데이터 읽어들이기
데이터를 읽어들이기 위해서는 컴퓨터 내부 데이터에 접근하거나 URL주소를 통해 데이터를 직접 다운받아야한다. 보통 큰 용량의 데이터의 경우 URL주소를 통해 접근해야 하므로 아래와 같은 코드를 입력하여 저장해야한다.
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/"
HOUSING_PATH = os.path.join('datasets', 'housing')
HOUSING_URL = DOWNLOAD_ROOT + 'datasets/housing/housing.tgz'
def fetch_housing_data(housing_url = HOUSING_URL, housing_path = HOUSING_PATH):
os.makedirs(housing_path, exist_ok = True)
tgz_path = os.path.join(housing_path, 'housing.tgz')
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()위와 같은 식은 처음 작성할 때, 쉽지 않은 방법이지만, 압축파일에 담겨있는 데이터 파일을 한번에 추출하기 위해 필요한 함수이므로 두고두고 사용할 수있는 방법이다. 즉 url주소만 있으면 저 함수에 대입해 언제든지 파일을 추출할 수 있다.
데이터 로드하기
import pandas as pd
def load_housing_data(housing_path = HOUSING_PATH):
csv_path = os.path.join(housing_path, 'housing.csv')
return pd.read_csv(csv_path)
데이터를 로드하는 것도 함수로 작성해 놓으면, 매번 컴퓨터 내부 주소로 접근할 필요가 없다.
데이터 탐색하기
housing.info()
housing.describe()
housing['ocean_proximity'].value_counts()
데이터 시각화해보기
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()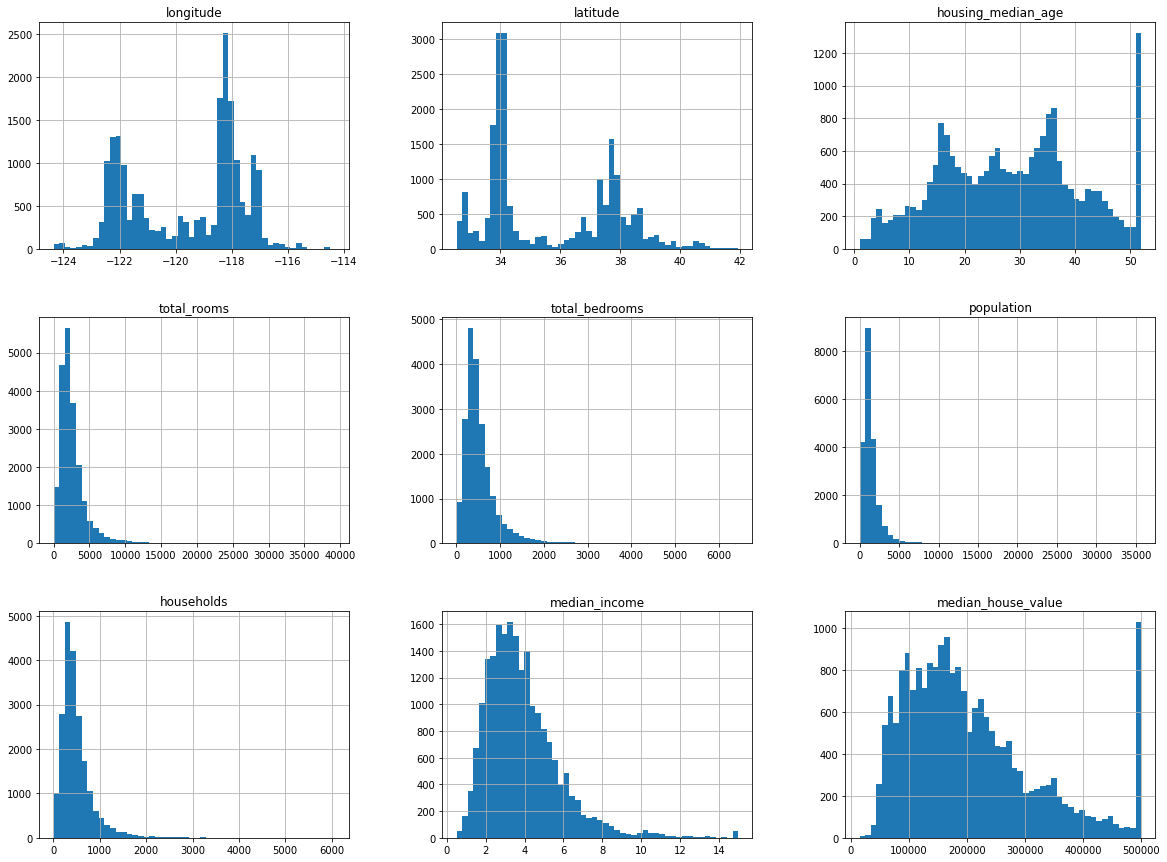
housing.plot(kind='scatter', x = 'longitude', y = 'latitude', alpha = 0.4, s=housing['population']/100, label='population', figsize=(10, 7),
c='median_house_value', cmap=plt.get_cmap('jet'), colorbar=True)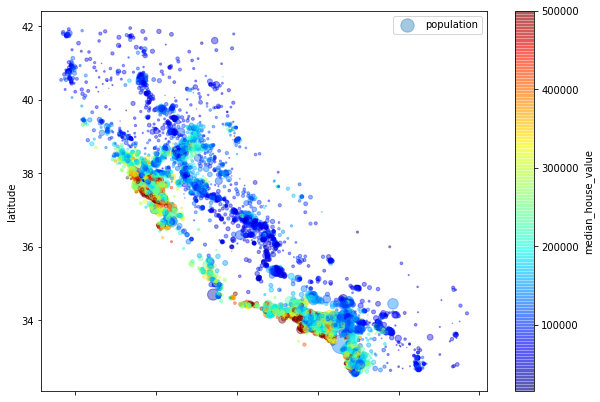
from pandas.plotting import scatter_matrix
attributes = ['median_house_value', 'median_income', 'total_rooms','housing_median_age']
scatter_matrix(housing[attributes], figsize = (12, 8))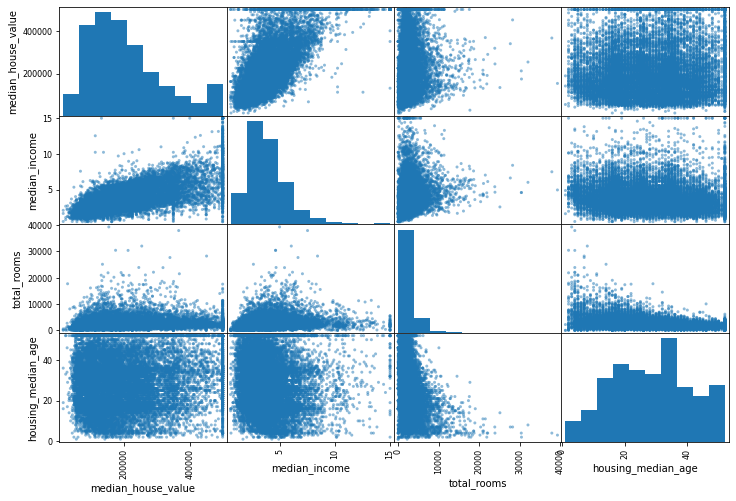
훈련 / 테스트 셋으로 분할하기
import numpy as np
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 42)머신러닝에 적합한 데이터로 변환(전처리)
housing['income_cat'] = pd. cut(housing['median_income'], bins = [0., 1.5, 3.0, 4.5, 6., np.inf], labels = [1, 2, 3, 4, 5])
housing['income_cat'].hist()
계층별로 분할하기
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits = 1, test_size = 0.2, random_state = 42)
for train_index, test_index in split.split(housing, housing['income_cat']):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]이처럼 계층별로 분할하지 않고 무작위로 분할할 경우, 각 계층의 비율을 무시한 데이터가 형성된다. 이러한 경향을 나타내는 데이터는 머신러닝의 예측에 큰 오류를 발생시키므로, 계층별 데이터가 있는 경우 이와 같은 계층별 분할(StratifiedShuffleSplit)을 시행해야 한다
na값 처리하기
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy = 'median')
housing_num = housing.drop('ocean_proximity', axis = 1)
imputer.fit(housing_num)원핫인코딩으로 명목변수값 숫자로 치환하기
from sklearn.preprocessing import OneHotEncoder
cat_encoder =OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot