Image Classification
-
Semantic Gap: 사람은 그림을 보지만 컴퓨터는 숫자의 집합으로 보이는 문제
-
사진을 보고 고양이라고 판단하기 위해서 컴퓨터가 갖는 challenges
- ViewPoint variation: 카메라의 각도가 조금만 달라져도 픽셀 값이 달라지는 문제
- Background Clutter: 고양이와 배경이 유사해서 구분하기 힘든 경우
- Illumination: 조명
- Occlusion: 사물이 가려져서 고양이라고 판단하기 어려운 경우
- Deformation: 고양이가 누워있는지, 앉아있는지에 따라서 모양이 달라짐
- Intraclass variation: 다양한 모습(색, 크기, 나이 등등)
-
Machine Learning: Data-Driven Approach (데이터 중심 접근방법)
- 이미지 dataset과 label 들을 수집한다.
- Machine Learning 알고리즘으로 classifier를 훈련한다 (train)
- classifier를 새로운 이미지에 적용해보며 평가 (predict)
-
NN (Nearist Neighbor)
- train: 모든 데이터와 label 들을 기억한다
- predict: 가장 유사한 train 이미지로 labeling
-
Distance Metric
-
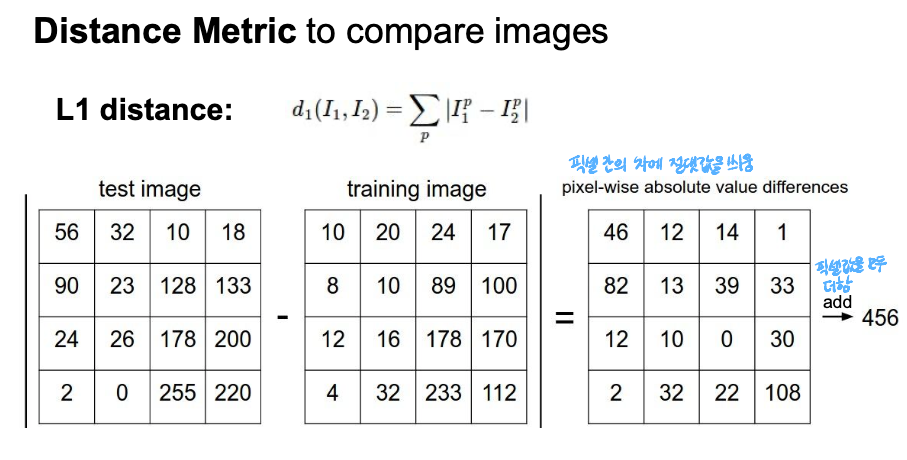
L1 distance:
- p는 모든 dimension을 의미한다. 예를 들어서, I1과 I2가 각각 (1, 1), (2, 0)의 값을 가지는 좌표들이라면, L1 distance는 |1-2| + |1-0|으로 2 가 된다
- 이미지 데이터에서도 유사하게 거리를 구할 수 있다. 동일한 크기의 이미지에 대해서 pixel-wise로 차를 계산하고,그 모든 차를 더해주면 두 이미지 데이터의 L1 distance를 구할 수 있다
- 이러한 거리 방식은 coordinate system과 잘 맞기 때문에 벡터의 각 원소가 각각의 의미를 가질 때 주로 쓰인다.
- L2 distance(Euclidean distance):
- 유클리드 거리는 우리가 일반적으로 알고 있는 거리를 의미한다. 위의 예제와 같이 I1과 I2가 각각 (1,1)과 (2,0)의 값을 가지는 좌표라면, 거리는 가 된다. 이 역시 3차원 이상의 dimension에 확장될 수 있다.
- 이러한 거리방식은 어떠한 공간에서 feature가 의미를 가질 때 주로 사용된다.
-

-
K-Nearest Neighbors


-
Hyperparameters
이 lecture에서는 k, distance(L1 or L2)를 의미-
idea #1: 학습 데이터의 정확도와 성능을 최대화하는 hyperparameter를 선택
👉 문제점: K = 1인 경우에 언제나 완벽하게 작동한다 (K의 값을 올리는 것이 학습 데이터를 잘못 분류할 수 있지만, 학습 데이터에 없는 데이터(test data)에 대해서 더 좋은 성능을 보인다, 우리에게 중요한 것은 학습 데이터에 없는 데이터에 대한 성능!)
-
idea #2: data를 test data와 train data로 split, test data에 가장 잘 작동하는 hyperparameter를 선택
👉 문제점: 새로운 data에 대해서 잘 작동하는지 알 수 없다.. (test data는 한 번만 작동시켜 보는 것이 가장 적절하다. 왜냐하면 만일 test data를 사용해서 적합한 hyperparameter를 찾아도 그것이 다른 test data 에서 잘 작동될지 보장할 수 없음)
-
idea #3(best!): train, validation data로 data를 split 한다, 그리고 validation에서 hyperparameter를 선택한 뒤, test 단계에서 검증해본다.
👉 test data는 오로지 1번만 수행하게 되는 장점
-
idea #4: Cross-Validation: data를 여러개의 fold로 나누고 각각의 fold 를 돌아가면서 한번씩 validation set으로 사용한다.
👉 단점: test data를 한번만 수행한다는 장점이 있지만 계산량이 너무 많아서 deep learning 보다는 작은 dataset에 유용하다
-
-
K-NN의 단점
-
Distance metric이 유용하지 않음
 그림에서 보면 1 pixel 만큼 사진을 shift 했을 때, 사람의 눈에는 두 사진이 매우 유사하지만, K-NN에서는 아예 다른 사진으로 판단하게 됨
그림에서 보면 1 pixel 만큼 사진을 shift 했을 때, 사람의 눈에는 두 사진이 매우 유사하지만, K-NN에서는 아예 다른 사진으로 판단하게 됨 -
test time에 매우 느리게 작동한다.
train time에는 느리가 작동하는 것이 괜찮지만 test time에서 느리게 작동하는 것은 곤란하다 -
K-NN이 잘 동작하려면 전체 공간을 조밀하게 커버할 만큼의 충분한 트레이닝 샘플이 필요하다
공간을 조밀하게 덮으려면 충분한 양의 학습 데이터가 필요하고 그 양은 차원이 증가함에 따라 기하급수적으로 증가하게 됨 (고차원의 이미지의 경우 모든 공간을 조밀하게 메울 만큼의 데이터를 모으는 일은 현실적으로 불가능)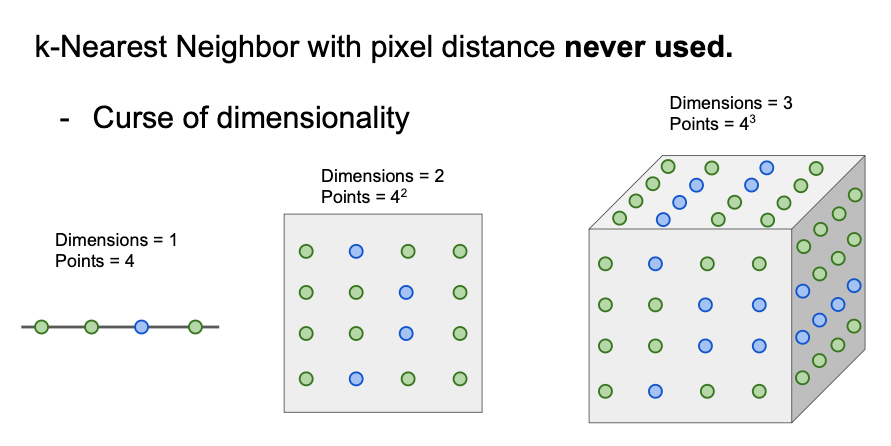
-
차원의 저주(Curse of Dimensionality)
: 데이터의 특징(feature)이 너무나도 많아서 알고리즘 성능 저하가 나타나는 현상
데이터를 학습시키는 근본적인 이유는 데이터 간의 경향성이나 어떤 패턴을 찾아 새로운 데이터에 대해서도 발견한 패턴을 적용하여 예측하기 위함이다. 하지만 data set의 고차원 공간(high-dimensional spaces)를 가지고 있다면 데이터 간 거리가 멀어져 비슷한 특징을 가지는 패턴이나 클러스터를 찾기 더 어려워진다
- K-NN에서 차원이 커지면 생기는 현상
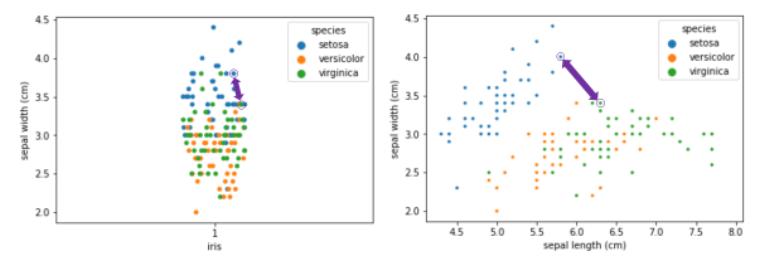
차원이 커지면 근접한 이웃의 거리가 점점 멀어지게 된다. 아래 예시와 같이 ‘Sepal Width’라는 하나의 특성만을 사용하여 분류 예측을 하고자 하면 근처 데이터들이 많아 분류하기가 쉽다. 차원을 하나 더 늘려 ‘Sepal Length’로도 분류를 하게 되면 데이터 간 거리가 점차 생기는 것을 확인할 수 있다.
물론 이와 같은 예시처럼 두 차원만으로 분류하는 것은 큰 문제가 되지 않지만 100차원, 1000차원이 넘는 데이터라면 데이터간의 거리가 상당히 멀어지게 된다. Joel Grus(Data Science from Scratch의 저자)의 말에 따르면 10,000개의 데이터를 대상으로 0차원에서 100차원으로 차원의 수를 늘려가면 두 데이터 간의 거리는 평균적으로 0.8까지 늘어나는 것을 볼 수 있다. 차원이 훨씬 커짐으로써 평균 거리가 1에 가깝게 되면 설명력이 그만큼 떨어지게 된다.
- 차원의 저주를 해결하는 방법
- 더 많은 데이터를 모은다. 차원이 크더라고 엄청난 양의 데이터를 모을 수 있다면 데이터의 밀도가 높아져 특징을 좀 더 잘 설명해줄 수 있게 된다.
- 차원 축소의 방법을 사용 (ex. PCA)
Linear Classifier
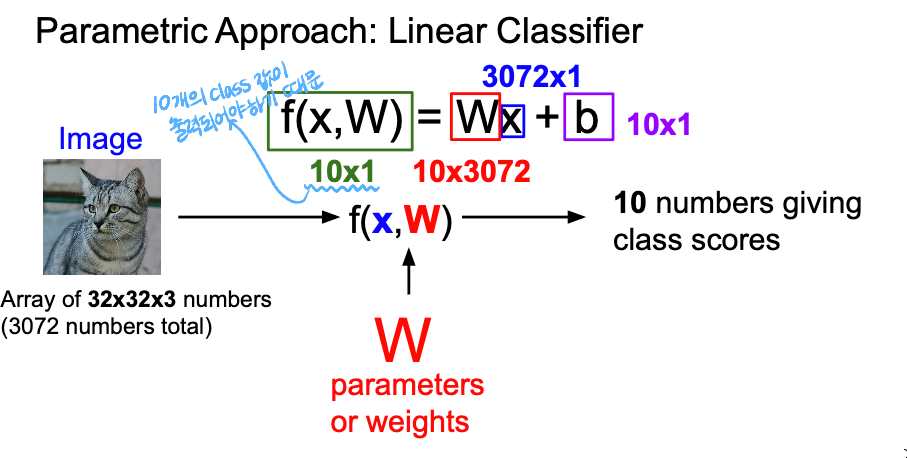 우리가 이전에 배웠던 K-NN 에서는 parameter가 없었는데, 이 경우에서는 W(parameter)가 존재한다.
우리가 이전에 배웠던 K-NN 에서는 parameter가 없었는데, 이 경우에서는 W(parameter)가 존재한다.
여기서 x는 input data, W는 training data의 요약된 정보가 담겨있는 weights를 의미한다. 그리고 출력값으로 10차원짜리 class score vector가 나오게 된다.
 2x2 이미지를 input으로 넣어주고, input을 4차원의 벡터로 flatten 시켜준 뒤 3x4 사이즈의 weight와 곱해주고, bias를 더해주면 3개의 class에 대한 score 값에 해당하는 3차원 벡터가 출력된다.
2x2 이미지를 input으로 넣어주고, input을 4차원의 벡터로 flatten 시켜준 뒤 3x4 사이즈의 weight와 곱해주고, bias를 더해주면 3개의 class에 대한 score 값에 해당하는 3차원 벡터가 출력된다.
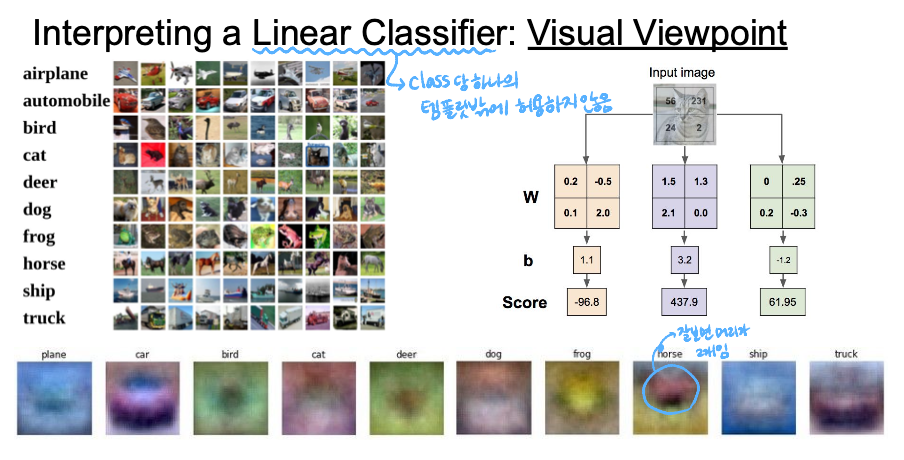 하지만 visual viewpoint의 관점에서 Linear Classifier를 보면 class 당 하나의 템플릿밖에 허용하지 않는다는 문제점이 있다. weight matrix W에서의 각 행이 각각의 class에 대응되는 template이다. 아래 흐릿한 사진들은 CIFAR10을 Wx+b로 학습했을 때의 W값들을 시각화한 것인데, 말의 경우는 머리가 2개인데 이것은 아마 사진을 학습시킬 때 말의 머리 방향이 좌, 우 모두 있었던으로 추정된다.
하지만 visual viewpoint의 관점에서 Linear Classifier를 보면 class 당 하나의 템플릿밖에 허용하지 않는다는 문제점이 있다. weight matrix W에서의 각 행이 각각의 class에 대응되는 template이다. 아래 흐릿한 사진들은 CIFAR10을 Wx+b로 학습했을 때의 W값들을 시각화한 것인데, 말의 경우는 머리가 2개인데 이것은 아마 사진을 학습시킬 때 말의 머리 방향이 좌, 우 모두 있었던으로 추정된다.
이처럼 각각의 class에 대해서 딱 하나의 template만 학습하기 때문에 같은 class 내에서도 variatio이 존재한다면, 모든 variation을 평균을 내버린다. 그렇기 때문에 다양한 케이스에 대해서 모두 학습할 수 없다는 한계점이 있다는 것이다.
