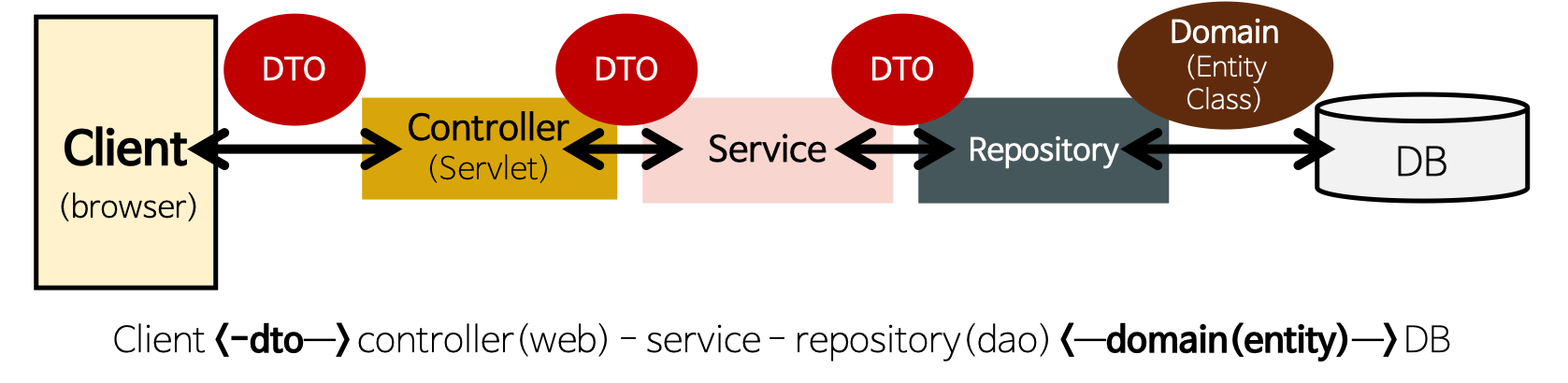
https://velog.io/@seungho1216/Spring-BootController-Service-Repository%EC%97%90-%EB%8C%80%ED%95%98%EC%97%AC
공부하려고 따라적은 것.
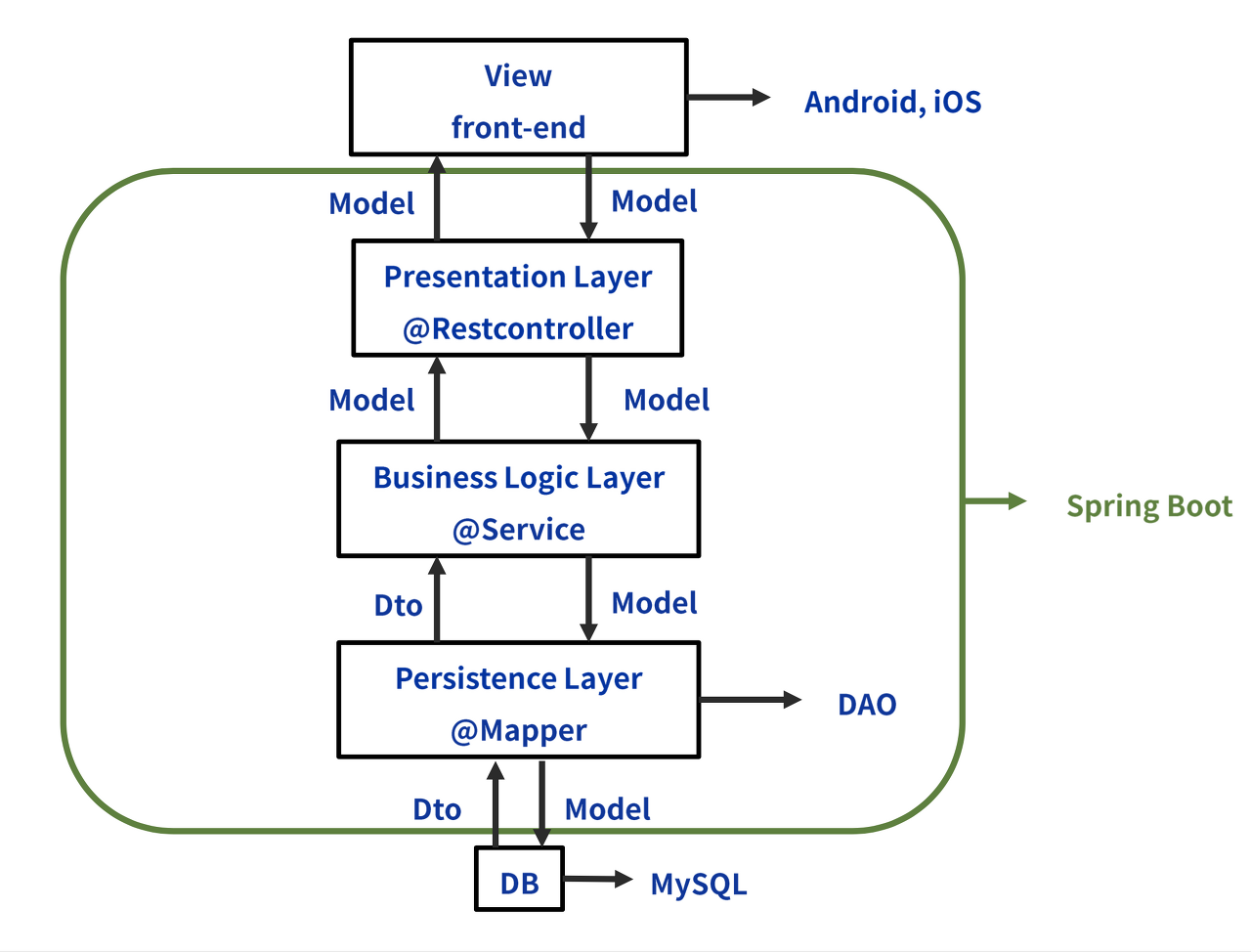
Controller
맨 위쪽에 front-end에서 들어오는 클라이언트 측의 요청이 가장 먼저 서버측과 맞닿는 부분이 controller.
서버에서 기능별 url이라는 api를 개설해 놓았고, 클라이언트는 필요한 정보를 얻기 위해 적절한 API에 요청하는 것.
즉 controller는 이런 창구 역할을 하는 API들을 모아놓은 클래스.
당연히 정보를 프론트 쪽으로 내려줄 때도 이 컨트롤러의 API를 통해서 보내준다.
Repository
Repository는 직역해도 '저장소'로 데이터베이스와 깊은 연관이 있음을 알 수 있다. 데이터단에 직접 매칭되는 Entity라는 것이 있는데, 이 Entity를 통해 데이터테이블이 생성이 되면, 받아온 정보를 데이터베이스(MySQL, mariaDB)에 저장하고 조회하는 기능을 수행함.

위 사진은 일반적인 데이터베이스(MySQL)과 이를 조작하는 SQL문과 매칭되는 개념으로, 스프링부트에서 Domain(Entity)가 table에, Repository가 SQL에 매칭된다. 즉 Repository에서 주어진 jpa인터페이스 메소드를 활용하여 기본적인 CRUD를 할 수 있다.
그러나 클라이언트가 원하는 정보를 주기 위해 단순 데이터조회로는 처리하지 못하는 개념들이 있다. 이때 더 고도화된 정보 가공을 처리하는 곳이 밑에서 설명할 service이다.
Service
service는 repository에서 얻어온 정보를 바탕으로 자바 문법을 이용하여 가공 후 다시 controller에게 정보를 보내는 곳. 어떻게 보면 controller는 클라이언트에, repository는 데이터에 맞닿아서 정보를 주고받는 부분으로 여길 수 있으나 service는 실질적으로 중요한 작동이 많이 일어나는 부분.
그럼 repository에서 정보를 가져오면 바로 가공해서 controller한테 주면 되는데 굳이 service가 필요한가?
결론-클라이언트 즉 controller쪽에서 바로 데이터베이스에 접근하여 정보를 얻고 가공해서 가져가는 것은 위험하다. 정보를 직접 CRUD하고 가공하는 과정에서 테이블에 저장된 원본의 정보가 손상될 우려가 크기 때문. 따라서 정보 변동의 위험이 큰 로직은 service에서 진행하는 것. 추가로 이때도 원본의 데이터를 사용하는 것이 아니라 데이터베이스에서 추출한 정보의 복사본인 DTO를 만들어서 로직을 조작하는 것이다.