
✨ 지도 학습은 입력과 출력 샘플 데이터가 있고, 주어진 입력으로부터 출력을 예측하고자 할 때 사용
2.1 분류와 회귀
-
지도 학습에는 분류(classification)와 회귀(regression)이 있다.
-
분류는 미리 정의된, 가능성 있는 여러 클래스 레이블 중 하나를 예측하는 것이다.
이진 분류( binary classification)
- 두 개의 클래스로 분류
- 질문의 답이 예/아니오만 나오는 경우
다중 분류( multiclass classification )
- 셋 이상의 클래스로 분류
-
회귀는 연속적인 숫자, 또는 실수를 예측하는 것이다.
예시
- 어떤 사람의 교육 수준, 나이, 주거지를 바탕으로 연간 소득을 예측하는 것이 예측
- 옥수수 농장에서 전년도 수확량과 날씨, 고용 인원수 등으로 올해 수확량을 예측
2.2. 일반화, 과대적합, 과소적합
-
일반화( generalization )
- 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화 되었다고 한다.
- 모델을 만들 때는 가능한 한 정확하게 일반화되도록 해야한다.
-
과대 적합( overfitting )
- 가진 정보를 모두 사용해서 너무 복잡한 모델을 만드는 것
- 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되기 어려울 때 일어난다.
-
과소 적합( underfitting )
- 데이터의 면면과 다양성을 잡아내지 못하고 훈련 세트에도 잘 맞지 않은 경우
- 너무 간단한 모델이 선택되는 것
- 모델을 복잡하게 할수록 훈련 데이터에 대해서는 더 정확히 예측할 수 있다.
- 하지만 너무 복잡해지면 훈련 세트의 각 데이터 포인트에 너무 민감해져 새로운 데이터에 잘 일반화 되지 못한다.
- ✨✨ 일반화 성능이 최대가 되는 최적점에 있는 모델을 찾아야 한다.
2.2.1. 모델 복잡도와 데이터셋 크기의 관계
- 모델의 복잡도는 훈련 데이터셋에 담긴 입력 데이터의 다양성과 관련이 깊다.
- 데이터셋에 다양한 데이터 포인트가 많을수록 과대적합 없이 더 복잡한 모델을 만들 수 있다.
- 보통 데이터 포인트를 더 많이 모으는 것이 다양성을 키워주므로 큰 데이터셋은 더 복잡한 모델을 만들 수 있게 해준다.
- 그러나 같은 데이터 포인트를 중복하거나 매우 비슷한 데이터를 모으는 것은 도움이 되지 않는다.
2.3. 지도 학습 알고리즘
- 머신러닝 알고리즘들을 둘러보면서 데이터로부터 어떻게 학습하고 예측하는지 설명한다.
- 모델들의 장단점을 평가하고 어떤 데이터가 잘 들어맞을지 살펴본다.
- 특정 알고리즘의 작동 방식이 궁금할 때 다시 돌아와서 확인하는 참고 자료로 사용하면 좋다.
2.3.1. 예제에 사용할 데이터셋
- 데이터는 작고 작위적으로 만든 것
- 특정 알고리즘의 특징을 부각하기 위해 만든 것도 있다.- 실제 샘플로 만든 큰 데이터셋도 있다.
- 두 개의 특성을 가진
forge데이터셋은 인위적으로 만든 이진 분류 데이터셋
import matplotlib.pyplot as plt
%matplotlib inline
import mglearn
# 데이터셋을 만든다.
x, y = mglearn.datasets.make_forge()
# 산점도를 그린다.
mglearn.discrete_scatter(x[:, 0], x[:, 1], y)
plt.legend(['클래스 0', '클래스 1'], loc=4)
plt.xlabel('첫 번째 특성')
plt.ylabel('두 번째 특성')
print('x.shape:', x.shape)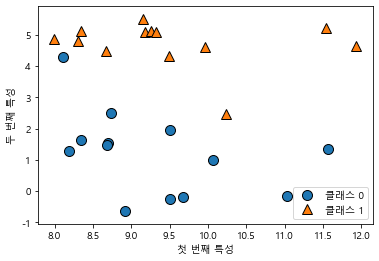
- 회귀 알고리즘에는 인위적으로 만든
wave데이터셋을 사용
x, y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(x, y, 'o')
plt.ylim(-3, 3)
plt.xlabel('특성')
plt.ylabel('타깃')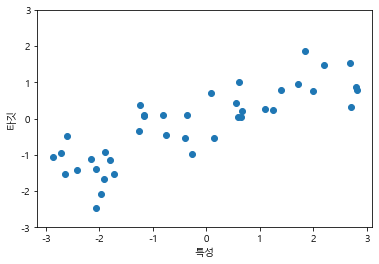
- 특징이 적은 데이터셋( 저차원 데이터셋 )에서 얻은 직관이 특성이 많은 데이터셋( 고차원 데이터셋 )에서 그대로 유지되지 않을 수 있따.
- 이런 사실을 유념해둔다면 알고리즘을 배울 때 저차원 데이터셋을 사용하는 것이 매우 좋다.
- 2차원이 넘는 특성은 표현하기가 힘들어 손쉽게 시각화하기 어렵다.
📍 위스콘신 유방암 데이터셋 사용
자세한 정보는
cancer.DESCR에서 확인 가능
from sklearn.datasets import load_breast_cancer
import numpy as np
cancer = load_breast_cancer()
print('cancer.key(): \n', cancer.keys())
print('유방암 데이터의 형태: ', cancer.data.shape)
print('클래스별 샘플 개수: \n', {n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))})
print('특성 이름: \n', cancer.feature_names)
~~~>
cancer.key():
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
유방암 데이터의 형태: (569, 30)
클래스별 샘플 개수:
{'malignant': 212, 'benign': 357}
특성 이름:
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']📍 보스턴 주택가격 데이터셋 사용
from sklearn.datasets import load_boston
boston = load_boston()
print('데이터의 형태: ', boston.data.shape)
x, y = mglearn.datasets.load_extended_boston()
print('x.shape: ', x.shape)
~~>
데이터의 형태: (506, 13)
x.shape: (506, 104)2.3.2. K-최근접 이웃
1) K-최근접 이웃 분류
- 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용
# 최근접 이웃을 한개 사용하는 경우
mglearn.plots.plot_knn_classification(n_neighbors=1)
~~>
# 최근접 이웃을 세개 사용하는 경우
mglearn.plots.plot_knn_classification(n_neighbors=3)
~~>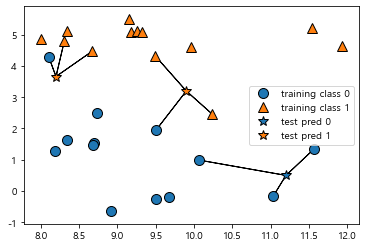
# 훈련 데이터와 테스트 데이터로 나눠 일반화 성능을 평가하기
from sklearn.model_selection import train_test_split
x, y = mglearn.datasets.make_forge()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
# 모델 학습시키기
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train, y_train)
print('테스트 세트 예측: ', clf.predict(x_test))
print('테스트 세트 정확도: {:.2f}'.format(clf.score(x_test, y_test)))
~~>
테스트 세트 예측: [1 0 1 0 1 0 0]
테스트 세트 정확도: 0.862) KNeighborsClassifier 분석
- 클래스별로 영역이 나뉘는 결정 경계를 확인 할 수 있다.
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 메소드는 self 오브젝트를 리턴
# 그래서 객체 생성과 fit 메소드를 한 줄에 쓸 수 있다.
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(x, y)
mglearn.plots.plot_2d_separator(clf, x, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(x[:, 0], x[:, 1], y, ax=ax)
ax.set_title('{} 이웃'.format(n_neighbors))
ax.set_xlabel('특성 0')
ax.set_ylabel('특성 1')
axes[0].legend(loc=3)
~~>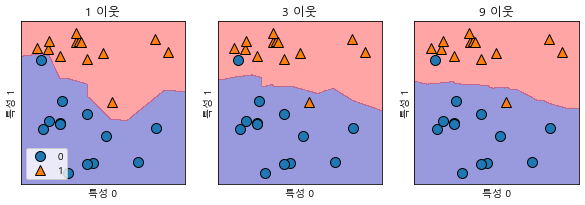
- 이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라가고 있다.
- 이웃의 수를 늘릴수록 결정 경계는 더 부드러워진다.
- 부드러운 경계는 더 단순한 모델을 의미
- 이웃을 적게 사용하면 모델의 복잡도가 높아지고, 많이 사용하면 복잡도는 낮아진다.
📍 유방암 데이터셋을 이용
# 유방암 데이터셋을 이용
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# 1 에서 10 까지 n_neighbors를 적용
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# 모델 생성
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(x_train, y_train)
# 훈련 세트 정확도 저장
training_accuracy.append(clf.score(x_train, y_train))
# 일반화 정확도 저장
test_accuracy.append(clf.score(x_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label='훈련 정확도')
plt.plot(neighbors_settings, test_accuracy, label='테스트 정확도')
plt.ylabel('정확도')
plt.xlabel('n_neighbors')
plt.legend()
~~>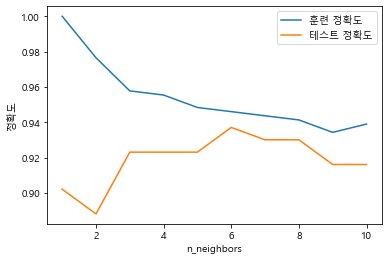
- 그래프는
n_neighbors 수( x 축 )에 따른 훈련 세트와 테스트 세트 정확도( y축 )를 보여준다. - 과대적합과 과소적합의 특징을 볼 수 있다.
3) K-최근접 이웃 회귀
📍 wave 데이터셋 이용
# 최근접 이웃을 1개로 설정했을 때
mglearn.plots.plot_knn_regression(n_neighbors=1)
~~>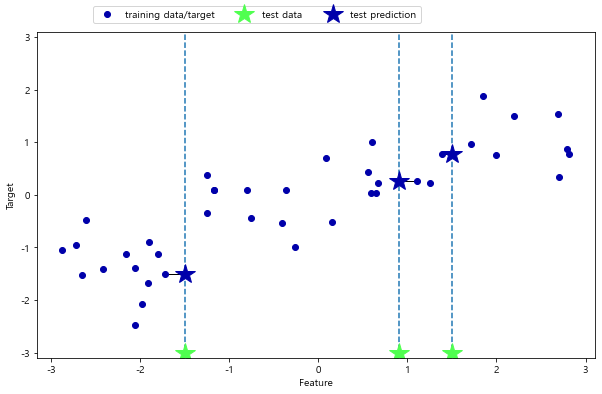
- x축에 세 개의 테스트 데이터를 흐린 별 모양으로 표시
- 최근접 이웃을 한 개만 이용할 때 예측은 그냥 가장 가까운 이웃의 타깃 값
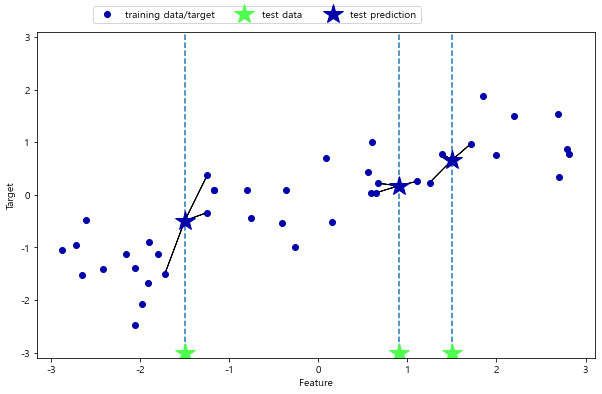
# 최근접 이웃을 3개로 설정했을 때
mglearn.plots.plot_knn_regression(n_neighbors=3)
~~>
📍 scikit-learn KNeighborsRegressor 라이브러리 사용
from sklearn.neighbors import KNeighborsRegressor
x, y = mglearn.datasets.make_wave(n_samples=40)
# wave 데이터셋을 훈련 세트와 테스트 세트로 나누기
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
# 이웃의 수를 3으로 하여 모델의 객체를 만들기
reg = KNeighborsRegressor(n_neighbors=3)
# 훈련 데이터와 타깃을 사용하여 모델 학습
reg.fit(x_train, y_train)
print('테스트 세트 예측 :\n', reg.predict(x_test))
print('테스트 세트 R^2: {:.2f}'.format(reg.score(x_test, y_test)))
~~>
테스트 세트 예측 :
[-0.05396539 0.35686046 1.13671923 -1.89415682 -1.13881398 -1.63113382
0.35686046 0.91241374 -0.44680446 -1.13881398]
테스트 세트 R^2: 0.834) KNeighborsRegressor 분석
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# -3 과 3 사이에 1,000개의 데이터 포인트를 만든다.
line = np.linspace(-3, 3, 10000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes):
# 1, 3, 9 이웃을 사용한 예측
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(x_train,y_train)
ax.plot(line, reg.predict(line))
ax.plot(x_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(x_test, y_test, 'v', c=mglearn.cm2(1), markersize=8)
ax.set_title('{} 이웃의 훈련 스코어 : {:.2f} 테스트 스코어 : {:.2f}'
.format(n_neighbors, reg.score(x_train, y_train), reg.score(x_test, y_test)))
ax.set_xlabel('특성')
ax.set_ylabel('타깃')
axes[0].legend(['모델 예측', '훈련 데이터 / 타깃', '테스트 데이터 / 타깃'], loc='best')
~~>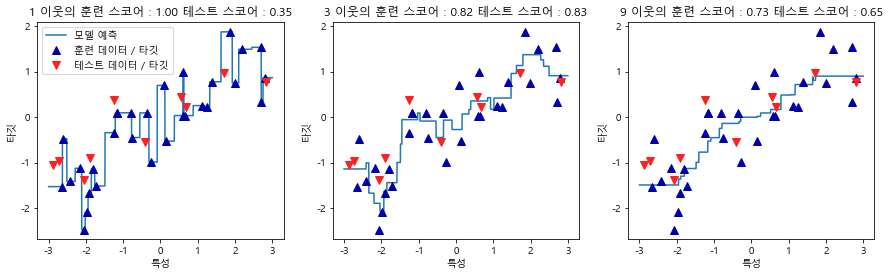
- 이웃을 하나만 사용할 때는 훈련 세트의 각 데이터 포인트가 예측에 주는 영향이 커서 예측 값이 훈련 데이터 포인트를 모두 지나간다.
- 매우 불안정한 예측을 만들어 냄 - 이웃을 많이 사용하면 훈련 데이터에는 잘 안 맞을 수 있지만 더 안정된 예측을 얻게 된다.
장단점과 매개변수
-
일반적으로
KNeighbors 분류기에 중요한 매개변수는 두 개이다.- 데이터 포인트 사이의 거리를 재는 방법
- 기본적으로 여러 환경에서 잘 동작하는 유클라디안 거리방식을 사용
- 이웃의 수
- 실제로 이웃의 수는 3개나 5개 정도로 적을 때 잘 작동하지만, 이 매개변수는 잘 조정해야한다.
- 데이터 포인트 사이의 거리를 재는 방법
-
KNN의 장점은 이해하기 매우 쉬운 모델이라는 점
-
많이 조정하지 않아도 자주 좋은 성능을 발휘한다.
- 더 복잡한 알고리즘을 적용해보기 전에 시도해볼 수 있는 좋은 시작점
-
최근접 이웃 모델은 매우 빠르게 만들 수 있지만, 훈련 세트가 매우 크면 예측이 느려진다.
- 특성의 수나 샘플의 수가 클 경우
-
KNN 알고리즘을 사용할 땐 데이터 전처리하는 과정이 중요
-
많은 특성을 가진 데이터 셋에는 잘 동작하지 않으며, 특성 값 대부분이
0인 데이터셋과는 특히 잘 작동하지 않는다. -
K-최근접 이웃 알고리즘이 이해하긴 쉽지만, 예측이 느리고 많은 특성을 처리하는 능력이 부족해 현업에서는 잘 쓰지 않는다.
-
이런 단점이 없는 알고리즘이 선형 모델이다.
