[프로메테우스 #5] 4가지 메트릭 타입(Gauge, Counter, Histogram, Summary) 정리 + 레이블 매처
🖥️제로부터 시작하는 Docker & 쿠버네티스
Prometheus를 쓰다 보면 가장 많이 마주치는 개념이 바로 메트릭 타입이다.
메트릭 타입을 정확히 이해해야 올바른 모니터링과 알람 설정이 가능하다.
Prometheus에는 총 4가지 메트릭 타입이 있다.
- Gauge
- Counter
- Histogram
- Summary
이 글에서는 각각의 개념을 쉽게 설명하고,
실습은 Gauge / Counter 타입 조회 두 가지만 다뤄볼 것이다.
Gauge 타입 (가장 직관적 타입)
Gauge는 말 그대로 눈금(Gauge) 값처럼
현재 상태를 나타내는 변수이다.
특징
- 값이 올라갈 수도 있고 내려갈 수도 있다.
- “현재 CPU 사용량”, “현재 연결 수” 같은 값을 나타낼 때 쓰인다.
- 순간 상태를 나타내기 때문에 변동성이 있다.
ex)
- node_memory_MemAvailable_bytes
- nginx_connections_active
-temperature_celsius - pod_cpu_usage
즉, “어제 40이었다가 지금 27로 떨어졌네?” → 이런 데이터가 Gauge에 해당한다.
Counter 타입 (무조건 증가만 하는 값)
Counter는 이름 그대로 계수기라고 볼 수 있다.
특징은 하나다.
특징
- 값은 증가만 한다.
- 단, 프로세스가 재시작되면 0으로 리셋될 수 있음
- "몇 번 일어났는가?" 를 세는 용도이다.
ex)
- HTTP 요청 횟수 → http_requests_total
- 에러 발생 횟수 → errors_total
- NGINX 요청 횟수 → nginx_http_requests_total
즉, “몇 번 발생했냐?”만 중요한 상황에서 쓰는 타입이라고 볼 수 있다.
Histogram 타입
Histogram은 버킷(bucket) 으로 값들을 모아
구간별로 몇 개가 들어왔는지를 세는 방식이다.
특징
- 예: 0.1초 이하 요청 몇 개? / 0.5초 이하 몇 개? / 1초 이하 몇 개?
- latency, response time 모니터링에 최적화
- histogram_count, histogram_sum 같은 메트릭과 함께 사용된다.
ex)
- http_request_duration_seconds_bucket
- grpc_server_handling_seconds_bucket
즉, “응답시간이 어떤 분포인지 알고 싶다” → Histogram.
Summary 타입
Summary는 백분위(percentile)를 내부적으로 계산하여 제공하는 메트릭이다.
특징
- Prometheus 서버가 아닌 Exporter가 직접 계산한다.
- p50 / p90 / p95 / p99 같은 값을 바로 제공함
ex)
- http_request_duration_seconds{quantile="0.95"}
- 애플리케이션 내부에서 관측한 latency 지표
Histogram과 비슷해 보이지만 목적이 조금 다르다.
- Histogram → 나중에 PromQL로 복잡한 통계 처리 가능
- Summary → Exporter가 이미 계산된 quantile 값만 전달
실습 1. Gauge 타입 조회
Prometheus UI → Graph 탭에서 아래 입력:
예제 1 — 시스템 부하(load average)
node_load1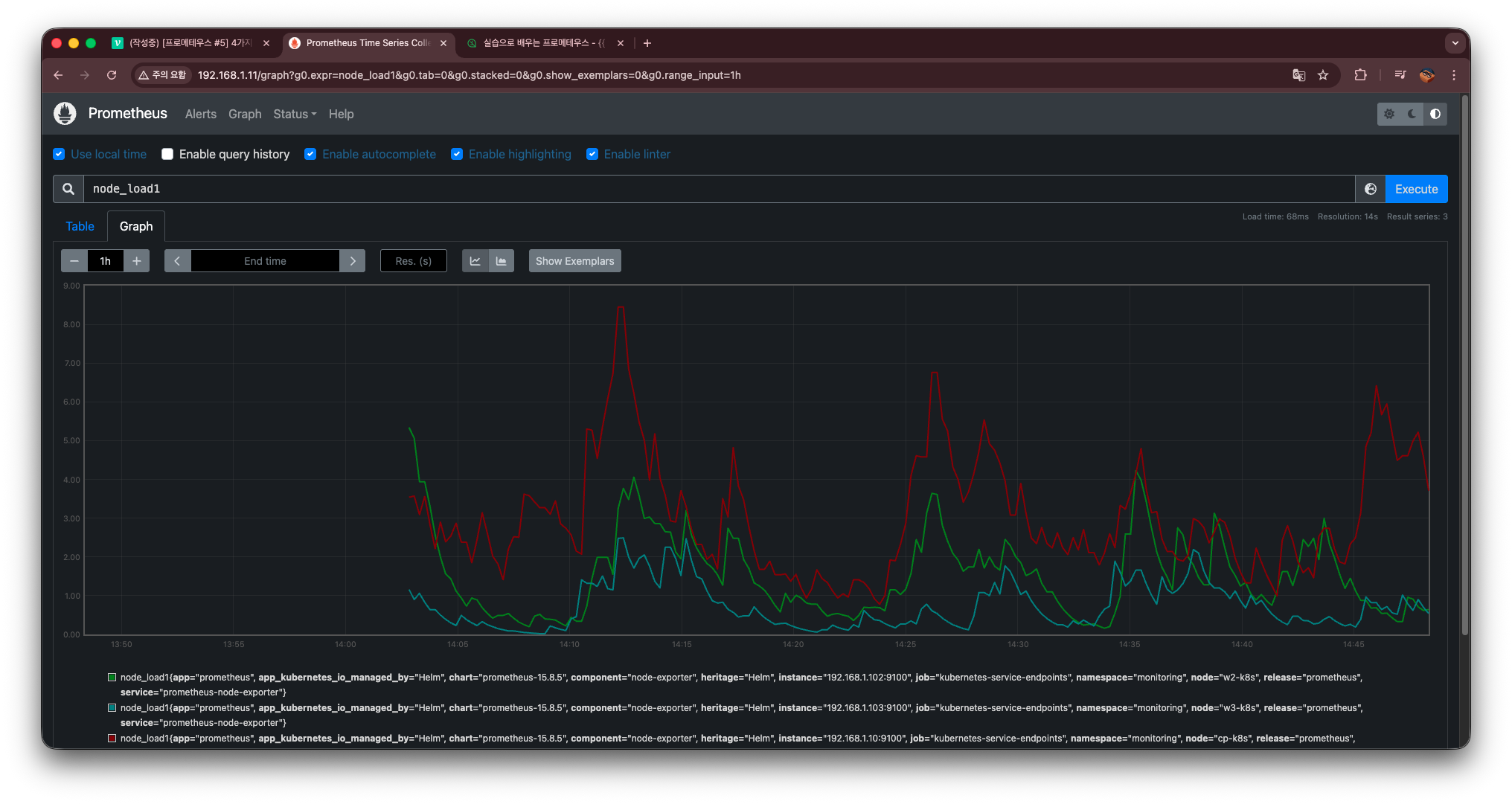
이 값은 계속 오르락내리락하는 Gauge 타입이다.
예제 2 — 남은 메모리
node_memory_MemAvailable_bytes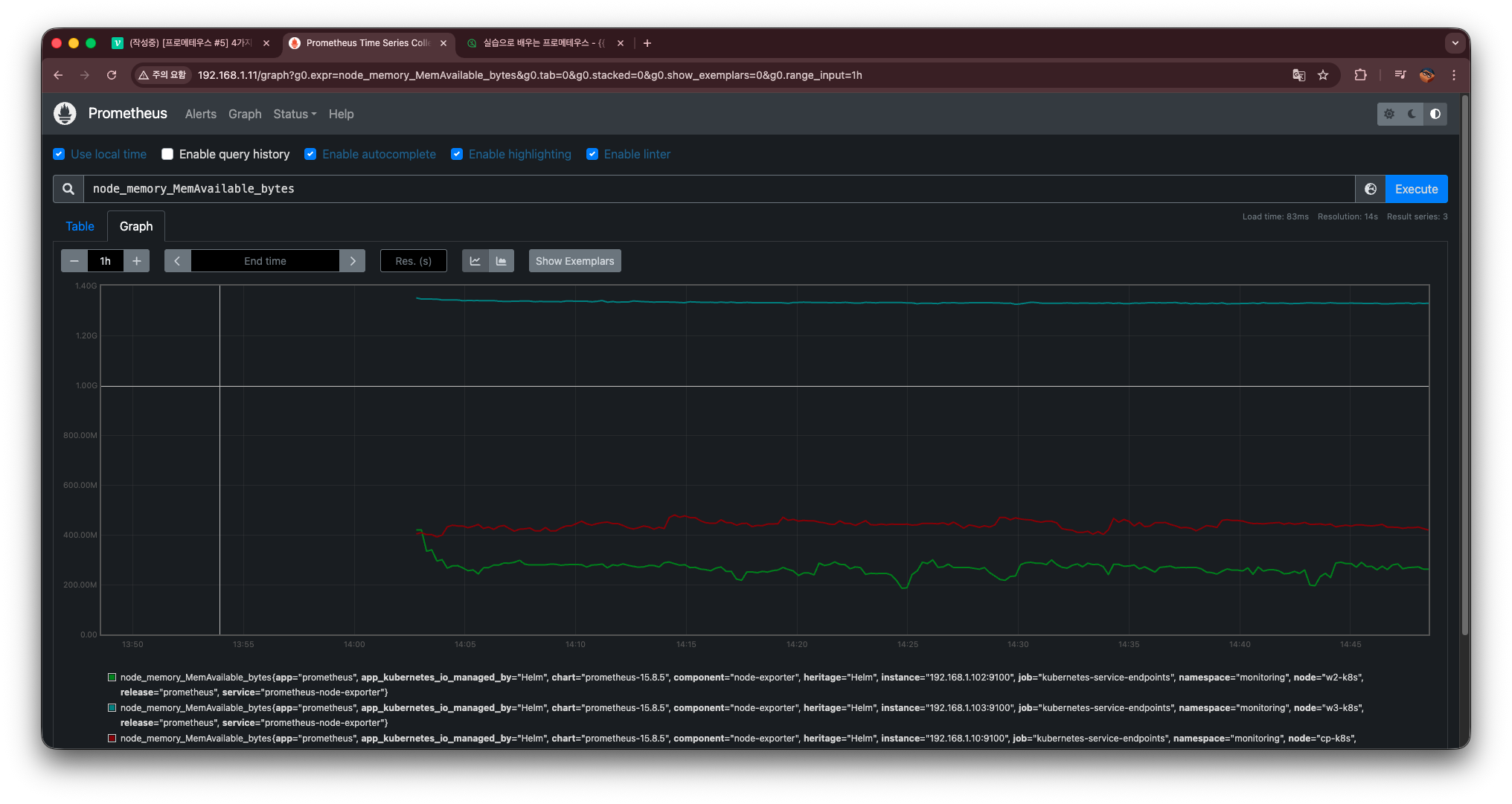
그래프 찍어보면 현재 남아있는 메모리 용량이 실시간으로 변하는 것을 확인할 수 있다.
실습2. Counter 타입 조회
Prometheus UI → Graph 에서 입력:
예제 1 — 컨테이너 재시작 횟수
kube_pod_container_status_restarts_total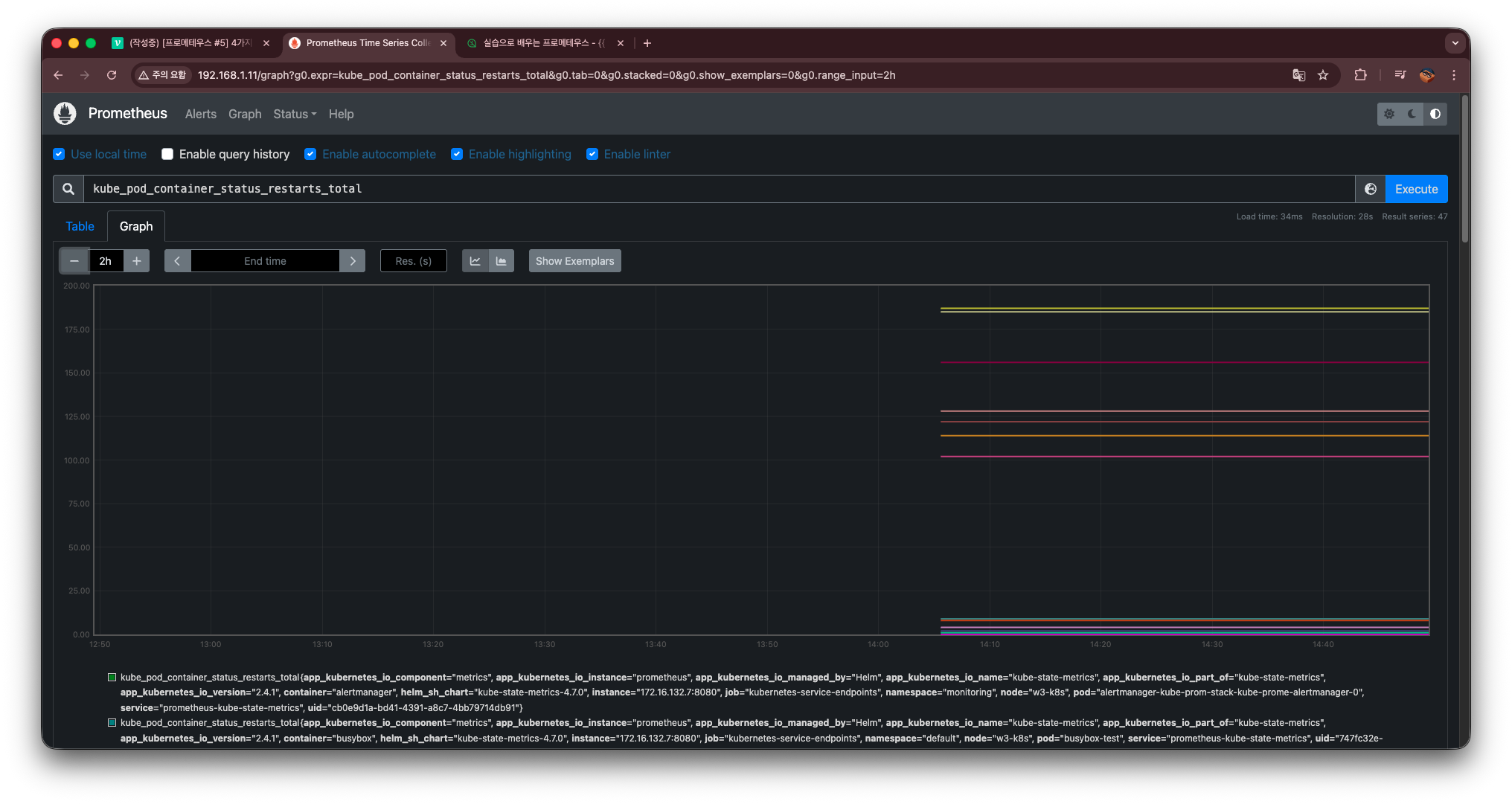
특정 파드만 조회하고 싶으면:
kube_pod_container_status_restarts_total{pod="busybox-test"}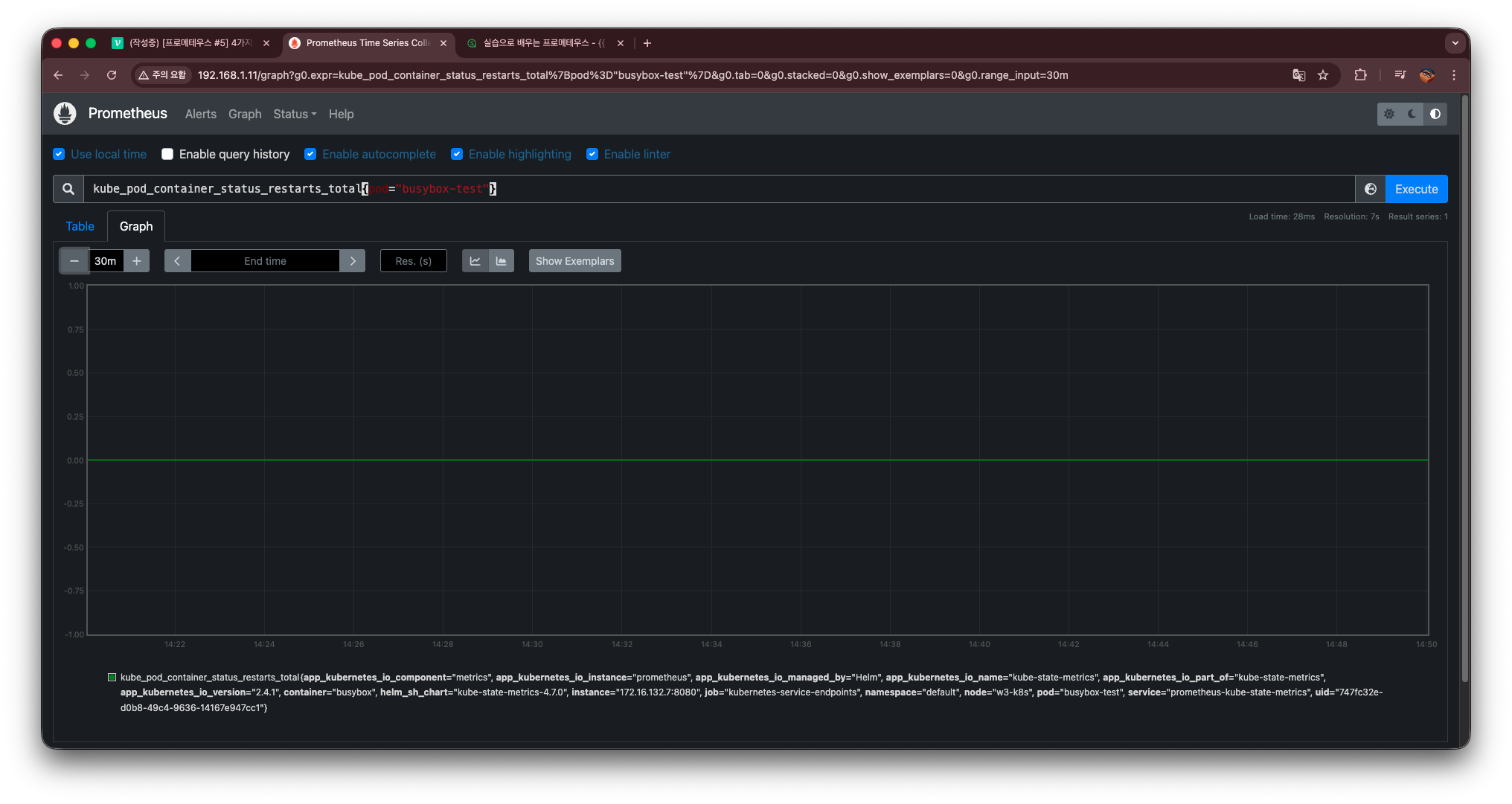
이 값은 절대 감소하지 않고,
재시작이 일어날수록 증가한다.
예제 2 — 프로세스 CPU 누적 사용 시간
process_cpu_seconds_total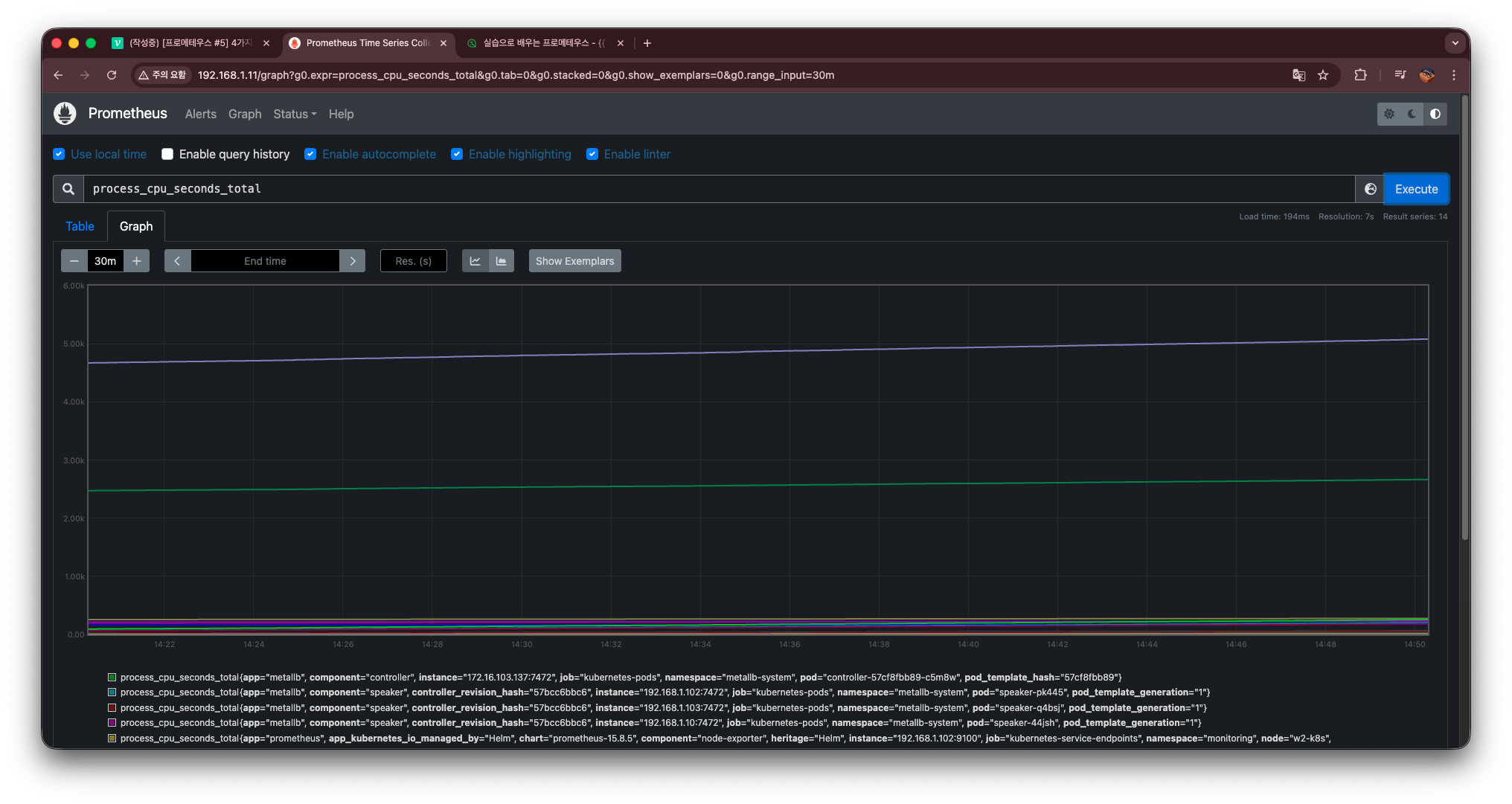
Counter 특성에 따라 숫자가 계속 증가한다.
정리
| 타입 | 특징 | 예 |
|---|---|---|
| Gauge | 오르락내리락 가능한 현재 상태 | node_load1, node_memory_MemAvailable_bytes |
| Counter | 증가만 함, 누적 값 | kube_pod_container_status_restarts_total |
| Histogram | 분포 저장 (bucket) | HTTP latency 분포 |
| Summary | Exporter가 quantile 계산 | p99, p95 등 |
+추가 : Label Matcher(레이블 매처)
위 실습에서 아래 쿼리가 있었다.
kube_pod_container_status_restarts_total{pod="busybox-test"}이 {pod="busybox-test"} 부분이 바로 레이블 매처(Label Matcher)라는 것이다.
레이블 매처란?
Prometheus 메트릭에 달려 있는 레이블(label)을 기준으로 특정 데이터만 필터링하는 문법이다.
메트릭은 단순 숫자가 아니라,
key=value 형태의 레이블이 함께 붙어 있다.
ex)
kube_pod_container_status_restarts_total{namespace="default", pod="busybox-test", container="busybox"}레이블 매처를 사용하면,
이 메트릭 중에서 원하는 조건만 뽑아올 수 있다.
예를 들어:
특정 파드만 조회
{pod="busybox-test"}특정 네임스페이스만 보기
{namespace="monitoring"}여러 컨테이너 제외하기(~= 사용)
{container!="POD"}busy 로 시작하는 모든 파드 조회
kube_pod_container_status_restarts_total{pod=~"busy.*"}이런식으로 여러가지 필터링을 하여 표현할 수 있다.
레이블 매처 4종류
| 문법 | 의미 | 예시 |
|---|---|---|
= | 정확히 일치 | {pod="busybox-test"} |
!= | 해당 값만 제외 | {container!="POD"} |
=~ | 정규식(regex) 매칭 | {pod=~"busy.*"} → busy로 시작하는 모든 파드 |
!~ | 정규식 불일치 | {pod!~"nginx.*"} → nginx로 시작하는 건 제외 |
레이블 매처 정리
레이블 매처는 Prometheus에서 정확히 내가 보고 싶은 대상만 골라내기 위한 필터라고 보면 된다.
Gauge / Counter / Histogram / Summary 모든 메트릭 타입에 적용 가능하다.
