최근 출장 관리 자동화 서비스를 개발하면서 자연어에서 출장 관련 정보를 추출하는 모델을 만들고 있습니다. 이 과정에서 Named Entity Recognition(NER)을 활용하여 출장 인원, 장소, 기간, 비용 등의 정보를 자동으로 추출하는 로직을 짜봤습니다. 이번 포스팅에서는 구현과정에서 발생한 문제 상황과 해결 과정을 기록해봅니다...
1. 문제 정의
자연어로 작성된 출장 관련 문장에서 다음과 같은 정보를 추출하는 것이 목표입니다.
- 출장 인원: "최명재, 이재영"
- 출장 장소: "서울에서 일본 도쿄로"
- 출장 기간: "2월 15일부터 2월 20일까지"
- 최대 비용: "500만원"
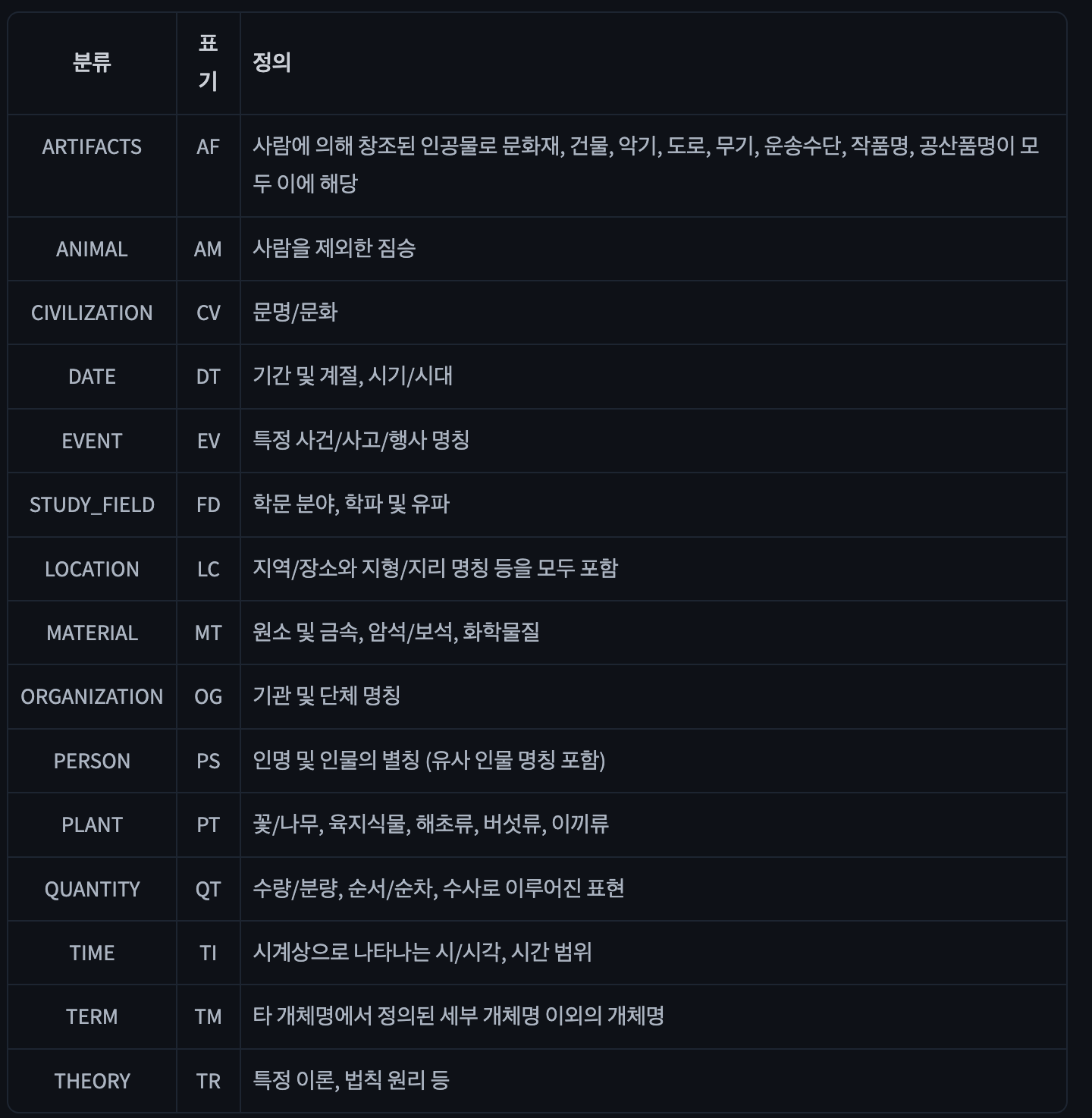
사용한 모델 (한국어 NER 모델)
태그셋
2. 문제점 분석
-
서브워드 토큰화 문제
- 모델이 단어를 서브워드 단위로 토큰화하여
##가 포함된 결과를 반환하는 경우가 많았습니다. - 예를 들어,
이##재영처럼 이름이 두 개의 서브워드로 나뉘는 경우가 있었습니다.
- 모델이 단어를 서브워드 단위로 토큰화하여
-
출장 기간 추출 오류
- 모델이 날짜를
2월15일부터 2월20일까지와 같이 하나의 개체로 인식하기도 하지만,2월15일,2월20일처럼 개별적으로 인식하는 경우도 있었습니다. ~,부터,까지등의 다양한 날짜 표현을 고려해야 했습니다.
- 모델이 날짜를
-
비용 표현 문제
- 초기에 더미로 설정한 입력예시인 "최대 예산은 500만원"은 정상적으로 추출되지만, "최대 비용 500만원" 또는 "비용은 1,000,000" 같은 표현이 누락되는 경우가 있었습니다.
- 쉼표가 포함된 금액 (
1,000,000원)을 처리하는 로직이 필요했습니다.
3. 해결 방법
3.1 서브워드 문제 해결 - 토큰 병합
NER 모델의 결과를 후처리하여, 서브워드로 나뉜 토큰을 병합하는 로직을 추가했습니다.
# 서브워드 토큰화 문제 해결 - 토큰 병합
def merge_tokens(ner_results, text):
merged_entities = []
current_entity = None
for token in ner_results:
word = token["word"].replace("##", "") # 서브워드 처리
entity = token["entity"]
score = token["score"]
start, end = token["start"], token["end"]
if entity.startswith("B-") or current_entity is None:
if current_entity:
merged_entities.append(current_entity)
current_entity = {"entity": entity[2:], "word": word, "score": score, "start": start, "end": end}
else:
current_entity["word"] += word
current_entity["end"] = end
current_entity["score"] = (current_entity["score"] + score) / 2 # 평균 점수 계산
if current_entity:
merged_entities.append(current_entity)
return merged_entities3.2 출장 기간 처리
다양한 날짜 표현을 인식할 수 있도록 ~, 부터, 까지 등의 표현을 고려하여 시작일과 종료일을 구분했습니다.
# 날짜 처리
def extract_dates(dates):
start_date, end_date = None, None
if dates:
date_text = dates[0]
if "~" in date_text:
parts = date_text.split("~")
start_date, end_date = parts[0].strip(), parts[1].strip()
elif "부터" in date_text:
start_date = date_text.split("부터")[0].strip()
if "까지" in date_text:
end_date = date_text.split("까지")[0].split("부터")[-1].strip()
return start_date, end_date3.3 비용 표현 확장
비용 표현을 보다 유연하게 인식할 수 있도록 정규표현식을 확장했습니다.
import re
def extract_cost(text):
cost_pattern = r"(비용은|예산|최대 비용)\s*(\d{1,3}(?:,\d{3})*)\s*(만원|원)?"
cost_match = re.search(cost_pattern, text)
if cost_match:
number_str = cost_match.group(2)
number = int(number_str.replace(",", "")) # 쉼표 제거 후 정수 변환
unit = cost_match.group(3)
if unit == "만원" or not unit:
cost_value = number * 10000 # 만원 단위 기본 처리
else:
cost_value = number # 원 단위일 경우 그대로 사용
return f"{cost_value:,}원"
return None3.4 출장 정보 종합 추출
위에서 해결한 문제들을 반영하여 최종적으로 출장 정보를 종합적으로 추출하는 함수를 작성했습니다.
def extract_business_trip_info(ner_results, text):
people, locations, dates = [], [], []
cost = extract_cost(text) # 비용 추출
for entity in merge_tokens(ner_results, text):
entity_type = entity["entity"]
entity_value = entity["word"]
if entity_type == "PS":
people.append(entity_value)
elif entity_type == "LC":
locations.append(entity_value)
elif entity_type == "DT":
dates.append(entity_value)
start_date, end_date = extract_dates(dates)
return {
"출장 인원": people,
"출장 장소": {"출발지": locations[0] if locations else None, "도착지": " ".join(locations[1:]) if len(locations) > 1 else None},
"출장 기간": {"시작일": start_date, "종료일": end_date},
"비용": cost
}4. 결과 및 성능 개선
이제 다양한 형태의 입력에서도 정확하게 정보를 추출할 수 있게 되었습니다.
입력 예시:
비용은 100만원
예산 1,000,000
최대 비용 500만원출력:
1,000,000원
10,000,000원
5,000,000원위를 통해 더 정교하게 데이터를 추출할 수 있습니다! 허허..
현재도 다양한 입력 패턴을 고려하여 모델과 정규식 기반 처리를 개선해 나가는 중입니다

chmod 000