들어가며..
지난번 고가네 사이트, 중앙대 유아교육과 스크레이핑에 이어서 서울시 교육청의 정보도 Firestore에 가져와서 저장해보는 코드를 구현해보았다. 이번에는 코드잇의 Selenium 웹 자동화 강의를 완강한 기념으로 한 단계 더 높여서 Selenium과 BeautifulSoup를 이용해서 만들었다!

🔍 BeautifulSoup vs Selenium
웹 스크래핑을 할 때 보통 BeautifulSoup과 Selenium 중 하나를 사용한다. 이전에 고가네 사이트나 유아교육과의 스크레이핑은 BeautifulSoup만을 이용해서 구현했지만 이번에는 Selenium을 추가해서 구현해보았다.
🎯 1. BeautifulSoup과 Selenium의 차이
| 기능 | BeautifulSoup | Selenium |
|---|---|---|
| HTML 파싱 방식 | 정적 HTML 파싱 (requests.get()) | 브라우저를 직접 실행하여 동적 페이지 로딩 |
| 요소 선택 | soup.select_one(), soup.select() | driver.find_element(), driver.find_elements() |
| 개별 요소 가져오기 | Tag 객체 | WebElement 객체 |
| 여러 요소 찾기 | tag.select() | web_element.find_elements() |
| 텍스트 추출 | tag.get_text() | web_element.text |
| 속성 값 가져오기 | tag['attr'] | web_element.get_attribute('attr') |
| JavaScript 실행 | ❌ 불가능 | ✅ 가능 |
| 동적 웹사이트 지원 | ❌ JavaScript로 생성된 데이터는 못 가져옴 | ✅ JavaScript가 실행된 후의 데이터를 가져올 수 있음 |
🎯 2. 서울시 교육청 사이트는 왜 Selenium을 사용했을까?
처음에는 다른 사이트들처럼 requests.get()과 BeautifulSoup을 사용하려 했었다.
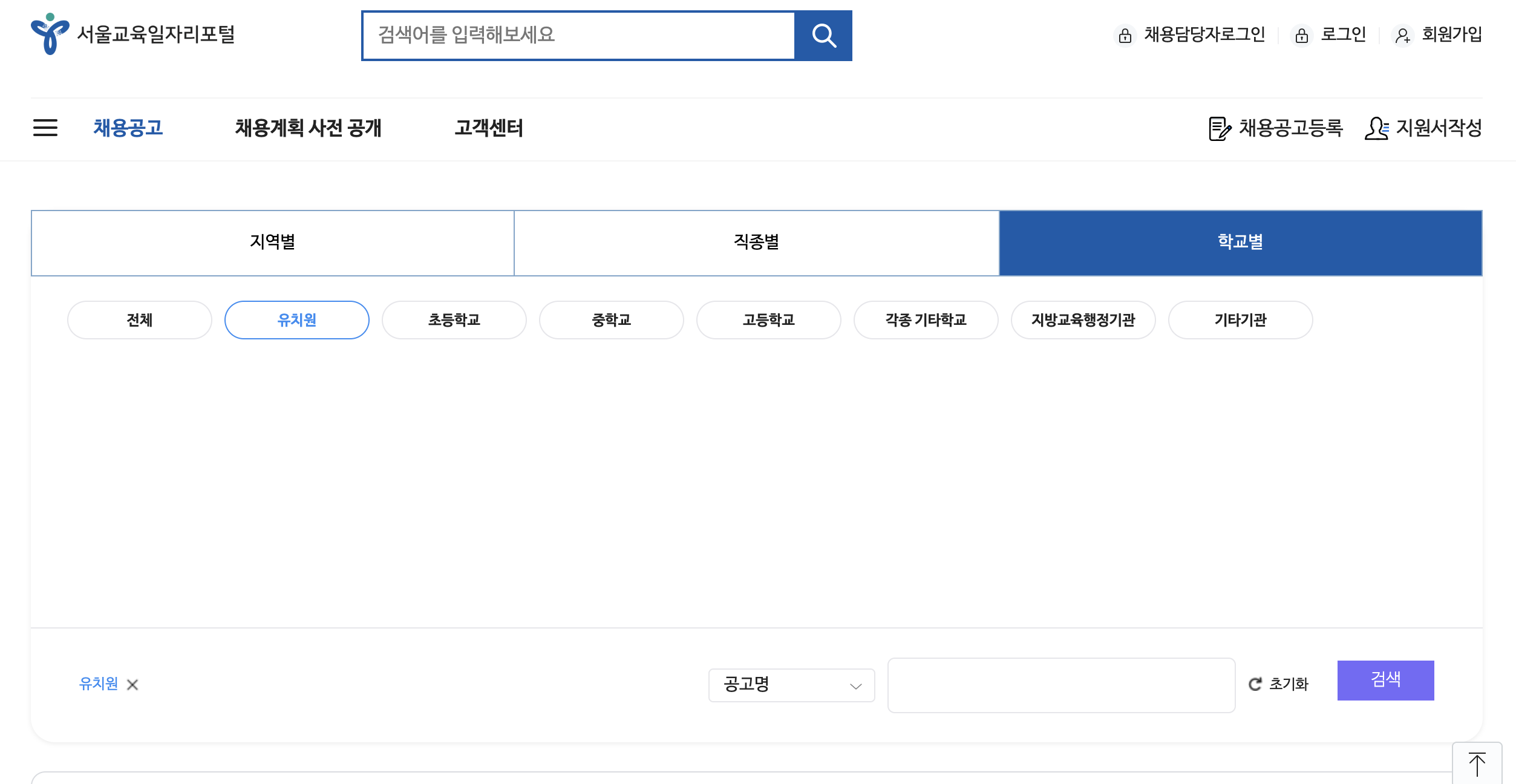
하지만, 서울시 교육청 구인구직 사이트는 JavaScript를 이용해 동적으로 데이터를 불러오는 방식이었다. 이때 필요한 것이 바로 Selenium 이다.
❌ requests.get() 방식으로 HTML을 가져올 경우:
import requests
from bs4 import BeautifulSoup
url = "https://work.sen.go.kr/work/search/recInfo/BD_selectSrchRecInfo.do"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify()) # 공고 목록이 포함되지 않은 정적 HTML만 보임이렇게 하면 JavaScript 실행 전의 HTML만 가져오므로, 원하는 데이터가 포함되지 않는다. 따라서 JavaScript가 실행된 이후의 HTML을 가져오기 위해 Selenium을 사용해야 했다. 즉, 단순한 HTML 요청으로는 데이터를 가져올 수 없었고, 실제 브라우저에서 JavaScript가 실행된 후의 HTML을 가져와야 했다.
🔥 서울시 교육청 구인구직 사이트 스크래핑 과정
🏁 Selenium을 이용해 브라우저 실행 & HTML 가져오기
1️⃣ Chrome WebDriver 설정 및 실행
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
# ✅ Chrome WebDriver 설정 (Headless 모드)
chrome_options = Options()
chrome_options.add_argument("--headless") # GUI 없이 실행
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# ✅ Chrome WebDriver 실행
driver = webdriver.Chrome(options=chrome_options)
# ✅ 서울시 교육청 구인구직 사이트 접속
url = "https://work.sen.go.kr/work/search/recInfo/BD_selectSrchRecInfo.do"
driver.get(url)
time.sleep(5) # 🚨 JavaScript 실행 대기
# ✅ 페이지의 HTML 가져오기
html_source = driver.page_source
driver.quit()Selenium이 driver.get(url)로 웹페이지를 열었다고 해서 즉시 모든 데이터가 로드되는 것이 아니다. JavaScript가 실행되면서 API 요청을 보내고, 서버에서 데이터를 받아서 웹페이지에 렌더링하는 시간이 필요하다.
따라서, Selenium이 HTML을 가져오기 전에 JavaScript가 실행될 시간을 주기 위해 time.sleep(5)을 사용했다. 일반적으로 2~5초 정도 대기하면 JavaScript가 실행되고, 최종 HTML이 완성된다.
또한 Selenium은 기본적으로 실제 Chrome 브라우저를 실행한다. 하지만, 서버에서 실행하거나 지금처럼 정보만 빼와서 백그라운드에서 실행해야 할 때는 GUI(그래픽 화면)가 필요하지 않다.
그러므로 headless 모드를 활성화하면 브라우저 창을 띄우지 않고 백그라운드에서 실행할 수 있다.
✅ headless 모드의 장점
✔ 속도가 더 빠름 → 브라우저를 띄우지 않으므로 렌더링 비용이 줄어듦
✔ 서버에서도 실행 가능 → GUI 환경이 없는 Linux 서버에서도 크롤링 가능
✔ 자동화 작업에 유리 → 화면이 없어도 백그라운드에서 실행 가능
🔹 --no-sandbox
이 옵션을 추가하면 Chrome을 샌드박스(Sandbox) 모드 없이 실행한다.
샌드박스는 보안 기능이지만, 특정 환경(Linux 서버 등)에서는 오히려 크롬 실행을 방해할 수도 있다.
그래서 서버에서 실행할 때는 이 옵션을 추가하는 것이 일반적이다.
🔹 --disable-dev-shm-usage
이 옵션은 Chrome이 메모리 사용을 최적화하도록 도와준다.
기본적으로 Chrome은 /dev/shm (공유 메모리)를 사용하지만, 일부 시스템에서는 사용량이 너무 커질 수 있다.
이 옵션을 추가하면 메모리 사용량을 줄여서 크롤링이 더 안정적으로 실행될 수 있다.
🔎 BeautifulSoup을 활용한 데이터 추출
이제 Selenium으로 가져온 HTML을 BeautifulSoup을 이용하여 파싱한 후, 원하는 데이터를 추출한다.
2️⃣ BeautifulSoup을 사용해 공고 정보 가져오기
from bs4 import BeautifulSoup
# ✅ HTML을 BeautifulSoup으로 파싱
soup = BeautifulSoup(html_source, "html.parser")
# ✅ 공고 목록 가져오기
job_list = soup.select("ul > li.flex_cont")
for job in job_list:
title_element = job.select_one("h4.list_title a")
if title_element:
title = title_element.text.strip()
link = "https://work.sen.go.kr" + title_element["href"]
print(f"공고 제목: {title}, 링크: {link}")
이제 h4.list_title a 태그를 찾아 제목과 링크를 추출할 수 있다.
📌 서울시 구 정보 추가하기
서울시는 각 공고의 지역 정보를 span.border-r 태그에 넣어둔다.

하지만 이 border-r 태그에 시급 정보나 경력 유무 정보를 넣는 등 통일성이 없고, 순서도 뒤죽박죽이라 그중에서 "00구"로 끝나는 값만 지역 정보로 저장하도록 구현했다.
import re # 정규 표현식 사용
# ✅ 지역 정보 가져오기 (00구로 끝나는 경우만)
location_elements = job.select("span.border-r")
location = "지역 미확인"
for loc in location_elements:
loc_text = loc.text.strip()
if re.search(r".*구$", loc_text): # "00구"로 끝나는 경우만 지역으로 저장
location = loc_text
break # 첫 번째로 찾은 구 이름을 사용하고 종료
# ✅ 지역 정보를 포함한 제목 생성
full_title = f"[{location}] {title}"
이렇게 하면 " [성동구] (성수병유)2025학년도 에듀케어 아침돌봄인력 위촉 공고" 같은 형식으로 데이터를 저장할 수 있다.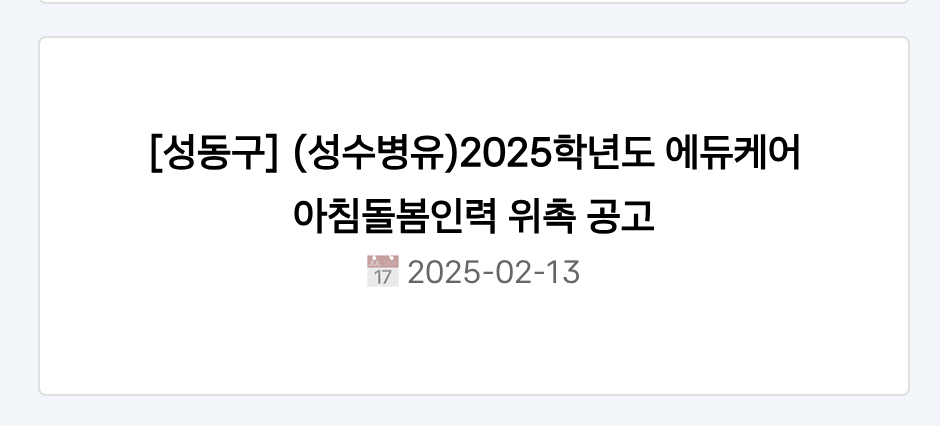
맺으며...
이번에 Selenium과 BeautifulSoup을 함께 사용하며 두 가지 기술을 동시에 사용하며 각자의 장점을 극대화하는 것에 신경을 썼다.
BeautifulSoup은 정적 HTML을 파싱하는 데 적합하지만, JavaScript로 동적으로 데이터를 로딩하는 페이지에서는 한계가 있다. 반면, Selenium은 실제 브라우저를 실행하여 JavaScript가 적용된 HTML을 가져올 수 있어, 서울시 교육청 구인구직 사이트와 같은 동적 웹페이지를 크롤링하는 데 필수적이다.
따라서 Selenium을 이용해 JavaScript가 실행된 후의 HTML을 가져오고, BeautifulSoup을 활용해 필요한 정보를 추출한 뒤 Firestore에 저장하는 방식으로 자동화 시스템을 구축했다.
앞으로는 이 데이터들을 AWS Lambda나 CRON Job을 활용하여 코드를 자동실행하여 Kinder-planet에 주기적으로 데이터를 업데이트하는 시스템을 만들고 싶다.
