요즘 오픈소스 LLM은 춘추전국 시대를 겪고 있는데요
(Llama, Qwen, Mixtral...)
시중에 사용할 수 있는 대부분의 모델은 한국어 성능이 부족한 이슈가 존재합니다.
이런 한국어 오픈소스 LLM 갈증을 해결해 줄 수도 있는 한국어 성능이 좋은 LLM인 Qwen이 2024년 06월 06일에 발표되었습니다.
해당 모델은 알비바바 Qwen 팀에서 선보인 모델인데요
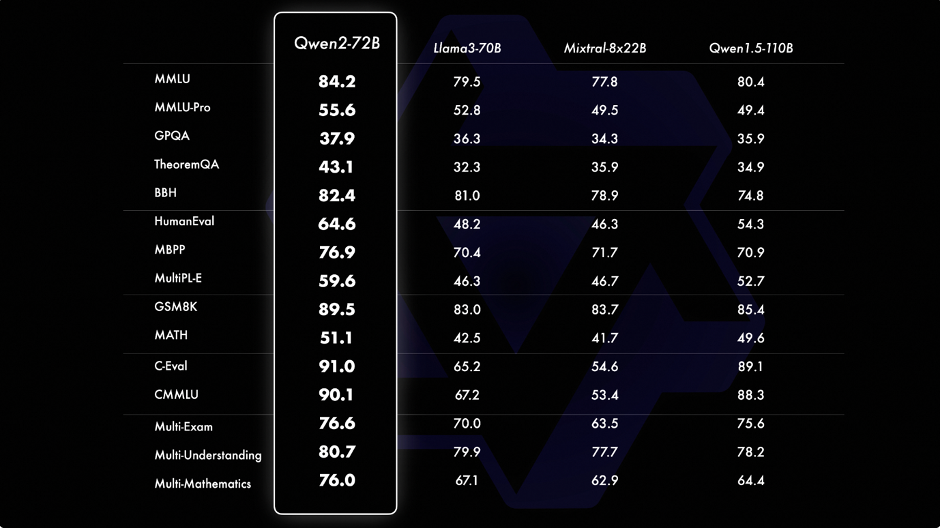
라마3 70B의 성능을 뛰어넘는 성능을 보여주고 있고
Qwen/Qwen2-72B-Instruct, Qwen/Qwen2-7B, Qwen/Qwen2-7B-Instruct-GPTQ-Int8 다양한 형태의 모델을 제공하고 있습니다.
해당 모델에 대한 TECHNICAL REPORT가 24년 7월 15일에 발표되어 한 번 살펴보겠습니다.
Abstract
알리바바는 대형 언어 모델(LLM)인 Qwen2 시리즈를 소개합니다.
해당 모델은 0.5B~72B의 다양한 매개변수를 가지는 모델를 공개합니다.
Qwen2는 다양한 오픈소스 LLM을 성능을 능가하며 선행 모델인 Qwen1.5보다 뛰어난 성능을 보이고 잇습니다.
주요 모델인 Qwen2-72B는
MLU에서 84.2점, GPQA에서 37.9점, HumanEval에서 64.6점, GSM8K에서 89.5점, BBH에서 82.4점을 기록했습니다.
30개 언어에 능숙한 다국어 능력을 보여주며,
영어, 중국어, 스페인어, 프랑스어, 독일어, 아랍어, 러시아어, 한국어, 일본어, 태국어, 베트남어 등 다양한 언어를 지원합니다.
혁신적인 모델 발전을 위해 모델 가중치를 공개하여 다양한 연구 작업을 촉진합니다.
INTRODUCTION
LLM 등장 이후 LLM은 엄청난 관심을 받게 됩니다.
점점 더 많은 경쟁력 있는 LLM이 OPENAI의 GPT 시리즈와 유사한 발전을 추구하고 있습니다.
Qwen, Mistral, Gemma등과 같이 오픈 가중치 방식으로 출시되었습니다.
Qwen은 언어, 비전, 오디오 모델과 같이 다양한 모델을 출시하였고 이번에 최신 Qwen2를 소개합니다.
Qwen2는 Transformer 아키텍처에 기반을 두고 다음 토큰을 예측하는 LLM 시리즈 중 하나입니다.
해당 모델 시리즈는 기본 언어 모델(사람의 선호도에 맞춰지지 않은 사전 학습 모델), instruction-tuned 모델을 출시합니다.
0.5억, 1.5억, 7억, 72억 매개변수를 가진 모델 4가지를 출시하였습니다.
이 중 0.5억, 1.5억 모델은 휴대용 장치에 쉽게 배포할 수 있게 설게되었습니다.
모든 모델은 다양한 도메인과 언어를 포함하는 7조 개 이상의 토큰으로 구성된 고품질 데이터셋에서 사전 학습되었습니다.
이후 훈련에 대해서는 모든 모델은 supervised된 fine-tuning과 DPO를 거쳐 학습함으로써 인간의 선호도에 맞춰져있습니다.
오픈, 독점 모델을 포함한 다양한 모델들과 비교분석을 수행하였습니다.
다양한 벤치마크에서 Qwen2는 경쟁 모델을 능가하는 것을 확인했습니다.
TOKENIZER & MODEL
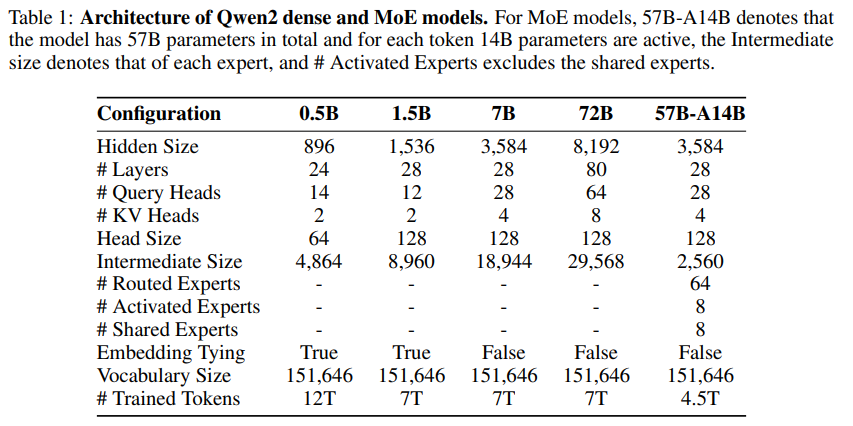
Qwen2의 토크나이저와 모델 설계를 소개합니다.
TOKENIZER
byte-level bytepair encoding 기반한 Qwen과 동일한 토큰나이저를 사용합니다.
해당 토큰나이저는 높은 압축률을 보여주어 높은 인코딩 효율성을 나타내면 다국어 기능을 향상시킵니다.
모든 크기의 모델은 151,643개의 일반 토큰과 3개의 제어 토큰으로 구성된 공통 어휘를 사용합니다.
MODEL ARCHITECTURE
Transformer 아키텍처에 기반한 대형 언어 모델로 self-attention with causal masks를 사용합니다.
이 시리즈는 4가지 규모의 밀집 언어 모델과 전문가 혼합(MoE) 모델을 포함합니다.
QWEN2 DENSE MODEL
multiple Transformer layers, each equipped with causal attention mechanisms and feed-forward neural networks (FFNs)
Qwen과 주요 차이점
- Grouped Query Attention (GQA): multi-head attention (MHA) 대신 라마2에 적용한 Grouped Query Attention (GQA)를 채택하여 추론 중 KV 캐시 사용을 최적화하고 처리량을 크게 향상시켰습니다.
- Dual Chunk Attention with YARN: 긴컨텍스트 창을 확장하기 위해 긴 시퀀스를 관리 가능한 길이로 나누는 DCA를 적용했습니다. 입력이 청크로 처리될 수 있는 경우 DCA는 원래의 어텐션과 동일한 결과를 산출합니다. 반대의 경우 DCA는 청크 내 및 청크 간의 토큰 간 상대적 위치 정보를 효과적으로 캡처하여 긴 컨텍스트 성능을 향상시킵니다, YARN을 사용하여 어텐션 가중치를 재종하여 더 나은 길이 외삽을 구현합니다.
- 기타 기술: 활성화 함수로 SwiGLU, 위치 임베딩으로 Rotary Positional Embeddings, 어텐션을 위해 QKV bias, 훈련 안정성을 위해 RMSNorm과 사전 정규화를 사용합니다.
QWEN2 MIXTURE-OF-EXPERTS MODEL
Qwen2 MoE 모델은 FFN 대신, MoE FFN은 각각 전문가로 역할하는 개별 FFNs로 구성됩니다.
- Expert Granularity: MoE 모델과 밀집 모델의 주요 구조적 차이점은 MoE 레이어가 각각 전문가로 역할하는 여러 FFNs를 포함한다는 것입니다. 예를 들어, Mistral-7B에서 Mixtral 8x7B로 전환할 때 8명의 전문가 중 두 명을 동시에 활성화합니다. 해당 방법은 더 많은 전문가를 동시에 활성화하면서 소규모 전문가를 생성하는 세밀한 전문가를 사용합니다.
- Expert Routing: 각 토큰을 생성할때 상황에 맞게 가변적으로 expert의 수를 결정하고, 계산해서 가져오는 방법을 적용합니다.
- Expert Initialization: 전문가 초기화는 업사이클링 방식과 유사하게, 밀집 모델의 가중치를 활용하여 이루어집니다. 이 과정은 전문가 초기화에 추가적인 확률성을 도입하여, 훈련 중 모델의 탐색 능력을 잠재적으로 향상시킬 수 있습니다.
PRE-TRAINING
Qwen2의 사전 훈련에서는 데이터셋을 정제하고 확장된 컨텍스트 길이를 효과적으로 처리하는 방법 개선을 중점으로 두었습니다.
PRE-TRAINING DATA
고품질 데이터셋 구축, 필터링 알고리즘, 30개 언어 지원, 다양한 출처와 도메인 데이터셋을 학습에 사용했습니다.
기존 3조 개의 토큰에서 7조 개의 토큰으로 확장되었습니다.
이 과정에서 12조 개의 토큰 데이터셋을 사용했지만 7조 개의 토근과 비교하여 모델 성능 향상이 눈에 띄지 않았습니다.
이에 따라 훈련 비용을 고려하여 7조 개의 토큰 데이터셋을 사용했습니다.
LONG-CONTEXT TRAINING
Qwen2의 긴 컨텍스트 처리 능력을 향상시키기 위해 컨텍스트 길이를 4,096 토큰에서 32,768 토큰으로 확장했습니다.
모델의 길이 외삽 잠재력을 최대한 활용하기 위해, 우리는 YARN 메커니즘과 Dual Chunk Attention 메커니즘을 채택했습니다.
POST-TRAINING
대규모 사전 훈련 후, 우리는 Qwen2의 사후 학습 단계를 진행합니다.
다른 모델들이 supervised 학습에 크게 의존하는 것과 달리 최소한의 인간 주석으로 확장 가능한 학습에 중점을 둡니다.
SFT, RLHDF을 위해 고품질의 데모 및 선호 데이터 획득 방법을 조사하여 인간 레이블링의 필요성을 최소화하면서 품질과 신뢰성을 극대화하는 것을 목표로 합니다.
포스트 트레이닝 데이터는 주로 두 가지 구성 요소로 구성됩니다:
데모 데이터 D = {(xi, yi)}와 선호 데이터 P = {(xi, y+i, y−i)}
여기서 xi는 명령어를 나타내고, yi는 만족스러운 응답을 나타내며, y+i와 y−i는 xi에 대한 두 개의 응답으로, y+i가 y−i보다 선호되는 선택입니다.
Evaluation
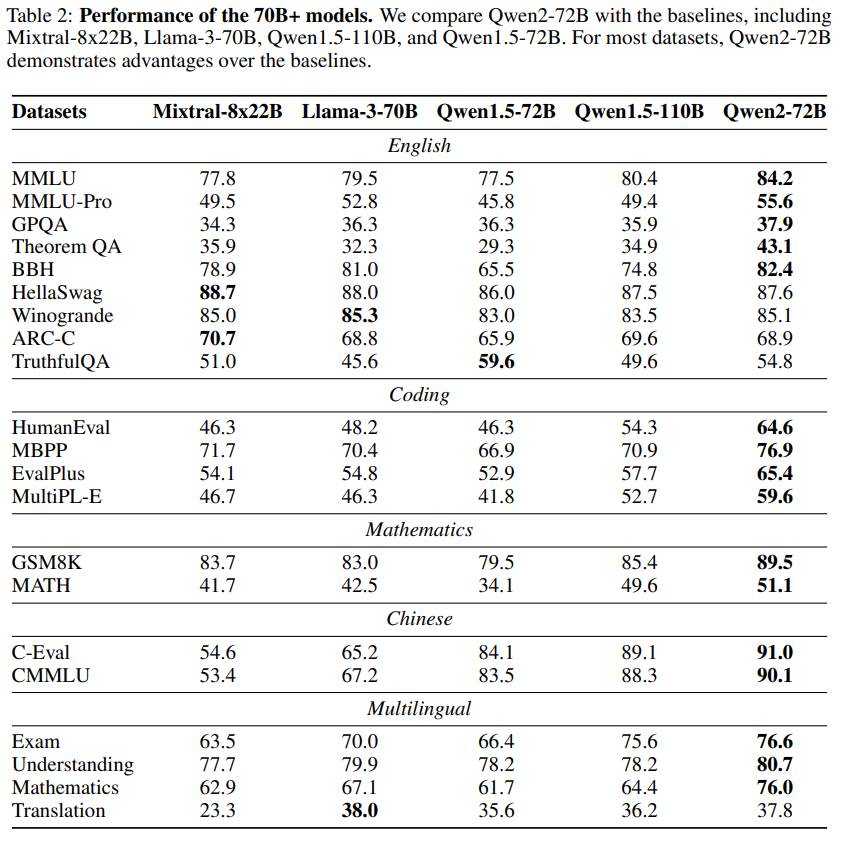
위의 표에서 알 수 있듯이 대부분의 성능이 다른 오픈 LLM과 비교하여 더 좋은 성능을 보이는 것을 확인할 수 있습니다.
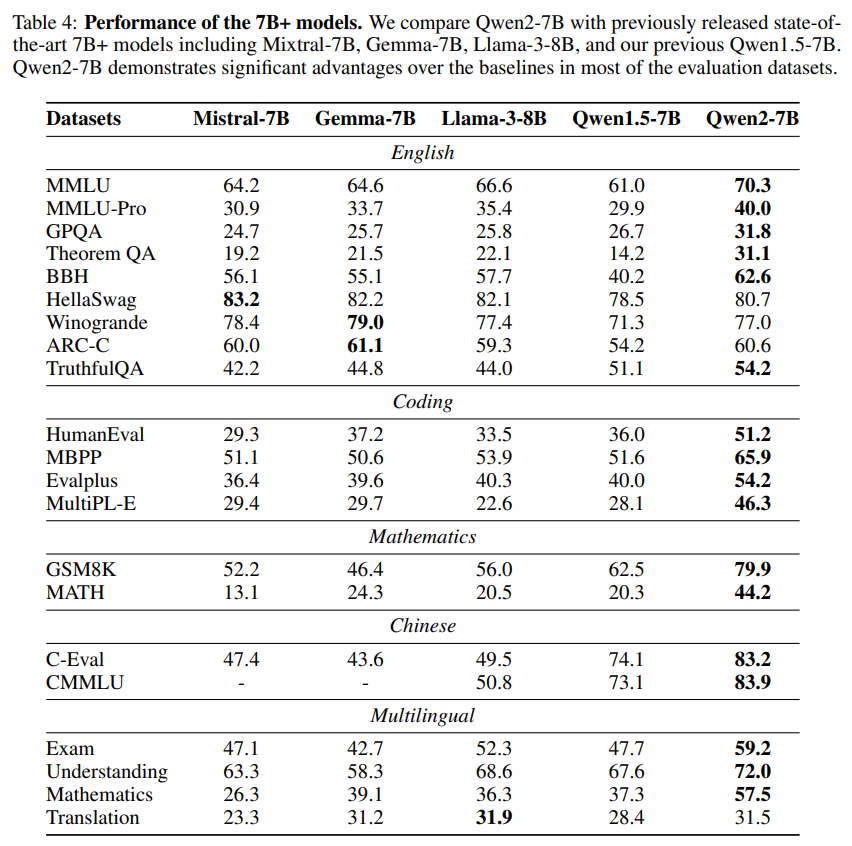
작은 모델의 경우도 마찬가지로 시중의 오픈 LLM과 비교하여도 높은 성능을 보이고 있습니다.
SAFETY & RESPONSIBILITY
공개적으로 접근 가능한 가중치를 가진 LLM은 연구와 발전에 기여합니다.
또한 AI 기술의 오용을 막기 위해서는 안전하고 책임 있는 LLM을 구축하는 것이 중요합니다.
다국어 안전 평가를 통해 다양한 언어에서 LLM의 안전 성능을 테스트합니다.
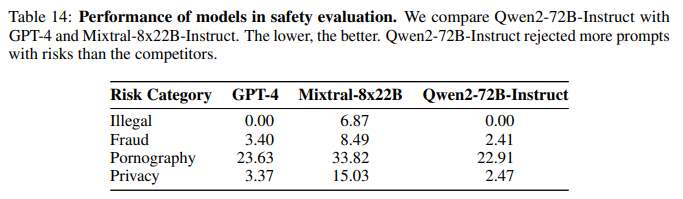
위의 표에서 볼 수 있듯이 GPT4와 비교하여도 더욱 안전한 응답을 보여주는 것을 확인할 수 있습니다.
실제 실사용에서도 Qwen 보안 가이드라인이 다른 오픈 LLM과 비교하여도 더 좋은 보안을 가지고 있는 것을 확인할 수 있습니다.
Conclusion
Qwen2는 다양한 매개변수를 가진 LLM 가중치를 공개하였습니다.
다양한 모델들은 Qwen1.5, 다른 오픈 LLM과 비교하여도 높은 성능을 확인할 수 있습니다.
언어 이해, 생성, 다국어 능력, 코딩, 수학, 추론 등의 다양한 벤치마크에서 독점 모델들과 경쟁력 있는 성능을 보입니다.
