
open
open함수를 통해 읽기 쓰기가 가능한 파일 객체를 생성할 수 있다.
fd = open('a.txt', 'r')
for line in fd.readlines():
print(line,end='')
fd.close()<fd>.readlines()는 문자열을 '개행 문자'를 기준으로 split() 시킨 리스트- line-ending을 나타내는 이스케이프 문자는 OS에 따라 다르다.
- 유닉스:
'\n' - 윈도우즈:
'\r\n' 'r'로 열면 둘다 ->'\n'으로 변환한다.- 이미지 파일등 바이너리를 텍스트모드로 열면 이 변환때문에 데이터 오류가 발생할 수 있다.
- 바이너리는
'rb'로 열자
- 바이너리는
- 유닉스:
json
- json file

- python dictionary
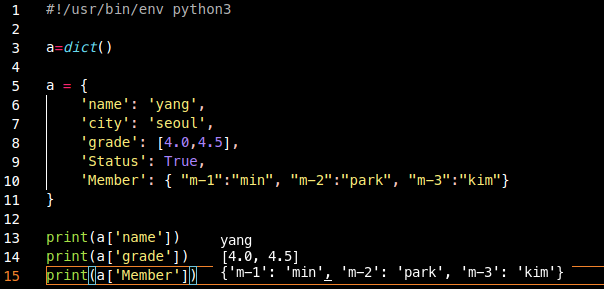
json이나 dictonary나 거의 똑같다.
py to json
json.dump(): obj -> write 'disk' using fd
import json
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)| Python object | Json |
|---|---|
dict | object |
list, tuple | array |
str | string |
int, float, int와 float에서 파생된 열거형 | number |
True | true |
False | false |
None | null |
json.dump( arg[= 기본값] ) | argument |
|---|---|
| obj | json으로 변활 시킬 python object |
fp | json File Pointer json 모듈은 항상 <str> 객체를 생성하므로, fp.write()는 str write 모드를 지원해야한다. |
skipkeys = False | True: 기본형(str, int, float, bool None이 아닌 딕셔너리 키는 <TypeError> |
ensure_ascii = True | True: 출력에서 모든 비 ASCII 문자가 이스케이프 되도록 보장False: 그 문자들은 있는 그대로 출력한다. |
check_circular = True | True: check_circular가 거짓이 되면, container type에 대한 circular reference check를 스킵하고 circurlar reference는 RecursionError(or worse) 결과를 낸다. |
allow_nan = True | True: JavaScript의 대응물(NaN, Infinity, -Infinity)가 사용된다.False: JSON 사양을 엄격히 준수하여 범위를 벗어난 float 값 (nan, inf, -inf)를 직렬화하면 ValueError를 일으킨다. |
indent = None | None:가장 간결한 표현not 음의 정수 | 문자열: Json 배열 요소와 오브젝트 멤버가 해당 들여쓰기 수준으로 예쁘게 인쇄됩니다.양의 정수: 수준 당 그만큼의 space로 들여쓰기한다.\t 와 같은 문자: 그에 맞는 indent |
separator = (item_sep, key_sep) | indent가 None일 경우, (', ', ': ')indent가 None아 아닐 경우, (',', ':')를 기본 값으로 사용. 지정되면 default와는 달리 직렬화 할수 없는 객체에 대한 호출되는 함수여야한다. 객체의 JSON 인코딩 가능한 버전을 반환하거나 <TypeError>를 발생시켜야한다. 지정하지 않으면 <TypeError>가 발생한다. |
- Python 3.6 부터 모든 매개변수는 kwargs이다.
default(o)
o의 직렬화 가능 객체를 반환하거나 (TypeError를 발생시키기 위해서) 베이스 구현을 호출하도록 서브 클래스에서 이 메소드를 구현하라.
임의의 이터레이터를 지원하려면, 다음과 같이 default()를 구현할 수 있다.
def default(self, o):
try:
iterable = iter(o)
except TypeError:
pass
else:
return list(iterable)
# Let the base class default method raise the TypeError
return json.JSONEncoder.default(self, o)encode(o)- python 데이터 구조 o의 Json 문자열 표현을 반환한다.
json.JSONEncoder().encode({"foo": ["bar", "baz"]}) '{"foo": ["bar", "baz"]}'iterencode(o)- 주어진 객체 o를 인코딩하고, 준비될 때 마다 문자열 표현을 yield 한다.
for chunk in json.JSONEncoder().iterencode(bigobject): mysocker.write(chunk)
obj -> json.dump(fd)
import json
dict_data={ ... }
json_file=open('sample.json','w')
json.dump(dict_data,json_file)
json_file.close()- import: json
- 재료: python <'dict'>
- 역할: json fd를 사용하여 json file로 디스크에 write
- open( )으로 fd 객체를 만듦
- json_dump( python<'dict'> object, 'json' object)
import json
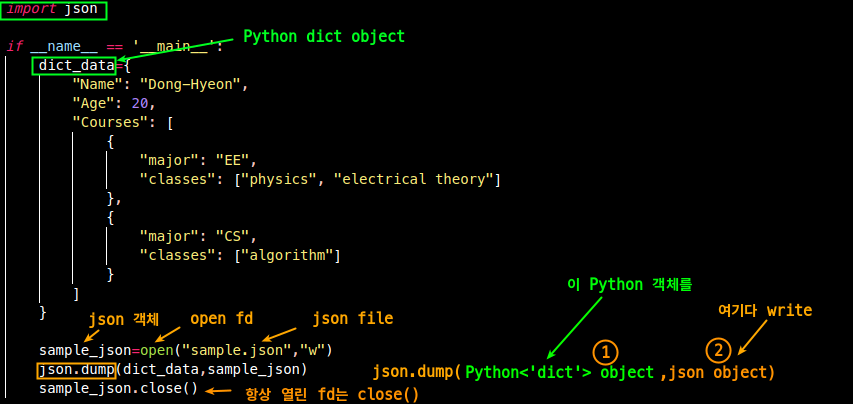
if __name__ == '__main__':
dict_data={
"Name": "Dong-Hyeon",
"Age": 20,
"Courses": [
{
"major": "EE",
"classes": ["physics", "electrical theory"]
},
{
"major": "CS",
"classes": ["algorithm"]
}
]
}
sample_json=open("sample.json","w") # 1. json fd를 얻는다.
json.dump(dict_data,sample_json) # 2. json.dump를 사용해 json fd에 write
sample_json.close()
- 결과
- json file이 write 됨

- json file이 write 됨
indent 사용
import json
if __name__ == '__main__':
dict_data={
"Name": "Dong-Hyeon",
"Age": 20,
"Courses": [
{
"major": "EE",
"classes": ["physics", "electrical theory"]
},
{
"major": "CS",
"classes": ["algorithm"]
}
]
}
sample_json=open("sample.json","w") # 1. json fd를 얻는다.
json.dump(dict_data,sample_json,indent=4) # 2. json.dump를 사용해 json fd에 write
sample_json.close()
- 결과
- json file이 write됨

- json file이 write됨
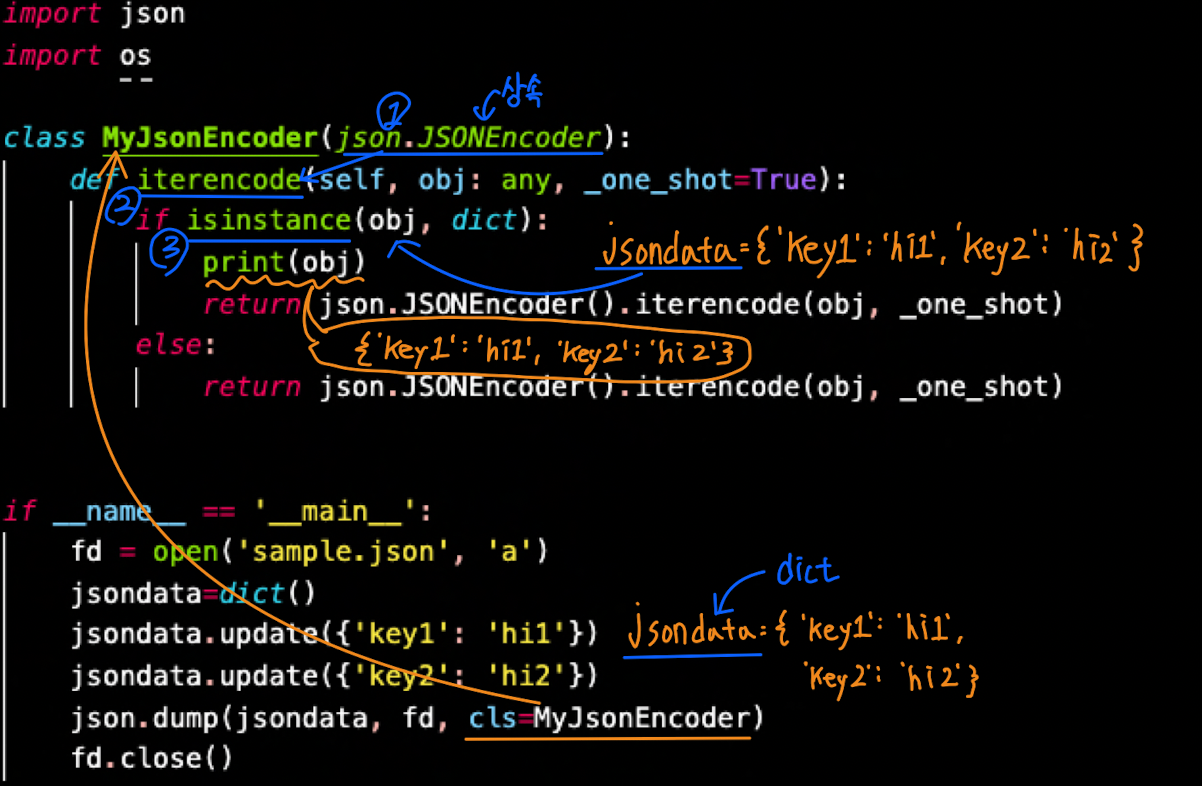
json dump를 JSONEncoder 사용
- obj: dictionary
- obj: list
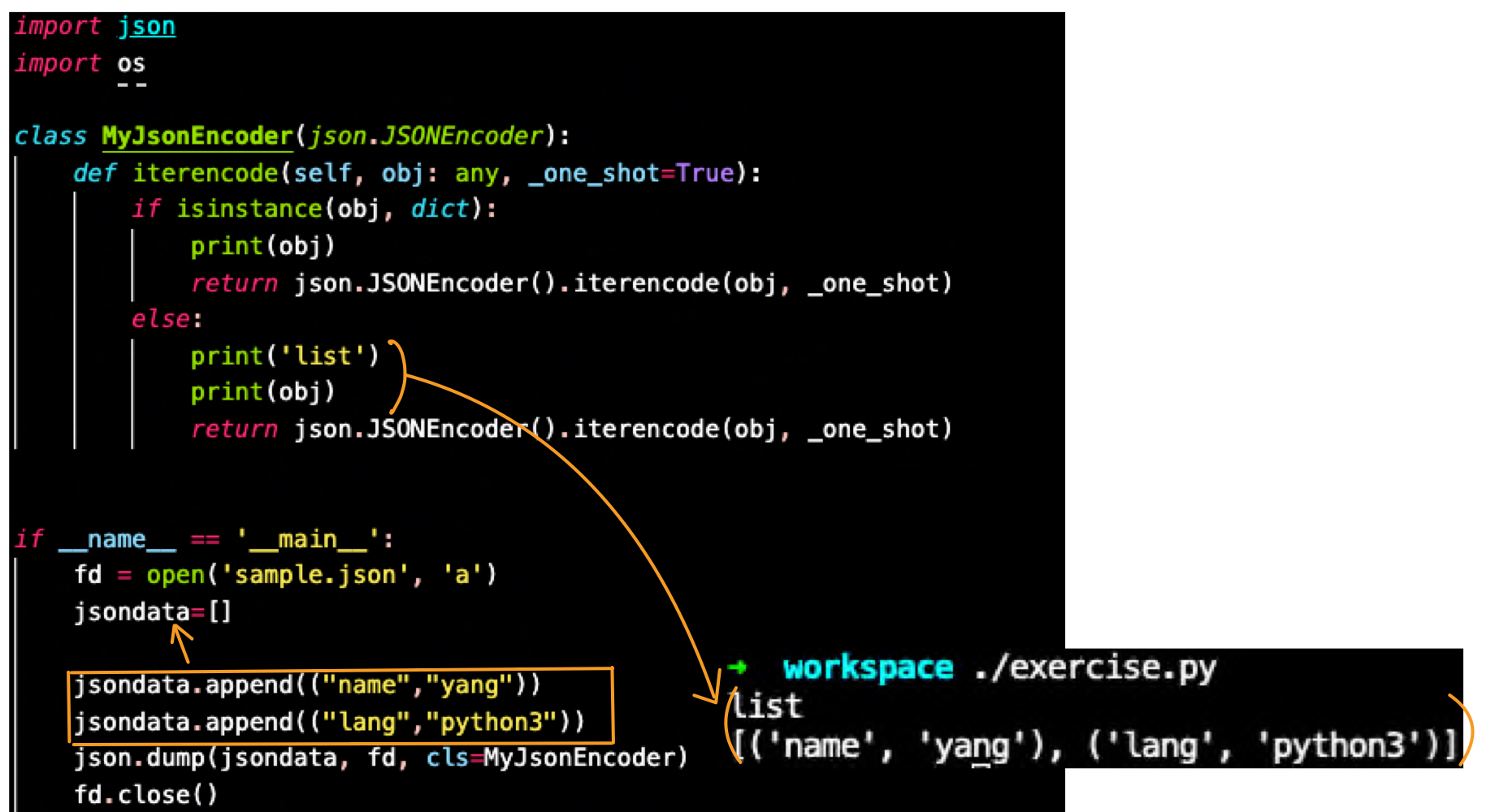

json.dumps(): dict -> json(RAM) object
import json
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
| Python object | Json |
|---|---|
dict | object |
list, tuple | array |
str | string |
int, float, int와 float에서 파생된 열거형 | number |
True | true |
False | false |
None | null |
json.dumps( arg[= 기본값] ) | argument |
|---|---|
| obj | json으로 변활 시킬 python object |
| json.dump와 같으니 json.dump 참고할 것 | - |
dumps(indet=): 들여 쓰기
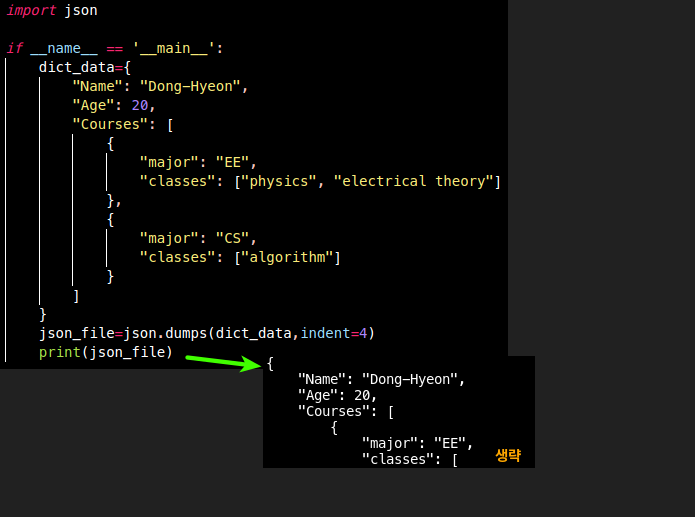
import json
json_data=json.dumps(python<'dict'>, indents=4)
print(json_data)json.dumps(python<'dict'>, indents=' ')indents=<NUM>을 부여해, 사람이 보기 좋게 들여 쓰기한 RAM의 json을 STDOUT으로 표시
dumps(sort_keys=True): 정렬
import json
json_data=json.dumps(python'<dict>'>, [indents=<NUM>], sort_keys=Ture)
print(json_data)- python dict의 Keys로 정렬
여러 번 json.dumps사용 시, Class 상속 받을 것
json to py'dict'
json.load(): json fd -> dict
import json
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)- 주의 여기서 읽어올 fp 는 readable(
open으로r) 이어야함
| Python object | Json |
|---|---|
dict | object |
list, tuple | array |
str | string |
int, float, int와 float에서 파생된 열거형 | number |
True | true |
False | false |
None | null |
json.load( arg[= 기본값] ) | argument |
|---|---|
| fp | json File Pointer |
cls = None | JSONDecoder 서브 클래스 지정 |
object_hook = None | 모든 오브젝트 리터럴의 Decode 결과(dict)로 호출되는 선택적 함수.object_hook의 반환 값이 dict 대신 사용된다. |
parse_float = None | 지정 시, 디코딩될 모든 JSON float의 문자열로 호출된다. (float(number_str)) |
parse_int = None | 지정 시, 디코딩될 모든 JSON int의 문자열로 호출된다. (int(number_str)) |
parse_constant = None | 지정 시, 다음과 같은 문자열 중 하나로 호출된다.'-Infinity', 'Infinity', 'NaN' |
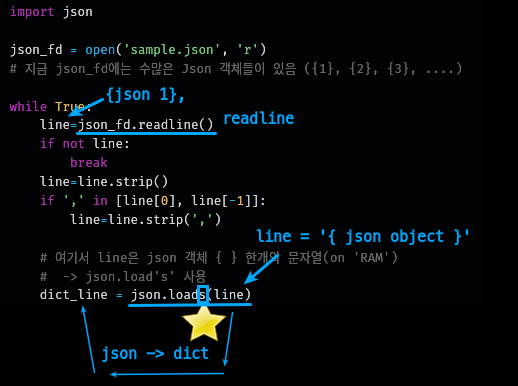
json 파일이 {1},{2}.. 인 경우
{json 1},{json 2}, ....와 같이 되어 있는 경우- 하나의 json 파일에서 json 객체가 여러 개일 경우,
array에 담겨야 한다.
[{json 1}, {json 2}, .... ]- 하나의 json 파일에서 json 객체가 여러 개일 경우,
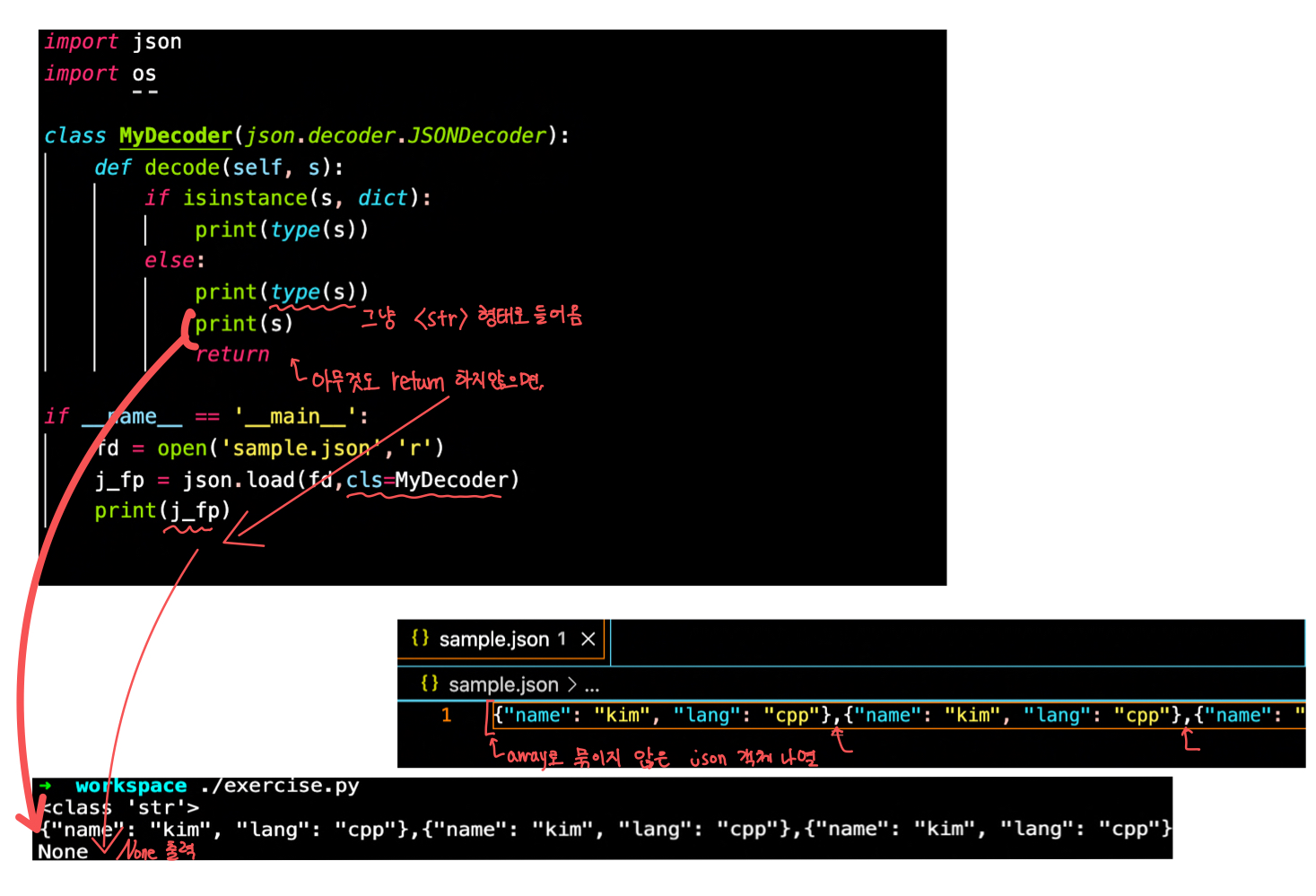
- 한 줄 씩 읽기
fp 파일에 아무 내용도 없는 경우
exception json.decoder.JSONDecodeError
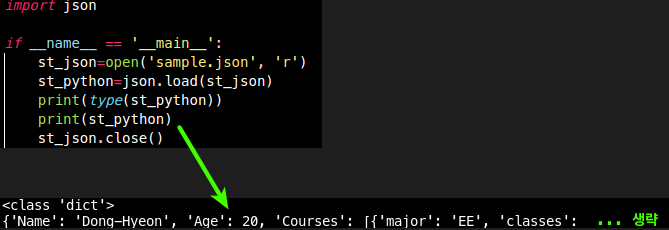
import json
if __name__ == '__main__':
st_json=open('sample.json', 'r')
st_python=json.load(st_json)
print(type(st_python))
print(st_python)
st_json.close()
json.loads(): RAM json -> py'dict'
예제
파일 없으면 생성하고 Json Write
import json
import os
if __name__ == '__main__':
FILENAME = 'compile-option.json'
if not os.path.exists(FILENAME): # 파일이 존재하지 않으면
fp = open('compile-option.json', 'w', encoding='utf-8') # 파일을 만듦 (r+)로는 만들 수 없음
fp.close()
fp = open('compile-option.json', 'r+', encoding='utf-8') # r+ 읽고쓰기
try:
comm_json = json.load(fp)
except json.decoder.JSONDecodeError as e:
# It is occur cause of nothing in the json file
if e.msg.startswith('Expecting value'):
comm_json = dict()
comm_json.setdefault('aarch64', {"CC": "gcc", "CFLAGS": "-I/usr/env"}) # dict하나 값 넣고
json.dump(comm_json, fp) # write
fp.close()CSV
- CSV로 다루기 위해서 import CSV로 모듈을 받아올 것
- 없다면 설치!
$ pip3 install python-csvCSV파일 한 줄 씩 읽기
csv_objeㄴct = csv.reader( file_object )를 사용해 CSV 객체로 변환
import csv
f = open('data.csv', 'r', encoding='utf-8')
csv_obj=csv.reader(f)
for line in csv_obj:
print(line) # 한 줄 씩 list로 return
f.close()CSV로 한 줄 씩 write
csv_object = csv.writer( file_object )를 사용해 CSV 객체로 변환csv_object.writerow([list to write])를 사용해 CSV 객체에 한 줄 씩 write
import csv
f = open('output.csv', 'w', encoding='utf-8', newline='')
csv_obj = csv.writer(f)
csv_obj.writerow([1, "Mark", False]) # 한 줄 씩 list로 write
csv_obj.writerow([2, "Andrew", True])
f.close()dict -> csv
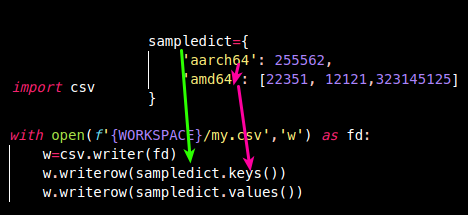
- 아래와 같은 dict가 있다.
sampledict={
'aarch64': 255562,
'amd64': [22351, 12121,323145125]
}open으로fd를 열고w <- csv.writer(fd)w.writerow( iterator )
- 결과

df -> csv

pllpokko@alumni.kaist.ac.kr