Schema & Query Design
What is a schema?
스키마는 데이터베이스에서 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계에 대한 설명입니다.
Q. 근데 엔티티가 머임? => 고유한 정보의 단위.
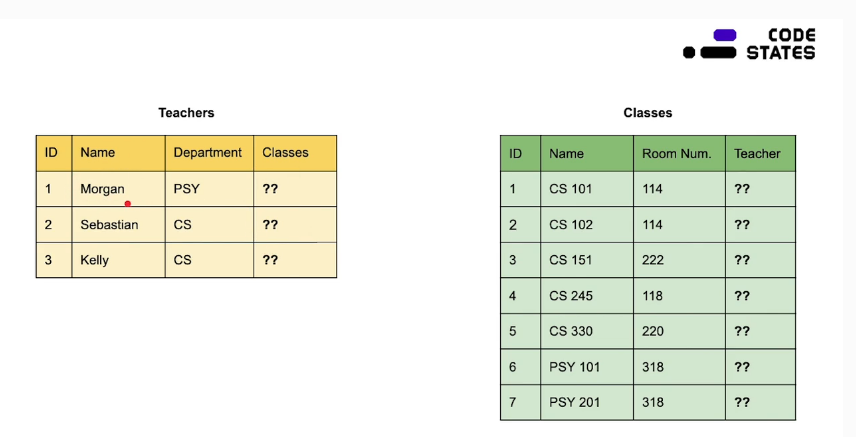
위 그림에서 Teachers과 Calsses의 관계를 서술할건데..
- Teachers에서 교수님들이 맡고있는 Classes들을 나열하는 방법!
근데 문제가... 만약에 Classes의 강의 이름(PSY 101)이 바뀌면 Teachers의 클래스 이름이 다 바뀜!
그래서 Classes의 name 보다는 ClassID 를 써주면 되지 않을까?
그럼 문제는... 한 교수님이 담당해야할 Max 클래스 개수를 모르면 어떻게 될까?
-
열의 크기는 고정이기 때문에 수업 ID를 담을 공간이 부족할 수 있음!
-
한 열에 여러 값을 저장하면(6, 7, 9,...) 하면 검색할때 복잡도 업!
아니 그러면 ClassID를 하나씩만 적으면 안되나?
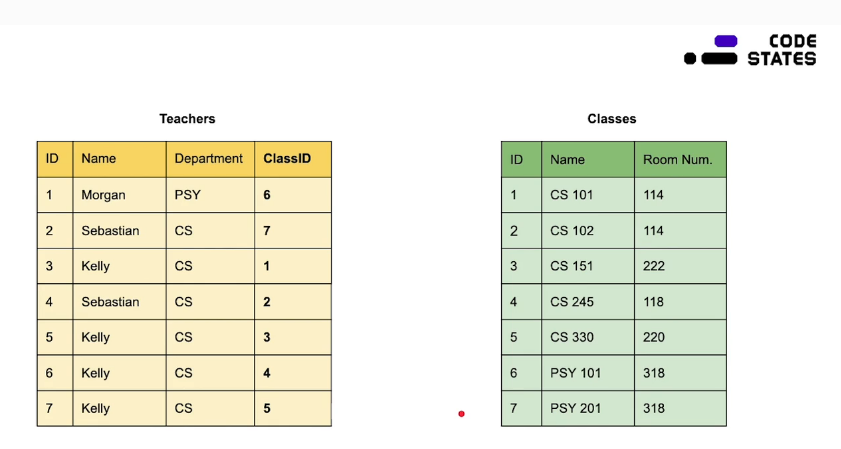
- 반대로 Classes아이디에 TeacherID를 넣으면 안되나?
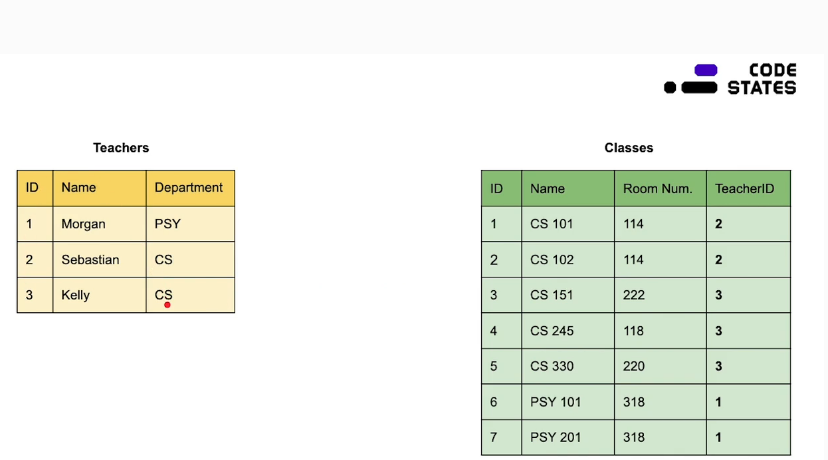
좋네.. 1대(교수) 다(학생)을 표현할때는 이게 훨 낫네!
그러면 다 대 다 방식은 ??
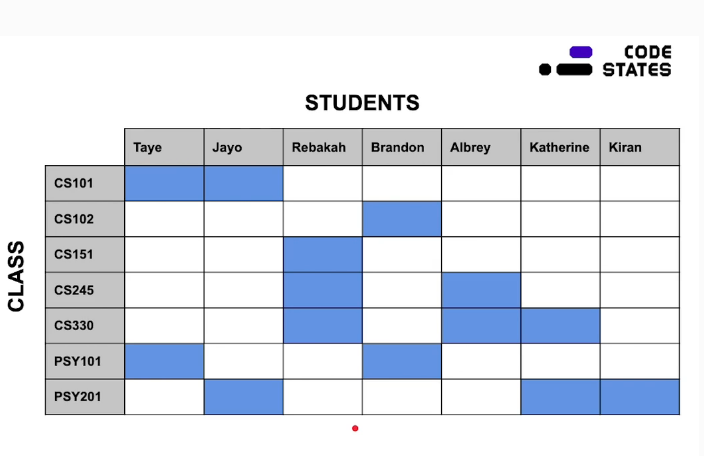
좌표계 처럼!
데이터베이스 설계
관계형 데이터베이스
구조화된 데이터는 하나의 테이블로 표현 가능
사전에 정의된 테이블을 relation이라 부름.
그래서 테이블을 사용하는 데이터베이스를 => 관계형 데이터베이스 라고 부름!
밑에는 반드시 알고 있어야 하는 키워드
-
데이터 : 각 항목에 저장되는 값
-
테이블 : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적됨.
-
칼럼 : 테이블의 한 열을 가리킴
-
레코드 : 테이블의 한 행에 저장된 데이터
-
키 : 테이블의 각 레코드를 구분할 수 있는 값. 각 레코드마다 고유한 값을 가지는데
기본키와 외래키등이 있음.
기본키 : 테이블에 저장된 각각의 레코드를 유일하게 구분하는 키
외래키 : 각 테이블간의 연결을 만들기 위해서 다른 테이블에 참조되는 키
관계 종류
1:1 관계
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우!
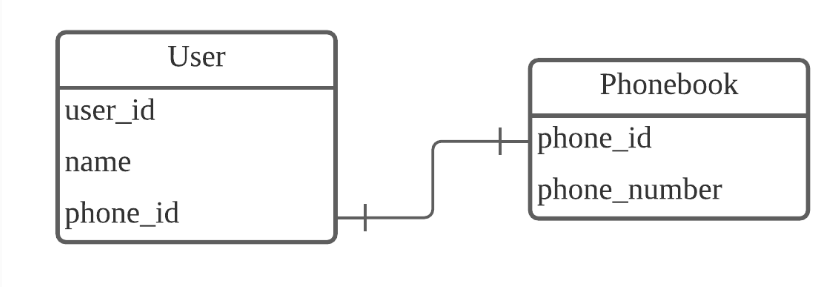
User 테이블에서 phone_id는 외래키임. ㅇㅇ 왜냐면 Phonebook의 phone_id과 연결되어있음!
각 전화번호가 단 한 명의 유저와 연결되어 있고, 그 반대도 동일하다면,
User 테이블과 Phonebook 테이블은 1:1 관계
근데 잘 사용하지는 않음. 1:1로 나타낼 수 있는관계면 User테이블에 phone_id말고 걍 phone_number를 쓰는게 나음.
1:N 관계
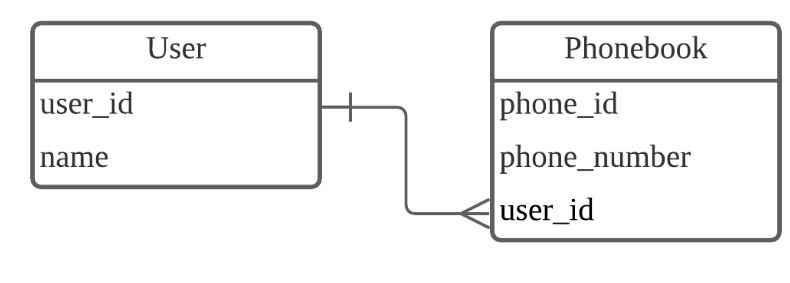
이 구조에서는 한 명의 유저가 여러 전화번호를 가질 수 있으나 여러 명의 유저가 하나의 전화번호를 가지지는 못함!
관계형 데이터베이스에서 가장가장 많이 사용!
N:N 관계
다대다 관계를 위해 스키마를 디자인할때에는, Join 테이블을 만들어 관리함!
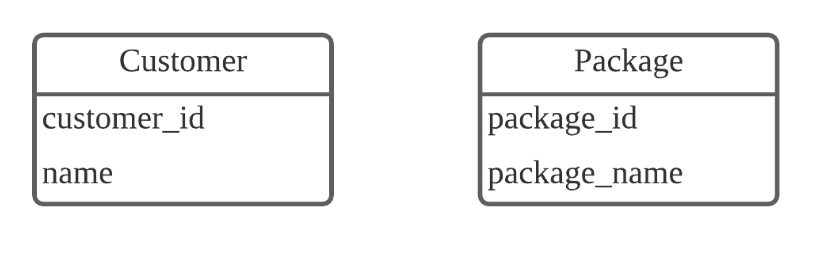
이렇게 되어있을때
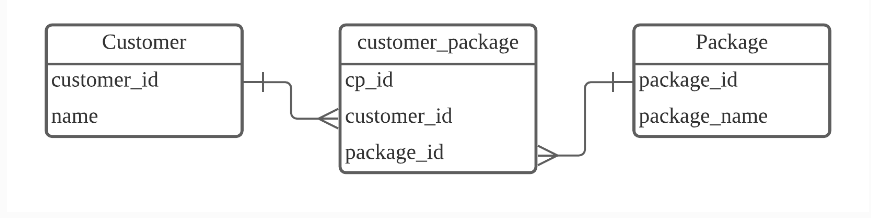
가운데 customer_package가 Join 테이블!
customer_package 테이블에서는 고객 한 명이 여러 개의 여행 상품을 가질 수 있고
여행 상품 하나를 여러 명의 고객이 가질 수 있음!
그러면 Join 테이블에서 해야할 역할 은 어떤 여행 상품이 몇 명의 고객을 가지고 있는지등을 관리할 기보니가 반드시 있어야 함!
Q. 만약 외래키를 리스트 형식으로 관리하는 필드가 있다면, 어떤 문제가 발생할 수 있을까요?
외래키는 기본키처럼 고유값이 아니니
-
필드에 저장되는 데이터의 크기를 설정해야하는데 엄청 커지게 되고 데이터가 저장되지 못할 수 도 있다.
-
데이터를 조회하는데 많은 비용이 발생하게 된다.
-
데이터를 수정할 때 두 곳에 수정이 잘 되었는지 확인이 불편하다. (실수를 유발한다.)
자기참조 관게
테이블 내에서 관계를 가지는 거.. 그넫 이게 왜 필요할까?
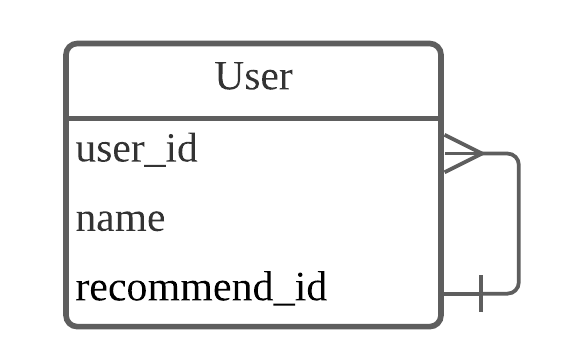
User 테이블의 recommend_id는 테이블 내 user_id와 연결되어있음.
1 : N 관계는 서로 다른 테이블의 관계를 나타내지만
얘는 User 테이블 안에서 관리
SQL More
SQL에서 사용되는 쿼리에는 유용하게 사용할 수 있는 함수가 너무많다 !!
조슴씨 알아보자!
SQL 내장함수
집합연산
레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산
GROUP BY
데이터를 조회할 때 그룹으로 묶어서 조회함.
다음과 같은 쿼리가 있다고 가정
SELECT * FROM customers;이 쿼리를 주(state)에 따라 그룹으로 묶어 표현 할 수 있음
SELECT * FROM customers;
GROUP BY State;GROUP BY 쿼리로 간단하게 State에 따라 그룹화할 수 있음.
쿼리의 결과를 확인하면, 데이터가 중간에 비어있는 것을 확인할 수 있음.
데이터베이스에서 데이터를 불러오는 과정에서 State에 따라 그룹을 지정했지만, 그룹에 대한 작업 없이 조회만 함!
HAVING
HAVING은 GROUP BY로 조회된 결과를 필터링 할 수 있음!
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId
HAVING AVG(Total) > 6.00invoices 테이블을 CustomerID로 그룹화하고 평균이 6초과한 결과를 조회
근데 이거 WHERE 아님? ㄴㄴ
HAVING은 그룹화한 결과에 대한 필터이고, WHERE은 저장된 레코드를 필터링 함
따라서 실제로 그룹화 전에 데이터를 필터해야 한다면 WHERE 사용!
COUNT()
COUNT 함수는 레코드의 개수를 헤아릴 때 사용!
SELECT *, COUNT(*) FROM customers
GROUP BY State;위 커맨드를 실행하면, 모든 레코드에 대한 COUNT 함수 실행!
SELECT State, COUNT(*) FROM customers
GROUP BY State;이 아이는 각 State에 해당하는 레코드의 개수를 확인!
SUM()
SUM 함수를 레코드의 합을 리턴!
SELECT InvoiceId, SUM(UnitPrice)
FROM invoice_items
GROUP BY InvoiceId;위를 실행하면 invoise_items 테이블에서 invoiceId 필드를 기준으로 그룹하고, UnitPrice 필드 값의 합을 구함!
AVG()
레코드의 평균값 계산!
SELECT TrackId, AVG(UnitPrice)
FROM invoice_items
GROUP BY TrackId;MAX(), MIN()
모르면 바보
SELECT CustomerId, MIN(Total)
FROM invoices
GROUP BY CustomerIdSELECT 실행 순서!
데이터를 조회하는 SELECT 문은 정해진 순서대로 동작함!
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
SELECT CustomerId, AVG(Total)
FROM invoices
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2위 쿼리문의 실행 순서는
-
FROM : invoices 테이블에 접근함
-
WHERE : CustomerId 필드가 10 이상인 레코드들을 조회
-
GROUP BY : CustomerId를 기준으로 그룹화 함!
-
HAVING SUM(Total) : Total 필드의 총합이 30 이상인 결과들만 필터링!
5!!!. SELECT : 조회된 결과에서 CustomerId 필드와 Total필드의 평균값을 구함!
- ORBER BY : AVG(Total) 필드를 기준으로 오름차순 정렬한 결과를 리턴!
