들어가며
원래 파이썬을 즐겨 사용하는 편은 아니지만 이번 학기에 파이썬 관련 수업을 듣게 되면서 조금 흥미가 생겼다.
여전히 syntax는 쓸 데마다 헷갈리긴 하지만 간결하고 표현력 좋은 언어적 특성은 참 맘에 든다.
아무튼 기말고사 기간 전까지 텀 프로젝트 과제가 주어졌는데
평소에 한 번쯤 써보고 싶었던 pandas나 matplotlib 같은 데이터 처리/시각화 라이브러리에 관심이 갔다.
그래서 이 두 녀석을 가지고 조금 장난을 쳐봤다.
가장 먼저 프로젝트 후보로 떠오른게 필립스 곡선.
필립스 곡선!
경제학 원론을 배운 사람이라면 들어봤을 수도 있다.
필립스 곡선(영어: Phillips curve)은 인플레이션율과 실업률 간에 상충관계(역의 상관관계)가 있음을 나타내는 곡선이다. 그래프의 세로축에 인플레이션율(물가상승률), 가로축에 실업률을 두면 우하향하는 곡선이 되는데, 이는 여러 나라의 시대별 자료에 대한 실증 연구를 통해 명목 임금상승률이 높을수록 실업률이 낮게 나타나는 반비례 관계임을 보여준다. 이러한 사실은 물가 상승과 실업 사이에는 상충 관계가 존재함을 의미하기 때문에 많은 경제학자들의 관심을 가지게 하였다.
실제 그래프의 모양은 아래와 같이 생겼다.
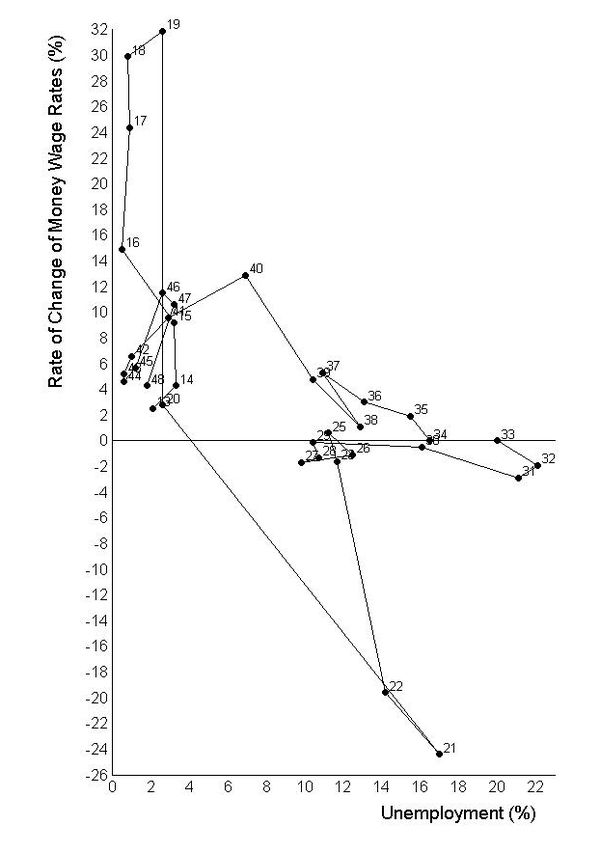
<출처> 위키백과 - 필립스 곡선
언뜻 보기엔 복잡해보이는 모양이지만 핵심적인 부분은 인플레이션율과 실업률이 서로 반비례하는 경향이 있다는 것.
(일반적으로 인플레이션율의 상승은 경제 성장의 결과로 해석되고, 이에 따라 실업률이 낮아진다는 이야기)
코드 작성
수업 시간에는 그런가보다 하고 넘어갔는데 갑자기 우리나라의 실제 데이터를 바탕으로 그려보면 재밌을 것 같다는 생각이 들었다.
그래서 바로 실행에 옮겼다.
우선 통계청으로 달려가서 소비자물가상승률과 실업률 자료를 구했다.
아래는 1990년부터 2017년까지 28개년도의 실업률과 소비자물가상승률 자료이다.


다음은 엑셀 파일 읽기다.
데이터 분석 라이브러리로 유명한 pandas는 엑셀 파일을 읽어들이는 api를 제공한다.
아래는 실제 코드 예시이다.
# import pandas as pd
def load_data():
"""
() -> (dict, dict)
물가상승률과 실업률 엑셀 파일을 읽어들여서 각각을 data와 label_name을 가진 데이터로 반환
"""
excel_files = ('inflation_rates.xls', 'unemployment_rates.xls')
unemployment_rate = {
'data': pd.read_excel(excel_files[1]).loc['실업률(%)'].values,
'label': 'unemployment rate'
}
inflation_rate = {
'data': pd.read_excel(excel_files[0]).loc['소비자물가상승률(%)'].values,
'label': 'inflation rate'
}
# TODO: fix manual float conversion
# 일부 데이터가 str 타입으로 로드되는 문제가 있음
unemployment_rate['data'] = [float(n) for n in unemployment_rate['data']]
return unemployment_rate, inflation_rate그런데 코드를 돌려보니 실업률 배열의 일부 데이터가 str 타입으로 저장된 것을 확인했다. 당장은 원인을 파악하지 못해서 그냥 float 함수를 이용해 형 변환을 해줬다.
다음으로 그래프를 그리기 위해 matplotlib을 활용했다.
matplotlib은 파이썬의 데이터 시각화 라이브러리로 일반적인 차트뿐만 아니라 바 차트, 원형 차트 등 여러가지 형태로 데이터를 나타낼 수 있게 도와준다.
아래는 matplotlib을 이용해서 필립스곡선을 그리는 함수를 정의한 예이다.
# import import matplotlib.pyplot as plt
# from math import ceil
def show_philips_curve(x_axis, y_axis, year_range):
"""
(x_axis: array<float>,
y_axis: array<float>,
year_range: (start=int, end=int)) -> None
시작, 끝 연도를 받아서 범위 내의 필립스 곡선을 보여주는 함수
"""
# 차트의 크기를 지정
plt.figure(figsize=(20, 10))
start = year_range[0]
end = year_range[1]
# MIN_YEAR = 1990
data_range = slice(start - MIN_YEAR, end - MIN_YEAR + 1)
data_x_axis = x_axis['data'][data_range]
data_y_axis = y_axis['data'][data_range]
# marker를 활용하면 각 자료마다 동그랗게 마커를 표시할 수 있다.
plt.plot(data_x_axis, data_y_axis, marker='o')
# 3 칸을 추가하면 더 보기가 쉽다
max_x_value = ceil(max(data_x_axis)) + 3
max_y_value = ceil(max(data_y_axis)) + 3
# x, y 축의 범위를 표시
plt.axis([0, max_x_value, 0, max_y_value])
plt.xticks(range(max_x_value + 1))
plt.yticks(range(max_y_value + 1))
# 각 축마다 이름을 붙여줌
plt.xlabel(x_axis['label'])
plt.ylabel(y_axis['label'])
# annotate를 활용하면 각 자료마다 라벨을 붙여줄 수 있음
# 여기서는 각 자료마다 해당 년도를 붙여주었음
for year in range(start, end + 1):
index = year - start
plt.annotate(year, (data_x_axis[index], data_y_axis[index]) )
# plt.show()를 해줘야 보여줄 수 있음.
plt.show()마지막으로 시작년도와 끝년도를 사용자에게 입력받는 main 함수를 정의하면?
def main():
print(f'필립스 곡선을 보여주는 프로그램입니다. {MIN_YEAR}년부터 최대 {MAX_YEAR}년까지의 데이터를 조회할 수 있습니다. \n')
start_year = int(input(f'시작년도를 입력해주세요. ex) {MIN_YEAR} \n'))
end_year = int(input(f'마지막년도를 입력해주세요. ex) {MAX_YEAR} \n'))
if (start_year < MIN_YEAR) or (end_year > MAX_YEAR):
print("error: year out of range")
return
unemployment_rate, inflation_rate = load_data()
show_philips_curve(
x_axis=unemployment_rate,
y_axis=inflation_rate,
year_range=(start_year, end_year)
)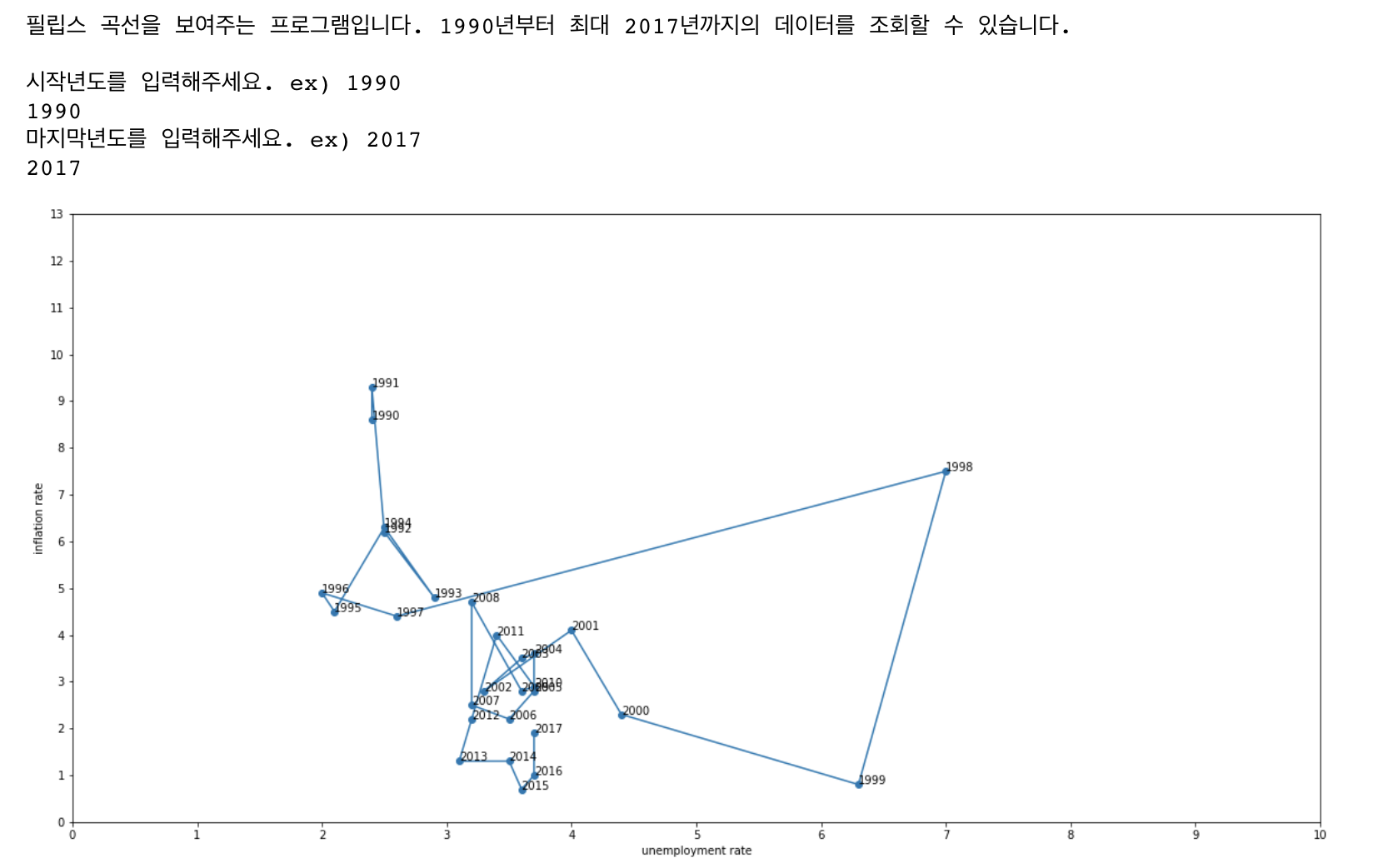
위와 같은 근사한 결과를 얻을 수 있다! 😀
마치며
데이터 처리/시각화는 파이썬이 갑..!
참고

오홍.. 신기하네요
왠지 조만간 회사에서 A/B 테스트 관련 작업 때문에
데이터 처리하게 될 일이 있을 것 같은데..
아직 이 분야는 초보라 좀 걱정되긴 하지만 뭐
컴퓨터 공학도로써 시간 금방하겠죠 헷