1. 라이브러리 및 데이터
Library & Data
import pandas as pd # 판다스 패키지 불러오기 from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 모델 불러오기 from sklearn.tree import DecisionTreeClassifier # 의사결정 나무 모델 불러오기
pd.read_csv()
- csv 파일 읽는 함수
# 데이터 불러오기 train = pd.read_csv('/content/drive/MyDrive/타이타닉/train.csv') # 모델 학습 파일 test = pd.read_csv('/content/drive/MyDrive/타이타닉/test.csv') # 모델 시험지 파일 submission = pd.read_csv('/content/drive/MyDrive/타이타닉/submission.csv') # 답안지 파일
2. 탐색적 자료분석 (EDA)
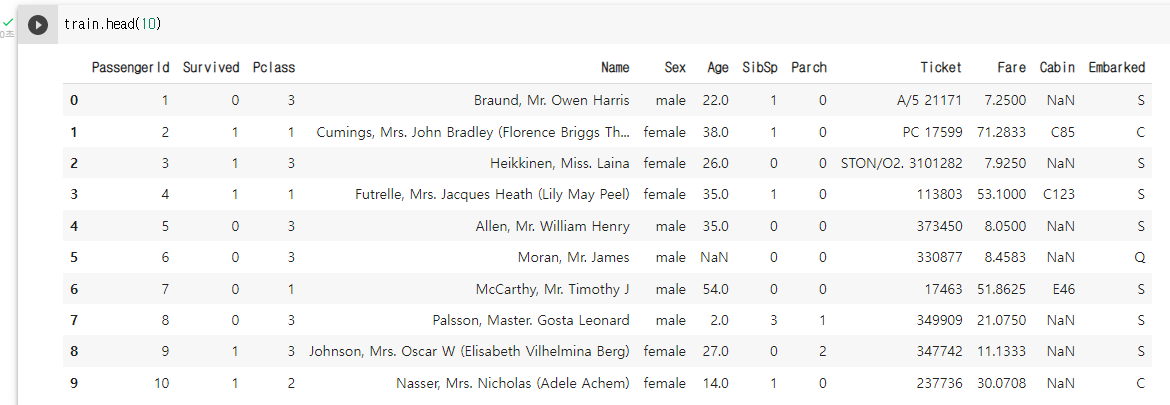
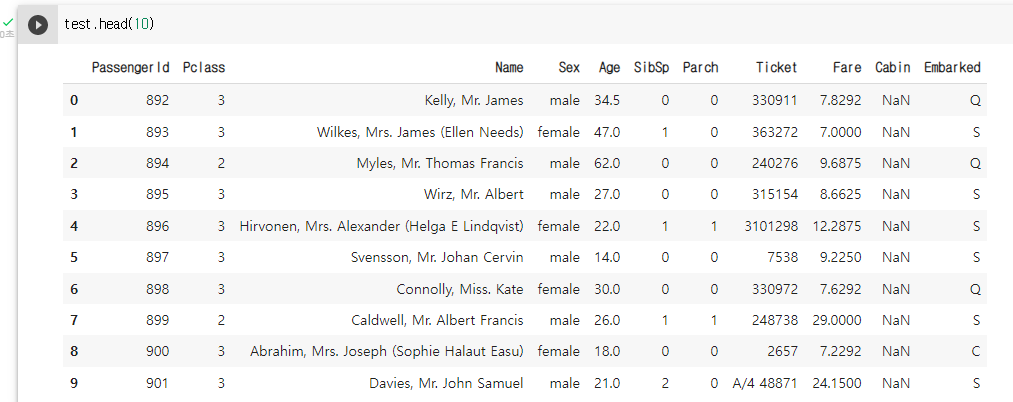
pd.DataFrame.head()
- 데이터 프레임의 위에서 부터 n개 행을 보여주는 함수
- n의 기본 값(default 값)은 5
# 상위 10개 행 train 데이터 확인 train.head(10)
# 상위 10개 행 test 데이터 확인 test.head(10)
train.data를 활용해서 생존유무 판별한 모델을 만들고, test.data에 저장되어 있는 탑승객들에 대한 생존유무를 예측해야 하는 것이기 때문에 Survived column이 제공되지 않음.
- passengerId : 탑승객의 고유 아이디
- Survival : 생존여부(0: 사망, 1: 생존)
- Pclass : 등실의 등급
- Name : 이름
- Sex : 성별
- Age : 나이
- Sibsp : 함께 탑승한 형제자매, 아내 남편의 수
- Parch : 함께 탑승한 부모, 자식의 수
- Ticket : 티켓번호
- Fare : 티켓의 요금
- Cabin : 객실번호
- Embarked : 배에 탑승한 위치(C=Cherbourg, Q=Queenstown, S=Southampton)
pd.DataFrame.tail()
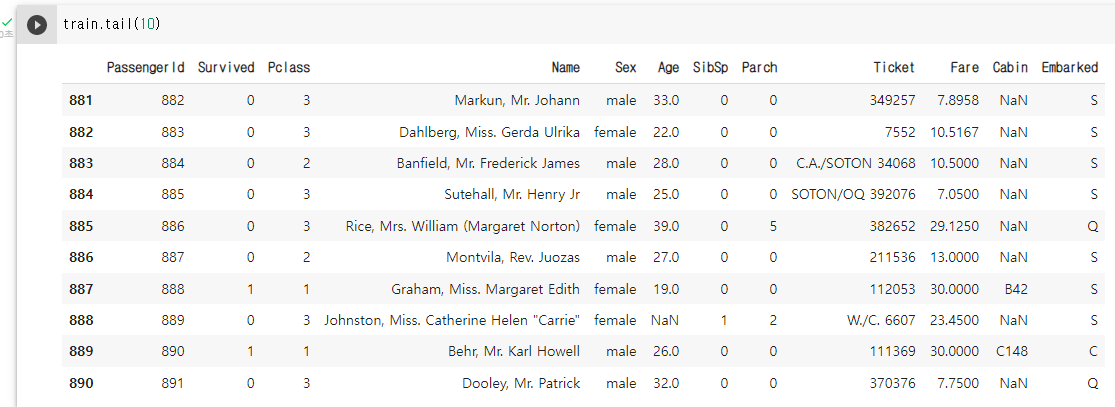
- 데이터 프레임의 아래에서 부터 n개 행을 보여주는 함수
- n의 기본 값(default 값)은 5
# 하위 10개 행 train 데이터 확인 train.tail(10)
pd.DataFrame.shape
- 데이터 프레임의 행의 개수와 열의 개수가 저장되어 있는 속성(attribute)
# train 데이터의 행, 열 개수 확인 train.shape # (891, 12)# test 데이터의 행, 열 개수 확인 test.shape # (418, 11)# submission 데이터의 행, 열 개수 확인 submission.shape # (418, 2)
pd.DataFrame.info()
- 데이터셋의 column별 정보를 알려주는 함수
- 비어 있지 않은 값은 (non-null)은 몇개인지?
- column의 type은 무엇인지?
- type의 종류 : int(정수), float(실수), object(문자열), 등등 (date, ...)
# train 데이터셋의 column별 정보 확인 train.info()# train.info() 결과 <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB# test 데이터셋의 column별 정보 확인 test.info()# test.info() 결과 <class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 418 non-null int64 1 Pclass 418 non-null int64 2 Name 418 non-null object 3 Sex 418 non-null object 4 Age 332 non-null float64 5 SibSp 418 non-null int64 6 Parch 418 non-null int64 7 Ticket 418 non-null object 8 Fare 417 non-null float64 9 Cabin 91 non-null object 10 Embarked 418 non-null object dtypes: float64(2), int64(4), object(5) memory usage: 36.0+ KB
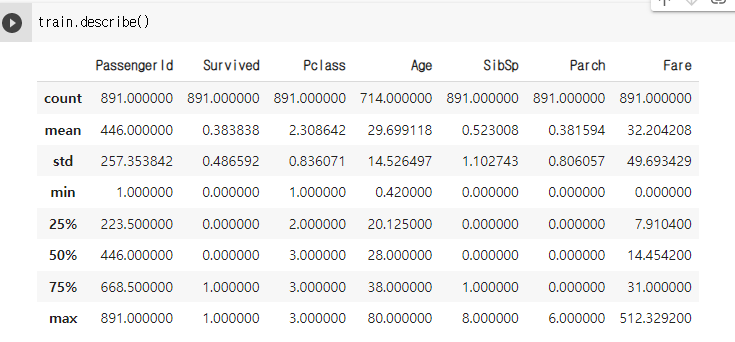
pd.DataFrame.describe()
- 숫자형 (int, float) column들의 기술 통계량을 보여주는 함수
- 기술통계량이란?
- 해당 column을 대표할 수 있는 통계값들을 의미
- 기술통계량 종류
- count: 해당 column에서 비어 있지 않은 값의 개수
- mean: 평균
- std: 표준편차
- min: 최솟값 (이상치 포함)
- 25% (Q1): 전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 1/4번째 지점에 있는 값
- 50% (Q2): 중앙값 (전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 2/4번째 지점에 있는 값)
- 75% (Q3): 전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 3/4번째 지점에 있는 값
- max: 최댓값 (이상치 포함)
- 이상치: 울타리 밖에 있는 부분을 이상치라고 정의함
- 아래쪽 울타리: Q_1Q1 - 1.5 * IQR1.5 ∗ IQR
- 위쪽 울타리: Q_3Q3 + 1.5 * IQR1.5 ∗ IQR
- IQRIQR = Q_3 - Q_1Q3 − Q1
# 숫자형 (int, float) column들의 기술 통계량 확인 train.describe()
pd.Series.value_counts()
- series 내 고유값들 각각의 개수를 보여주는 함수
- 가장 많이 나오는 고유값들 순서로 보여줍니다.
- 비어 있는 값은 고려하지 않습니다.
# Sex 개수 train['Sex'].value_counts()# train['Sex'].value_counts() 결과 male 577 female 314 Name: Sex, dtype: int64# Embarked 개수 train['Embarked'].value_counts()# train['Embarked'].value_counts() 결과 S 644 C 168 Q 77 Name: Embarked, dtype: int64
pd.Series.unique()
- 해당 series의 고유값들만 보여주는 함수
- [1, 1, 1, 3] 이라는 시리즈가 있다면, unique() 함수 적용시 [1, 3]이 출력됩니다.
- nan 값이 있을시 nan값도 포함하여 출력한다 (Not a Number)
- 출현하는 순서대로 나오기 때문에, 알파벳 순서 또는 오름차순으로 정렬되어 있지 않습니다.
train['Embarked'].unique()# 실행 결과 array(['S', 'C', 'Q', nan], dtype=object)train['Pclass'].unique()# 실행 결과 array([3, 1, 2])
pd.DataFrame.groupby()
- 집단에 대한 통계량 확인
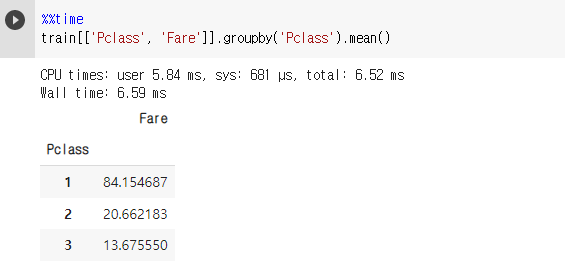
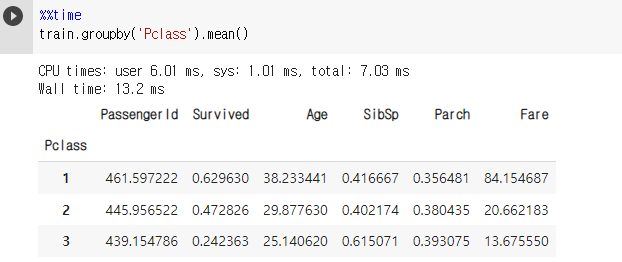
%%time train[['Pclass', 'Fare']].groupby('Pclass').mean()
%%time train.groupby('Pclass').mean()
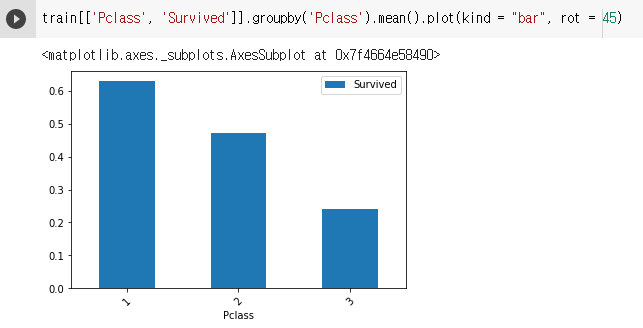
pd.Series.plot(kind = "bar")
- 막대 그래프
- index 값이 x축, value값이 y축으로 대응 됩니다.
- value_counts()의 결과물을 보여줄 때 유용합니다.
- groupby된 결과물을 보여줄 때 유용합니다.
train[['Pclass', 'Survived']].groupby('Pclass').mean().plot(kind = "bar", rot = 45)
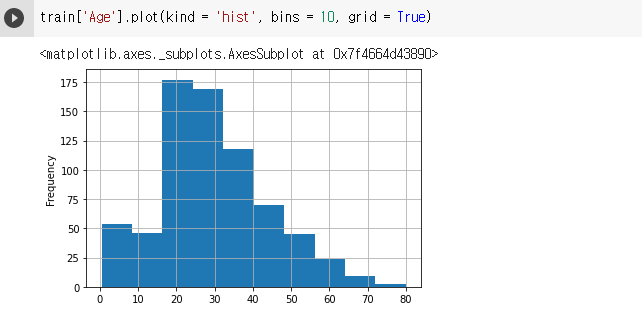
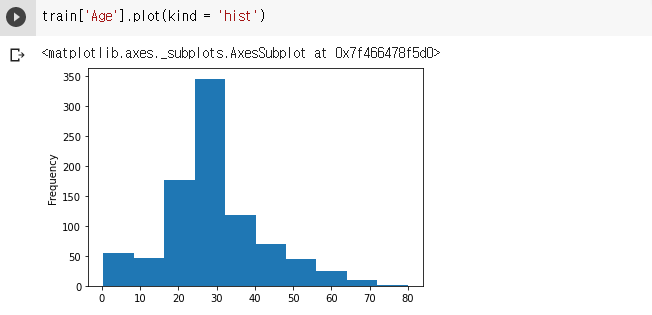
pd.Series.plot(kind = 'hist')
- 히스토그램: 구간별로 속해있는 row의 개수를 시각화 합니다.
- 수치형에서만 가능, 범주는 안됨
train['SibSp'].unique()# 실행 결과 array([1, 0, 3, 4, 2, 5, 8])
- 보조선은 grid = True를 통해 추가 할 수 있습니다.
train['Age'].plot(kind = 'hist', bins = 10, grid = True)
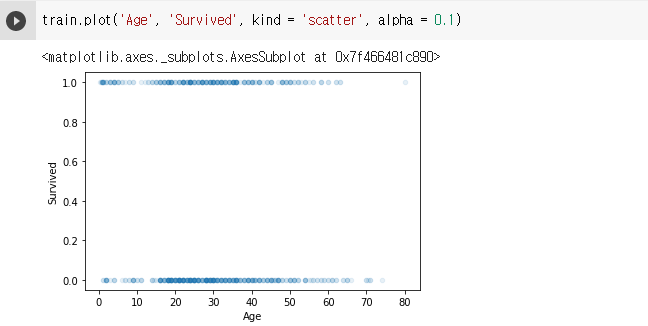
pd.DataFrame.plot(x, y, kind = 'scatter')
- 산점도: 두 변수간의 관계를 시각화
train.plot('Age', 'Survived', kind = 'scatter', alpha = 0.1)
3. 데이터 전처리
pd.Series.isna()
- 결측치 여부를 확인해줍니다.
- 결측치면 True, 아니면 False
# train data 결측치 여부 확인 train.isna().sum() / 891PassengerId 0.000000 Survived 0.000000 Pclass 0.000000 Name 0.000000 Sex 0.000000 Age 0.198653 SibSp 0.000000 Parch 0.000000 Ticket 0.000000 Fare 0.000000 Cabin 0.771044 Embarked 0.002245 dtype: float64train['Age'].mean()# 실행 결과 29.69911764705882train['Embarked'].value_counts()# train['Embarked'].value_counts() 실행 결과 S 644 C 168 Q 77 Name: Embarked, dtype: int64
pd.DataFrame.fillna()
- 결측치를 채우고자 하는 column과 결측치를 대신하여 넣고자 하는 값을 명시해주어야 합니다.
- 범주형 변수일 경우, 최빈값으로 대체할 수 있습니다.
# train data의 Age 결측치 대체 train['Age'] = train['Age'].fillna(value = train['Age'].mean()) train['Age'].isna().sum()0# train data의 Embarked 결측치 대체 train['Embarked'].fillna(value = 'S', inplace = True) train['Embarked'].isna().sum()0train.isna().sum()# 실행 결과 PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 0 dtype: int64# test data의 Age 결측치 대체 test['Age'].fillna(value = train['Age'].mean(), inplace = True) test.isna().sum()# 실행 결과 PassengerId 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 327 Embarked 0 dtype: int64train['Age'].plot(kind = 'hist')
pd.Series.map()
- 시리즈 내 값을 변환 할 때 사용하는 함수
train['Sex'] = train['Sex'].map({'male':0, 'female':1})
4. 변수 선택 및 모델 구축
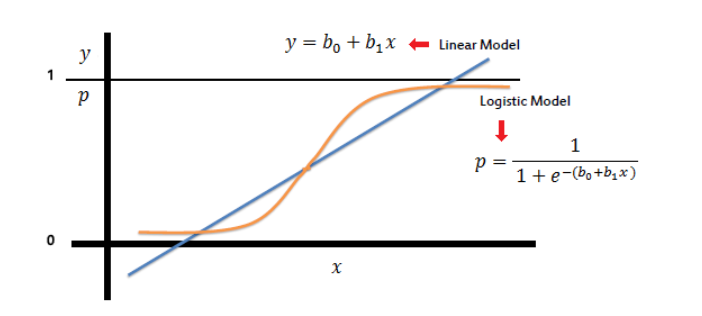
sklearn.linear_model.LogisticRegression()
- 로지스틱 회귀 모형
- 0과 1사이의 값을 산출
- 로지스틱 함수를 통해 0과 1사이의 값을 산출하여, 탑승객의 생존 여부를 파악해봅시다.
X_train = train[['Pclass', 'Age']] y_train = train['Survived'] X_test = test[['Pclass', 'Age']]from sklearn.linear_model import LogisticRegression model = LogisticRegression()# 로지스틱 함수를 통해 0과 1사이의 값을 산출 model.fit(X_train, y_train)# 생존 여부 예측 값 y_pred = model.predict(X_test)submission['Survived'] = y_pred# 생존 여부 예측 값 csv 파일로 변환 submission.to_csv('lr_model_Pclass_Age.csv', index = False)
sklearn.tree.DecisionTreeClassifier()
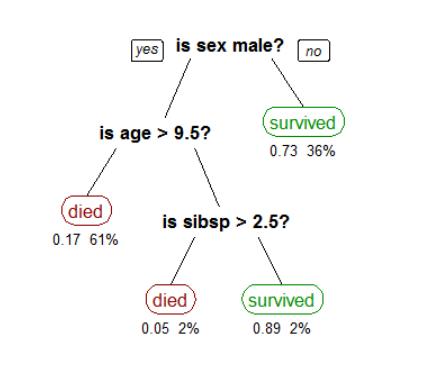
- 의사결정 나무 모델
- 특징변수들로부터 타깃변수를 맞추기 위해 경우를 쪼개나가는 알고리즘입니다.
- (예) 과일이 사과, 딸기, 포도 중 무엇인지 맞추려합니다
- 주어진 특징은 과일 1개의 가로최대길이, 세로최대길이, 과일의색상이라고 합시다
- 사과를 맞추기 위해서 10~13cm의 가로, 세로 최대길이와 빨간색의 과일을 탐색하게 되겠죠
- 위의 '길이가 10~13cm인가? 아닌가?', '색깔이 빨간색인가? 아닌가?'의 기준이 경우를 쪼개나가는 기준이 됩니다.
- 주어진 데이터와 연결지어 생각해봅시다.
from sklearn.tree import DecisionTreeClassifier dt_model = DecisionTreeClassifier()# 의사결정 나무 모델 dt_model.fit(X_train, y_train)submission['Survived'] = dt_model.predict(X_test)submission.to_csv('dt_model.csv', index = False)
5. 모델 학습 및 검증
model.fit()
- 모델 학습
model.predict()
- 모델 예측
model.predict_proba()
- 모델 예측
submission['Survived'] = model.predict_proba(X_test)[:,1]submission.to_csv('lr_proba.csv', index = False)submission['Survived'] = dt_model.predict_proba(X_test)[:,1]submission.to_csv('dt_proba.csv', index = False)DecisionTreeClassifier()dt_model_new = DecisionTreeClassifier(min_samples_split=10)dt_model_new.fit(X_train, y_train)
submission['Survived'] = dt_model_new.predict_proba(X_test)[:, 1]submission.to_csv('dt_min_samples_10_proba.csv', index = False)train
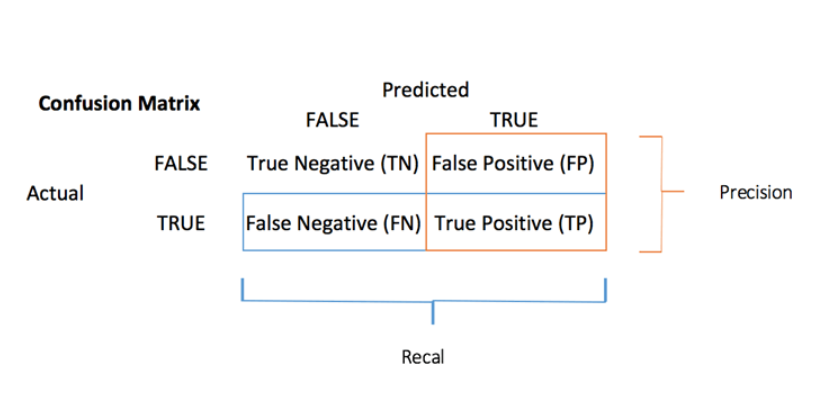
from sklearn.metrics import confusion_matrix, classification_report from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import accuracy_score from sklearn.metrics import roc_auc_scoreX_train = train[['Pclass', 'Age']] y_train = train['Survived'] X_test = test[['Pclass', 'Age']]model = LogisticRegression() model.fit(X_train, y_train) y_pred = model.predict(X_train)y_true = y_train.valuescf_matrix = confusion_matrix(y_true, y_pred)cf_matrix
accuracy_score(y_true, y_pred)# 실행 결과 0.7025813692480359(cf_matrix[0,0] + cf_matrix[1,1]) / 891# 실행 결과 0.7025813692480359precision_score(y_true, y_pred)# 실행 결과 0.6584362139917695(cf_matrix[1,1]) / (83 + 160)# 실행 결과 0.6584362139917695recall_bscore(y_true, y_pred)# 실행 결과 0.4678362573099415(cf_matrix[1,1]) / (182 + 160)# 실행 결과 0.4678362573099415print(classification_report(y_true, y_pred))# 실행 결과 precision recall f1-score support 0 0.72 0.85 0.78 549 1 0.66 0.47 0.55 342 accuracy 0.70 891 macro avg 0.69 0.66 0.66 891 weighted avg 0.70 0.70 0.69 891
- 데이콘 채점 기준은 auc 라는 지표를 사용합니다.
- auc값을 측정하기 위해서는, 예측을 확률값으로 해주어야 합니다.
- 그 중에서 1에 속할 확률을 선택해주어야 합니다.
roc_auc_score(y_true, y_pred)# 실행 결과 0.6583261432269197


pd.DataFrame.to_csv()
- csv파일 저장하는 함수
6. 결과 및 결언
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import KFold from sklearn.metrics import roc_auc_score# 데이터 불러오기 train = pd.read_csv('data/train.csv')# 모델 학습 파일 test = pd.read_csv('data/test.csv')# 모델 시험지 파일 submission = pd.read_csv('data/submission.csv') #답안지 파일model_10 = DecisionTreeClassifier(min_samples_split=10) model_20 = DecisionTreeClassifier(min_samples_split=20) model_30 = DecisionTreeClassifier(min_samples_split=30)kfold = KFold(n_splits=5, shuffle=True, random_state=10)train['Age'] = train['Age'].fillna(value = train['Age'].mean()) test['Age'] = test['Age'].fillna(value = train['Age'].mean())X_train = train[['Pclass', 'Age']] y_train = train['Survived']score_10 = [] for trn_idx, val_idx in kfold.split(X_train): X_trn, y_trn = X_train.iloc[trn_idx, :], y_train.iloc[trn_idx] X_val, y_val = X_train.iloc[val_idx, :], y_train.iloc[val_idx] model_10.fit(X_trn, y_trn) y_pred = model_10.predict_proba(X_val)[:, 1] print('예측 완료') score_10.append(roc_auc_score(y_val.values, y_pred))# 실행 결과 예측 완료 예측 완료 예측 완료 예측 완료 예측 완료score_10# 실행 결과 [0.6625999448580093, 0.6935200216450217, 0.6567085953878408, 0.5899470899470899, 0.7008647798742138]score_20 = [] for trn_idx, val_idx in kfold.split(X_train): X_trn, y_trn = X_train.iloc[trn_idx, :], y_train.iloc[trn_idx] X_val, y_val = X_train.iloc[val_idx, :], y_train.iloc[val_idx] model_20.fit(X_trn, y_trn) y_pred = model_20.predict_proba(X_val)[:, 1] print('예측 완료') score_20.append(roc_auc_score(y_val.values, y_pred))# 실행 결과 예측 완료 예측 완료 예측 완료 예측 완료 예측 완료score_20# 실행 결과 [0.6765922249793217, 0.697443181818182, 0.658149895178197, 0.5986111111111111, 0.6964098532494759]score_30 = [] for trn_idx, val_idx in kfold.split(X_train): X_trn, y_trn = X_train.iloc[trn_idx, :], y_train.iloc[trn_idx] X_val, y_val = X_train.iloc[val_idx, :], y_train.iloc[val_idx] model_30.fit(X_trn, y_trn) y_pred = model_30.predict_proba(X_val)[:, 1] print('예측 완료') score_30.append(roc_auc_score(y_val.values, y_pred))# 실행 결과``` 코드를 입력하세요예측 완료
예측 완료
예측 완료
예측 완료
예측 완료```python score_30# 실행 결과 [0.7031982354562999, 0.713474025974026, 0.6565120545073374, 0.6110449735449734, 0.7037473794549267]import numpy as npnp.mean(score_10), np.mean(score_20), np.mean(score_30)# 실행 결과 (0.6607280863424351, 0.6654412532672576, 0.6775953337875128)DecisionTreeClassifier()
