테이블을 설계하다 보면 이런식의 JSONB 타입의 배열 오브젝트 타입의 컬럼을 사용해야 할 때가 있습니다.
| id | name | employees | employees1 |
|---|---|---|---|
| 1 | 삼성 | [{"age": "20", "name": "홍길동1"}, {"age": "21", "name": "홍길동2"}, {"age": "22", "name": "홍길동3"}] | [{"age": "20", "name": "홍길동1"}, {"age": "21", "name": "홍길동2"}, {"age": "22", "name": "홍길동3"}] |
| 2 | 카카오 | [{"age": "30", "name": "장동건1"}, {"age": "31", "name": "장동건2"}, {"age": "32", "name": "장동건3"}] | [{"age": "30", "name": "장동건1"}, {"age": "31", "name": "장동건2"}, {"age": "32", "name": "장동건3"}] |
| 3 | 네이버 | [{"age": "40", "name": "스티브1"}, {"age": "41", "name": "스티브2"}, {"age": "42", "name": "스티브3"}] | [{"age": "40", "name": "스티브1"}, {"age": "41", "name": "스티브2"}, {"age": "42", "name": "스티브3"}] |
하지만 정작 데이터를 select 할 때 특정값(예를들면 name)만 추출해서 필요한 경우가 있습니다.
| name |
|---|
| 홍길동1 |
| 홍길동2 |
| 홍길동3 |
| 홍길동1 |
| 홍길동2 |
| 홍길동3 |
| 장동건1 |
| 장동건2 |
| 장동건3 |
| 장동건1 |
| 장동건2 |
| 장동건3 |
| 스티브1 |
| 스티브2 |
| 스티브3 |
| 스티브1 |
| 스티브2 |
| 스티브3 |
1. jsonb_to_recordset + UNION 사용하기
select item. FROM company, jsonb_to_recordset(company.employees) as item("name" text)
union all
select item1. FROM company, jsonb_to_recordset(company.employees1) as item1("name" text);
다행이 데이터는 잘 나옵니다.
| name |
|---|
| 홍길동1 |
| 홍길동2 |
| 홍길동3 |
| 장동건1 |
| 장동건2 |
| 장동건3 |
| 스티브1 |
| 스티브2 |
| 스티브3 |
| 홍길동1 |
| 홍길동2 |
| 홍길동3 |
| 장동건1 |
| 장동건2 |
| 장동건3 |
| 스티브1 |
| 스티브2 |
| 스티브3 |
하지만!
Append (cost=0.00..4442.60 rows=126000 width=32) (actual time=0.020..0.036 rows=18 loops=1)
cost가 4442.60으로 매우 높습니다! 이는 데이터가 증가 할 수록 성능에 엄청난 악영향을 미칠 수 있습니다.
2. jsonb_to_recordset + || 사용하기
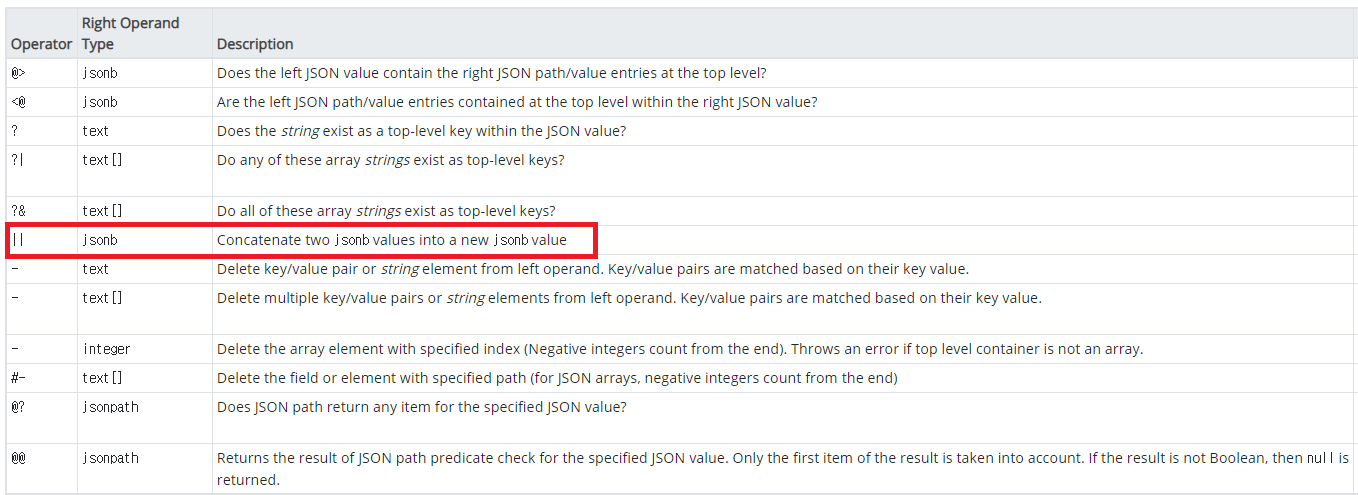
|| 연산자는 컬럼을 연결하여 새로운 컬럼을 만들 수 있습니다.
|| 연산자를 활용해서 쿼리를 변경해 보겠습니다.
select item.*
FROM (select employees || employees1 as rs FROM company) c, jsonb_to_recordset(c.rs) as item("name" text);
결과
Nested Loop (cost=0.01..1276.30 rows=63000 width=32) (actual time=0.025..0.033 rows=18 loops=1)
같은 데이터를 select 하더라도 cost가 1/4만큼 줄어든 결과를 얻을수 있었습니다!
참조 사이트 https://www.postgresql.org/docs/12/functions-json.html
