Knowledge Distillation(KD; 지식 증류)은 고성능의 Teacher 모델로부터 지식을 전달 받아서 Student 모델을 학습 시키는 기법이다. 이는 파라미터 수가 많고 성능은 좋지만 속도가 느린 teacher 모델을 성능은 보통이지만 파라미터 수가 적고 속도가 빠른 student 모델로 가볍게 만들어 메모리 사용을 줄이고 연산 속도를 높일 수 있는 방법이다.
KD는 크게 knowledge와 transparency의 관점에서 접근할 수 있다.
KD기법의 분류
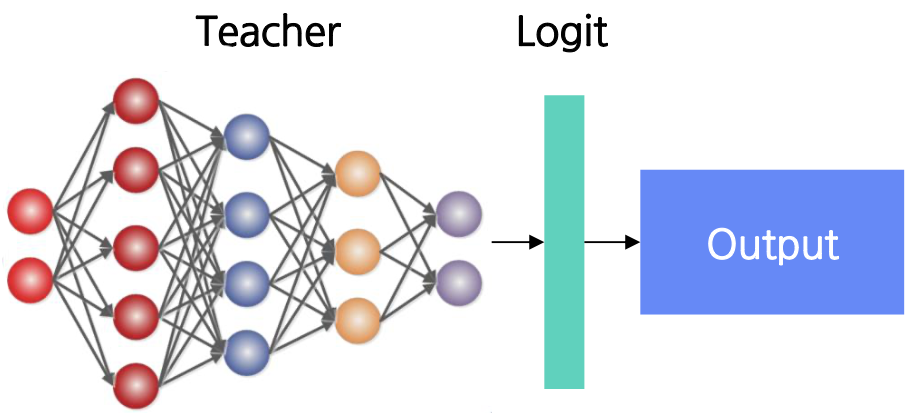
Knowledge
증류할 지식의 종류에 따라 Response-based KD와 Feature-based KD로 구분할 수 있다.
Response-based KD
- Logit-based : teacher 모델의 logit 값을 배우는 것이다.
다시 말하면 teacher 모델 출력의 확률 분포를 배우는 것다. 예를 들어, 분류 모델을 학습할 때, 이미지가 고양이로 분류된다는 output 뿐만 아니라, cat = 0.8, cow = 0.07, dog = 0.13과 같이 클래스 확률값도 같이 학습하는 것이다. student 모델은 자신의 클래스 확률 분포 예측이 teacher 모델의 클래스 확률 분포 예측과 같아지도록 KL divergence를 loss로 활용해 학습한다. 이는 label smoothing의 일종으로, 클래스 간의 유사도 정보도 학습할 수 있고 student 모델의 일반화 성능을 향상시키는 효과가 있다.
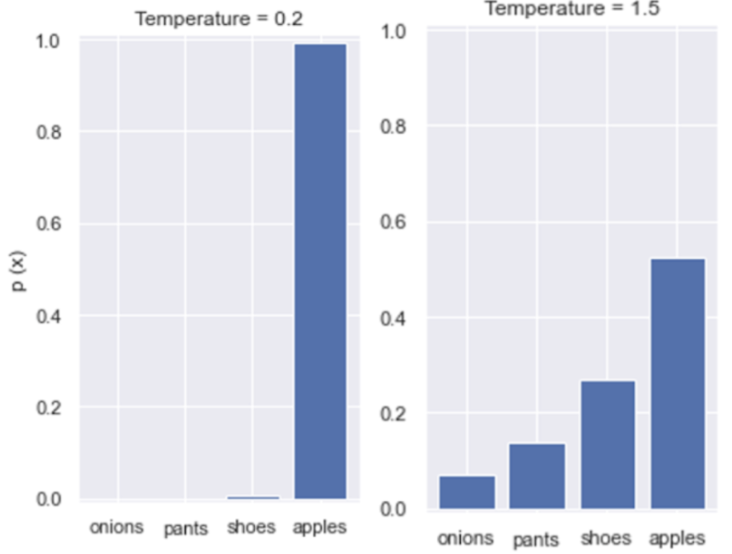
이 때 temperature T를 도입하면 확률 분포를 날카롭게 혹은 완만하게 변형할 수 있다. 확률 분포를 날카롭게 한다는 것은, 확률값이 높은 클래스의 값을 높이고 낮은 클래스의 값을 더 낮춰 contrast를 심화시키는 것이다. 반대로 완만하게 변형한다는 것은, 확률 값이 높은 클래스의 값을 낮추고 낮은 클래스의 값은 높여서 contrast가 적게 모든 분포가 비슷하게 되도록하는 것이다. T < 1이면 확률 분포가 날카롭게, T > 1이면 완만하게 변형된다. 이 값을 적절히 설정하면 지식 증류가 보다 더 효과적으로 이루어진다.
- Output-based : teacher 모델의 output을 배우는 것이다.
Feature-based KD
teacher 모델의 중간 레이어의 feature/representation을 배운다. 그러나 보통 teacher 모델의 중간 레이어 feature map과 student 모델의 중간 레이어 feature map은 차원이 다르기 때문에 student 모델에 regressor layer를 도입하여 차원을 맞추게 된다. 이 때 두 feature map이 유사해지도록 MSE loss를 추가한다.
Transparency
모델 내부 구조/파라미터 열람 가능 여부에 따라 white-box, gray-box, black-box로 구분할 수 있다.
White-box
teacher 모델의 내부 구조, 파라미터 등을 알 수 있는 경우
Gray-box
teacher 모델의 output 및 최종 logit 값 등 제한된 정보만을 알 수 있는 경우
Black-box KD (Imitation Learning)
teacher 모델의 내부(레이어, 파라미터 등), 추론 과정은 알 수 없고 입력에 따른 결과만 접근 가능할 때, student 모델이 입력에 따른 결과 출력 행동을 관찰하고 이를 모방하여 자신의 정책을 학습하는 방법이다. 모델의 출력을 입력 데이터로 학습하기 때문에 teacher 모델이 오류가 있는 예측을 했을 때 그 영향을 받는다는 단점이 있다. 하지만 데이터 수집 비용이 저렴하고, 이 지식이 인간이 해석가능한 형태라는 장점이 있다.
Step 1. 모방 데이터 수집
teacher 모델에게 할 질문(seed 질문)을 설정하고, 더 유의미한 답변을 얻기 위해 prompt engineering을 수행한다. (ex) 반품 정책은 어떻게 되나요? → 반품 절차가 몇 단계로 이루어져 있는지 각 단계별로 자세히 설명해주세요.)
Step 2. 데이터 전처리
의미 없는 대화, 매우 짧거나 불충분한 답변, hallucination 등을 제거하고 특정 유형의 질문-답변이 지나치게 많거나 적지 않도록 균형을 맞춘다.
Step 3. 모델 학습
수집하여 전처리한 데이터를 이용해 student 모델을 학습시킨다.
코드
Logit-based KD
코드 부분 실습 참고해서 다시 작성
# Teacher 모델 정의
class Teacher(nn.Module):
pass
teacher = Teacher(num_classes=10)
print(sum(p.numel() for p in teacher.parameters())) # teacher 모델의 파라미터 수
# Student 모델 정의 (Teacher과 유사하지만 shallow)
class Student(nn.Module):
pass
student = Student(num_classes=10)
print(print(sum(p.numel() for p in teacher.parameters())) # student 모델의 파라미터 수
# teacher 모델 학습 & 테스트
# 분류 문제를 Cross-Entropy Loss로 학습 (hard label -> 0 or 1)
train(teacher, train_data, epochs=10, learning_rate=1e3)
test(teacher, test_data)
# student 모델 학습 & 테스트
# 분류 문제를 Cross-Entropy Loss로 학습 (hard label) + teacher 모델의 확률 값을 KL divergence loss로 학습 (soft label)
train(student, train_data, epochs=10, learning_rate=1e3)
test(student, test_data)Feature-based KD
def 