REST API
REST의 탄생 배경
1991년 WEB이 탄생한 후 인터넷에서 정보들을 하이퍼텍스트로 연결하여 공유하기로 함( 표현형식 HTML,식별자 URI,전송방법 HTTP )
그로부터 몇년 후(1994년) Roy T.Fielding은 HTTP/1.0의 명세에 참여하게됨.
그동안 이미 HTTP가 World Wide Web의 전송 프로토콜로 사용되고 있으며 급속도로 성장하는 중이었음. 그 상황에서 HTTP를 정립하고 기능을 더하고 기존의 기능을 고쳐야 하는 상황
=> 호환성 문제를 어떻게 피할 것인가?(How do I improve HTTP without breaking the Web?)
이 문제의 해결책으로 HTTP Object Model이 나왔고 이것이 나중에 REST라는 이름으로 발표됨
어떻게 호환성 문제를 해결하였는가?
Uniform Interface를 구현해냄으로써 서버와 클라이언트가 각각 독립적으로 진화할 수 있게 되었음. 이는 서버의 기능이 변경 되었을 때 클라이언트까지 업데이트 하지 않아도 되는 것을 가능하게 함
[참고]: 그런 REST API로 괜찮은가
이미지 업로드 어떻게 하는지?
django를 이용한 이미지 업로드
When you use a FileField or ImageField, Django provides a set of APIs you can use to deal with that file.
Django는 FileField와 ImageField를 통해 이미지를 다룰 수 있는 API들을 제공하고 있다.
model을 선언할때 image를 사용할 필드에 ImageField를 지정해준 후 settings.py에서 MEDIA_ROOT, MEDIA_URL를 설정한다.
MEDIA_URL은 파일에 대한 URL Prefix를 지정하여 이미지가 저장되는 서버상의 경로를 지정하며, MEDIA_ROOT은 로컬에서 저장되는 이미지 경로이다.
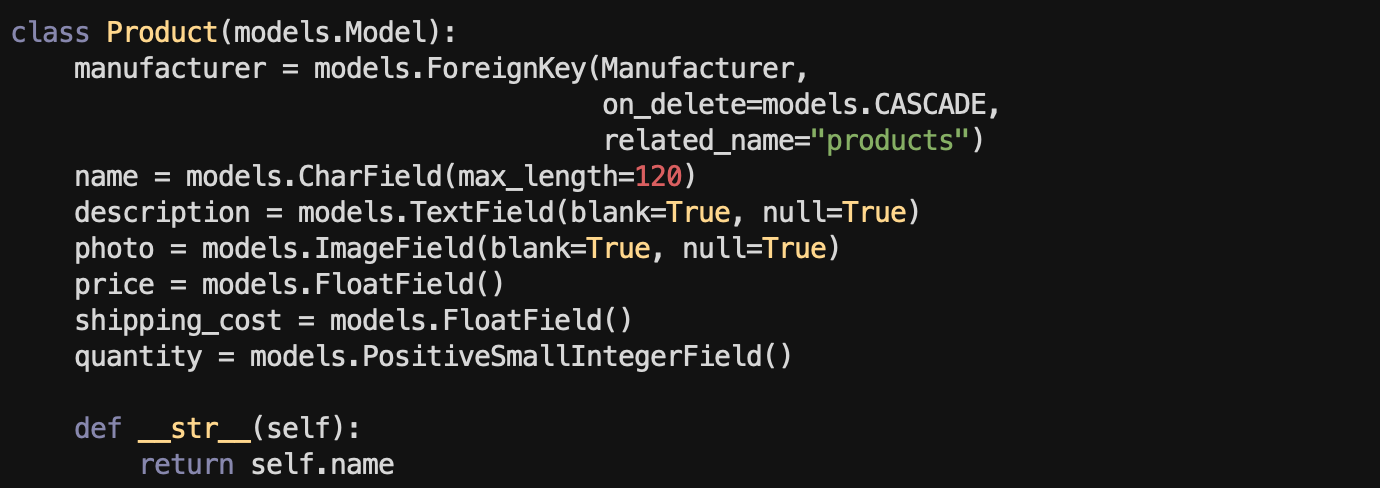

프론트 구현은 admin에게 맡겨버리자....
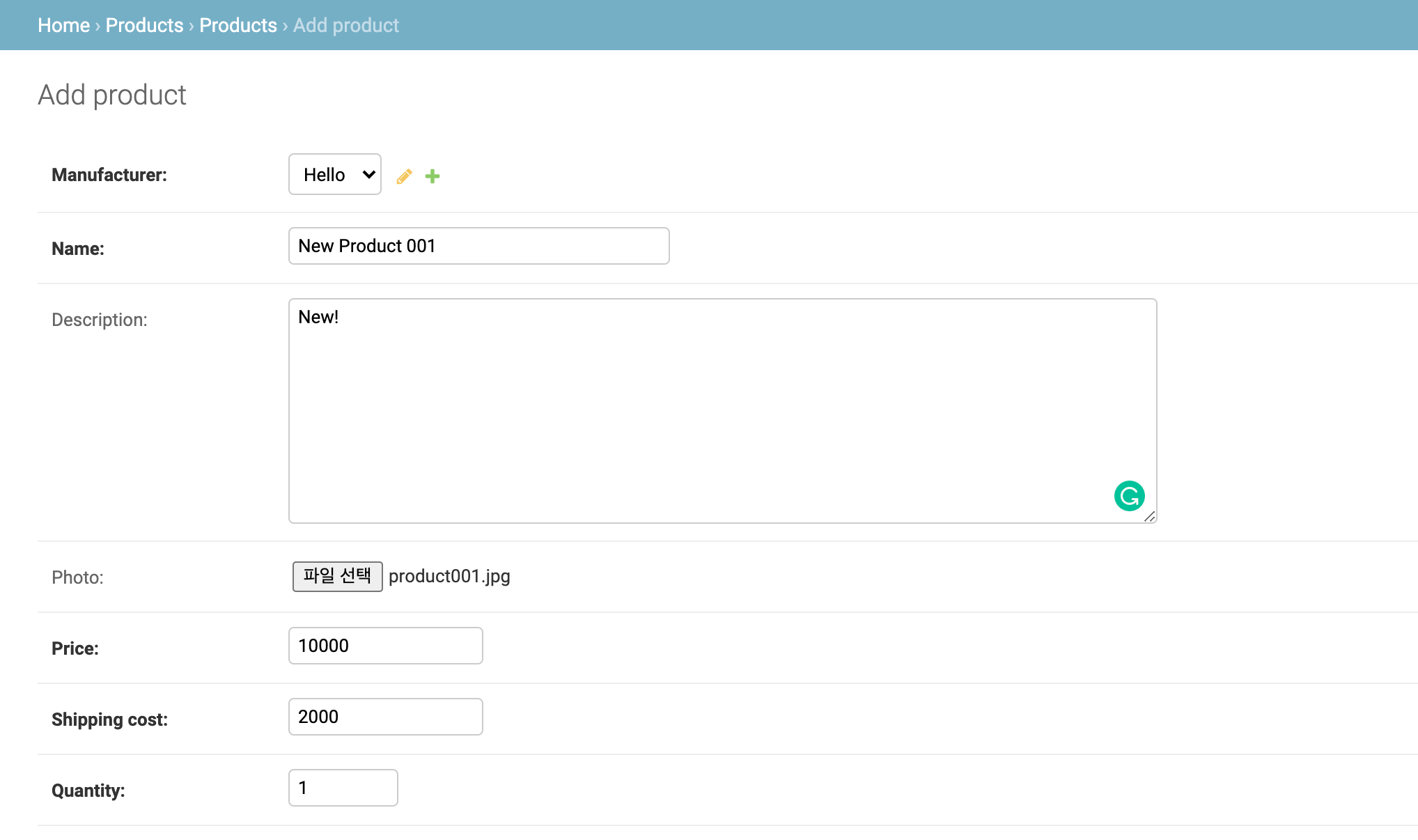
저장된 데이터를 확인하면 다음과 같다.
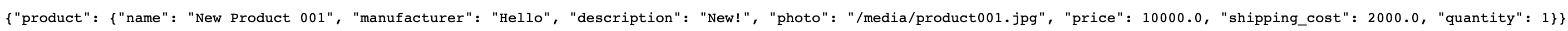 DB에 저장된 이미지 url을 확인하니
DB에 저장된 이미지 url을 확인하니 /media/product001.jpg이다.
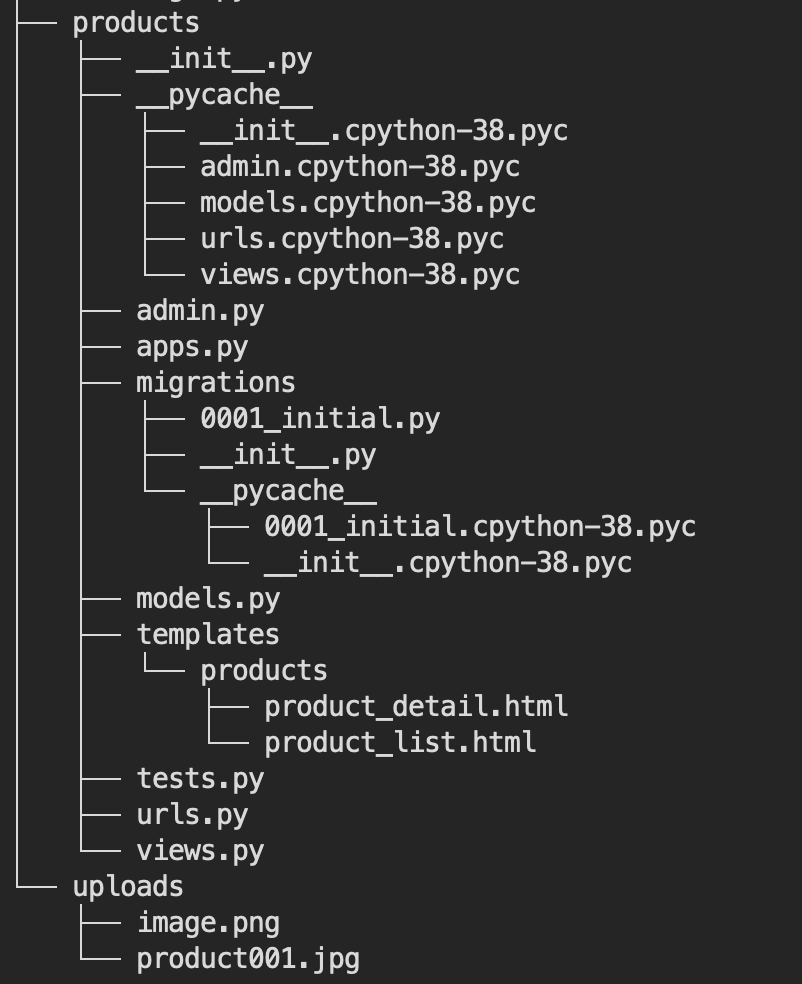 로컬에서는 product001.jpg는 uploads라는 폴더에 저장된 것을 확인할 수 있다.
로컬에서는 product001.jpg는 uploads라는 폴더에 저장된 것을 확인할 수 있다.
개발환경에서의 이미지 서빙
서빙?
웹 서버에서 웹 클라이언트가 특정 위치에(URL) 있는 서버 저장소(storage)에 있는 자원(resource)을 요청(HTTP request) 받아서 제공(serving)하는 것
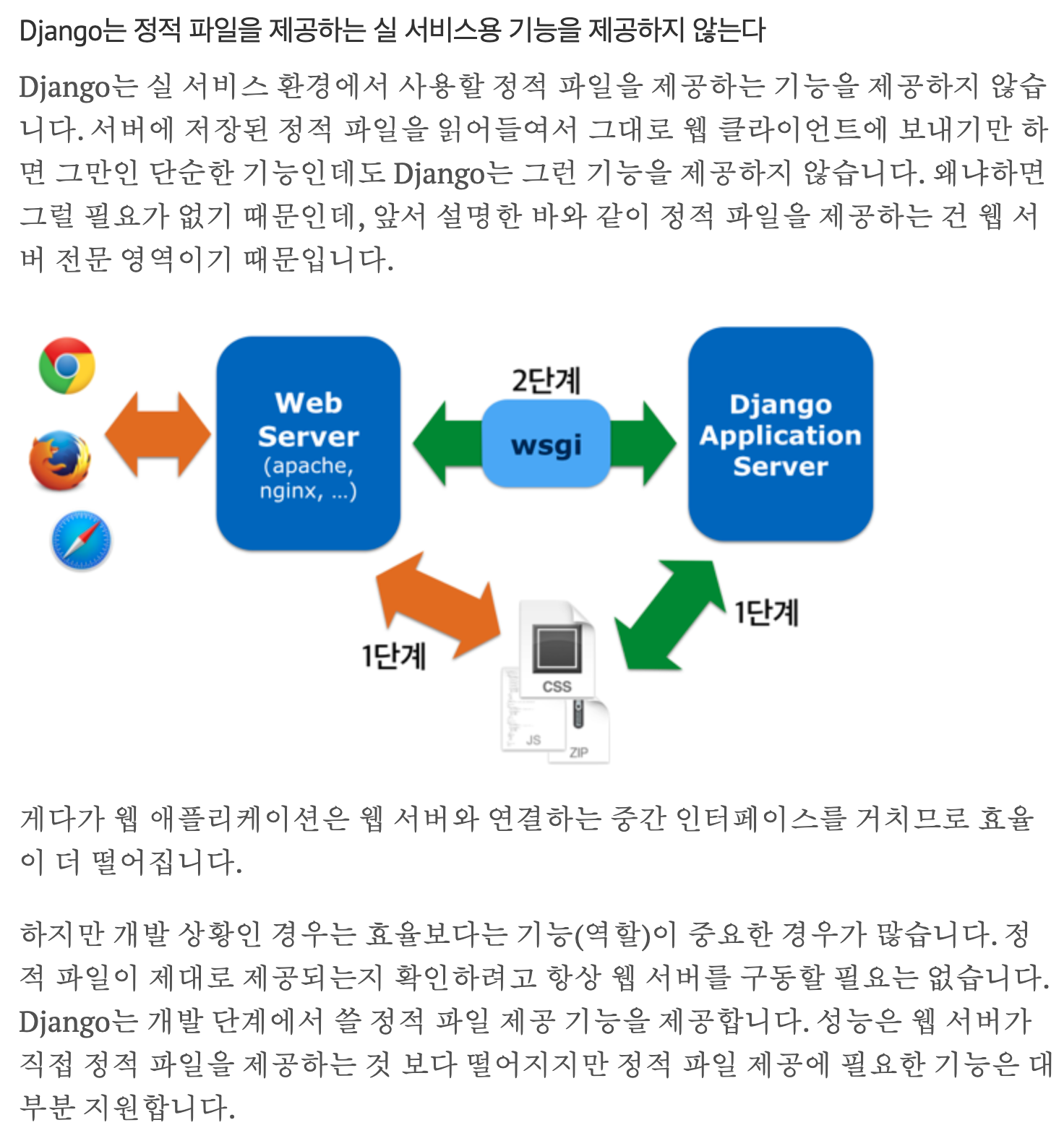
위의 설명처럼 개발 단계(DEBUG = True)에서 정적 파일을 확인하기 위해서는 프로젝트의 urls.py에서 아래와 같은 설정이 필요하다.

이제 브라우저를 통해 확인해보자.
현재는 장고에서 제공하는 개발용 웹서버에 이미지를 업로드하였지만 이와 비슷한 방식으로 AWS의 S3에 이미지를 업로드할 수도 있으니 참고하세요!
https://blog.theodo.com/2019/07/aws-s3-upload-django/
[출처]
https://docs.djangoproject.com/en/3.1/topics/files/
https://blog.hannal.com/2015/04/start_with_django_webframework_06/
https://wayhome25.github.io/django/2017/05/10/media-file/
+) 이것을 읽고 웹서버, 앱서버가 헷갈리고 궁금하다면 여기를 참고하세yo🤟🏻
DB
데이터베이스 설계 과정에 대해 설명해라
(일단 패스)
https://victorydntmd.tistory.com/125
DB Indexing이란 무엇이고 어느 경우에 적용하는지?
DB Indexing
인덱싱이란 쿼리 성능을 향상시키기 위하여 원하는 데이터를 빠르게 찾을 수 있도록 인덱스를 지정하는 것이다.


어느 경우에 적용?
테이블에서 데이터를 가장 빠르게 찾을 수 있는 방법은 pk를 이용하는 것인데, 개발자들은 pk값을 알고 있지만 실제 사용자들은 그렇지 않다.
예를들어 10만명의 유저가 있다고 할때 자신이 쓴 글을 검색하기 위해서는 글의 제목이나 내용을 검색할 것이지 pk로 검색하진 않을 것이다. 이렇게 pk가 아닌 필드로 검색을 하게 되면 테이블 전체를 확인하면서 데이터를 찾아야한다. 만약 수십만개의 데이터가 있는 상황에서 이런 경우가 발생한다면 시간이 굉장히 오래 걸릴 것이다.
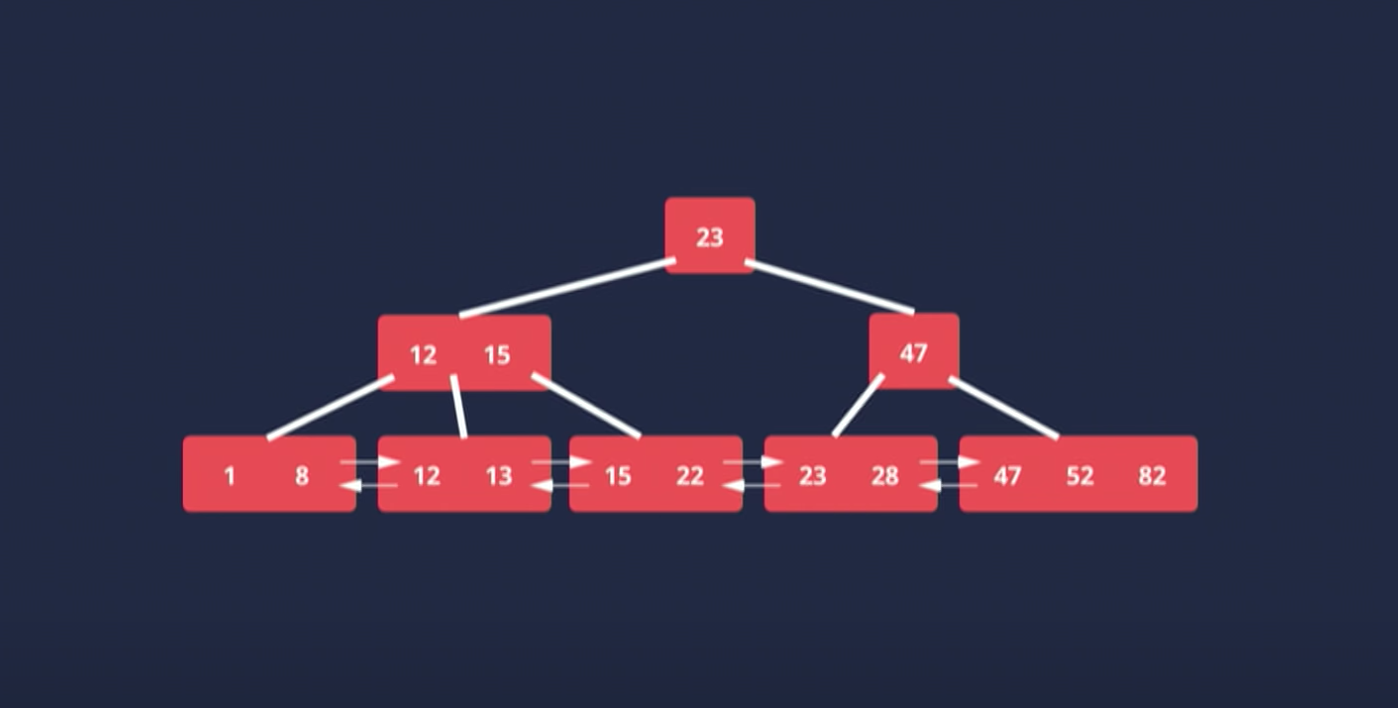 인덱스를 지정하면 해당 인덱스들에 B-Tree(Balanced Tree)를 적용하여 가장 아래에 있는 leaf node에 순차적으로 정렬한다. 이 구조는 인덱스를 빠르게 검색 할 수 있도록 한다. 또한 linked list로 서로 연결되어 있기 때문에 오름차순, 내림차순으로 검색할 수 있다.
인덱스를 지정하면 해당 인덱스들에 B-Tree(Balanced Tree)를 적용하여 가장 아래에 있는 leaf node에 순차적으로 정렬한다. 이 구조는 인덱스를 빠르게 검색 할 수 있도록 한다. 또한 linked list로 서로 연결되어 있기 때문에 오름차순, 내림차순으로 검색할 수 있다.
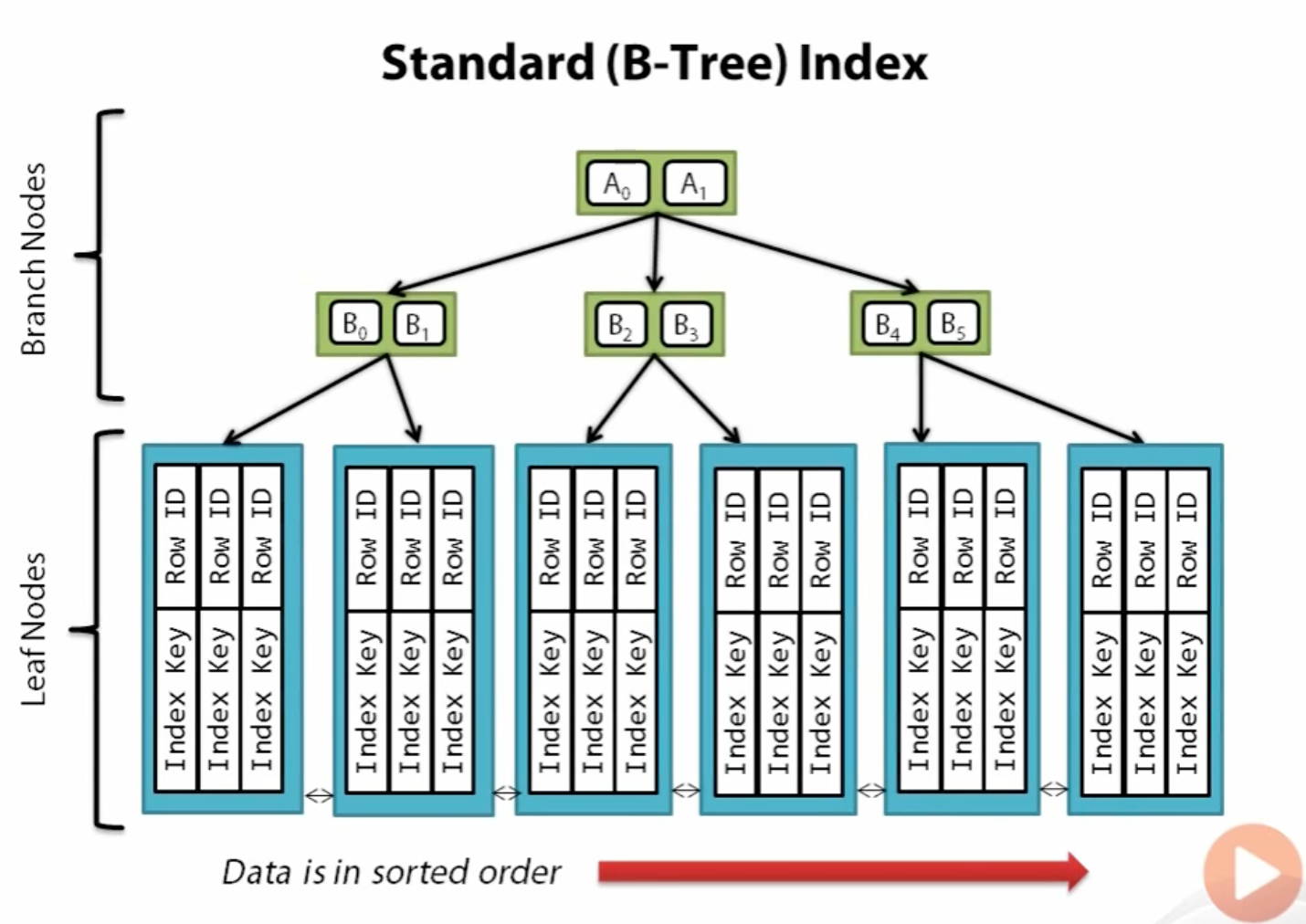 이 인덱스들은 rowid(원래 테이블의 pk)와 연결되어있어 해시를 사용하여 원래의 데이터를 빠르게 찾아갈 수 있다.
이 인덱스들은 rowid(원래 테이블의 pk)와 연결되어있어 해시를 사용하여 원래의 데이터를 빠르게 찾아갈 수 있다.
상황에 따라 알맞은 인덱스를 사용하면 다음과 같이 쿼리의 속도를 향상시킬 수 있다.
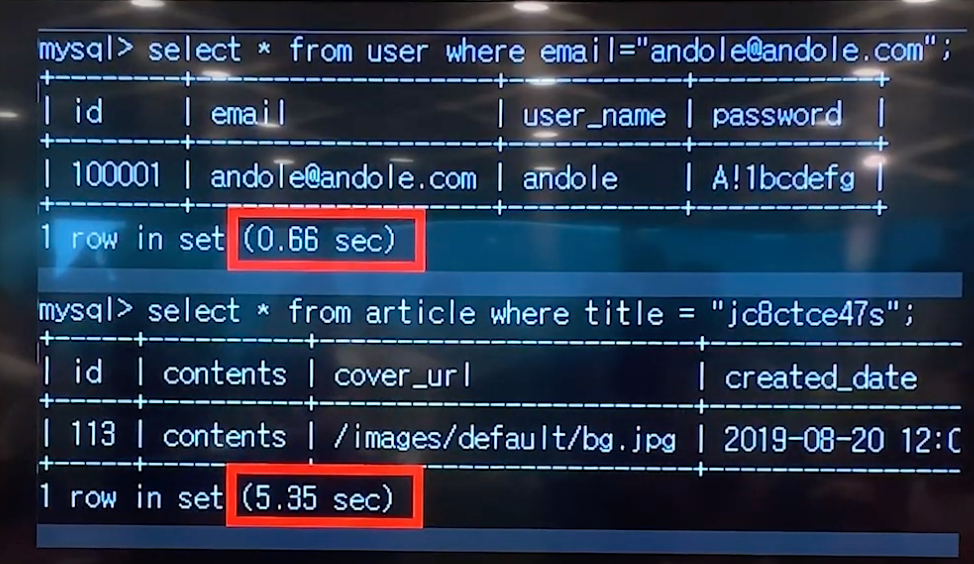 ▲ 인덱싱전
▲ 인덱싱전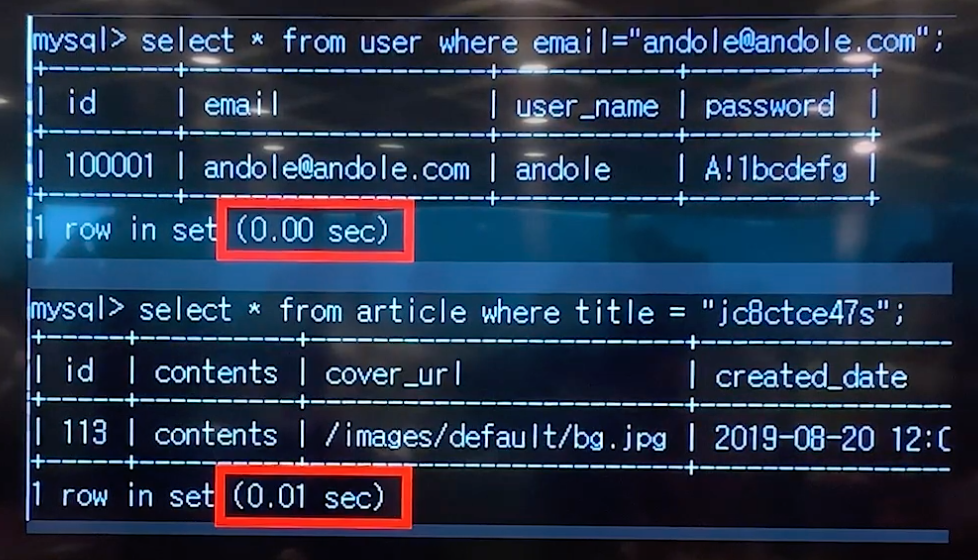 ▲ 인덱싱후
▲ 인덱싱후
[참고]
https://www.youtube.com/watch?v=ZugmrJnbvdU
https://www.youtube.com/watch?v=NkZ6r6z2pBg (추천)
https://www.youtube.com/watch?v=HubezKbFL7E (추천)
https://www.youtube.com/watch?v=7h6x1SDWNnI
