
1. Introduction
기존의 음성 인식 연구
- 음성 인식 분야의 발전은 Wav2Vec2.0(Baevski et al., 2020)에서 제시된 unsupervised pre-training techniques의 발전에 힘입어 활성화 되었음
- 인간의 레이블이 필요 없이 원시 오디오로 직접 학습할 수 있기 때문에, 레이블이 없는 대규모 데이터 세트를 생산적으로 사용할 수 있음
- 이렇게 사전학습된 모델로 표준 벤치마크에서 미세 조정을 하면 적은 데이터로도 현재 최고수준의 성능을 이끌어 냈음
- 그러나, 출력 표현을 매핑하는 디코더가 없이 단순히 unsupervised pre-training 된 모델이라 실제로 음성 인식 작업을 수행하려면 복잡한 과정의 fine tuning이 필요함
- 또 이 fine tuning 과정은 특정 훈련 데이터셋 내에서의 패턴을 아주 능숙하게 찾지만, 학습 되지 않은 다른 데이터셋에는 일반화 되지 않음
Whisper
음성 인식 시스템의 목표는 모든 분포의 오디오에 대한 디코더의 fine tuning 없이도 광범위한 환경에서 신뢰성 있게 바로 사용할 수 있어야 함
- Narayanan et al. (2018), Likhomanenko et al. (2020), Chan et al. (2021) 에 의해 보여진 바와 같이, 레이블이 없는 음성 데이터에 비하면 여전히 작지만 레이블이 있는 데이터에 대해 더 많은 데이터셋을 사용하여 supervised learning을 했더니 좋은 성능을 냈음
- Mahajan et al. (2018), Kolesnikov et al. (2020) 에 따르면 아직 음성 인식에 대해서는 충분한 연구가 이루어 지지 않았지만 컴퓨터비전 연구에서 대량의 weakly supervised 데이터셋을 사용하니 모델의 견고성과 일반화가 크게 향상된다는것이 입증됨
- 이에 따라 whisper에서는 weakly supervised dataset 를 활용하여 680,000 시간의 레이블이 있는 오디오 데이터를 활용함
- 또 다국어 및 다중 작업이 가능하도록 680,000시간의 오디오 중 117,000시간은 다른 96개 언어 음성을, 125,000시간은 이 다른 언어 음성을 영어로 번역한 데이터까지 포함됨
2. Approach
2-1. Data Processing
- 데이터 표준화 없이 원시 오디오, 원시 텍스트를 예측하도록 훈련함(데이터에 전처리를 거의 하지않음)
- 발화와 그 텍스트 형태 간의 매핑을 학습하기 위해 seq-to-seq 모델의 표현력에 의존함
- 정규화 단계를 제거함으로써 음성 인식 파이프라인을 단순화시켜 자연스러운 텍스트를 생성할 필요가 없게 함
- 이러한 오디오 품질의 다양성은 모델을 견고하게 훈련시킬 수 있음
- 그러나 텍스트 품질의 다양성은 모델 학습에 오히려 안좋은 효과를 낼 수 있음
- 훈련 데이터셋에서 machine-generated data를 감지하고 제거함
- 인터넷상에서 뽑은 데이터셋의 텍스트라벨은 실제로 인간이 생성한게 아닌 기존 ASR 시스템을 통해 출력된 결과인것들이 많음
- 최근 연구에 따르면 mixed human and machine-generated data는 모델 학습시 성능을 크게 저하시킬 수 있음
- 느낌표, 쉼표, 물음표와 같은 구두점, 공백 또는 대문자 사용과 같이 오디오 신호만으로 예측하기 어려운 텍스트라벨을 제거하거나 정규화
- 모두 대문자나 모두 소문자로만 이루어진 텍스트는 제외
- 오디오 언어 감지모델을 사용하여 오디오와 텍스트라벨의 언어가 다르면 제외
- 초기모델을 훈련하여 훈련 데이터셋에 대한 오류율을 집계하고 높은 오류율과 segment 길이의 조합으로 정렬하여 수동 검사를 수행해 낮은 품질의 데이터를 제거
2.2. Model
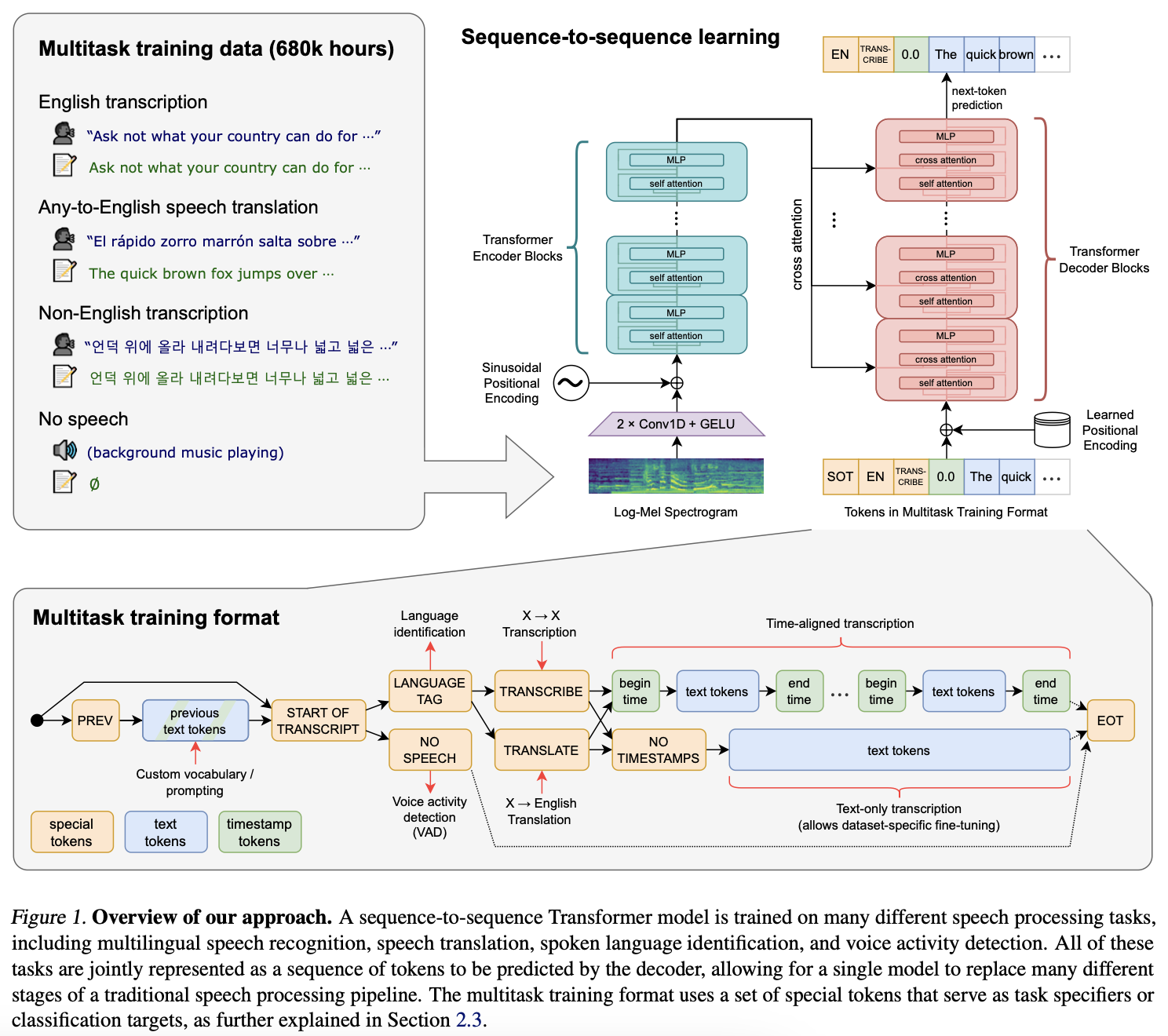
whisper의 모델은 인코더-디코더 Transformer(Vaswani et al., 2017)을 그대로 사용했음
- 모든 오디오는 16,000Hz로 리샘플링 되며, 25밀리초 윈도우에 대해 10밀리초의 스트라이드로 80개의 log mel spectrogram로 계산되어 짐
- 특성 정규화를 위해 평균이 0인 -1~1 사이로 입력을 전역적으로 스케일링함
- 인코더는 필터 폭 3을 가지는 2개의 컨볼루션 레이어로 이루어지고 두번째 컨볼루션 레이어는 2배의 스트라이드를 가짐
- 그리고 Sinusoidal Positional Embedding이 컨볼루션 레이어의 출력에 더해지고 인코더 트랜스포머 블록에 입력됨
- 디코더는 Learned Positional Embedding와 tied input-output token representations(Press & Wolf, 2017)을 사용함
- 인코더와 디코더는 동일한 폭과 트랜스포머 블록 수를 가짐
2.3. Multitask Format
해당 오디오 프레임에 어떤 단어가 발화되었는지 예측하는 것은 음성 인식 문제의 핵심 부분임
그러나 완전한 기능을 갖춘 음성 인식 시스템에는 voice activity detection, speaker diarization, inverse text normalization와 같은 많은 추가 Task가 포함될 수 있음
- 이를 위해 whisper에서는 specify all task, conditioning information을 디코더의 sequence of input tokens로 함께 제공함
- 즉 디코더 훈련을 위해 활용되는 input token은 “text tokens”, “timestamp tokens” 뿐만 아닌 “special tokens” 또한 추가됨
- 이 “special tokens”에는 예측의 시작을 알리는 토큰인 <|startoftranscript|>
- 오디오 segment에 음성이 없는 경우 이를 예측하도록 훈련되는 <|nospeech|>
- 전사 혹은 번역 Task를 지정하는 <|transcribe|>, <|translate|>
- 타임스탬프를 예측할지에 대한 여부를 나타내는 <|notimestamps|>
- 마지막으로 마지막을 알리는 토큰 <|endoftranscript|> 으로 이루어져있음
3. Experiments
3.1. Zero-shot Evaluation
whisper의 목표인 다양한 도메인, Task, 언어에 대한 일반화를 위해 표준 프로토콜 즉 train-test set을 분할하고 모델을 평가할때는 훈련 데이터를 전혀 사용하지 않고 zero-shot 설정에서 평가하여 광범위한 일반화를 측정함
3.2. Evaluation Metrics
정확한 성능 비교를 위해 WER(Word Error Rate)를 사용함
3.3. English Speech Recognition
이미 음성 인식에서의 다양한 연구들은 LibriSpeech Clean Test 에서 사람의 인식 오류율 5.8%보다 훨씬 낮은(좋은 성능) 을 보였음
그러나 이게 과연 인간의 음성 인식 능력을 뛰어 넘었다고 할 수 있는건지에 대한 의문을 가짐
인간은 특정 데이터 분포를 벗어난 즉 unsupervised task를 수행하도록 요청받음
따라서 인간은 out-of-distribution generalization 성능이고, machine은 in-distribution generalization 성능임
따라서 넓고 다양한 오디오 분포에서 훈련되고 zero-shot 설정에서 평가되는 whisper 모델은 기존 음성 인식 시스템들 보다 인간과 더 잘 일치할 수 있음
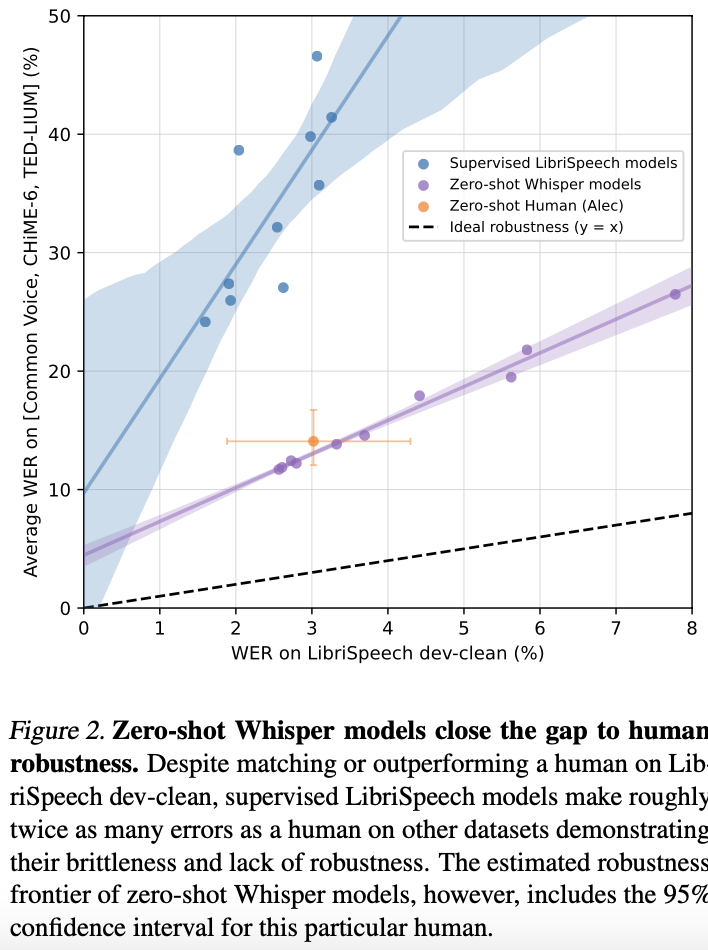
whisper의 일반화된 음성인식 성능을 비교&측정을 위해 Libri speech dataset dev-clean 데이터에 대한 WER를 x축으로, 또 다른 데이터셋에 대한 WER를 y축으로 두어 도식화 하였음
파란색 영역이 기존의 LibriSpeech 기반의 학습 모델들, 보라색 영역이 whisper 모델, 노란색 영역이 사람의 인식능력, 검정색 점선이 이상적인 일반화된 모델을 나타냄
보라색 영역(whisper)이 사람의 인식능력과 비슷한 양상을 보이고 있고, 파란색 영역은 LibriSpeech에 대한 성능은 좋으나 다른 데이터셋에 대한 성능은 떨어지는 것을 볼 수 있음
3.4. Multi-lingual Speech Recognition
다양한 언어의 음성 인식에 대한 이전 연구들과 비교하기 위해 다국어 벤치마크인 MLS, VoxPopuli 이 두가지에 대한 결과를 확인함
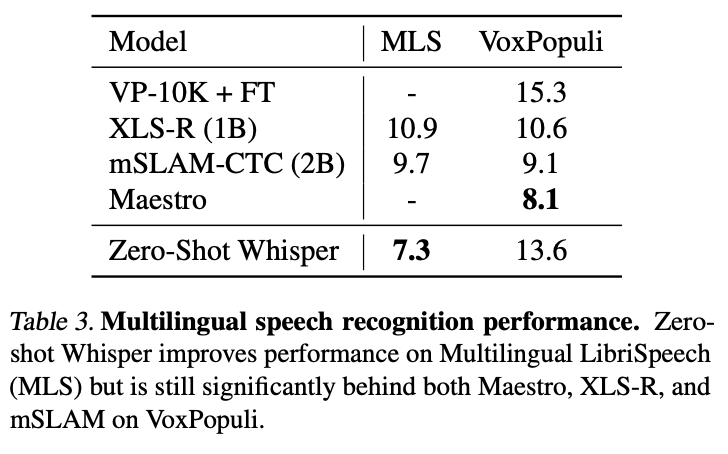
MLS에 대한 성능은 이전 연구들보다 훨씬 좋은 성능을 내었지만, VoxPopuli에서는 저조한 성능을 보였음
연구자들은 이런 결과의 원인이 다른 연구의 모델들이 해당 데이터셋 분포를 unsupervised learning dataset으로 포함하고 있을 것이라 판단함
또 이 두 벤치마크는 다소 좁은 다국어 영역을 다루어서 75개 언어에 대한 음성 인식 훈련 데이터를 포함하는 whisper 모델의 다국어 능력을 연구하는데에 제한이 있음
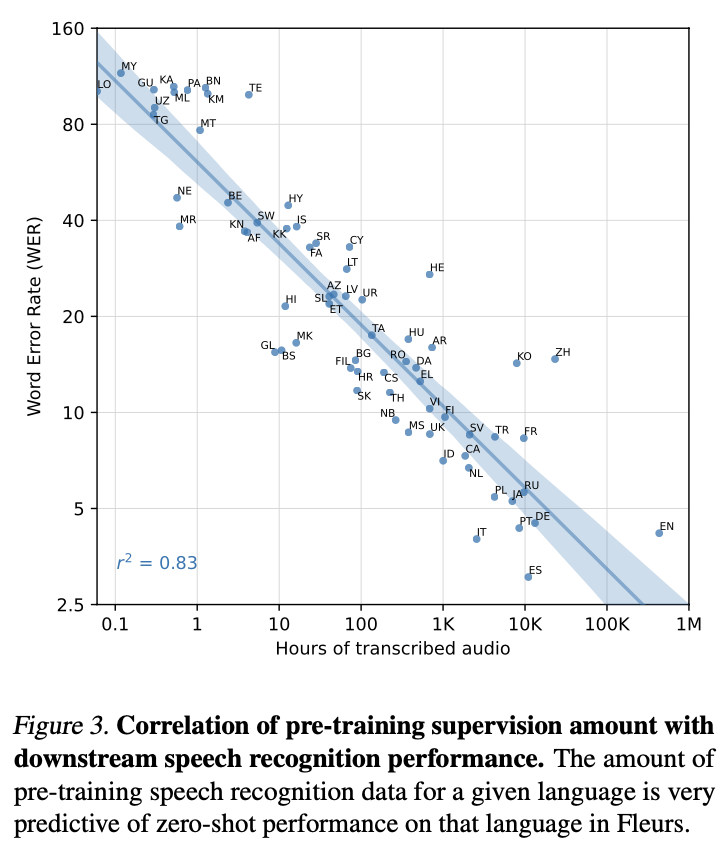
whisper의 성능을 더 넓게 연구하기 위해 주어진 언어에 대한 훈련 데이터 양과 그 언어의 zero-shot 성능 간의 관계를 연구한 결과를 시각화 함
각 언어의 훈련 데이터 양의 로그와 WER의 로그 사이에 0.83의 강한 상관 계수를 발견함
이는 훈련 데이터가 16배 증가할 때마다 WER이 반으로 줄어드는 것으로 추정됨
3.5. Translation
whisper 모델의 번역 능력을 비교하기 위해 CoVoST2의 영어 번역 부분을 측정하였음
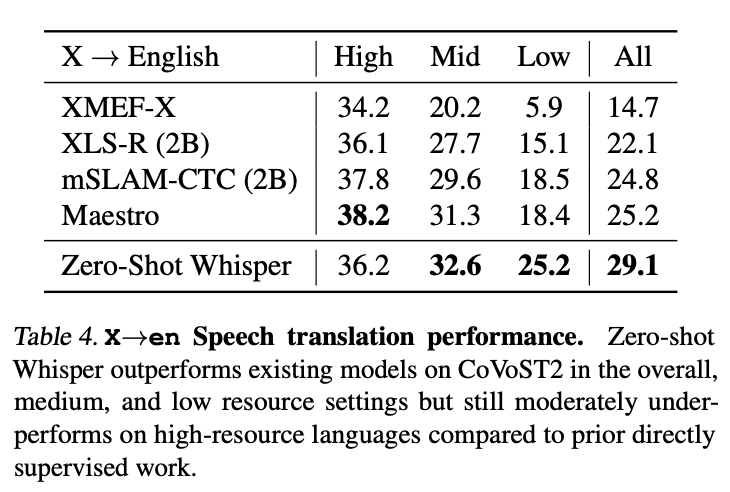
whisper는 CoVoST2 훈련 데이터를 전혀 사용하지 않고 29.1 BLEU의 최고기록을 zero-shot으로 달성함
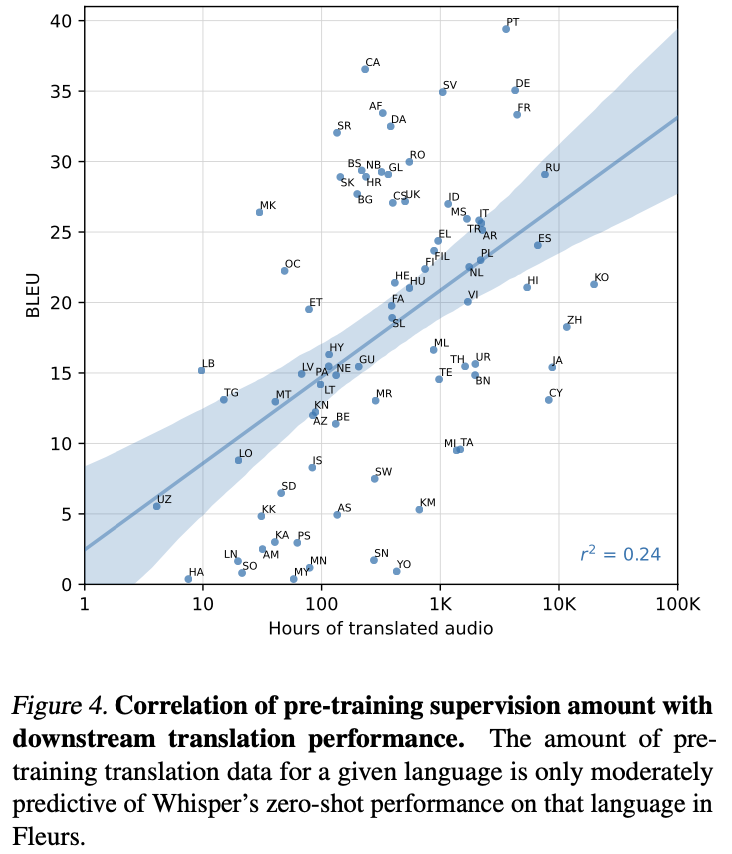
더 넓은 범위의 언어에 대한 추가 분석을 위해 Fleurs를 번역 데이터 세트로 사용하여 Fleurs의 언어별 번역 훈련 데이터 양과 zero-shot BLEU 결과 사이의 상관관계를 시각화함
훈련 데이터가 증가함에 따라 개선의 추세가 있음에도 불구하고 0.24라는 낮은 상관관계를 보임
이는 잡음이 많은 훈련 데이터에 의해 발생한다고 의심됨
이 후에도 다양한 Task에 대한 측정과 연구 결과가 있으나 다음 포스트로 넘기겠습니다~~
