시멘틱 웹
-
검색엔진은 이 시대의 가장 강력한 권력 중의 하나라고 말할 수도 있는데 SEO (검색엔진 최적화): Search Engine Optimization 같은 마케팅 도구를 사용해 검색엔진이 본인의 웹사이트를 검색하기 알맞은 구조로 웹사이트를 조정하기도 하는데, 이것은 검색엔진이 웹사이트 정보를 어떻게 수집하는부터 알아야 한다.
-
검색엔진은 로봇(Robot)이라는 프로그램을 이용해 매일 전세계의 웹사이트 정보를 수집한다.(크롤링) 그리고 검색 사이트 이용자가 검색할 만한 키워드를 미리 예상해 검색 키워드에 대응하는 인덱스(색인)을 만들어 둔다.(인덱싱) 인덱스를 생성할 때 사용되는 정보는 검색 로봇이 수집한 정보인데 웹사이트의 HTML 코드이다. 검색엔진은 HTML 코드 만으로 그 의미를 인지하여야 하는데 이떄 시맨틱 요소를 해석하게 된다.
시멘틱 요소
-
개발자가 의도한 요소의 의미가 명확히 드러나게 하고 코드의 가독성을 높이고 유지보수를 쉽게한다.
-
시멘틱 태그 -> 브라우저, 검색엔진, 개발자 모두에게 콘텐츠의 의미를 명확히 설명하는 역할.
-
시멘틱 웹 -> 웹에 존재하는 수많은 웹페이지들에 메타데이터를 부여하여, 기존의 잡다한 데이터 집합이었던 웹페이지를 '의미'와 '관련성'을 가지는 거대한 데이터베이스로 구축하고자 하는 발상
-
non-semantic 요소
: div, span 등이 있으며 content에 대해 어떤 설명도 하지 않는다. -
semantic 요소
: form, table, img 등이 있으며 content의 의미를 명확히 설명한다. -
HTML5에서 새롭게 추가된 시멘틱 태그.
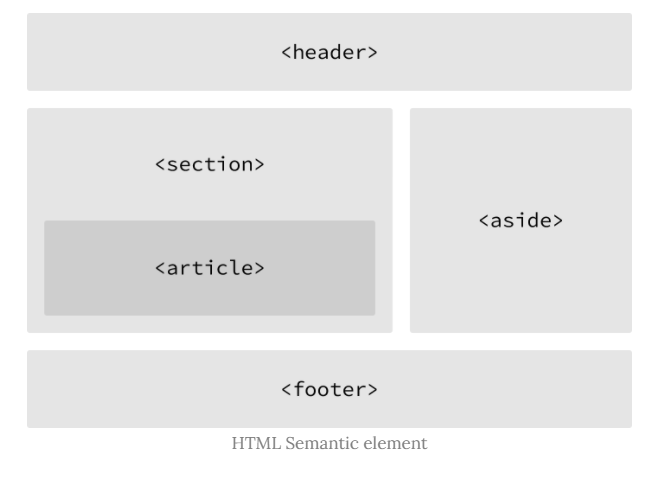
1. header -> 헤더- nav -> 내비게이션
- aside -> 사이드에 위치하는 공간
- section -> 본문의 여러 내용(article)을 포함하는 공간
- article -> 본문의 주내용이 들어가는 공간
- footer -> 푸터
참고 : https://poiemaweb.com/html5-semantic-web
