OCR 모델의 성능은 어떻게 평가할 수 있을까?
이번 포스팅에서는 우선 검출된 글자가 정확한지에 대해서는 생략하고, 검출된 글자 영역이 정확한지 bounding box의 관점에서 평가하는 방법을 알아보겠다.
Area Recall, Area Precision
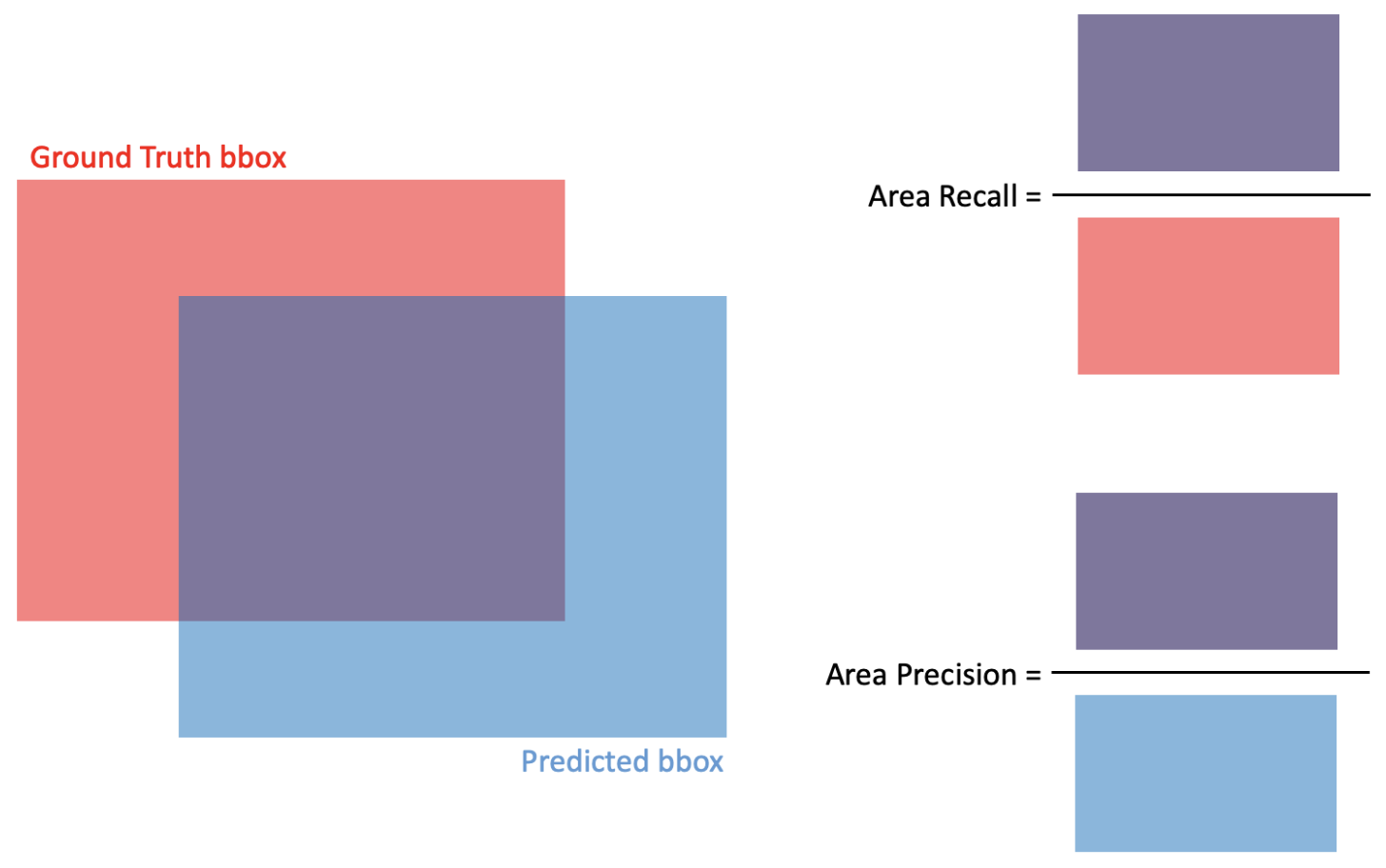
Ground Truth bbox가 있고, 모델을 통해 예측한 predicted bbox가 있을 때, 이 두 bbox의 겹치는 넓이로 성능을 평가할 수 있다.
recall은 Ground Truth의 관점에서 predicted bbox의 넓이를 보는 보는 개념이므로 Area Recall은
으로 계산할 수 있다.
precision은 prediction의 관점에서 실제로도 참일 확률을 보는 것이므로 Area Precision은
으로 계산할 수 있다.
Area Precision과 Area Recall의 개념은 혼동하기 쉬운데, 정리해보면 아래 표와 같다.
| 구분 | Area Precision | Area Recall |
|---|---|---|
| 기준 | Predicted bbox | Ground Truth bbox |
| 평가하는 질문 | predicted bbox가 얼마나 정확한가? | 실제 객체를 얼마나 놓치지 않고 포함했는가? |
| 의미 | 예측한 영역 중 실제 객체와 일치하는 부분의 비율 | 실제 객체 영역 중 예측된 bbox에 포함된 부분의 비율 |
| 초점 | 예측의 정확성 (불필요한 예측 감소) | 예측의 포괄성 (누락되는 예측 감소) |
Match

ground truth bbox와 predicted bbox가 어떻게 매치되고 있는지도 중요하다. One-to-One match의 경우, ground truth bbox와 predicted bbox가 1:1로 잘 매치된 모습을 볼 수 있다. One-to-Many match는 ground truth bbox는 하나이나 predicted bbox가 쪼개져서 여러 개인 경우이다. Many-to-One match는 ground Truth bbox는 여러 개인데 예측에서 하나로 예측한 것을 의미한다.
DetEval
하나의 이미지에 여러 텍스트가 존재하다면 OCR 태스크를 했을 때 ground truth bbox와 predicted bbox가 여러 개 생기게 될 것이다. 이들을 모두 고려해서 OCR이 얼마나 잘 되었는지 평가하는 metric이 DetEval이다.
1) 각 ground truth bbox와 predicted bbox를 매칭하여 각 쌍의 area recall, area precision을 계산한다.
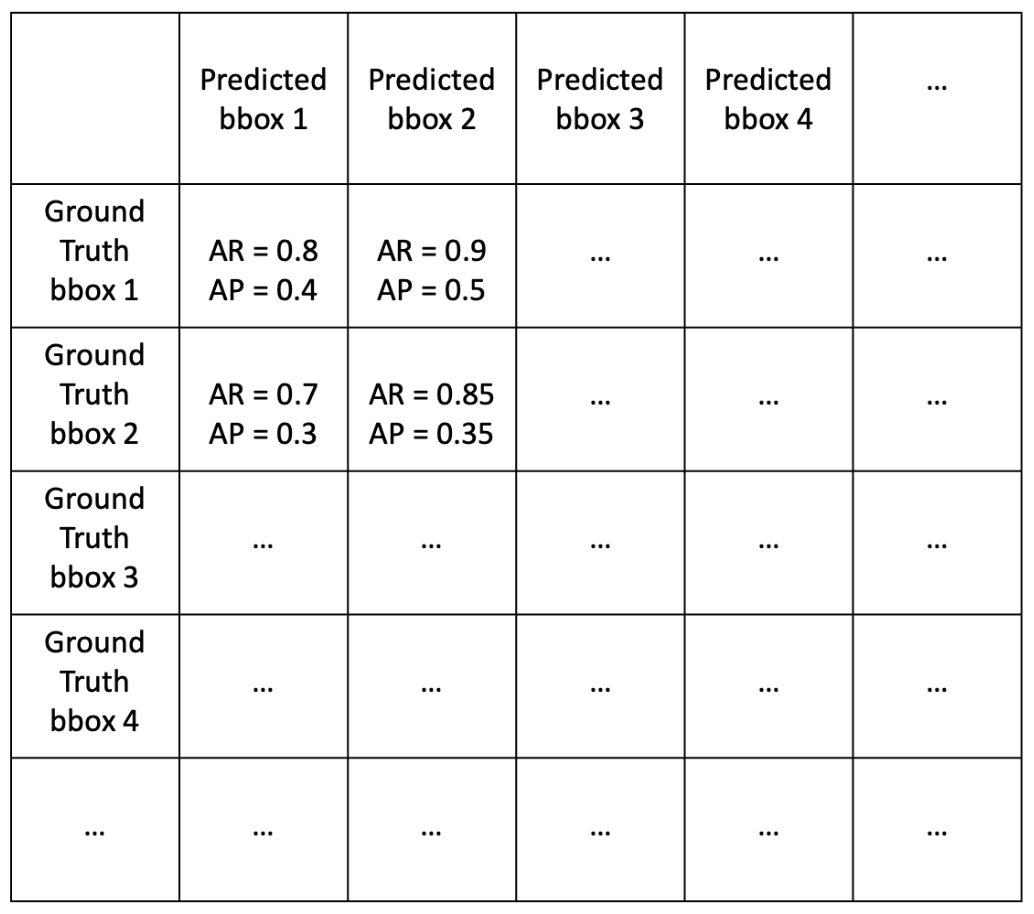
2) 각 케이스에서 Area Recall 0.8 and Area Precision 0.4 이면 1, 그렇지 않으면 0으로 값을 매긴다. (→ binary)
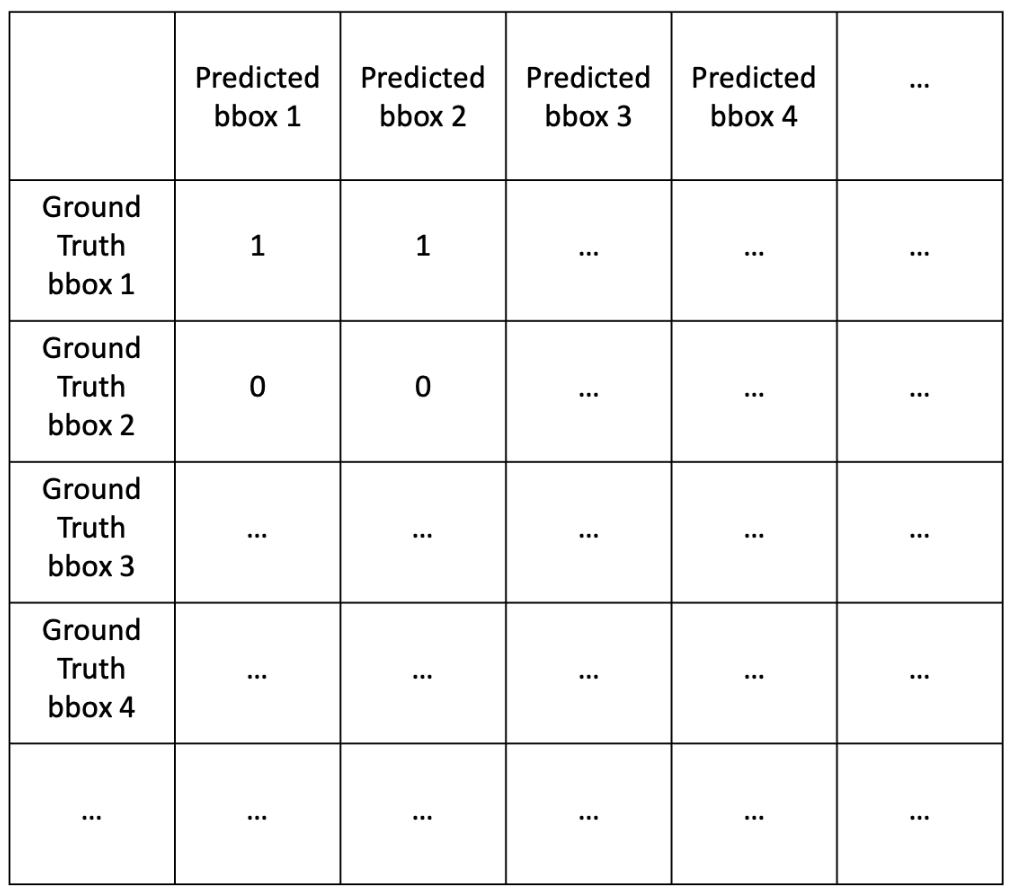
3) 그러나 Match 항목에서 봤듯이, 하나의 텍스트에 대해서 ground truth bbox와 predicted bbox가 1:1로 잘 매칭되었을 수도 있지만 predicted bbox가 여러 개로 쪼개졌거나, 여러 개의 단어를 합쳐 하나의 predicted bbox가 생겼을 수 있다. 이 때 Many-to-One match의 경우에는 별도의 페널티 없이 그대로 1을 곱해주고, 텍스트가 쪼개져 예측되는 One-to-Many match의 경우에는 0.8을 곱하여 페널티를 준다.
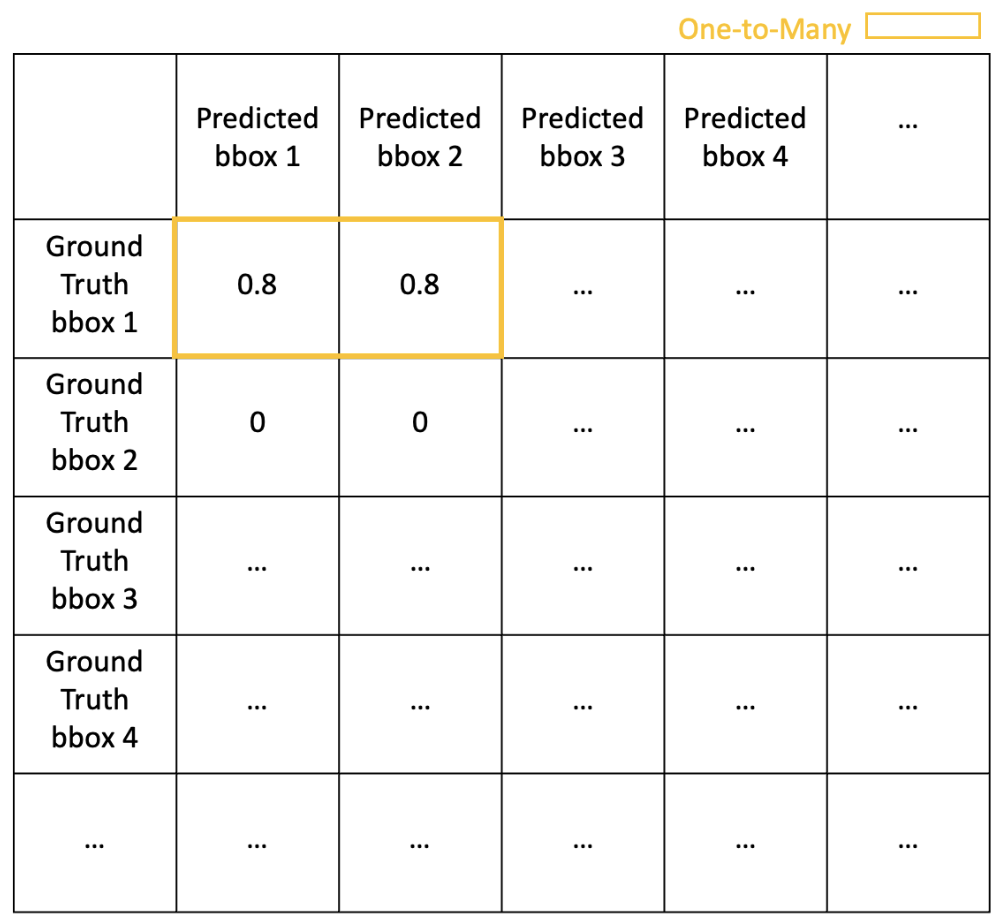
4) 이렇게 계산된 값들을 평균낸다. Ground Truth 기준으로 평균 값을 내면 Recall이 되고, Precision 기준으로 평균 값을 내면 Precision이 된다. 이를 활용해 F1 score를 계산하면 최종적으로 하나의 이미지에 대해 OCR이 얼마나 잘 되었는지 (bbox의 관점에서) 평가할 수 있다.
IoU
TIoU
IoU가 ground truth bbox와 predicted bbox를 합친 영역과 겹친 영역의 비율만 따지는 개념이라면, TIoU (Tightness-aware IoU)는 ground truth bbox에 비해 predicted box가 부족하거나 초과된 영역 크기에 비례하여 IoU 점수에 페널티를 부여하는 것이다.
TIoU는 predicted bbox가 ground truth bbox보다 작을 경우 (부족할 경우)와 predicted bbox가 ground truth bbox보다 클 경우 (초과된 경우)에 다르게 계산하는데, 전자를 , 후자를로 부른다.
최종 TIoU는 과 의 조화 평균으로 계산된다.
다만 TIoU는 ground truth가 golden answer이라는 가정이 필요하고, 단순히 넓이로 페널티를 주기 때문에 넓이는 충분한데 일부 글자를 누락한 경우를 놓칠수 있다는 맹점이 있다.
CLEval
CLEval (Character-Level Evaluation)은 얼마나 많은 글자를 맞추고 틀렸는지를 평가하는 것이다. 따라서 detection 뿐만 아니라 recognition에 대해서도 평가할 수 있다.
우선 이미지에서 텍스트의 위치 정보를 뽑아낸 후에 이를 기반으로 개별 글자의 중심인 Pseudo Character Centers (PCC)를 계산한다.
그리고 DetEval 때처럼 predicted bbox와 ground truth bbox를 매칭한 것에 대해서 Recall과 Precision을 계산한다.
- : ground truth bbox 내의 PCC 중 predicted bbox에 속하게 된 PCC의 개수
- : ground truth bbbox 내의 PCC를 포함하는 predicted bbox의 개수 - 1
- : ground truth bbox 내의 PCC 개수
Precision도 같은 식으로 계산하지만, predicted bbox를 기준으로 보므로 각 요소의 계산 방법이 약간씩 다르다.
- : predicted bbox 내의 PCC의 개수를 세되, PCC가 여러 predicted bbox에 속해있다면 그 predicted bbox의 개수로 나누어서 센다.
ex) PCC 하나가 2개의 predicted bbox에 속해있다면 +1/2 - : predicted bbox와 매칭된 ground truth bbox의 개수 - 1 (매칭되는 기준 : ground truth의 PCC를 predicted bbox도 포함하고 있을 경우)
- : predicted bbox가 포함하고 있는 PCC의 개수
위와 같이 Recall과 Precision을 계산해서, 조화 평균을 구하면 CLEval 값을 구할 수 있다.
예시
아래 3개의 케이스에 대해서 DetEval, IoU, TIoU, CLEval을 계산해보자.

(1) 정답
| Metric | Score |
|---|---|
| DetEval | 1.0 |
| IoU | 1.0 |
| TIoU | 0.9 |
| CLEval | 8/9 |
(2) 정답
| Metric | Score |
|---|---|
| DetEval | 0.8 |
| IoU | 0.0 |
| TIoU | - |
| CLEval | 0.9 |
(3) 정답
| Metric | Score |
|---|---|
| DetEval | 1.0 |
| IoU | 0.0 |
| TIoU | - |
| CLEval | 0.93 |
