이런 서비스를 만든 이야기를 합니다!
1. Learn-me 서비스가 뭔가요?
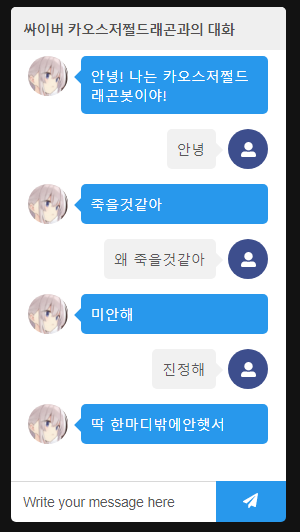
Twitter API를 이용해 유저의 최근 3200개 트윗을 분석한 후, 나를 따라하는 Chatbot을 만들어 주는 서비스입니다!
2. 어떤 이야기를 할 예정인가요?
머신 러닝은 기본적으로 컴퓨팅 자원이 많이 듭니다.
특히, 사용한 모델인 BERT는 모델 자체가 꽤 무거워, 많은 사람에게 "충분히 빠른" 훈련 결과를 가져다 주는 것은 꽤 어려운 일입니다.
일반적인 사용자라면, 오늘 서비스를 등록해서 내일 결과를 받는 것을 원하진 않을 테니까요.
따라서, 많은 유저가 접속하더라도 "충분히 빠른" 수준의 결과값을 보장하기 위해 어떤 아키텍쳐를 사용했는지, 왜 그 방법을 사용했고, 런칭 이후 어떤 결과가 나왔는지에 대한 이야기를 할 예정입니다.
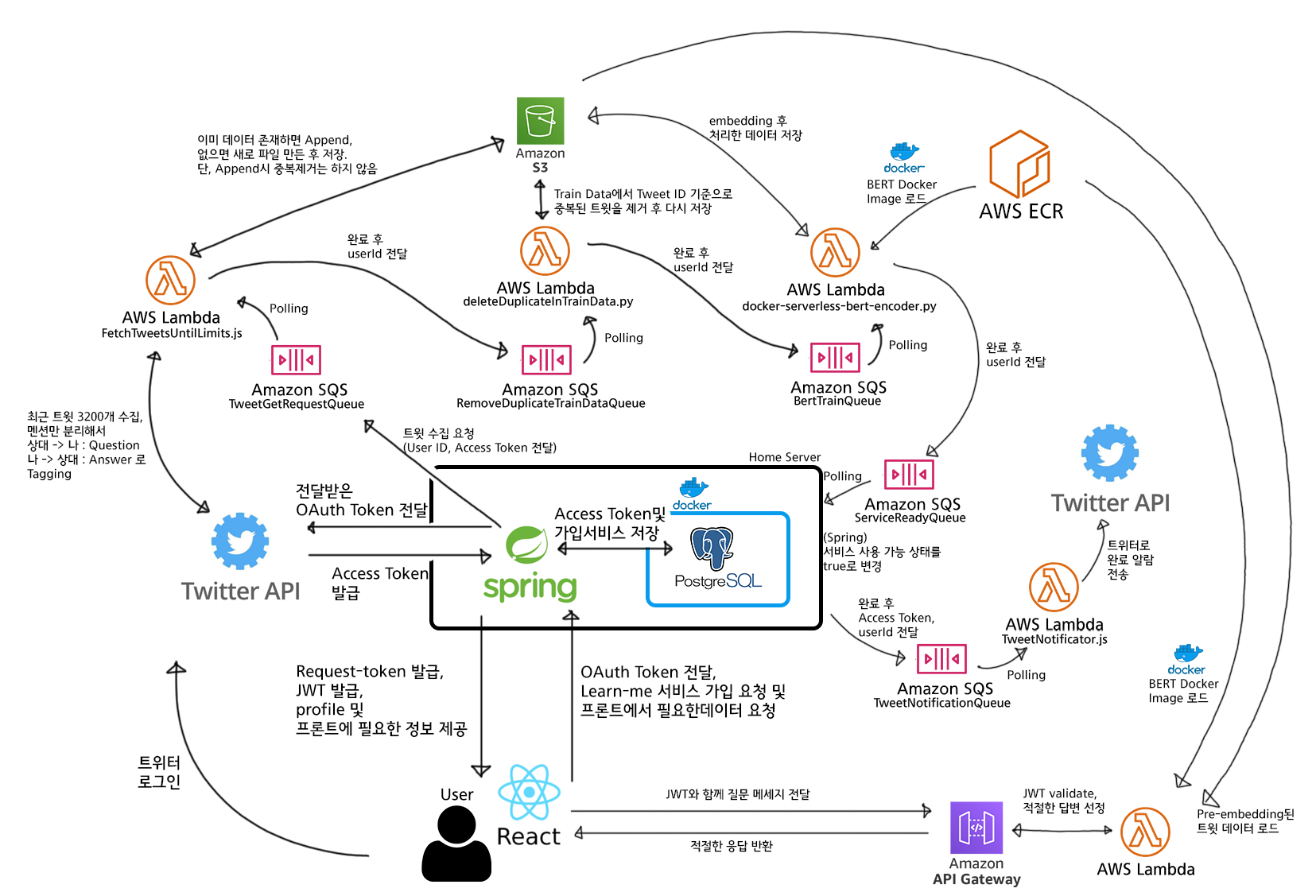
즉, 이렇게 생긴 아키텍쳐를 만든 이야기를 합니다! 우클릭 후 새 탭에서 이미지 보기를 누르시면 더 잘 보여요.
각 장에서 이야기할 내용은 다음과 같습니다.
1장에선 개발 배경 및 첫 런칭하고 느꼈던 여러 생각들에 대한 이야기를 합니다.
링크
- 이하는 작성중인 내용들입니다..
2장에선 "큰 서비스" 를 어떻게 "작은 작업" 들로 나누고, 작은 작업들이 어떻게 협력 해서 서비스를 이루는지에 대한 이야기를 할 예정입니다.
거시적인 관점에서, 프론트엔드, 백엔드, 데이터 파이프라인의 동작 원리는 일단 멀리 치워 두고, 전체 서비스가 어떻게 동작하는지에 대한 이야기를 할 예정입니다. 어려운 이야기는 빼고, 정말 정말 정말 쉽게 이야기 하는 것이 목표입니다!
3장에선, OAuth 및 로그인 관련 이야기를 할 예정입니다.
회원 가입/로그인 기능은 어떤 사이트에나 다 있지만, 직접 구현 해 보면 "생각보다" 어렵고, 고민할 것이 많다는 것을 느낄 수 있습니다. 프론트엔드-백엔드로 나뉜 환경에서 어떻게 OAuth 로그인을 구현하는가? 에 대한 예제입니다. 또한, JWT 와 선택 이유에 대해서도 다룹니다.
4장에선, Queue 기반 Serverless 아키텍쳐 와 클라우드 시스템 에 대해 다룹니다. 플랫폼은 AWS 기반이지만, 다른 플랫폼에서도 비슷한 서비스를 찾아 사용 가능할 것이라고 생각합니다.
5장에선, 프론트엔드 개발 과 그 과정에서 했던 고민에 대해 다룹니다.
6장에선, 백엔드 개발 과 그 과정에서 했던 고민들에 대해 다룹니다.
7장에선, BERT Model을 AWS Lambda에 올리며 생긴 여러 문제점과, 그를 해결한 방법에 대해서 다룹니다.
