
시작하는 말
오늘은 알고리즘 문제 풀이에 있어 평가 척도가 되는 시간/공간 복잡도에 대해 이야기해보려 한다.
사실 서순이 맞으려면 시공간 복잡도에 대해서 먼저 이해하고 그 뒤에 자료구조나 알고리즘에 접근해야하지만, 내가 공부한 서순은 뒤죽박죽이었기 때문에 뒤늦게 정리하고자 한 것이다.
또한 이번 학기에 자료구조 수업을 수강하고 있는데, 강의 1~2주차에 이 글에서 다루려는 내용이 나왔었기 때문에 더욱이 정리의 필요성을 느껴 따로 글을 적게 된 것이다.
알고리즘 문제풀이를 접한지 6개월 정도 된 것 같은데, 그동안 시공간 복잡도에 대해 이해를 시도한 적이 없었던 건 아니다. 구글에 여러 번 검색하기도 했고, 알고리즘 책에 서술돼있는 내용도 읽었지만 뭔가 와닿지 않았다. 빅오, 빅세타, 빅오메가가 뭔지 그리고 로그 함수는 왜 나오는 것이며 코드를 보고 어떻게 시간 복잡도를 계산하는지 전혀 감을 잡지 못했다.
그러다가 요새 코드트리로 알고리즘 스터디를 진행하고 있는데, 코드트리에서도 자료구조에 대한 코스가 있어 수강했다가 덕분에 드디어 깨달음을 얻게되어 정리할 수 있게 된 것이다.
시간 복잡도란?
본론으로 들어가서 시간 복잡도란 대체 무엇인지 짚고 넘어가야겠다. 시간복잡도는
코드의 효율성을 연산 횟수를 기준으로 평가하는 척도
라고 정리할 수 있다. 가령 아래와 같은 코드 한 줄이 있다면
set a = 10우리는 쉽게 이 코드가 값을 변수에 대입하는 코드임을 알 수 있고 굉장히 가벼울 것이라 예측할 수 있다.
그러나 아래와 같이
function solution1(n)
set sum = 0
for i = 1 ... i <= n
for j = 1 ... j <= i
sum += i * jfor문을 이중으로 도는 코드가 있다면, set a = 10 코드와 비교했을 때 훨씬 시간이 오래 걸리는 연산임은 확신할 수 있을 것이다.
이러한 코드마다의 연산 횟수를 측정하여 나타내는 것이 시간 복잡도이며, 시간 복잡도를 계산하기 위해 연산 횟수를 일일이 카운팅하는 바보같은 짓을 하는 대신에 '점근적 표기법'이라는 수학적 개념을 이용해 '대략적'으로 해당 알고리즘의 시간 복잡도를 근사치로 표현하는 것이다.
점근적 표기법
앞서 말한 시간 복잡도를 나타내기 위한 수단으로서의 점근적 표기법에는 크게 3가지 표기법이 존재하는데 바로 O(빅오), Ω(빅오메가), Θ(빅세타)가 그것이다.
이것들에 대한 설명은 다른 블로그들에 너무나도 자세히 설명돼있기 때문에 여기서는 간단하게 짚고 넘어가겠다.
간단한 다항식 이라는 식이 있다고 가정한다면,
- O(빅오)는 다항식에서 가장 높은 차수와 같거나 그보다 높은 식을 뜻하고(),
- Ω(빅오메가)는 다항식에서 가장 높은 차수와 같거나 그보다 낮은 식을 뜻하고()
- Θ(빅세타)는 다항식에서 가장 높은 차수와 같은 식을 뜻한다().
이 세가지 표기법 중에 O(빅오)를 사용하는 이유만 알고 있으면 되는데, 그 이유는 아래와 같다.
만약 시간복잡도 측정 과정에서 Θ(빅세타)를 사용한다면 매우 정확하겠지만, 현실적으로 특정 코드의 시간복잡도를 완벽하게 알기 힘든 경우도 있으므로, 사용을 피하는 편입니다.
또한, Ω(빅오메가)를 사용하게 된다면 오래 걸리는 코드의 시간복잡도를 너무 낮게 표현할 수 있는 위험이 있으므로 사용하지 않습니다.
한 줄 요약하자면, 제일 최악의 경우를 가정했을 때마저 문제에서 주어진 조건을 통과한다면 그 아래는 볼 필요도 없어지기 때문에 O(빅오)를 사용하는 것이다.
문돌이에게 생소한 로그함수
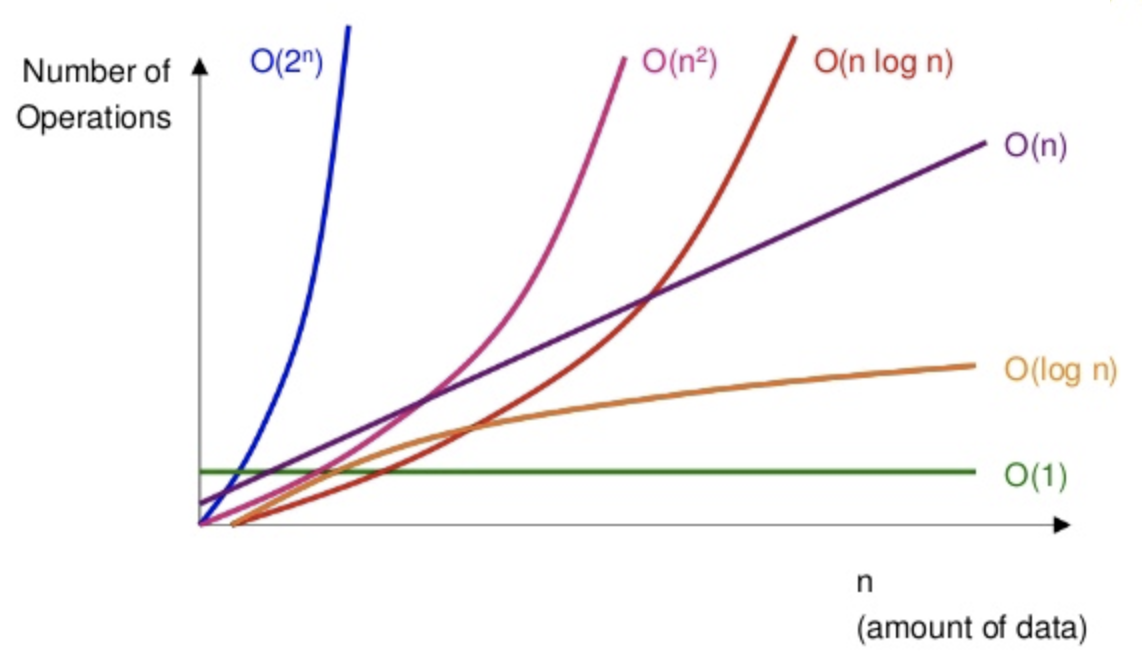
O(빅오) 표기법에서 우리가 흔히 볼 수 있는 케이스는 위 사진에 모두 나와있다. 이며, 이 중에서 문돌이 관점에서 생소한 로그함수만 짚고 넘어가도록 하겠다.
function solution2(n)
for i = 0 ... i < n
set j = 1
while j < i
j *= 2
위 코드는 for문 안에 while문이 들어가 있는 형태인데, i가 2배씩 늘어날 때마다 while문이 반복되므로 이 되는 k가 존재할 때 i가 n-1일 경우 j가 k번 반복되면 함수가 종료될 것이다.
따라서 while문의 연산 횟수 k를 구하려면 양변에 를 취해준다.
이때 k는 연산 횟수기 때문에 시간 복잡도로 나타낼 수 있다. 보통 로그 아래첨자 2는 생략하기 때문에 while문의 시간복잡도 T(n)은 다음과 같이 표현할 수 있다.
while문의 시간 복잡도를 구했다면, 그 바깥에 있는 for문의 시간 복잡도를 구하여 곱해준다. while문을 n번 반복하고 있기 때문에 for문의 시간 복잡도는 이고, 최종 시간 복잡도는 이 되는 것이다.
공간 복잡도
시간 복잡도를 알아봤으니 공간 복잡도도 알아보자. 우선 공간 복잡도는 시간 복잡도가 '코드의 효율성을 연산 횟수를 기준으로 평가하는 척도'였듯이 동일하게 코드의 효율성을 평가하는 또다른 척도다.
다만 프로그램을 실행시켰을 때 소요시간 뿐만 아니라 프로그램이 사용하는 메모리의 양도 퍼포먼스에 영향을 미친다. 가능한 한 적은 메모리를 사용하는 것이 효율적이기 때문에 '이 코드가 메모리를 얼마나 차지하고 있는지' 측정하는 것도 필요한 것이다. 물론 예전에 비해 기술의 발전으로 메모리 공간이 넉넉해지면서 시간 복잡도에 비해 공간 복잡도의 우선순위는 낮긴 하다
공간 복잡도의 계산은 보통 C++을 기준으로 생각한다고 한다. C++ 에서는 int가 4 byte, char이 1 byte, double이 8 byte, short가 2 byte로 정해져있다.
따라서 이 부분만 알고 있으면, int로 2천만이 대략 80MB라는 것을 이용하여 다음과 같이 쉽게 계산이 가능하다.
int a[2천만] : 80MB
int a[2백만] : 80 / 10 = 8MB
char a[2천만] : 80 / 4 = 20MB
double a[2천만] : 80 * 2 = 160MB따라서 사용하는 배열의 크기에 따라 대략 어느 정도의 메모리를 사용하는지를 미리 계산할 수 있어 메모리 제한을 넘지 않는 코드인지를 확인해볼 수 있다.
만약 정수가 담긴 10000 * 10000 크기의 배열을 만들면 메모리를 1GB 이하로 사용할 수 있는가? 라고 묻는다면, int 자료형 2천만개의 크기가 80MB이므로 10000 * 10000 = 1억개의 int 자료형 배열의 크기는 대략 400MB이므로 1024MB(=1GB) 이하로 사용 가능하다 답할 수 있다.
마치며..
시간 / 공간 복잡도를 알아보며 좀 더 자료구조 / 알고리즘에 가까워진 듯한 느낌이 든다. 이 주제 말고도 연결 리스트, 스택과 큐에 관해서도 공부를 해야하므로 조만간 또 찾아올 예정. 화이팅이다~~
출처
- 코드트리 자료구조 / 알고리즘 - 시간, 공간 복잡도
- 벨로그 차수연님 - [Algorithm] 시간 복잡도, 공간 복잡도
- 티스토리 Yoongrammer님 - 시간 복잡도(Time Complexity) 및 공간 복잡도(Space Complexity)
