
퀵 정렬
퀵 정렬(Quick Sort)는 대표적인 분할 정복 알고리즘으로 O(N x logN) 의 평균 속도를 가진다. 특정한 상황을 제외하고는 O(N^2)을 가지는 선택, 삽입, 버블 정렬보다 훨씬 빠른 알고리즘이며 말 그대로 Quick한 정렬 알고리즘이다. 하지만 이미 어느정도 정렬되어 있어 분할 정복의 특성을 이용하지 못하는 특정 상황의 경우 O(N^2)의 시간복잡도를 가질 수 있다.
- 평균 시간 복잡도:
O(N x logN) - 최악 시간 복잡도:
O(N^2)
분할 정복 알고리즘이 빠른 이유?
예를 들어 O(N^2)의 시간 복잡도를 가진다고 가정을 할 때
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]의 경우의 수는 10 x 10 = 100번 수행되지만
반으로 분할 정복할 경우에는
[1, 2, 3, 4, 5]의 경우, 5 x 5 = 25
[6, 7, 8, 9, 10]의 경우, 5 x 5 = 25
25 + 25 = 50으로 총 50번으로 수행횟수가 줄어 든다.
단계
일단 간단히 정리하자면, 퀵 정렬은 특정한 기준값(Pivot)을 기준으로 큰 값과 작은 값을 서로 교환한 후 배열을 반으로 나누는 방식이다. 아래의 예시를 통해서 알아보자.

- 첫 번째 값(8)을 pivot값으로 지정한다.

- pivot값과 비교해서 큰 값을 왼쪽에서 오른쪽으로, 작은 값을 오른쪽에서 왼쪽으로 검색한다. 이때 큰 값(10)의 인덱스가 작은 값(2)의 인덱스보다 더 작기 때문에 두 값을 서로 교환한다.
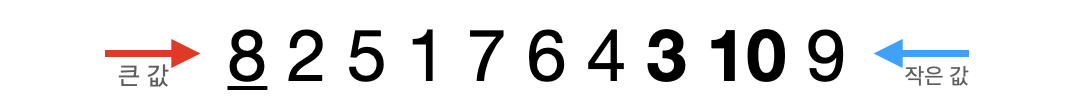
- 다시 검색한다. 이때 큰 값(10)의 인덱스가 작은 값(3) 인덱스보다 더 크기 때문에 작은 값인
3과 pivot값을 서로 교환한다.
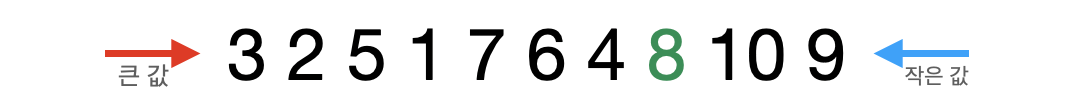
- 교환된 pivot값(8)은 정렬이 완료되고 8을 기준으로 나누어진 왼쪽과 오른쪽 집합에 대해서 위의 과정을 반복한다. - (분할 정복)
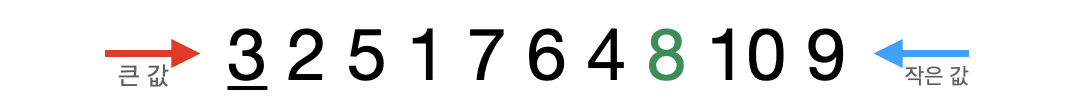
- 8을 기준으로 왼쪽 그룹의 첫 번째 값(3)을 pivot값으로 지정하고 검색한다.
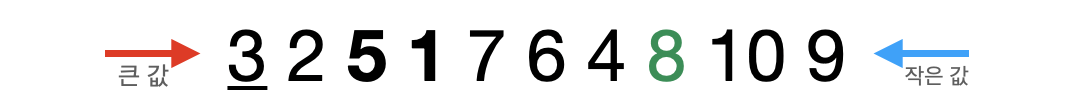
큰 값(5)의 인덱스가 작은 값(1)의 인덱스보다 더 작기 때문에 두 값을 서로 교환한다.
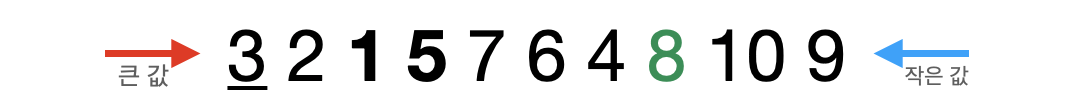
- 다시 검색하고 큰 값(5)의 인덱스가 작은 값(1)의 인덱스보다 더 크기 때문에 작은 값과 pivot값을 서로 교환한다.
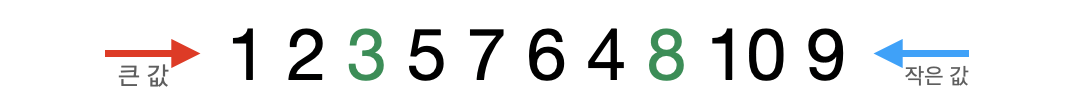
- 교환된 pivot값(3)은 정렬이 완료되고 3을 기준으로 다시 나누어진 왼쪽과 오른쪽 집합에 대해서 위의 과정을 반복한다. - (분할 정복)

- 3을 기준으로 왼쪽 그룹의 첫 번째 값(1)을 pivot값으로 지정하고 검색한다. 이 때 큰 값(2)는 찾았지만 작은 값은 찾지 못해서 pivot값(1)까지 도달한다. 또한 큰 값(2)의 인덱스가 작은 값(1)의 인덱스보다 더 크기 때문에 작은 값(1)과 pivot값(1)을 서로 교환한다. 자신을 서로 교환하기 떄문에 변화가 없다.

- 교환된 pivot값(1)은 정렬이 완료되고 1을 기준으로 나누어진 왼쪽과 오른쪽 집합에 대해서 위의 과정을 반복해야하는 데 왼쪽이 없기 때문에 넘어가서 오른쪽에 대해서 수행한다. - (분할 정복)

이런 과정을 반복하면 정렬이 완료된다. 이 과정에서 잘 생각해보면 분할 정복이 잘 이루어지지 않으면 성능이 제대로 나오지 않는 이유도 알 수 있을 것이다.
구현
#include <stdio.h>
int number = 10;
int arr[] = {1, 3, 6, 9, 10, 4, 7, 8, 2, 5};
void quickSort(int *arr, int start, int end) {
if (start >= end) return;
int key = start; // 기준값(Pivot)
int i = start + 1;
int j = end;
int temp;
// 엇갈릴 때까지 반복
while (i <= j) {
// key보다 큰 값을 만날 때까지
while (arr[key] >= arr[i] && i <= end) {
i++;
}
// key보다 작은 값을 만날 때까지
while (arr[key] <= arr[j] && j > start) {
j--;
}
// 엇갈리면 작은 값과 key값 swap
if (i > j) {
temp = arr[key];
arr[key] = arr[j];
arr[j] = temp;
// 엇갈리지 않으면 i,j값 swap
} else {
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// key값 기준으로 양쪽을 재귀로 분할 정복
quickSort(arr, start, j-1);
quickSort(arr, j+1, end);
}
int main() {
quickSort(arr, 0, number-1);
for (int i=0; i<number; ++i) {
printf("%d ", arr[i]);
}
return 0;
}병합 정렬
병합 정렬(Merge Sort)도 퀵 정렬과 마찬가지로 대표적인 분할 정복 알고리즘이며 O(N x logN)의 시간 복잡도를 가진다. 하지만 특정한 상황에서 O(N^2) 이라는 최악의 시간 복잡도를 가지는 퀵 정렬과 달리 병합 정렬은 메모리는 조금 더 사용하지만 최악의 경우에도 O(N x logN)을 보장한다는 점이 큰 특징이다.
단계
합병 정렬의 개념은 하나씩 나눠질 때까지 반으로 모두 나눈 다음 합칠 때 정렬을 수행하는 것이 전부이다.
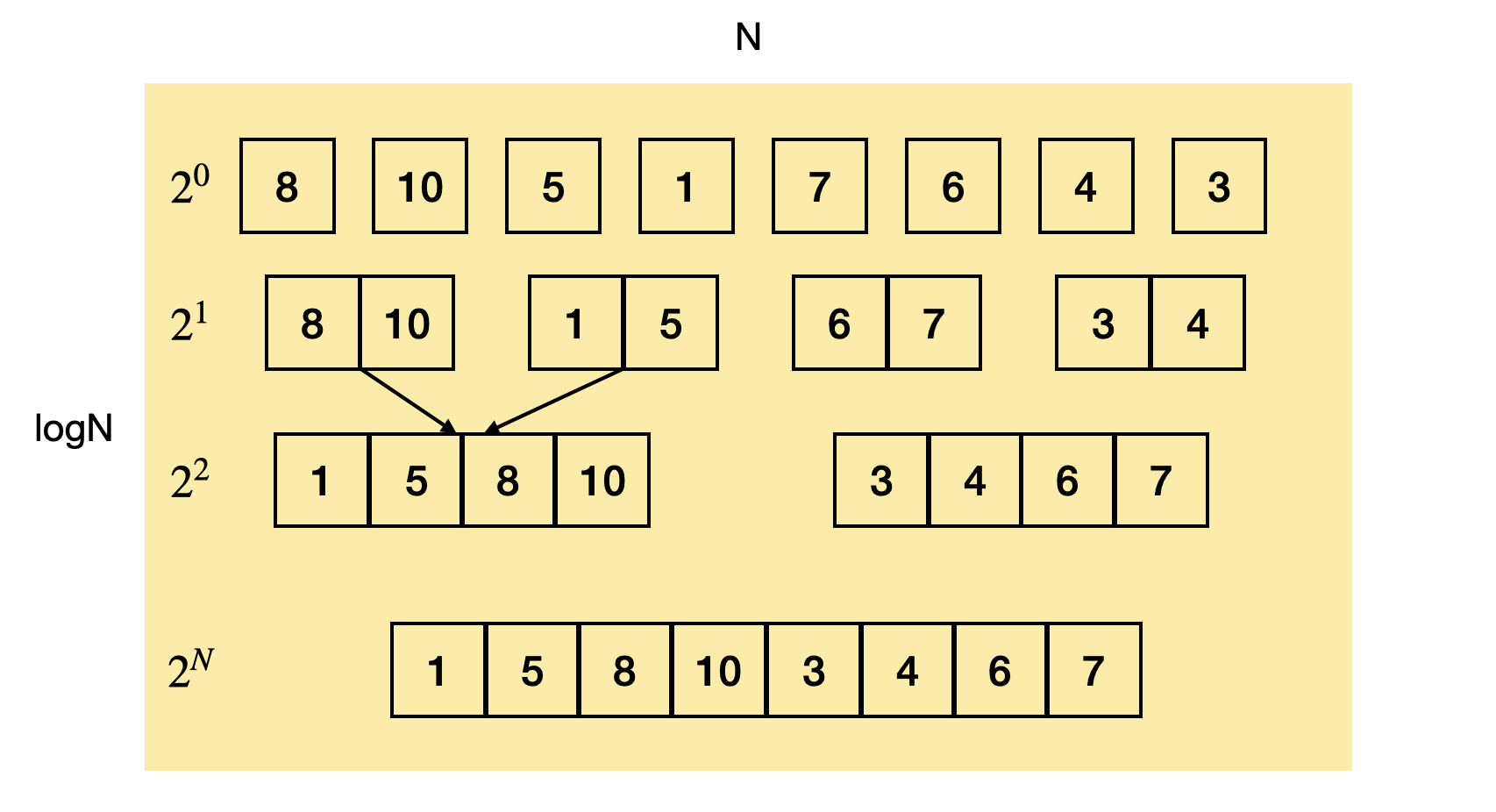
- 높이는 왜
logN인가?- 무조건 반으로 나누기 때문에 단계의 수는
log(data의 개수)이다. - (거의 상수와 같은 정도)
- 무조건 반으로 나누기 때문에 단계의 수는
- 너비는 왜
N인가?- 병합된 집합들끼리 비교 연산을하는데 왜
N밖에 안되는지 의아해할 수 있다. 그 이유는 병합된 이전 집합들이 이미 각각 정렬된 상태이기 때문이다.
- 병합된 집합들끼리 비교 연산을하는데 왜
구현
#include <stdio.h>
int sorted[10];
void merge(int arr[], int m, int mid, int n) {
int i = m; // 앞 배열의 idx
int j = mid + 1; // 뒷 배열의 idx
int k = m; // sorted[]의 idx
// 작은 순서대로 sorted[]에 삽입, idx 증가
while (i <= mid && j <= n) {
if (arr[i] <= arr[j]) {
sorted[k] = arr[i];
i++;
} else {
sorted[k] = arr[j];
j++;
}
k++;
}
// 앞, 뒷 배열의 삽입이 먼저 완료될 때 나머지 데이터 삽입
if (i > mid) {
for (int t=j; t<=n; t++) {
sorted[k] = arr[t];
k++;
}
} else {
for (int t=i; t<=mid; t++) {
sorted[k] = arr[t];
k++;
}
}
// 임시로 sorted[]에 저장된 배열을 삽입
for (int t=m; t<=n; t++) {
arr[t] = sorted[t];
}
}
void mergeSort(int arr[], int m, int n) {
// 분할 정복(재귀)
if (m < n) {
int mid = (m + n) / 2;
mergeSort(arr, m, mid);
mergeSort(arr, mid+1, n);
merge(arr, m, mid, n);
}
}
int main() {
int arr[10] = {7, 6, 5, 8, 3, 5, 9, 1, 2, 10};
mergeSort(arr, 0, 9);
for (int i=0; i<10; i++) {
printf("%d ", arr[i]);
}
return 0;
}![]()
