지도 학습이란?
정답(label)을 컴퓨터에게 미리 알려 주고 데이터를 학습시키는 방법이다.
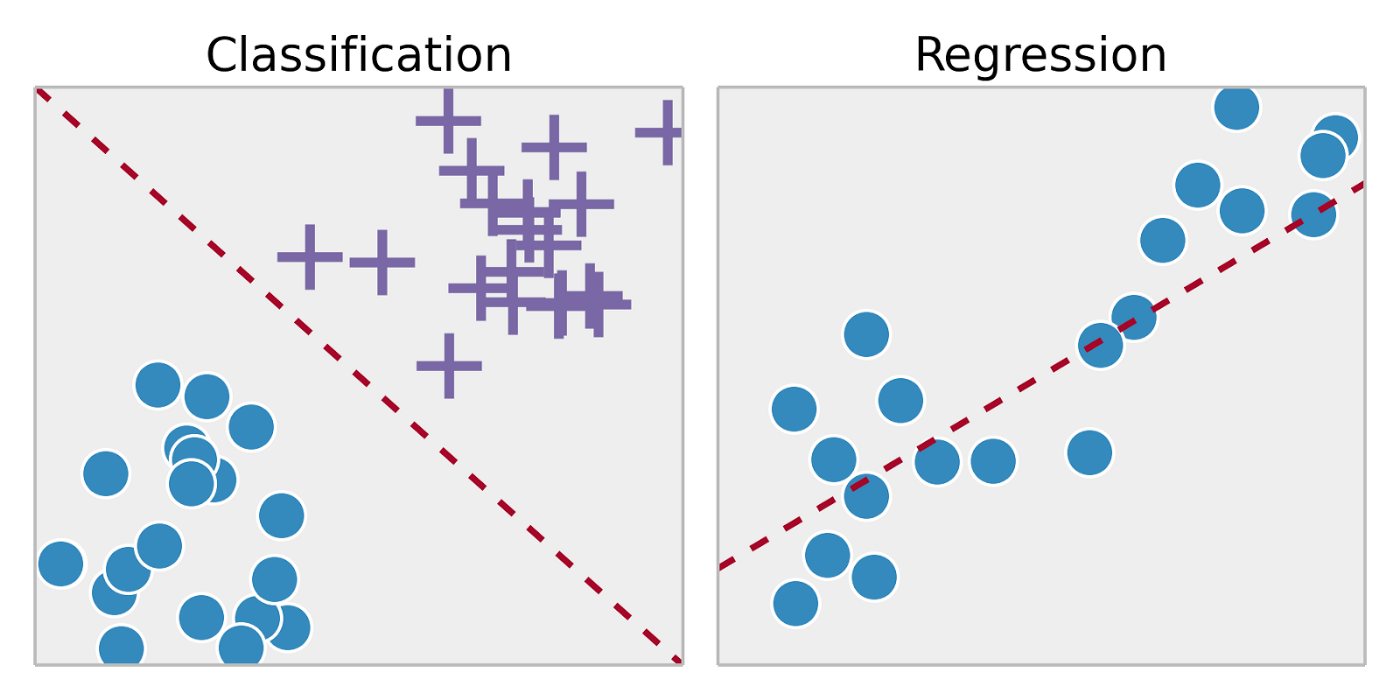
지도 학습에는 분류(classification)와 회귀(regression)가 존재한다.
| 구분 | 분류 | 회귀 |
|---|---|---|
| 데이터 유형 | 이산형 데이터(discrete) | 연속형 데이터(continuous) |
| 결과 | 훈련 데이터의 레이블 중 하나를 예측 | 연속된 값을 예측 |
| 예시 | 학습 데이터를 A,B,C 그룹 중 하나로 매핑 | 결괏값이 어떤 값이든 나올 수 있음 |
1. K-최근접 이웃이란?
새로운 데이터가 입력될 때, 기존 클러스터에서 모든 데이터와 인스턴스(instance) 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘
즉, 과거 데이터를 사용하는 것이 아닌, 과거 데이터를 저장해두고 필요할 때마다 비교를 수행하는 방식이다. k-NN은 다음과 같은 특성을 가진다.
- 분류 또는 회귀에 사용할 수 있는 알고리즘으로 간단하고 강력하다.
- 비매개변수 모델 알고리즘이다.
- 훈련단계에서 학습을 하지 않기 때문에 "게으른 학습"이라고 부른다.
- 거리에만 의존하므로 차원의 저주에 따라 예측에 필요한 특징의 갯수가 늘어나면 성능이 크게 저하된다.
보통 알고리즘에 'K-'라는 단어가 붙으면 갯수에 대한 처리 기법을 다룬다고 알면 된다.2. K-최근접 이웃의 원리
K-최근접 이웃 알고리즘의 핵심은 쿼리지점과 다른 데이터 지점 사이의 거리를 결정하는 것이다. 거리 계산 메트릭은 다음 4가지로 분류된다.
- 유클리드 거리
- 맨해튼 거리
- 민코프스키 거리
- 해밍 거리
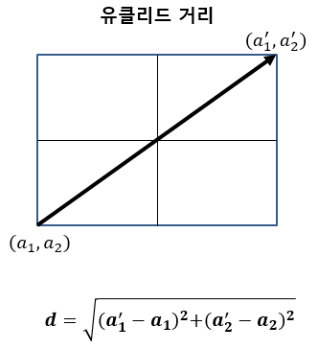
1) 유클리드 거리
- 두 점 사이의 거리를 계산할 때 흔히 쓰는 방법
- 두 점의 최단거리를 의미
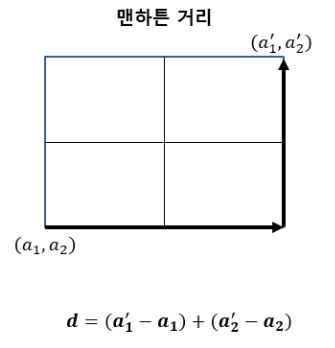
2) 맨해튼 거리
- 한 번에 한 축 방향으로 움직일 수 있을 때, 두 점 사이의 거리

AI/Network