들어, 여러 심리 검사 문항이 ‘불안’이나 ‘우울’ 같은 공통한 심리적 상태에 기인할 수 있습니다.
고유 요인(Unique Factor) 또는 특이요인(Specific Factor)
각 변수에 특유한 변동이나 오차를 나타냅니다. 이는 해당 변수만의 특성이나 측정 오차 등, 다른 변수들과 공유되지 않는 부분입니다.
4. 판별분석
- 주어진 데이터에서 미리 정의된 그룹(또는 클래스)을 가장 잘 구분해줄 수 있는 변수들의 선형(또는 비선형)조합을 찾는 통계 기법
- 분류 문제에서 많이 사용
- 각 그룹의 특징을 기반 -> 새로운 관측치가 어느 그룹에 속하는지 예측할 때 유용
<목표 및 개념>
판별 분석의 주요 목적은 미리 정의된 그룹(클래스) 간의 차이를 극대화하는 변수 조합(판별 함수)를 찾아, 각 관측치가 어느 그룹에 속하는지 효과적으로 분류하는 것입니다.
분류 문제:
예를 들어, 의료 진단에서 환자의 여러 검사 결과(변수들)를 이용해 환자가 질병이 있는 그룹과 없는 그룹으로 분류하거나, 마케팅 데이터에서 고객을 특정 유형(예: 충성 고객, 이탈 가능 고객)으로 분류할 수 있습니다.
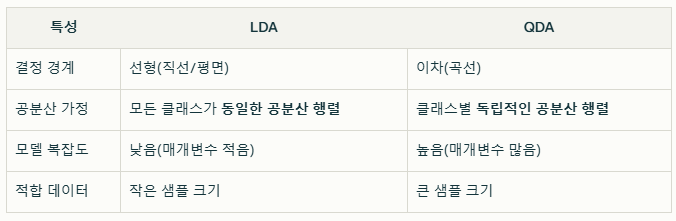
선형 판별 분석(LDA)
-
가정: 각 그룹이 동일한 공분산 행렬을 가진다고 가정하여, 변수의 선형 결합을 통한 분류 경계(결정 경계)가 선형이 됩니다.
-
특징: 계산이 비교적 간단하고, 데이터가 선형 결정 경계로 분리될 때 효과적입니다.
이차 판별 분석(QDA)
-
가정: 각 그룹이 서로 다른 공분산 행렬을 가진다고 가정합니다.
-
특징: 데이터가 선형 결정 경계로 잘 분리되지 않을 때, 보다 유연하게 그룹을 분류할 수 있으나, 모델의 복잡성이 증가하여 데이터가 적을 경우 과적합의 위험이 있습니다.
공분산?
- 두 변수간의 관계를 나타내는 값
- 두 변수가 같은 방향으로 움직이는지(양의 상관)
- 반대 방향으로 움직이는지(음의 상관)
- 서로 관계가 없는지(0에 가까움)를 측정
상관계수
- 공분산이 단위에 의존적이기 때문에 이를 해결하기 위해 공분산을 표준화한 값
- 상관계수는 항상
-1≤r≤1사이의 값을 가짐
5. 군집분석
-
주어진 자료만으로 성격이 다른 세부 군집으로 나누고자 하는 방법
-
집단의 수 OR 집단 구조에 대한 가정이 없음
-
개체들 사이의 유사성(OR 비유사성) 또는 거리에 근거하여 군집을 형성하고 특성을 파악하는 탐색적 다변량 통계분석임
-
대용량 데이터에서 개개의 관찰치를 요약하는 것보다 전체를 유사한 관찰치들의 군집으로 구분하여 복잡한 전체 보다는 그를 잘 대표하는 군집들을 관찰함으로써 전체 데이터에 대한 의미있는 정보를 얻어낼 수 있음
5-1. 계층적 군집화 (Hierarchical Clustering)
-
가장 유사한 두 개체들을 선택하여 병합해 가는 방법 -> 데이터 포인트들을 하나씩 합침(병합)
-
먼 개체들을 선택하여 나누어 가는 방법 -> 큰 그룹에서 나눠가며(분할)
트리 구조(dendrogram)를 만든다. -
트리 기반임
-
소량의 자료를 군집화하는 방법
-
가계도처럼 데이터의 유사성을 계층적으로 표현할 수 있음
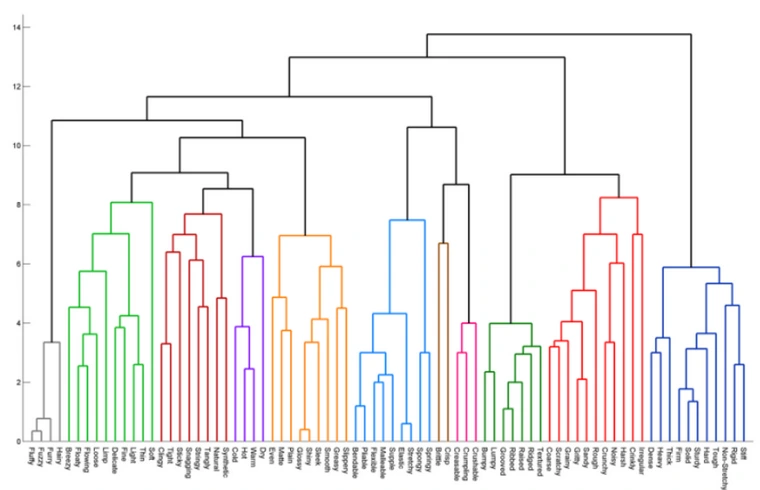
출처 : https://ratsgo.github.io/machine%20learning/2017/04/18/HC/
장점
- 군집 개수 K를 나중에 시각화해서 선택 가능.
- 시각적으로 군집 형성 과정을 볼 수 있어 이해하기 쉬움.
5-2. 비계층적 군집화(Non-hierarchical cluster)
= 분할방법
- 군집 수가 미리 결정 되어 있을 때 사용 -> 군집 수에 대한 사전정보가 있거나 군집 수를 제한해야할 경우 사용
5-3. K-평균 군집화 (K-means Clustering)
- 군집의 개수 K를 미리 정해줘야함
- 데이터를 K개의 중심점(centroid) 주위로 나눈다.
- 반복하면서 중심점을 계속 조정해, 각 군집이 내부적으로 가장 응집력 있게 만든다.
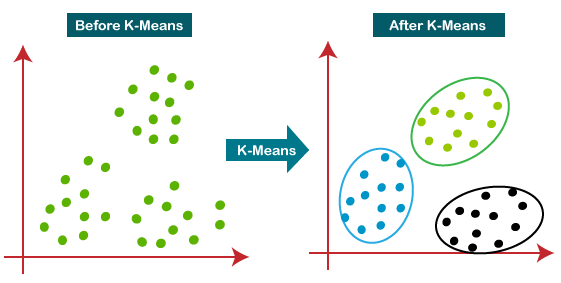
출처 : https://www.tpointtech.com/k-means-clustering-algorithm-in-machine-learning
5-4. 밀도 기반 군집화(DBSCAN)
- 밀도가 높은 곳을 하나의 군집으로 묶음
- 서로 가까운 점들이 일정 밀도 이상이면 하나의 그룹으로 본다
장점
- 복잡한 모양의 군집도 잘 찾아냄
- 이상치를 자동으로 따로 분류 가능
단점
- 파라미터(eps, minPts) 설정이 민감함.
출처 : https://www.reddit.com/r/MachineLearning/comments/1jcaklx/p_dbscan_clustering_on_a_classic_nonlinear/?rdt=52580
6. 다변량 분산분석(Multivariate Analysis of Variance, MANOVA)
- 한 개의 종속 변수가 아닌 여러 종속 변수들에 대해 집단 간 차이가 있는지 동시에 검정하는 통계적 방법
- 여러 종속 변수를 동시에 고려하여 집단 간 전반적인 차이를 검정하는 강력한 분석 도구
목적
- 여러 종속 변수의 동시 검증
- 상관관계 고려
- 집단 간 전반적 패턴 파악
7. 정준 상관 분석(CCA)
- 두 개의 변수 집합 사이에 존재하는 상호 연관성을 동시에 분석하는 다변량 기법
- 한쪽 변수 집합과 다른 쪽 변수 집합 각각에 대해 새로운 변수(정준 변량, canonical variates)를 만들어, 이 두 정준 변량 사이의 상관 관계를 최대화하도록 하는 방법
8. 구조 방정식 모델링
-
목적: 변수들 간의 인과 관계를 동시에 모형화하며, 측정 오차를 고려하는 통계 기법입니다.
-
특징: 관찰 변수와 잠재 변수를 동시에 다루며, 경로 분석(Path Analysis)과 요인 분석이 결합된 형태
-
응용 분야: 심리학, 경영학, 사회과학 연구에서 복잡한 인과 모델링
9. 다차원 척도법
-
목적: 데이터 사이의 거리를 바탕으로 저차원 공간에 데이터를 시각화하는 기법입니다.
-
응용 분야: 심리학, 생태학, 마케팅 등에서 유사성 혹은 거리 데이터를 시각적으로 표현
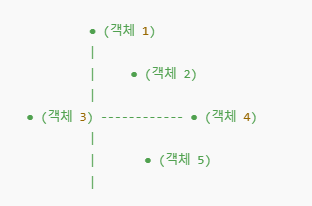
-
각 점은 개별 객체
-
점들 사이의 거리는 원본 유사도 데이터를 기반으로 하여 객체들 간의 관계를 시각화함
분산분석(ANOVA)참고 자료 - https://www.qualtrics.com/ko/experience-management/research/anova/
