실습 진행
1. 실습 환경 생성 및 점검
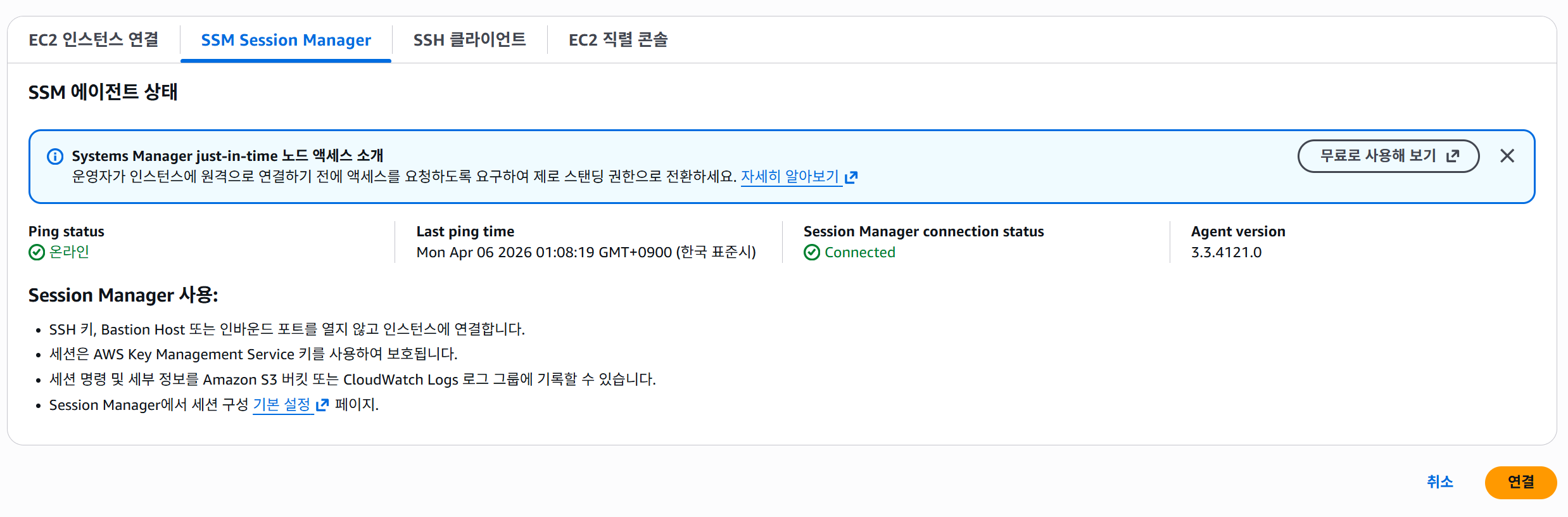
EKS 노드 SSM 접속
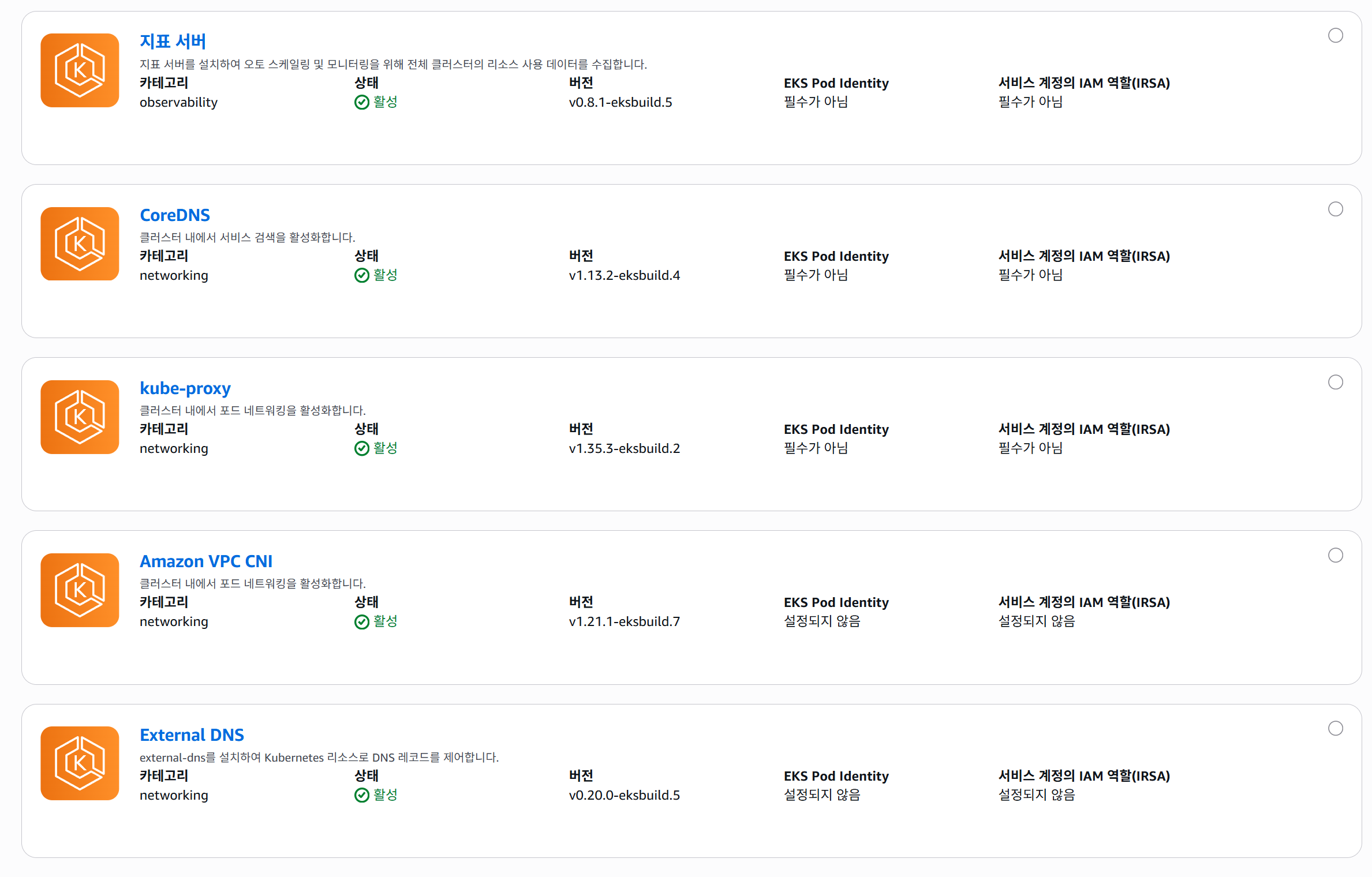
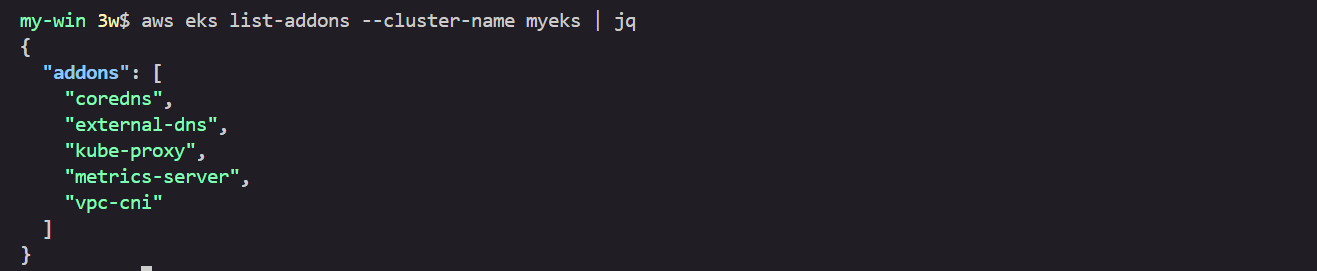
addon 확인
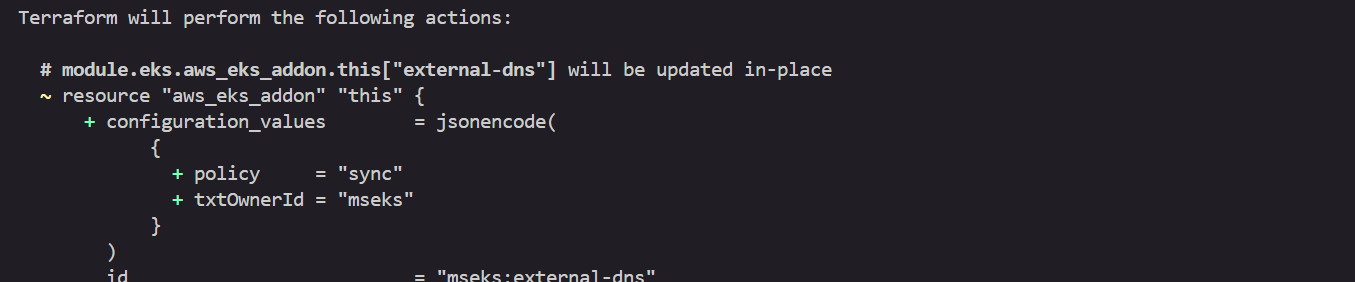
[도전과제] policy=sync 적용 해보기
- 테라폼으로 eks addon 에 external-dns 배포 시, extraArgs 에 policy=sync 적용 해보기

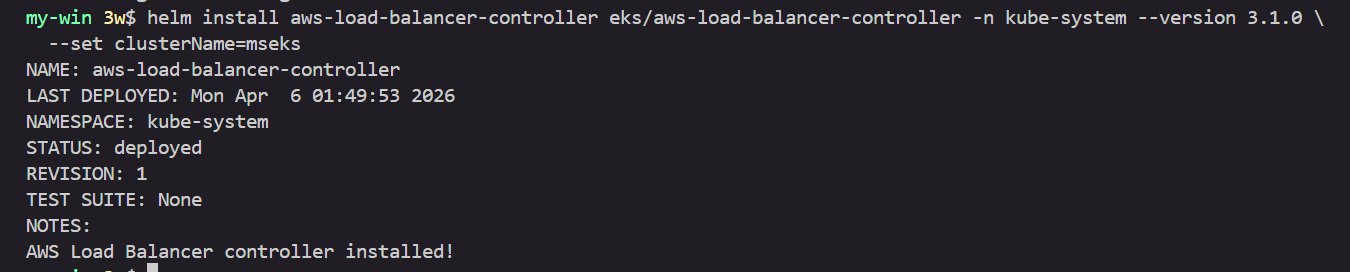
AWS LBC 설치
# Helm Chart Repository 추가
helm repo add eks https://aws.github.io/eks-charts
helm repo update
# Helm Chart - AWS Load Balancer Controller 설치 : EC2 Instance Profile(IAM Role)을 파드가 IMDS 통해 획득 가능!
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --version 3.1.0 \
--set clusterName=myeks
# 확인
helm list -n kube-system
kubectl get pod -n kube-system -l app.kubernetes.io/name=aws-load-balancer-controller
kubectl logs -n kube-system deployment/aws-load-balancer-controller -f

eks-node-viewer 설치
- 노드 할당 가능 용량과 요청 request 리소스 표시, 실제 파드 리소스 사용량 X
# Windows 에 WSL2 (Ubuntu) 설치
sudo apt install golang-go
go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest # 설치 시 2~3분 정도 소요
echo 'export PATH="$PATH:/root/go/bin"' >> /etc/profile# [신규 터미널] 모니터링 : eks 자격증명 필요
# Standard usage
eks-node-viewer
# Display both CPU and Memory Usage
eks-node-viewer --resources cpu,memory
eks-node-viewer --resources cpu,memory --extra-labels eks-node-viewer/node-age
# Display extra labels, i.e. AZ : node 에 labels 사용 가능
eks-node-viewer --extra-labels topology.kubernetes.io/zone
eks-node-viewer --extra-labels kubernetes.io/arch
# Sort by CPU usage in descending order
eks-node-viewer --node-sort=eks-node-viewer/node-cpu-usage=dsc
# Karenter nodes only
eks-node-viewer --node-selector "karpenter.sh/provisioner-name"
# Specify a particular AWS profile and region
AWS_PROFILE=myprofile AWS_REGION=us-west-2
Computed Labels : --extra-labels
# eks-node-viewer/node-age - Age of the node
eks-node-viewer --extra-labels eks-node-viewer/node-age
eks-node-viewer --extra-labels topology.kubernetes.io/zone,eks-node-viewer/node-age
# eks-node-viewer/node-ephemeral-storage-usage - Ephemeral Storage usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-ephemeral-storage-usage
# eks-node-viewer/node-cpu-usage - CPU usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-cpu-usage
# eks-node-viewer/node-memory-usage - Memory usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-memory-usage
# eks-node-viewer/node-pods-usage - Pod usage (requests)
eks-node-viewer --extra-labels eks-node-viewer/node-pods-usage





kube-ops-view 배포 + ALB Ingress
# kube-ops-view : NodePort 나 LoadBalancer Type 필요 없음!
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=ClusterIP --set env.TZ="Asia/Seoul" --namespace kube-system
# 확인
kubectl get deploy,pod,svc,ep -n kube-system -l app.kubernetes.io/instance=kube-ops-view

# 사용 리전의 인증서 ARN 변수 지정 : 정상 상태 확인(만료 상태면 에러 발생!)
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 자신의 공인 도메인 변수 지정
MyDomain=<자신의 공인 도메인>
echo $MyDomain
# kubeopsview 용 Ingress 설정 : group 설정으로 1대의 ALB를 여러개의 ingress 에서 공용 사용
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
labels:
app.kubernetes.io/name: kubeopsview
name: kubeopsview
namespace: kube-system
spec:
ingressClassName: alb
rules:
- host: kubeopsview.$MyDomain
http:
paths:
- backend:
service:
name: kube-ops-view
port:
number: 8080
path: /
pathType: Prefix
EOF
# service, ep, ingress 확인
kubectl get ingress,svc,ep -n kube-system
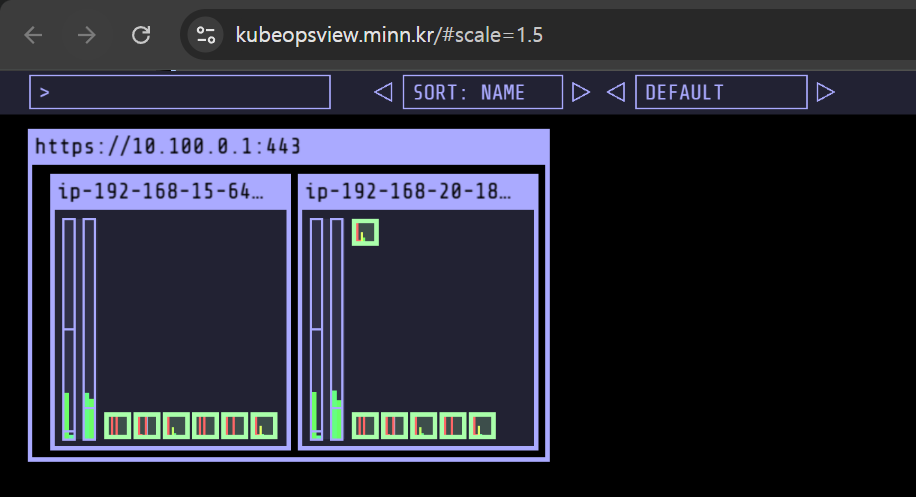
# Kube Ops View 접속 정보 확인
echo -e "Kube Ops View URL = https://kubeopsview.$MyDomain/#scale=1.5"
open "https://kubeopsview.$MyDomain/#scale=1.5" # macOS
# (참고) 삭제 시
kubectl delete ingress -n kube-system kubeopsview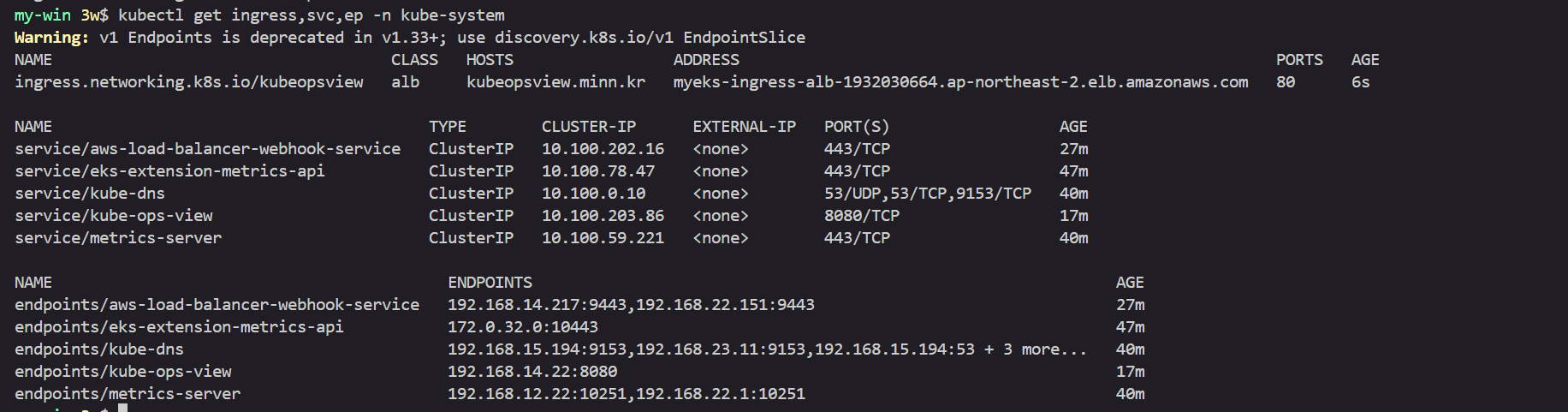
kube-prometheus-stack 배포 + ALB Ingress
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# helm values 파일 생성 : additionalScrapeConfigs 는 아래 설명
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
additionalScrapeConfigs:
# apiserver metrics
- job_name: apiserver-metrics
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Scheduler metrics
- job_name: 'ksh-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Controller Manager metrics
- job_name: 'kcm-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Enable vertical pod autoscaler support for prometheus-operator
#verticalPodAutoscaler:
# enabled: true
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
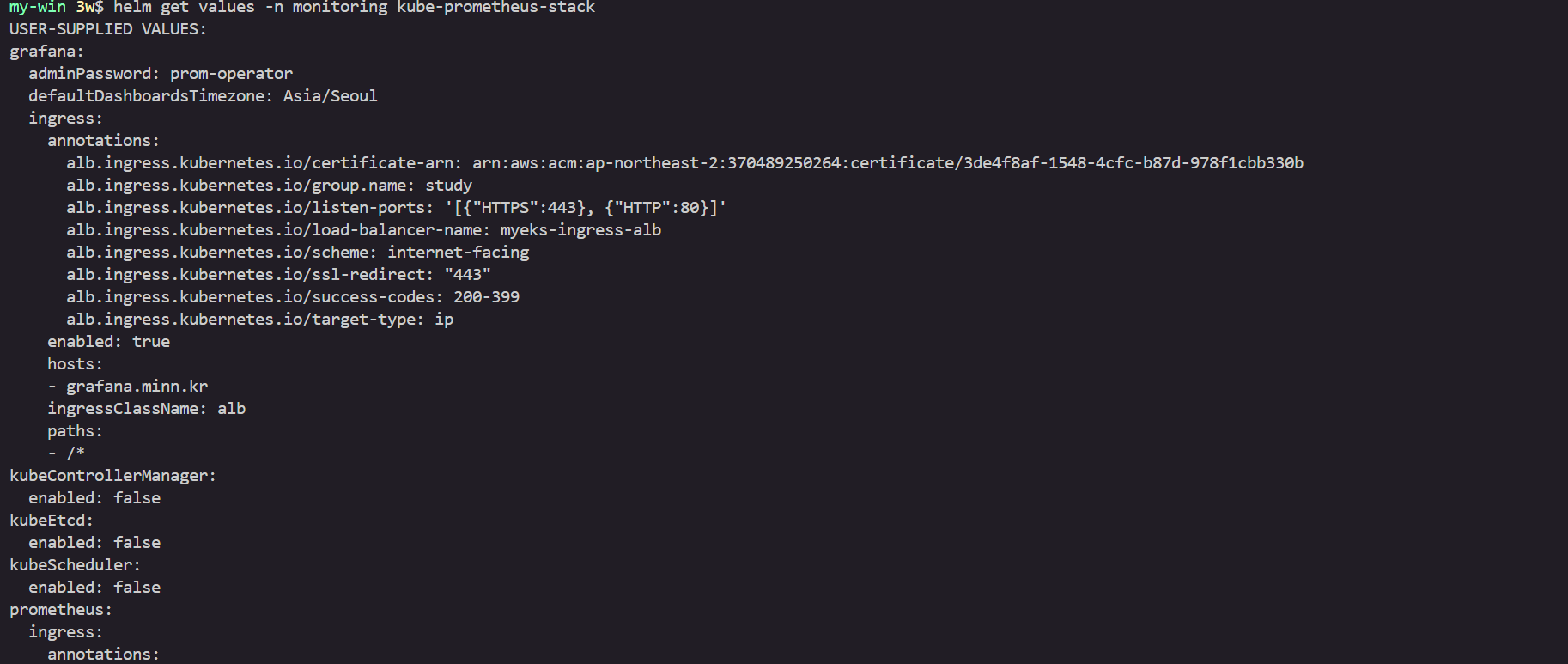
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 80.13.3 \
-f monitor-values.yaml --create-namespace --namespace monitoring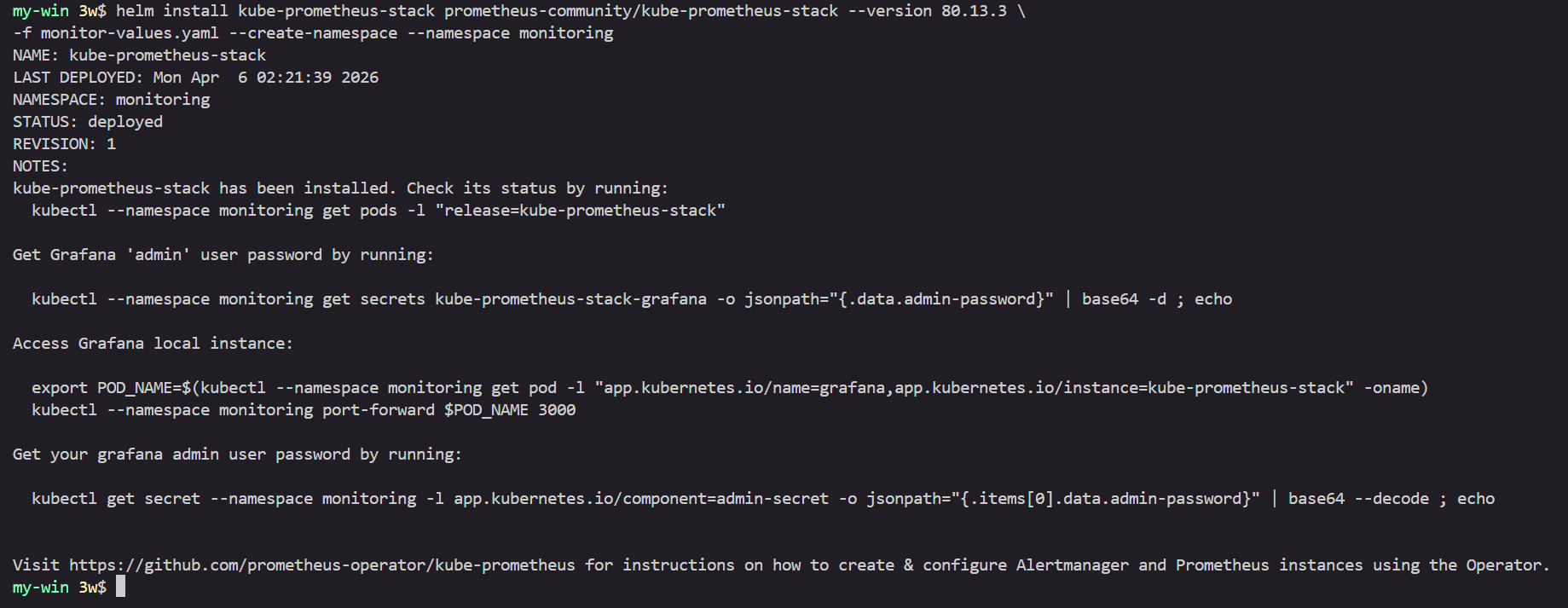
# 확인
helm list -n monitoring
kubectl get sts,ds,deploy,pod,svc,ep,ingress -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
kubectl get-all -n monitoring # kubectl krew install get-all
# 프로메테우스 버전 확인
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version
prometheus, version 3.1.0 (branch: HEAD, revision: 7086161a93b262aa0949dbf2aba15a5a7b13e0a3)
...
# 프로메테우스 웹 접속
echo -e "https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" # macOS
# 그라파나 웹 접속 : admin / prom-operator
echo -e "https://grafana.$MyDomain"
open "https://grafana.$MyDomain" # macOS
# (참고) 업그레이드 및 삭제 시
helm upgrade -i kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 80.13.3 \
-f monitor-values.yaml --create-namespace --namespace monitoring
helm uninstall -n monitoring kube-prometheus-stack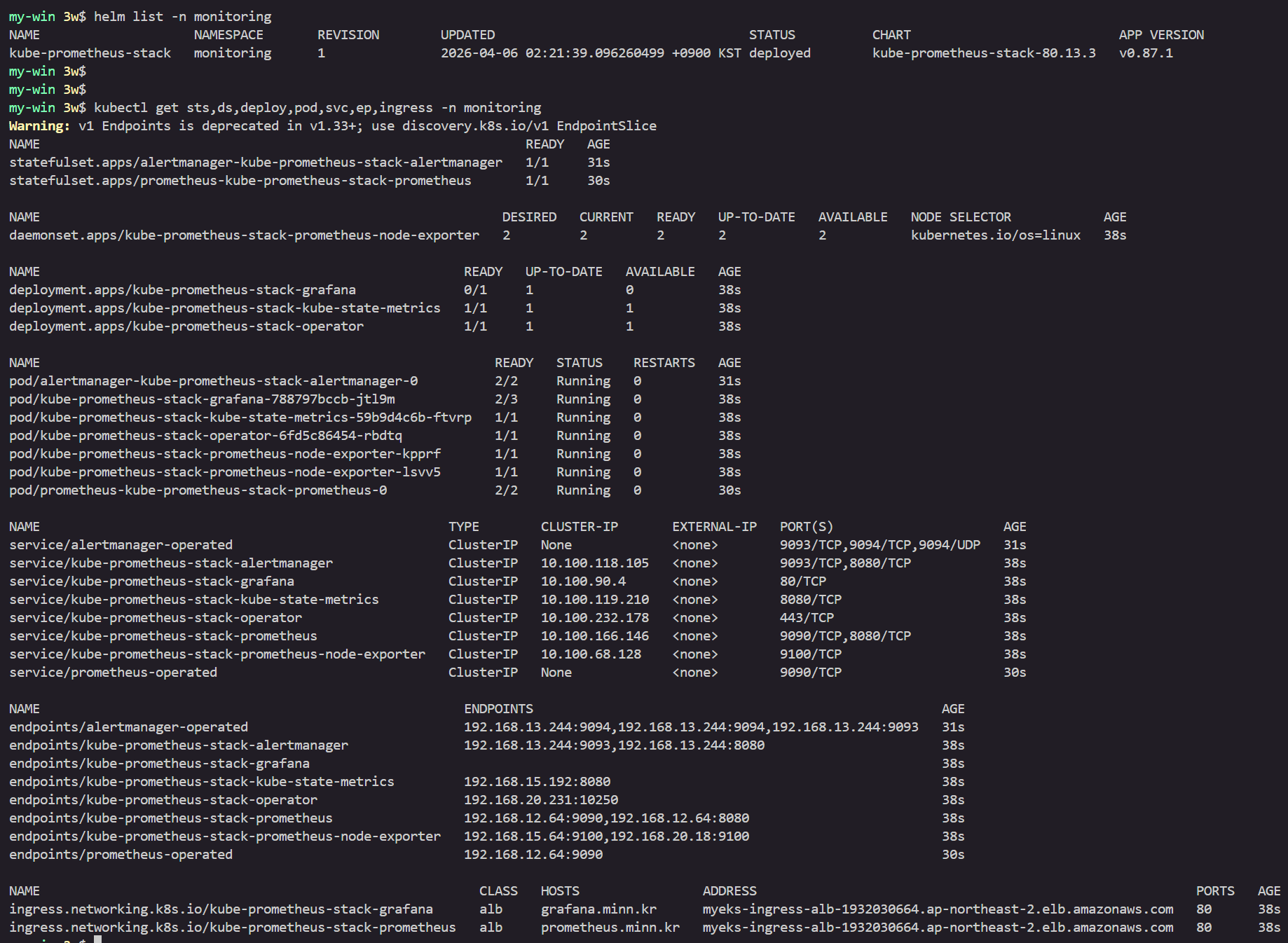
# helm values 파일 생성 : additionalScrapeConfigs 다시 살펴보기!
helm get values -n monitoring kube-prometheus-stack
...
job_name: ksh-metrics
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics
...
# Metrics.eks.amazonaws.com의 컨트롤 플레인 지표 가져오기 : kube-scheduler , kube-controller-manager 지표
kubectl get --raw "/apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics"
kubectl get --raw "/apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics"
kubectl get svc,ep -n kube-system eks-extension-metrics-api
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
NAME SERVICE AVAILABLE AGE
v1.metrics.eks.amazonaws.com kube-system/eks-extension-metrics-api True 75m
v1beta1.metrics.k8s.io kube-system/metrics-server True 68m
# 프로메테우스 파드 정보 확인
kubectl describe pod -n monitoring prometheus-kube-prometheus-stack-prometheus-0 | grep 'Service Account'
Service Account: kube-prometheus-stack-prometheus
# 해당 SA에 권한이 없음!
kubectl rbac-tool lookup kube-prometheus-stack-prometheus # kubectl krew install rbac-tool
kubectl rolesum kube-prometheus-stack-prometheus -n monitoring # kubectl krew install rolesum
...
Policies:
• [CRB] */kube-prometheus-stack-prometheus ⟶ [CR] */kube-prometheus-stack-prometheus
Resource Name Exclude Verbs G L W C U P D DC
endpoints [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
endpointslices.discovery.k8s.io [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
ingresses.networking.k8s.io [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
nodes [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
nodes/metrics [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
pods [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
services [*] [-] [-] ✔ ✔ ✔ ✖ ✖ ✖ ✖ ✖
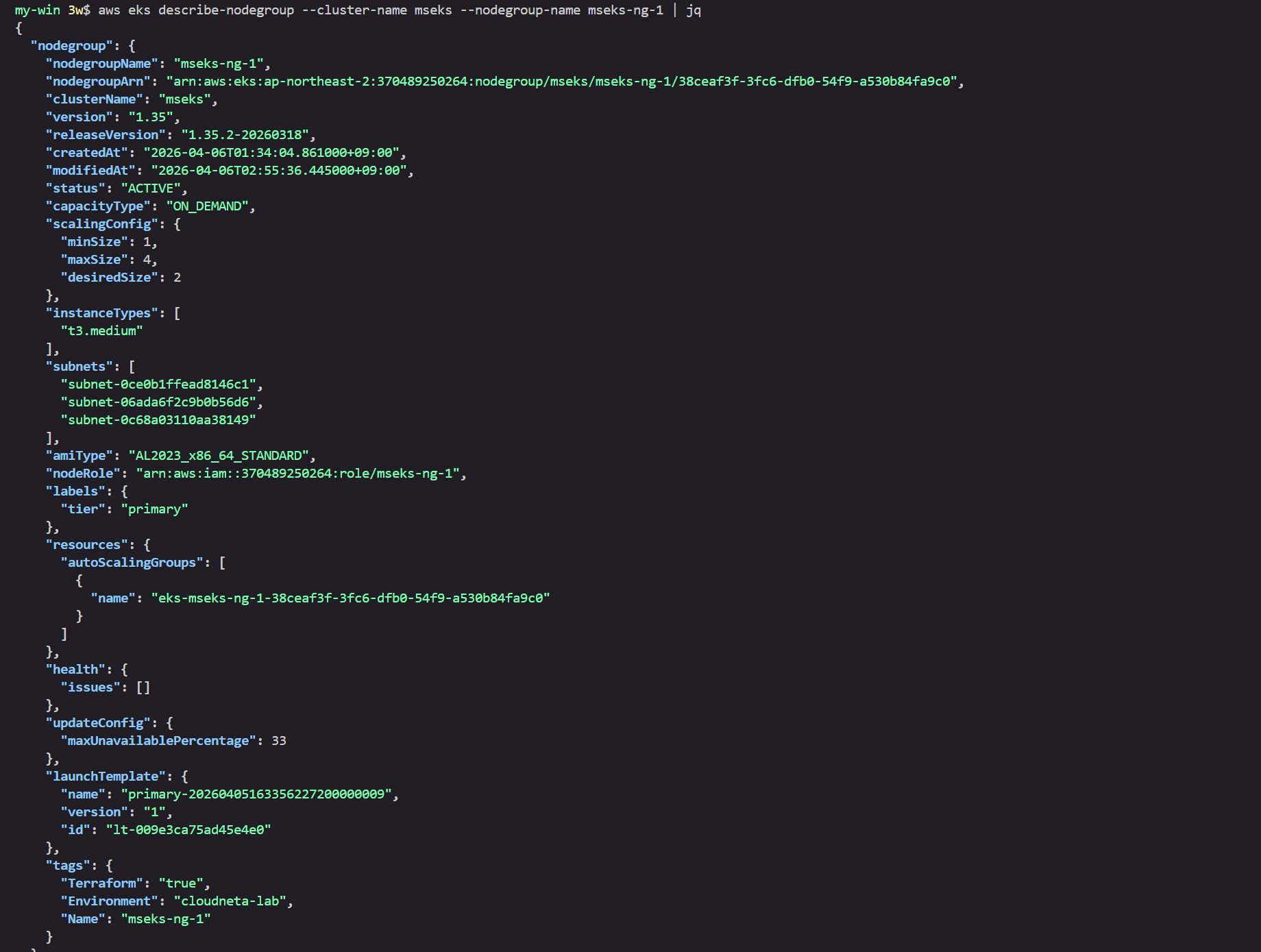
# 클러스터롤에 권한 추가
kubectl get clusterrole kube-prometheus-stack-prometheus
kubectl patch clusterrole kube-prometheus-stack-prometheus --type=json -p='[
{
"op": "add",
"path": "/rules/-",
"value": {
"verbs": ["get"],
"apiGroups": ["metrics.eks.amazonaws.com"],
"resources": ["kcm/metrics", "ksh/metrics"]
}
}
]'
kubectl rolesum kube-prometheus-stack-prometheus -n monitoring
...
• [CRB] */kube-prometheus-stack-prometheus ⟶ [CR] */kube-prometheus-stack-prometheus
Resource Name Exclude Verbs G L W C U P D DC
...
kcm.metrics.eks.amazonaws.com/metrics [*] [-] [-] ✔ ✖ ✖ ✖ ✖ ✖ ✖ ✖
ksh.metrics.eks.amazonaws.com/metrics [*] [-] [-] ✔ ✖ ✖ ✖ ✖ ✖ ✖ ✖
...
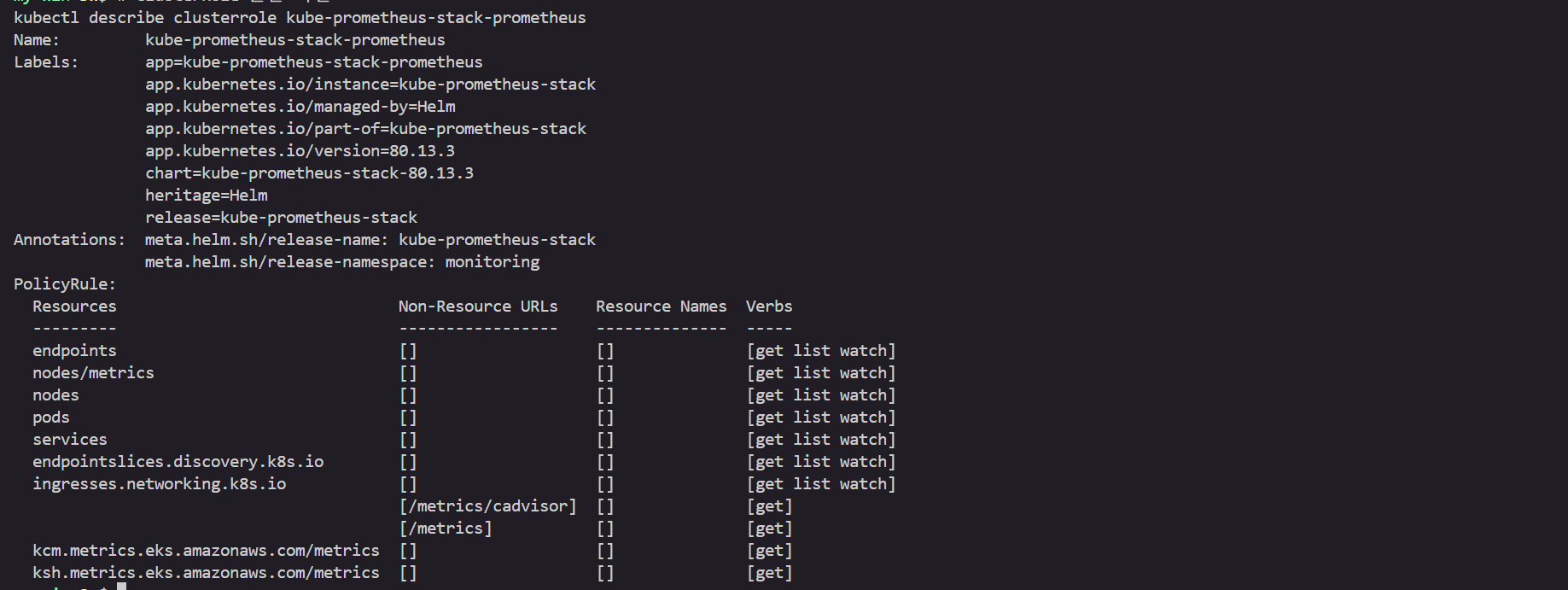
# 대시보드 다운로드
curl -O https://raw.githubusercontent.com/dotdc/grafana-dashboards-kubernetes/refs/heads/master/dashboards/k8s-system-api-server.json
# sed 명령어로 uid 일괄 변경 : 기본 데이터소스의 uid 'prometheus' 사용
sed -i -e 's/${DS_PROMETHEUS}/prometheus/g' k8s-system-api-server.json
# my-dashboard 컨피그맵 생성 : Grafana 포드 내의 사이드카 컨테이너가 grafana_dashboard="1" 라벨 탐지!
kubectl create configmap my-dashboard --from-file=k8s-system-api-server.json -n monitoring
kubectl label configmap my-dashboard grafana_dashboard="1" -n monitoring
# 대시보드 경로에 추가 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- ls -l /tmp/dashboards
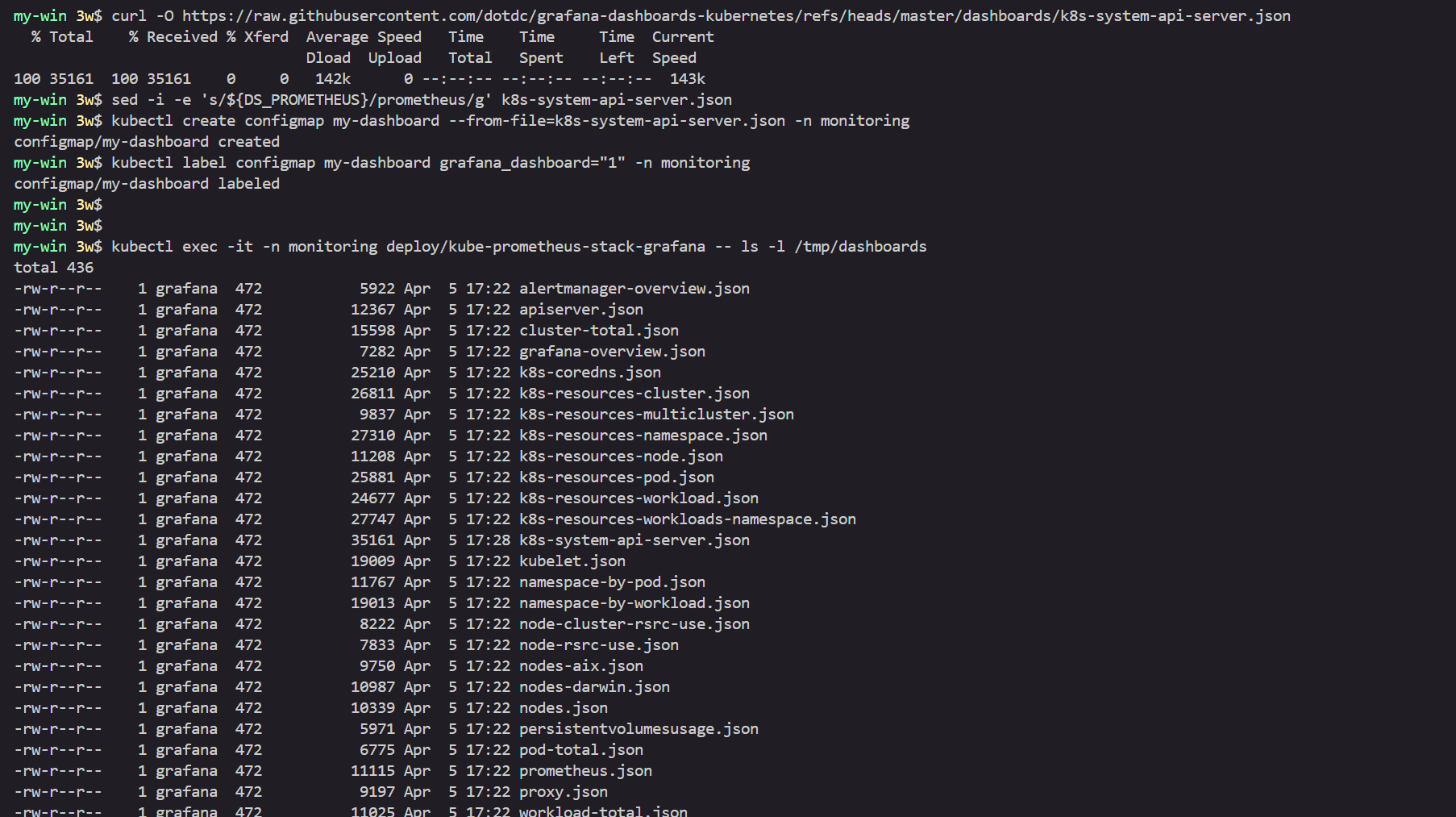
2. EKS 관리형 노드 그룹
관리형 노드 그룹 myeks-ng-1
# 노드 정보 확인
kubectl get nodes --label-columns eks.amazonaws.com/nodegroup,kubernetes.io/arch,eks.amazonaws.com/capacityType
# 관리형 노드 그룹 확인
eksctl get nodegroup --cluster myeks
aws eks describe-nodegroup --cluster-name myeks --nodegroup-name myeks-ng-1 | jq
관리형 노드 그룹 myeks-ng-2
-
AWS Graviton 프로세서
- 64-bit Arm 프로세서 코어 기반의 AWS 커스텀 반도체 ⇒ 20~40% 향상된 가격대비 성능
-
주석처리된 2번 테라폼 코드 주석 해제 후 테라폼 Plan / Apply

# sample-app 디플로이먼트 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
labels:
app: sample-app
spec:
replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
nodeSelector:
kubernetes.io/arch: arm64
containers:
- name: sample-app
image: nginx:alpine
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 128Mi
EOF
# 확인
kubectl describe pod -l app=sample-app
# 파드에 tolerations 설정으로 배치 실행!
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
labels:
app: sample-app
spec:
replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
nodeSelector:
kubernetes.io/arch: arm64
tolerations:
- key: "cpuarch"
operator: "Equal"
value: "arm64"
effect: "NoExecute"
containers:
- name: sample-app
image: nginx:alpine
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 128Mi
EOF
kubectl get events -w --sort-by '.lastTimestamp'
# 확인
kubectl get pod -l app=sample-app
kubectl describe pod -l app=sample-app
# 삭제
kubectl delete deploy sample-app
# 샘플 애플리케이션 배포
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: mario
labels:
app: mario
spec:
replicas: 1
selector:
matchLabels:
app: mario
template:
metadata:
labels:
app: mario
spec:
nodeSelector:
kubernetes.io/arch: arm64
tolerations:
- key: "cpuarch"
operator: "Equal"
value: "arm64"
effect: "NoExecute"
containers:
- name: mario
image: pengbai/docker-supermario
EOF
kubectl get events -w --sort-by '.lastTimestamp'
# 확인
kubectl get pod -l app=mario
kubectl stern -l app=mario
+ mario-7cb97489b5-ftcbf › mario
mario-7cb97489b5-ftcbf mario exec /usr/local/tomcat/bin/catalina.sh: exec format error
# 삭제
kubectl delete deploy mario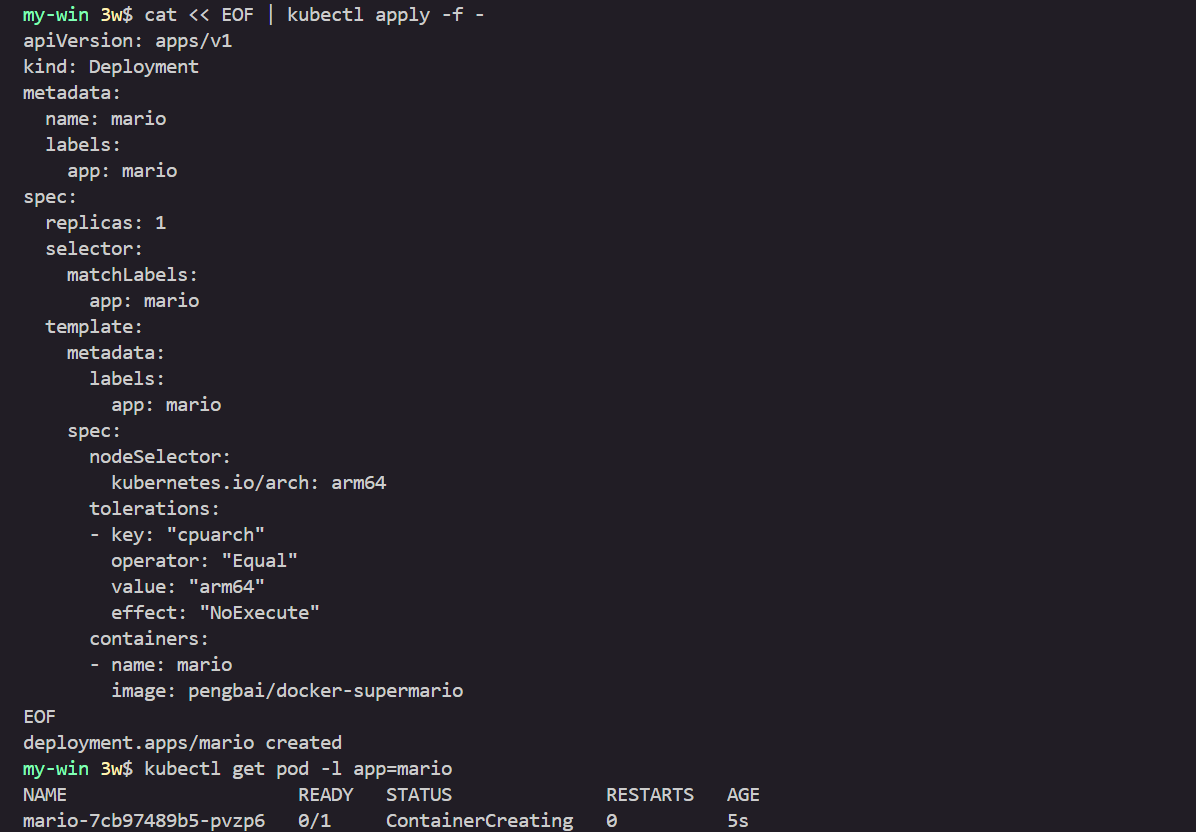
관리형 노드 그룹 myeks-ng-3
-
주석처리된 3번 테라폼 코드 주석 해제 후 테라폼 Plan / Apply
-
Spot instances 노드 그룹
-
Amazon Web Services 의 Spot 인스턴스는 일반 온디맨드 인스턴스보다 최대 70~90% 저렴하지만, 조건이 붙음
- AWS에 남는 서버 자원(유휴 capacity)을 활용
- 필요해지면 AWS가 강제로 회수 가능 (인터럽트)
- 보통 2분 전에 종료 알림 제공
# 신규 노드 그룹 생성 확인
kubectl get nodes --label-columns eks.amazonaws.com/nodegroup,kubernetes.io/arch,eks.amazonaws.com/capacityType
kubectl get nodes -L eks.amazonaws.com/capacityType
eksctl get nodegroup --cluster myeks
aws eks describe-nodegroup --cluster-name myeks --nodegroup-name myeks-ng-3 | jq
aws eks describe-nodegroup --cluster-name myeks --nodegroup-name myeks-ng-3 | jq .nodegroup.instanceTypes
kubectl get node -l tier=third
kubectl get node -l eks.amazonaws.com/capacityType=SPOT
kubectl describe node -l eks.amazonaws.com/capacityType=SPOT
eks-node-viewer --extra-labels eks-node-viewer/node-age
# 스팟 EC2 인스턴스 확인
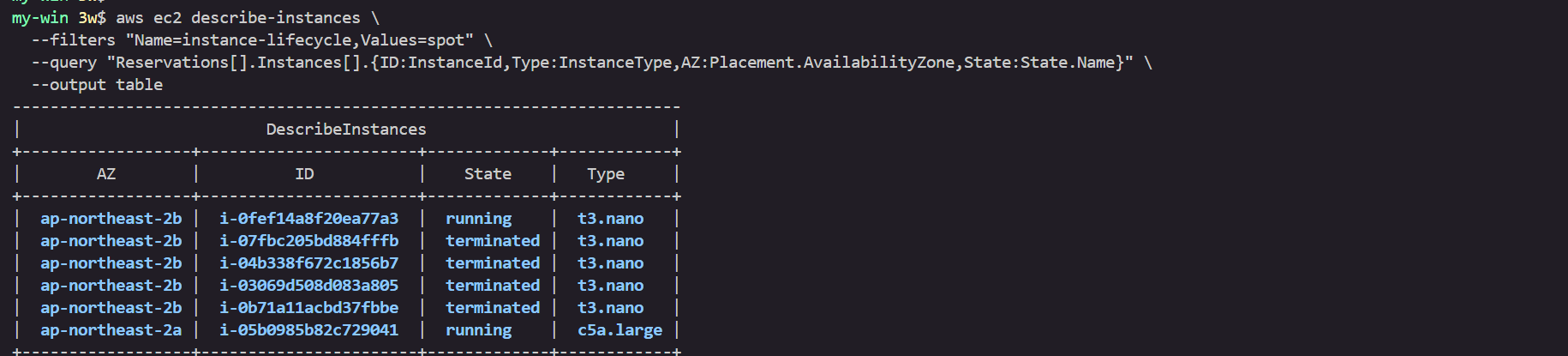
aws ec2 describe-instances \
--filters "Name=instance-lifecycle,Values=spot" \
--query "Reservations[].Instances[].{ID:InstanceId,Type:InstanceType,AZ:Placement.AvailabilityZone,State:State.Name}" \
--output table
# 스팟 요청 확인 : Spot Instance Request
aws ec2 describe-spot-instance-requests \
--query "SpotInstanceRequests[].{ID:SpotInstanceRequestId,State:State,Type:Type,InstanceId:InstanceId}" \
--output table
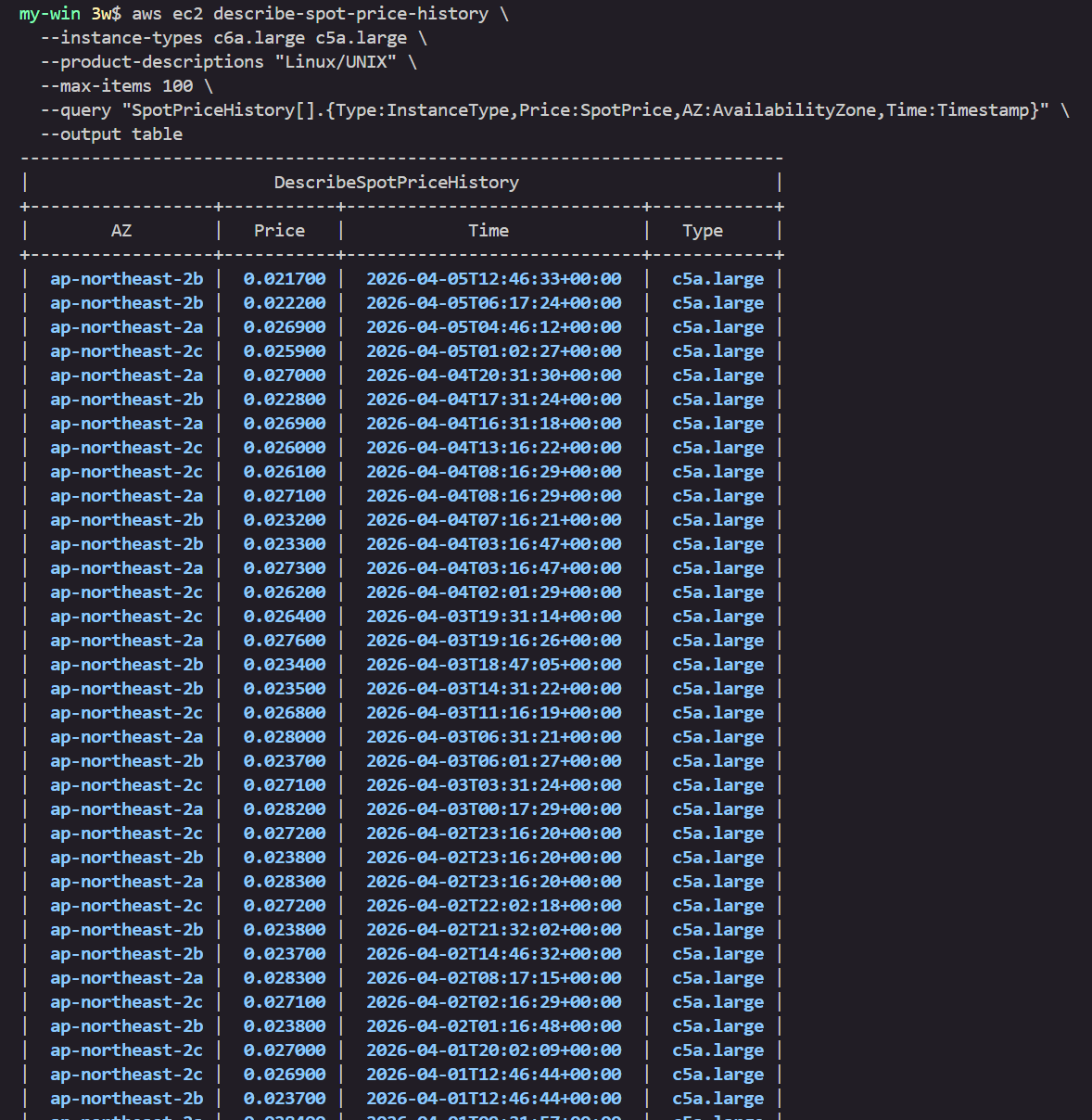
# Spot 가격 조회 : # t3a.large t3a.medium
aws ec2 describe-spot-price-history \
--instance-types c6a.large c5a.large \
--product-descriptions "Linux/UNIX" \
--max-items 100 \
--query "SpotPriceHistory[].{Type:InstanceType,Price:SpotPrice,AZ:AvailabilityZone,Time:Timestamp}" \
--output table


# 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
terminationGracePeriodSeconds: 3
containers:
- name: busybox
image: busybox
command:
- "/bin/sh"
- "-c"
- "while true; do date >> /home/pod-out.txt; cd /home; sync; sync; sleep 10; done"
nodeSelector:
eks.amazonaws.com/capacityType: SPOT
EOF
# 파드가 배포된 노드 정보 확인
kubectl get pod -owide
# 삭제
kubectl delete pod busybox

3. HPA - Horizontal Pod Autoscaler
소개
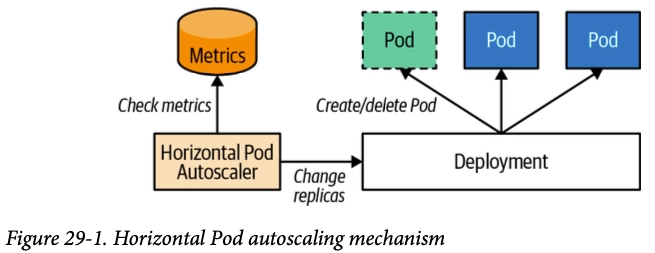
- Kubernetes에서 애플리케이션의 Pod 복제본 수를 확장하는 것을 수평 Pod 자동 확장이라고 합니다.
- 수평적이기 때문에 트래픽 증가를 위해 복제본 수를 늘리것이고, 수직적은 복제본에서 사용할 수 있는 리소스를 늘리는 것을 의미합니다.
- 일반적으로 시스템을 확장하려면 수평 스케일링을 사용해야 합니다.
- Kubernetes에는 수평 포드 오토스케일러(HPA)라는 기능이 포함되어 있습니다. 이 시스템은 CPU 사용량과 같은 포드 메트릭을 관찰하고 대상으로 지정할 수 있으며, 일부 스케일링 제한(최소 및 최대 복제본)도 포함되어 있습니다.
- 그런 다음 HPA는 포드를 생성하고 제거하여 사용자의 메트릭을 충족하려고 시도합니다.
- CPU의 경우, 예를 들어 20%의 CPU 사용률을 목표로 하는 경우, HPA는 평균 사용량(모든 포드에서)이 20%를 초과할 때 복제본을 추가하고(팟이 리소스 요청에서 요청한 것의) 20% 이하로 떨어지면 복제본을 제거합니다.
- 이러한 행동은 사용자가 제공하는 최소 및 최대 한도와 너무 많은 이탈을 피하기 위한 재사용 대기 시간의 영향을 받습니다.
HPA 샘플 애플리케이션 배포
# Run and expose php-apache server
# https://k8s.io/examples/application/php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
# 확인
kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
...
# 모니터링 : 터미널2개 사용
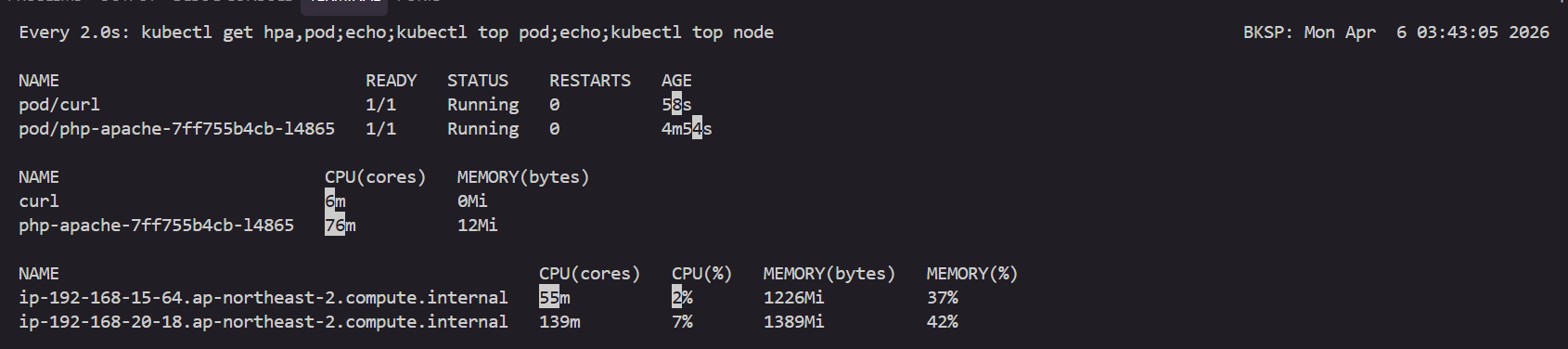
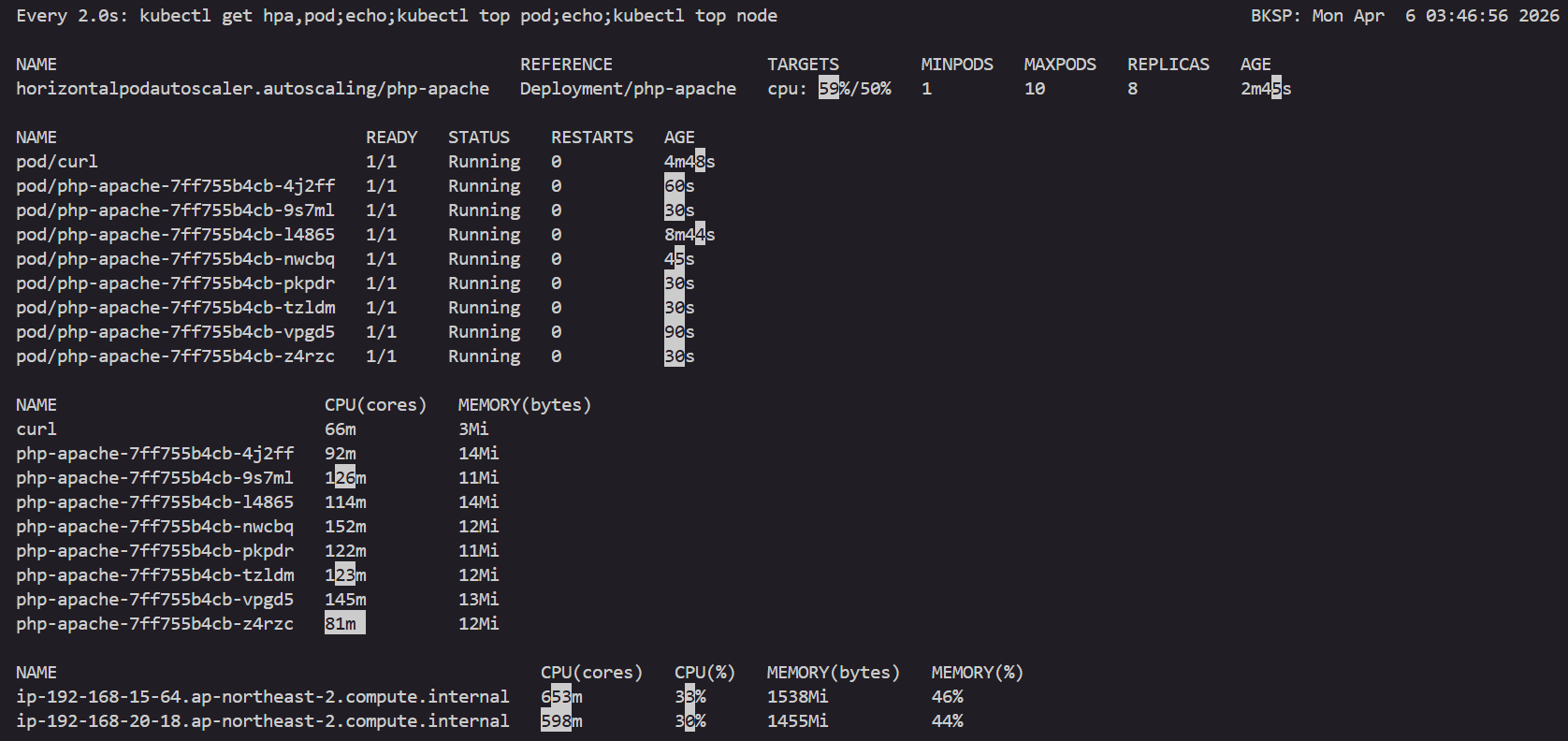
watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
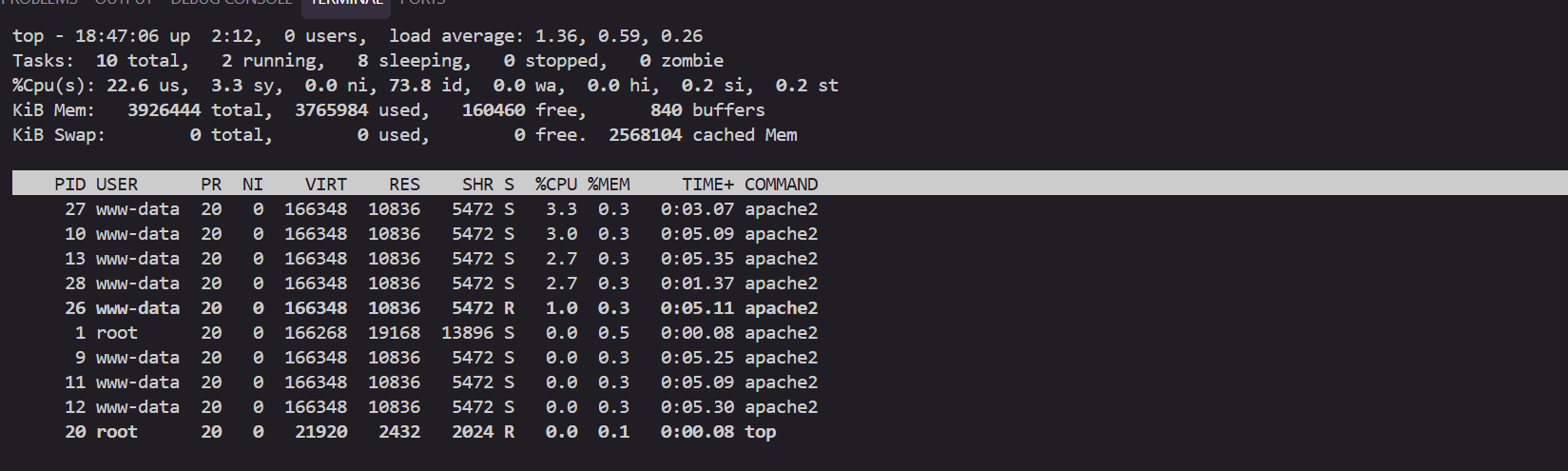
kubectl exec -it deploy/php-apache -- top
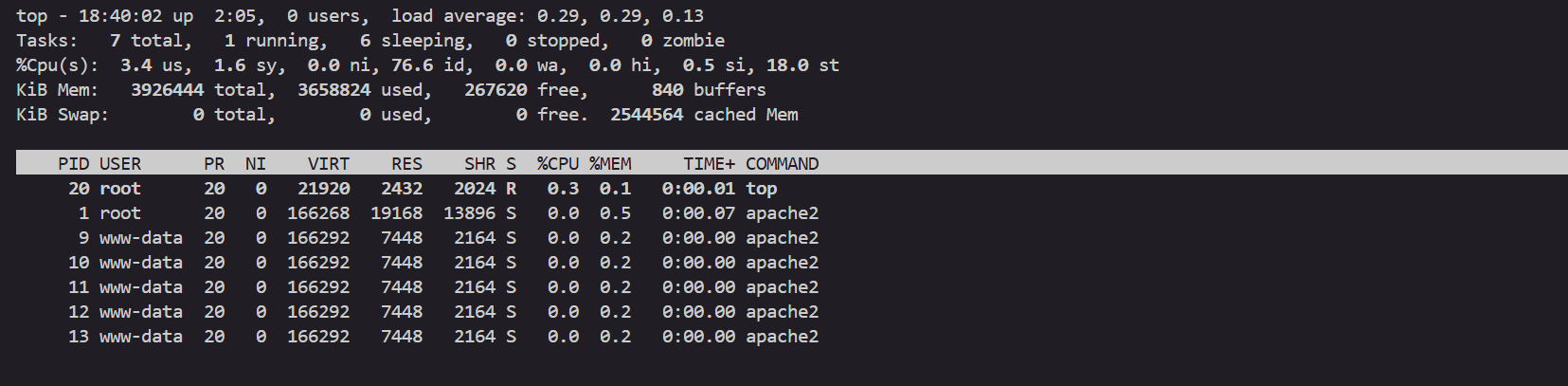
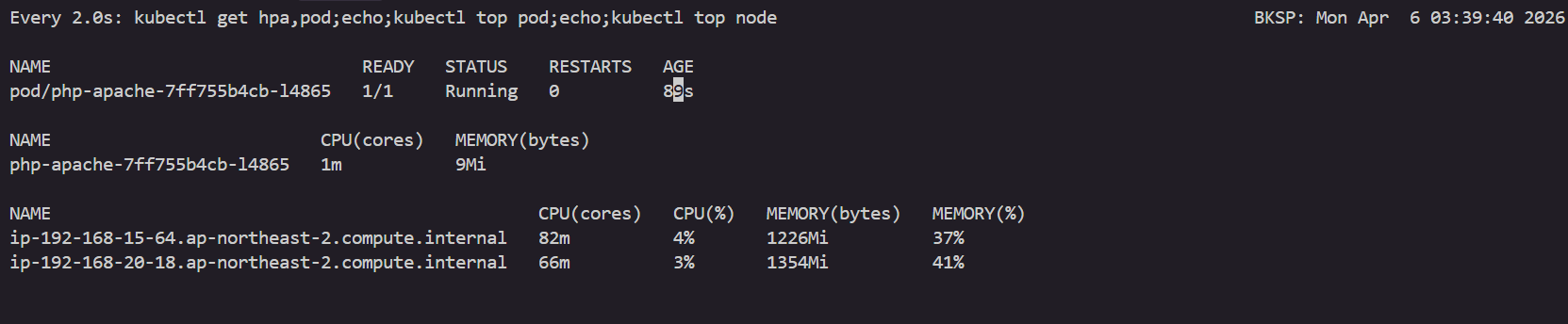
부하 발생을 위한 클라이언트용 파드 배포 및 반복 호출
# curl 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: curl
spec:
containers:
- name: curl
image: curlimages/curl:latest
command: ["sleep", "3600"]
restartPolicy: Never
EOF
# 서비스명으로 호출 : 'kubectl exec -it deploy/php-apache -- top' 에 CPU 증가 확인!
kubectl exec -it curl -- curl php-apache
kubectl exec -it curl -- curl php-apache
# 서비스명으로 반복 호출
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 1; done'
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.5; done'
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.1; done'
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.01; done'
혹은 병렬 호출 (부하 테스트 느낌, 5개 worker 동시 요청)
kubectl exec -it curl -- sh -c '
for i in $(seq 1 5); do
while true; do curl -s php-apache & sleep 1; done &
done
wait'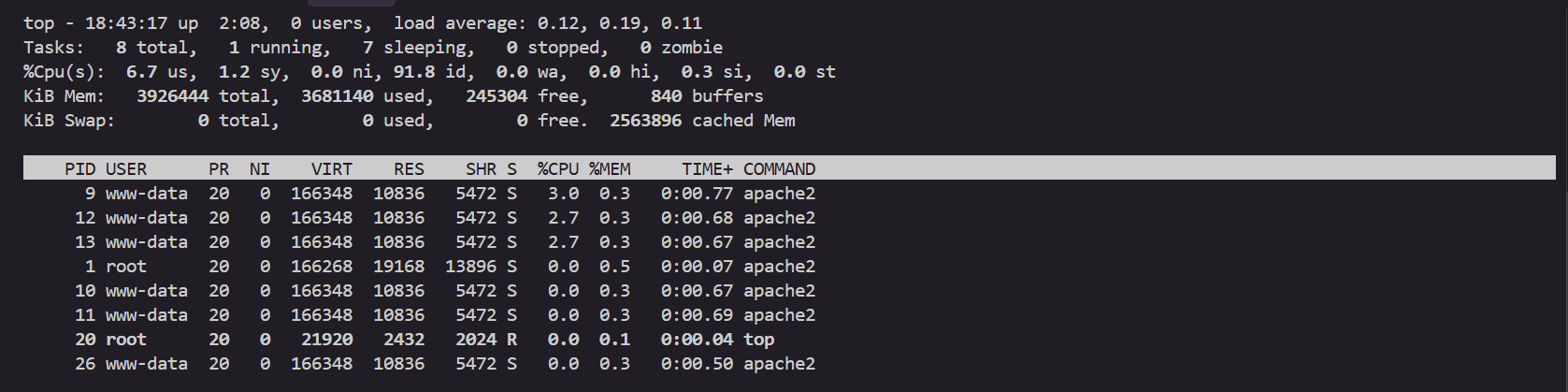
HPA 정책 생성 및 부하 발생 후 파드 오토 스케일링 확인
# Create the HorizontalPodAutoscaler : requests.cpu=200m - 알고리즘
# Since each pod requests 200 milli-cores by kubectl run, this means an average CPU usage of 100 milli-cores.
cat <<EOF | kubectl apply -f -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
EOF
혹은
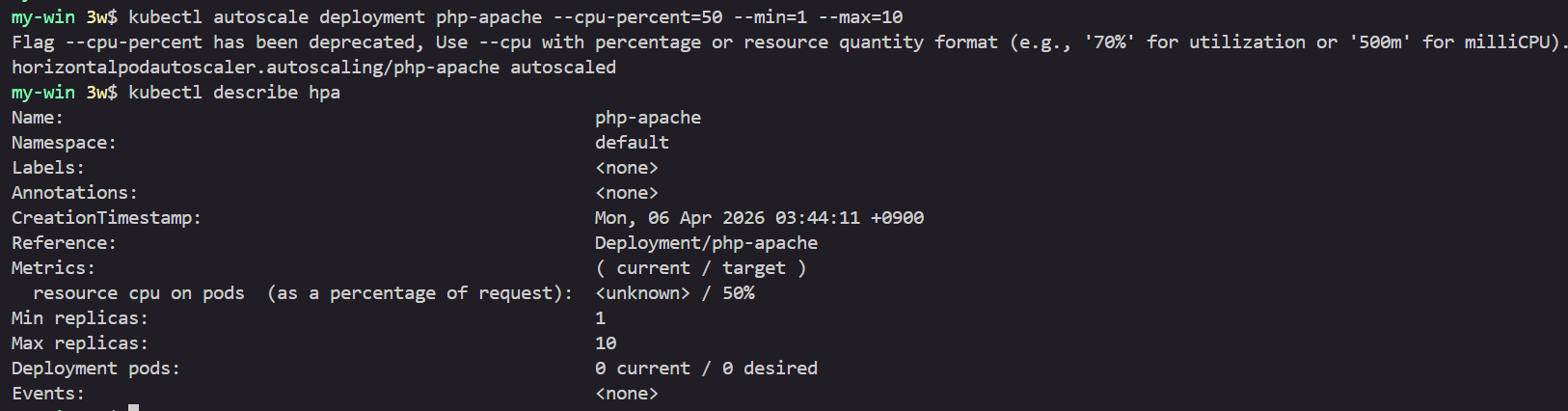
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
# 확인
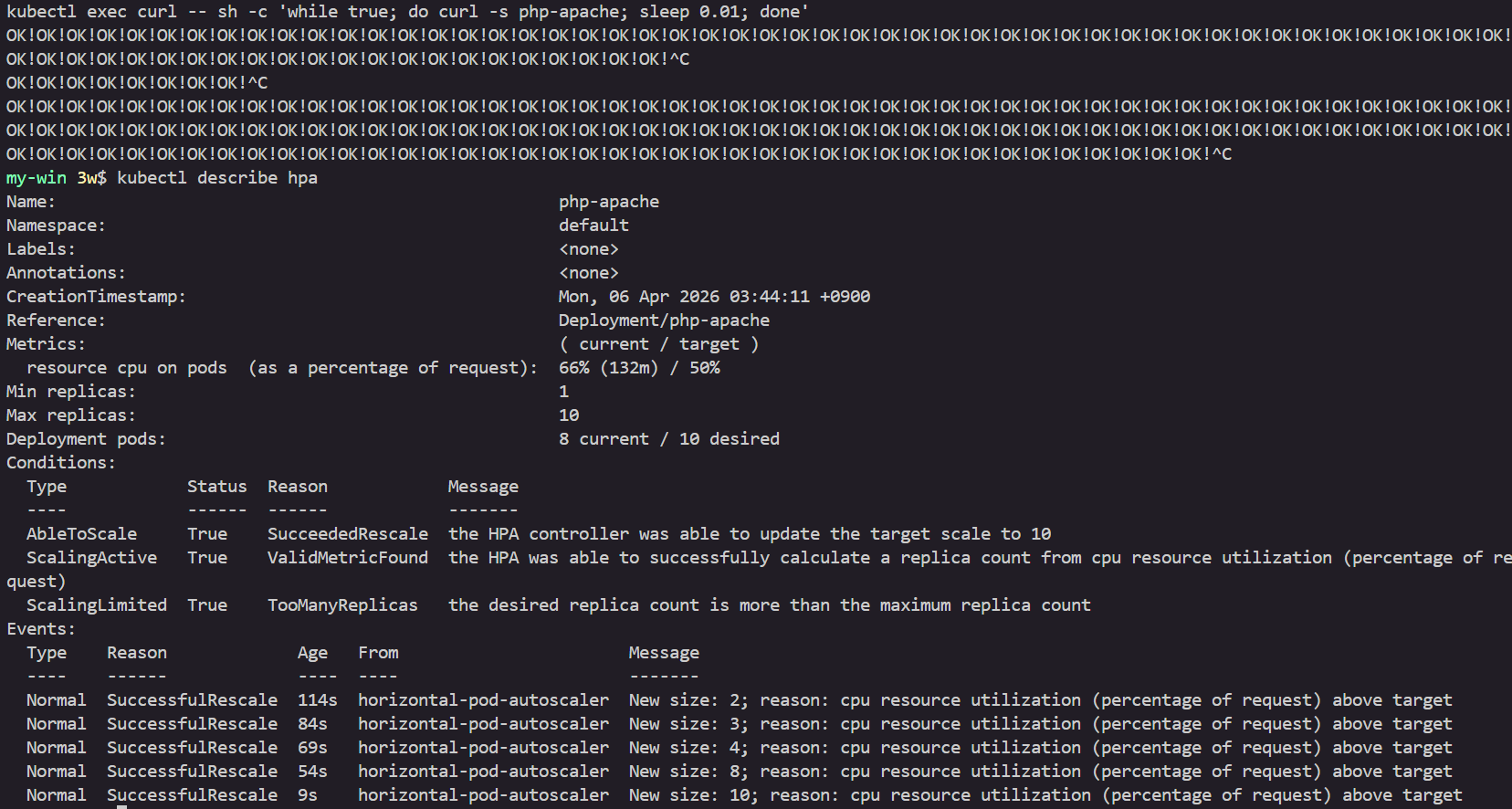
kubectl describe hpa
...
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
...
# HPA 설정 확인
kubectl get hpa php-apache -o yaml | kubectl neat
spec:
minReplicas: 1 # [4] 또는 최소 1개까지 줄어들 수도 있습니다
maxReplicas: 10 # [3] 포드를 최대 10개까지 늘립니다
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache # [1] php-apache 의 자원 사용량에서
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # [2] CPU 활용률이 50% 이상인 경우
# 반복 접속 1 (파드1 IP로 접속) >> 아래 각각 실행 후 최대 증가 갯수 확인 해보기! 스터디 시간 상 sleep 0.01 바로 실행!
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.5; done'
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.1; done'
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.01; done'
# 반복 접속 2 (서비스명 도메인으로 파드들 분산 접속) >> 증가 확인(몇개까지 증가되는가? 그 이유는?) 후 중지
## >> [scale back down] 중지 5분 후 파드 갯수 감소 확인
# Run this in a separate terminal
# so that the load generation continues and you can carry on with the rest of the steps
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
# Horizontal Pod Autoscaler Status Conditions
kubectl describe hpa
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 13m horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 11m horizontal-pod-autoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 11m horizontal-pod-autoscaler New size: 6; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 10m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 5m35s horizontal-pod-autoscaler New size: 7; reason: All metrics below target
Normal SuccessfulRescale 4m35s horizontal-pod-autoscaler New size: 5; reason: All metrics below target
Normal SuccessfulRescale 4m5s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Normal SuccessfulRescale 3m50s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
4. VPA - Vertical Pod Autoscaler
소개
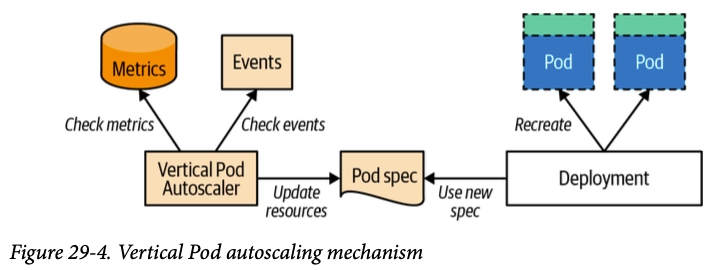
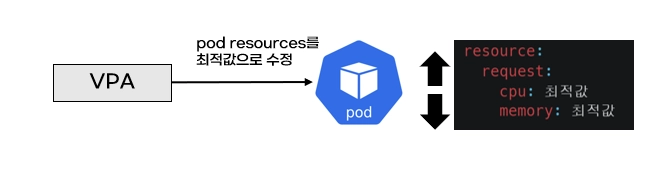
- pod resources.request을 최대한 최적값으로 수정
- 계산 방식 : ‘기준값(파드가 동작하는데 필요한 최소한의 값)’ 결정 → ‘마진(약간의 적절한 버퍼)’ 추가
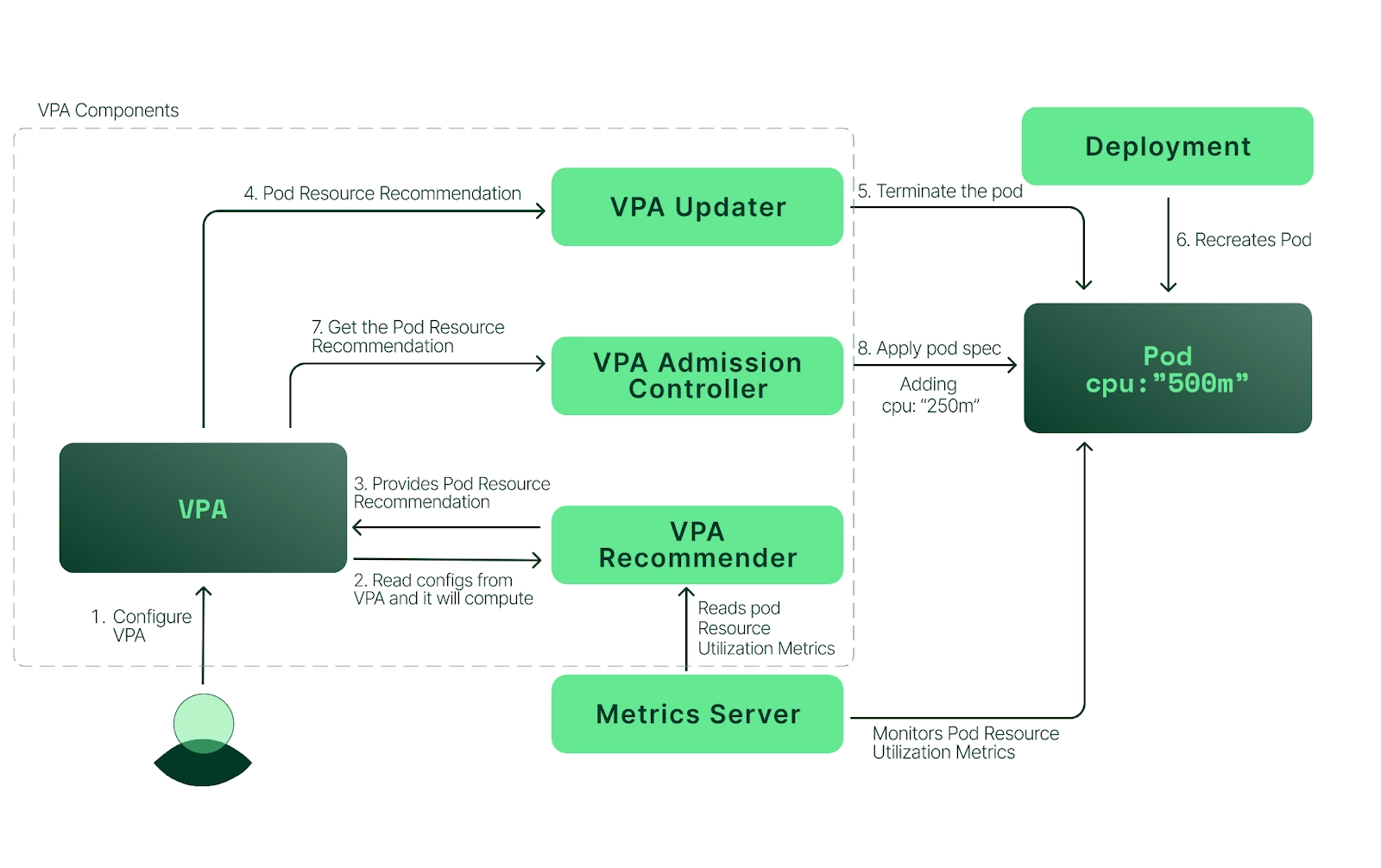
VPA 예제 진행
# CRD 설치 - feat: CPU startup boost in master (#9141)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/autoscaler/refs/heads/master/vertical-pod-autoscaler/deploy/vpa-v1-crd-gen.yaml
# RBAC 설치 - VPA: Update vpa-rbac.yaml for allowing in place resize requests
kubectl apply -f https://raw.githubusercontent.com/kubernetes/autoscaler/refs/heads/master/vertical-pod-autoscaler/deploy/vpa-rbac.yaml
# 코드 다운로드
git clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
tree hack
# Deploy the Vertical Pod Autoscaler to your cluster with the following command.
watch -d kubectl get pod -n kube-system
cat hack/vpa-up.sh
./hack/vpa-up.sh
kubectl get crd | grep autoscaling
kubectl get mutatingwebhookconfigurations vpa-webhook-config
kubectl get mutatingwebhookconfigurations vpa-webhook-config -o json | jq
# 모니터링
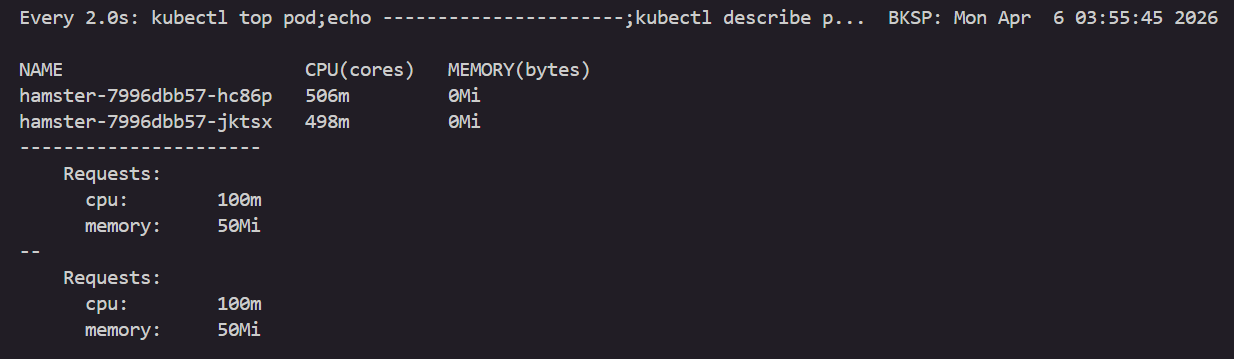
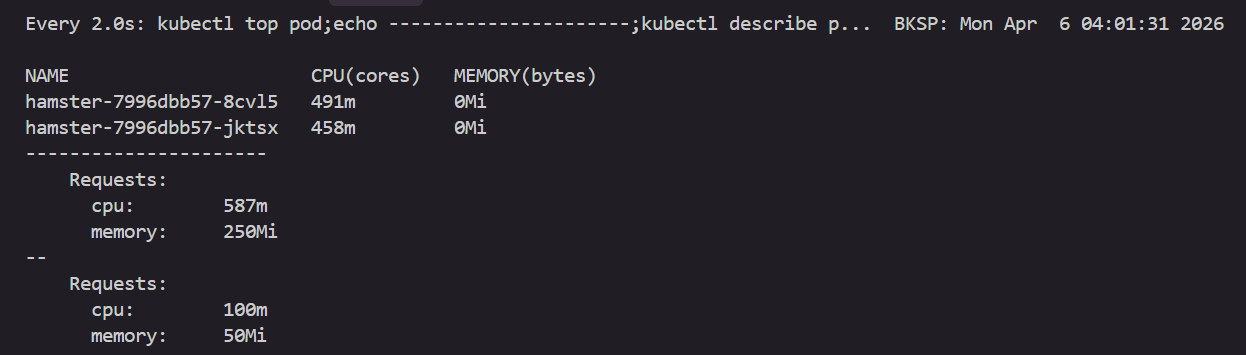
watch -d "kubectl top pod;echo "----------------------";kubectl describe pod | grep Requests: -A2"
# 공식 예제 배포
cd ~/autoscaler/vertical-pod-autoscaler/
cat examples/hamster.yaml
kubectl apply -f examples/hamster.yaml && kubectl get vpa -w
# 파드 리소스 Requestes 확인
kubectl describe pod | grep Requests: -A2
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 587m
memory: 262144k
--
Requests:
cpu: 587m
memory: 262144k
# VPA에 의해 기존 파드 삭제되고 신규 파드가 생성됨
kubectl get events --sort-by=".metadata.creationTimestamp" | grep VPA
2m16s Normal EvictedByVPA pod/hamster-5bccbb88c6-s6jkp Pod was evicted by VPA Updater to apply resource recommendation.
76s Normal EvictedByVPA pod/hamster-5bccbb88c6-jc6gq Pod was evicted by VPA Updater to apply resource recommendation.

5. KEDA - Kubernetes Event-driven Autoscaling
소개
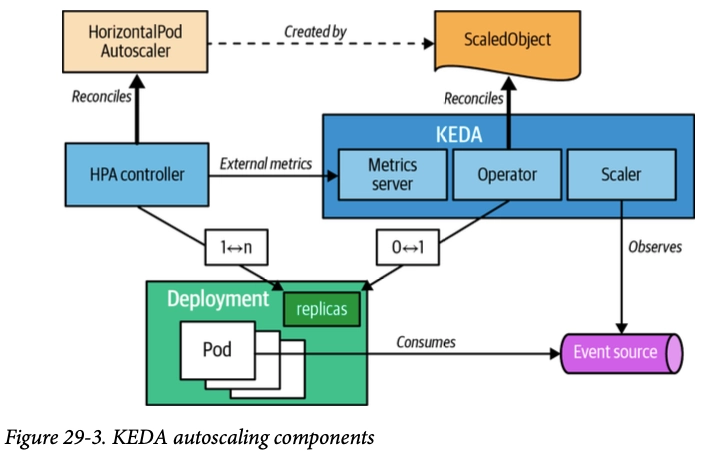
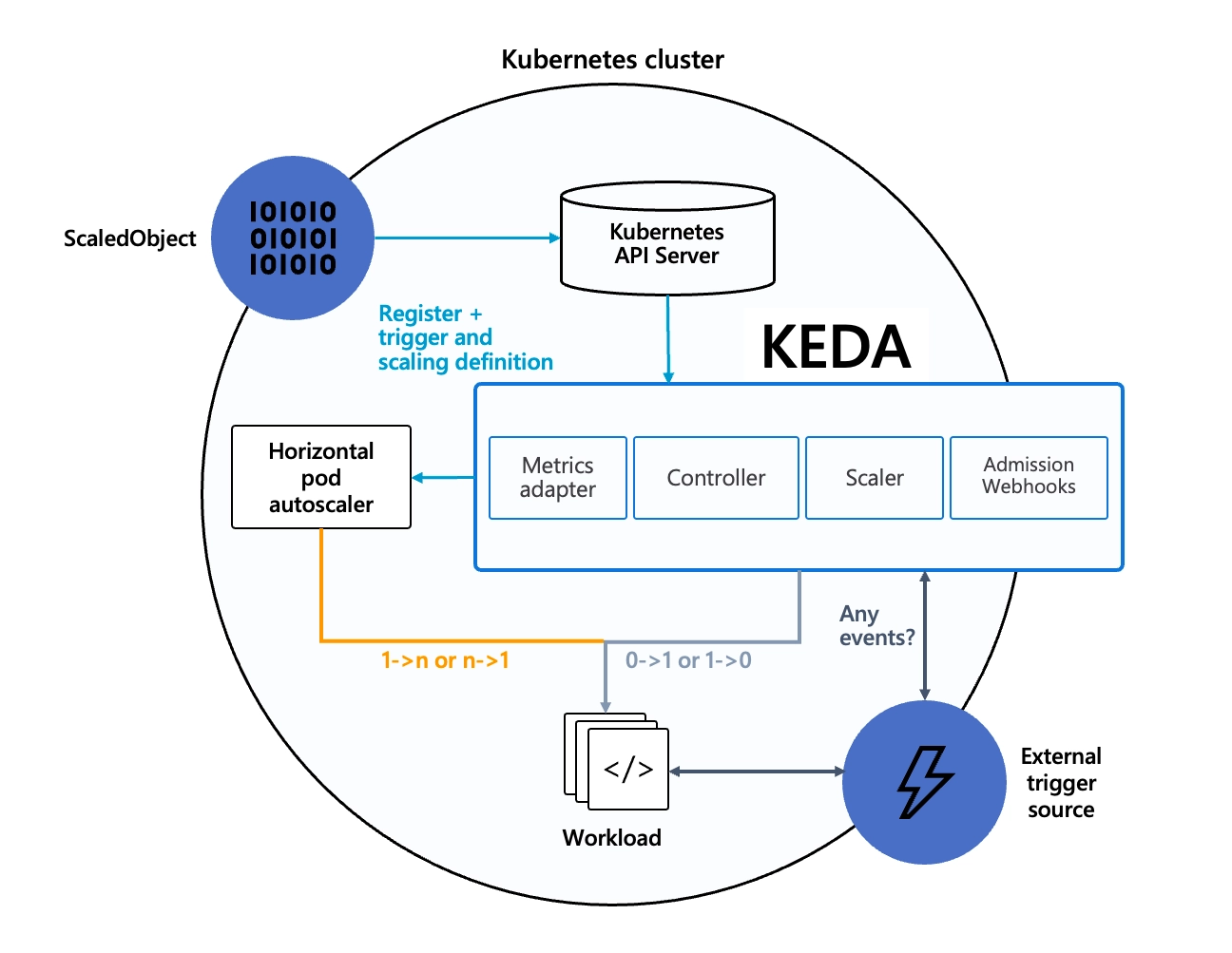
- KEDA는 HPA와 달리 리소스가 아닌 이벤트(예: task queue)를 기반으로 더 빠르게 스케일링한다.
KEDA with Helm 실습
# 설치 전 기존 metrics-server 제공 Metris API 확인
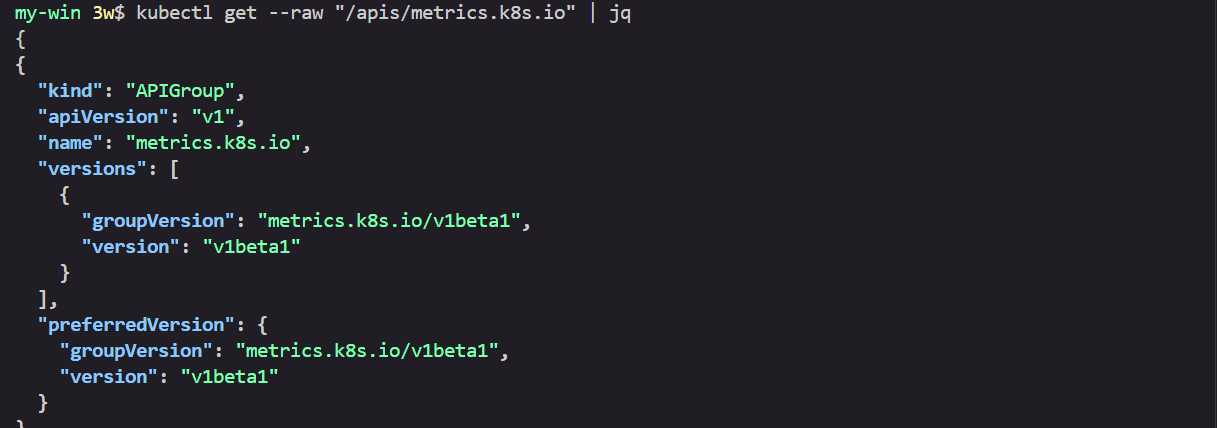
kubectl get --raw "/apis/metrics.k8s.io" -v=6 | jq
kubectl get --raw "/apis/metrics.k8s.io" | jq
{
"kind": "APIGroup",
"apiVersion": "v1",
"name": "metrics.k8s.io",
...
# KEDA 설치 : serviceMonitor 만으로도 충분할듯..
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8020
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --version 2.16.0 --namespace keda --create-namespace -f keda-values.yaml
# KEDA 설치 확인
kubectl get crd | grep keda
kubectl get all -n keda
kubectl get validatingwebhookconfigurations keda-admission -o yaml
kubectl get podmonitor,servicemonitors -n keda
kubectl get apiservice v1beta1.external.metrics.k8s.io -o yaml
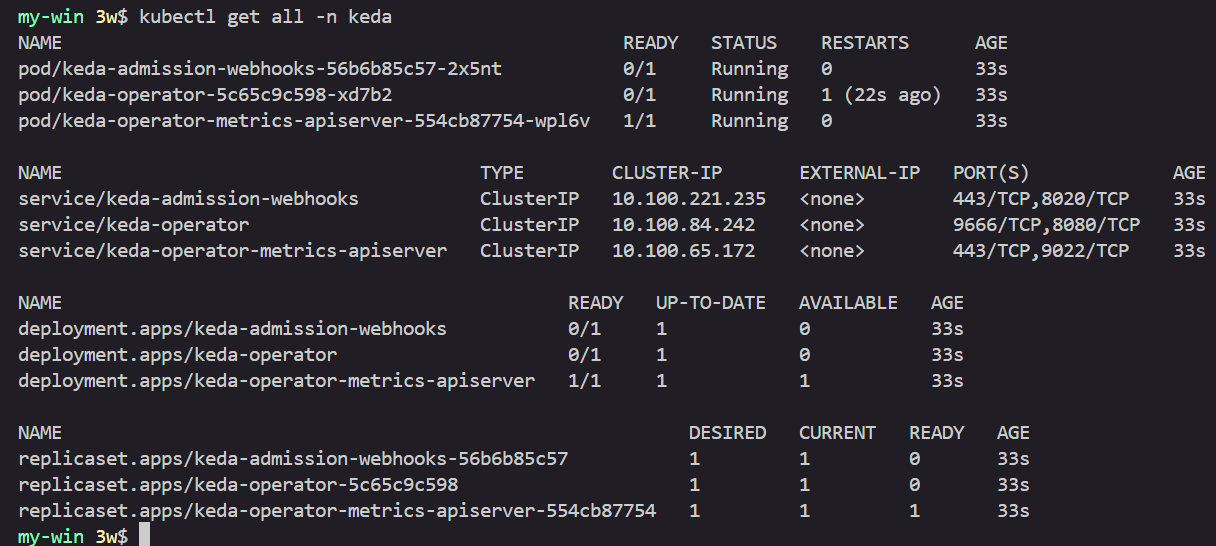
# CPU/Mem은 기존 metrics-server 의존하여, KEDA metrics-server는 외부 이벤트 소스(Scaler) 메트릭을 노출
## https://keda.sh/docs/2.16/operate/metrics-server/
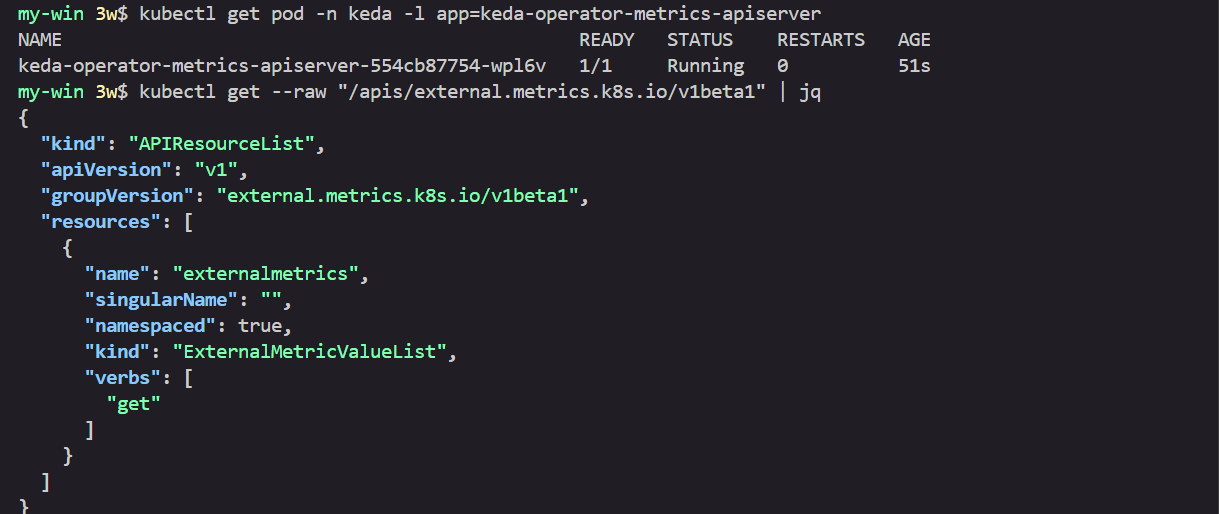
kubectl get pod -n keda -l app=keda-operator-metrics-apiserver
# Querying metrics exposed by KEDA Metrics Server
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "external.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "externalmetrics",
"singularName": "",
"namespaced": true,
"kind": "ExternalMetricValueList",
"verbs": [
"get"
]
}
]
}
# keda 네임스페이스에 디플로이먼트 생성
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml -n keda
kubectl get pod -n keda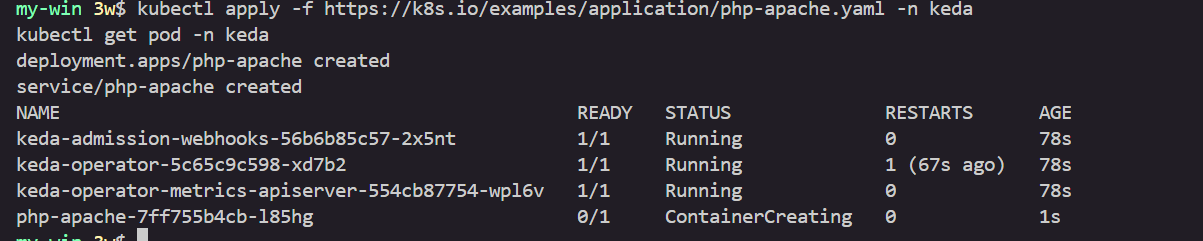
# ScaledObject 정책 생성 : cron
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2 # Specifies the maximum number of replicas to scale up to (defaults to 100).
pollingInterval: 30 # Specifies how often KEDA should check for scaling events
cooldownPeriod: 300 # Specifies the cool-down period in seconds after a scaling event
scaleTargetRef: # Identifies the Kubernetes deployment or other resource that should be scaled.
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers: # Defines the specific configuration for your chosen scaler, including any required parameters or settings
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
kubectl apply -f keda-cron.yaml -n keda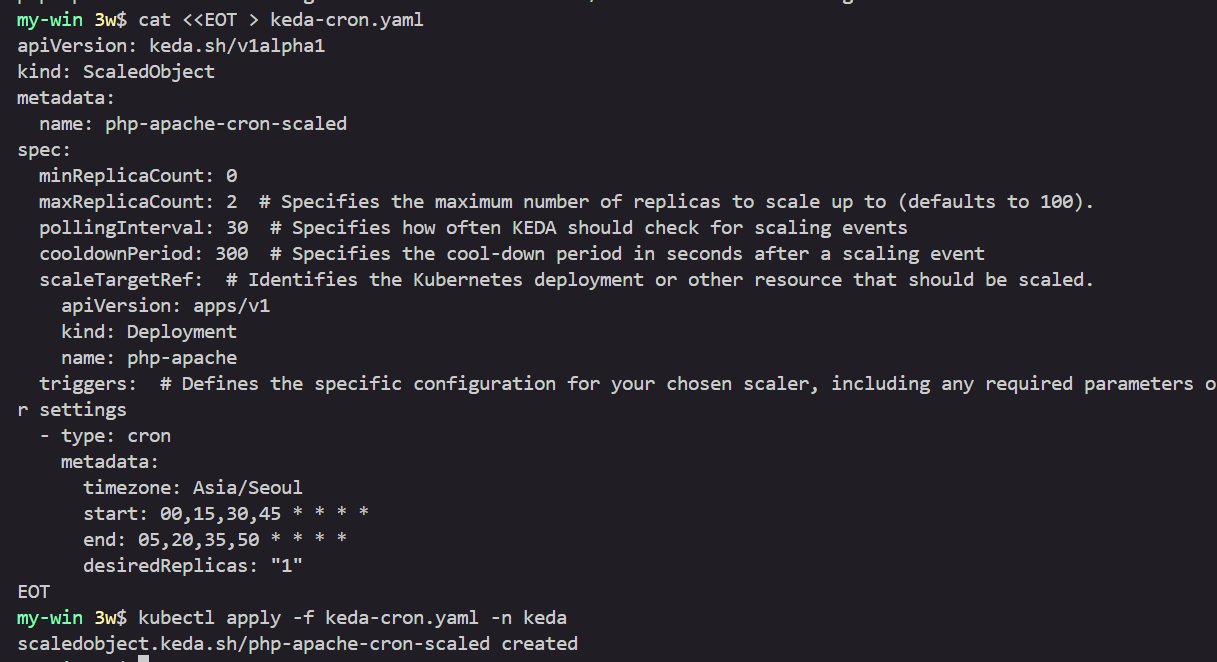
# 그라파나 대시보드 추가 : 대시보드 상단에 namespace : keda 로 변경하기!
# KEDA 대시보드 Import : https://github.com/kedacore/keda/blob/main/config/grafana/keda-dashboard.json
# 모니터링
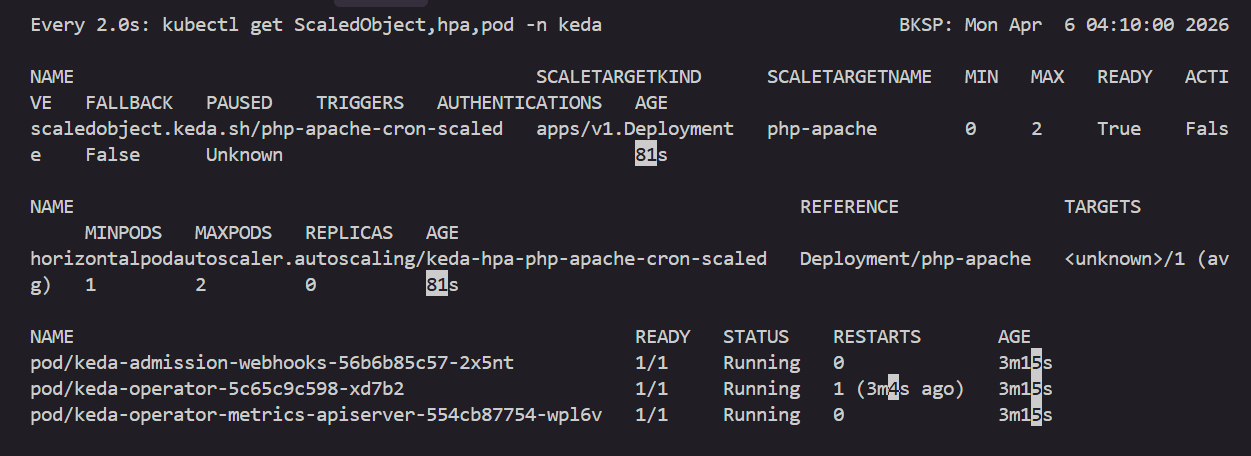
watch -d 'kubectl get ScaledObject,hpa,pod -n keda'
kubectl get ScaledObject -w
# 확인
kubectl get ScaledObject,hpa,pod -n keda
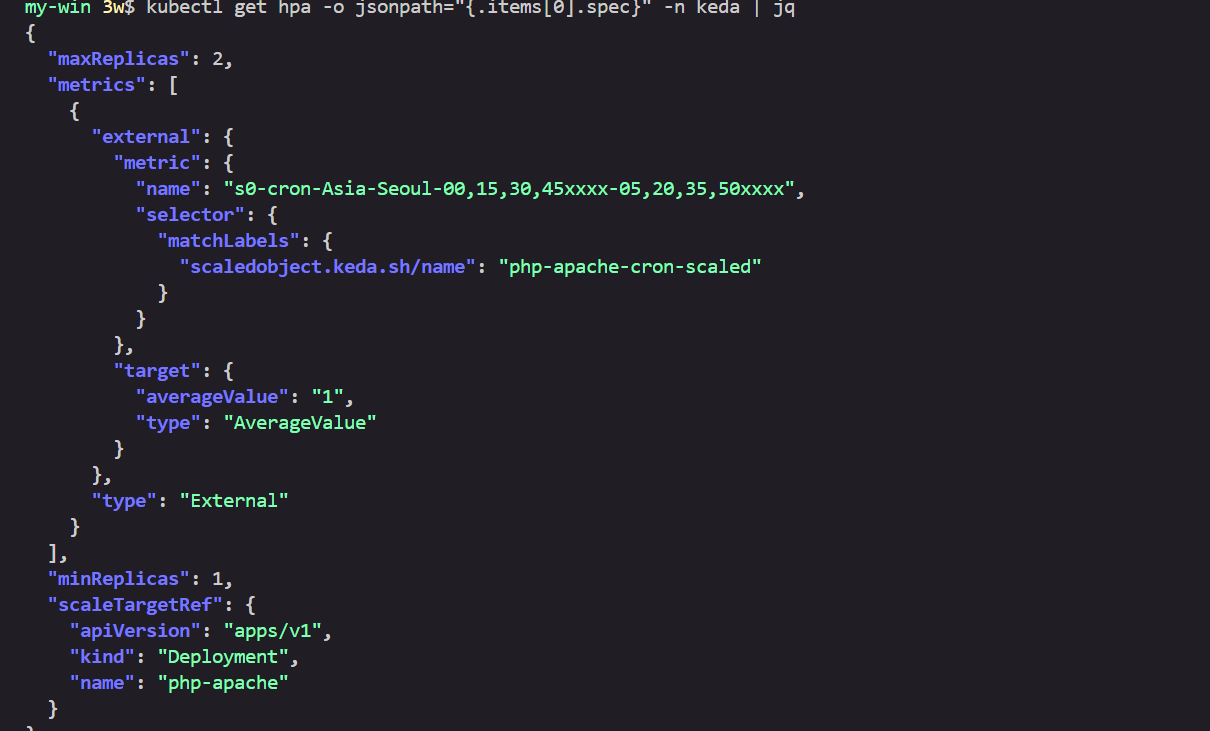
kubectl get hpa -o jsonpath="{.items[0].spec}" -n keda | jq
...
"metrics": [
{
"external": {
"metric": {
"name": "s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx",
"selector": {
"matchLabels": {
"scaledobject.keda.sh/name": "php-apache-cron-scaled"
}
}
},
"target": {
"averageValue": "1",
"type": "AverageValue"
}
},
"type": "External"
}
# KEDA 및 deployment 등 삭제
kubectl delete ScaledObject -n keda php-apache-cron-scaled && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda
6. CPA - Cluster Proportional Autoscaler
소개
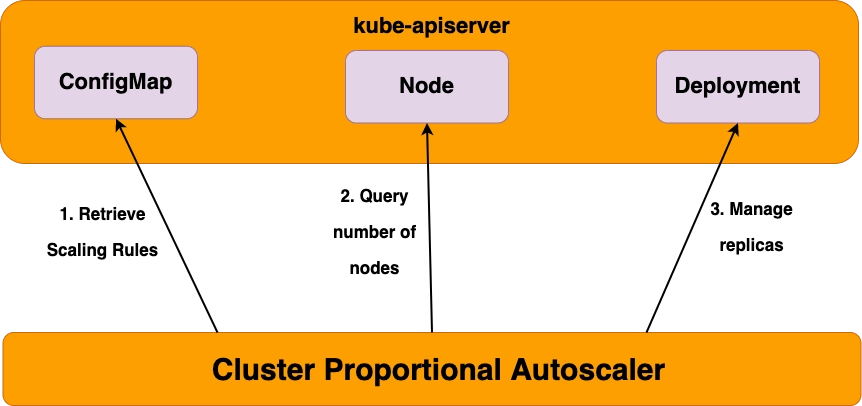
- 노드 수 증가에 비례하여 성능 처리가 필요한 애플리케이션(컨테이너/파드)를 수평으로 자동 확장
실습
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml

# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
kubectl describe cm cluster-proportional-autoscaler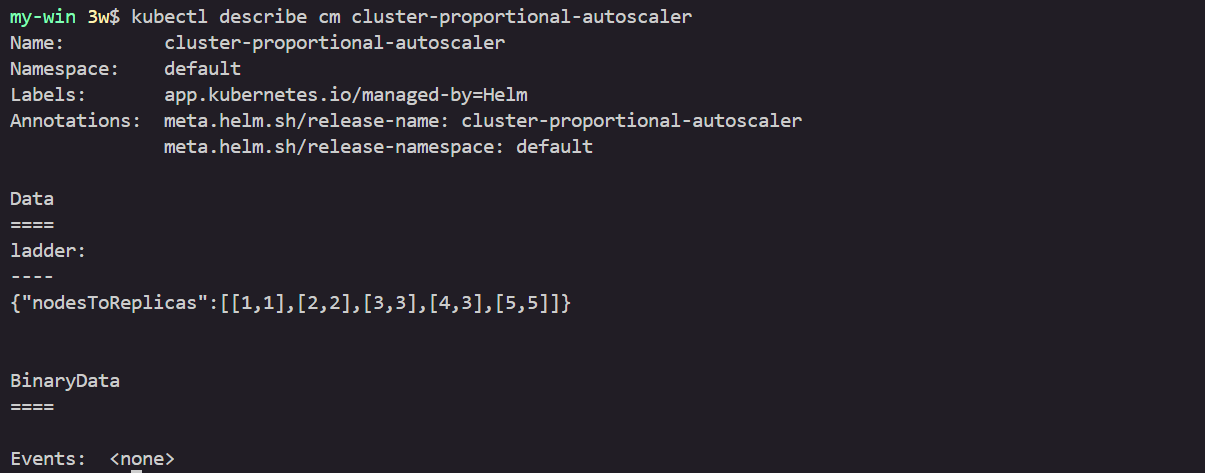
# 모니터링
watch -d kubectl get pod
# helm 업그레이드
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5개로 증가
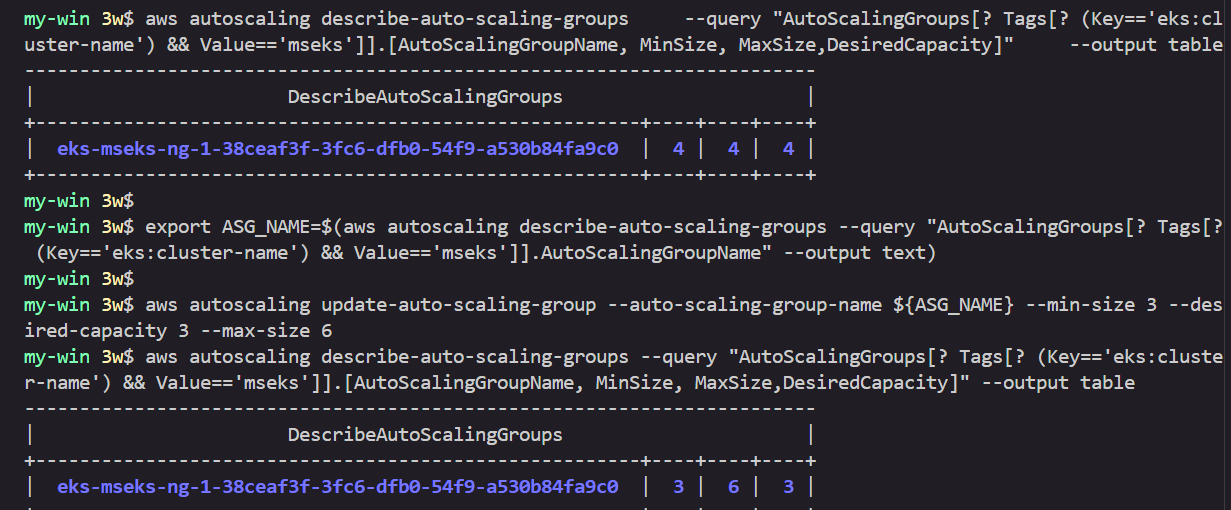
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table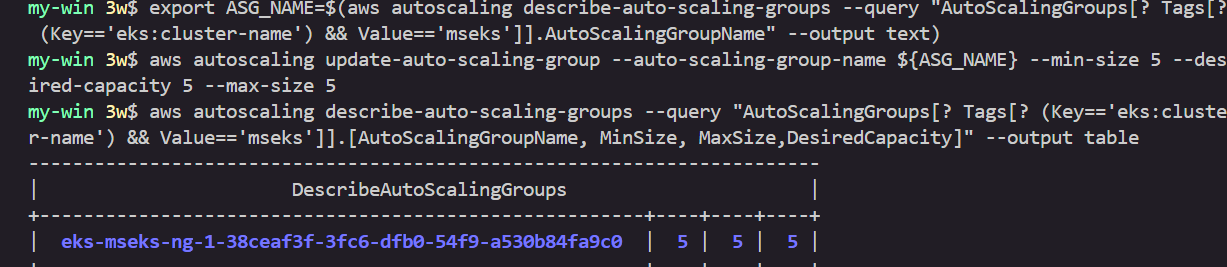
# 노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table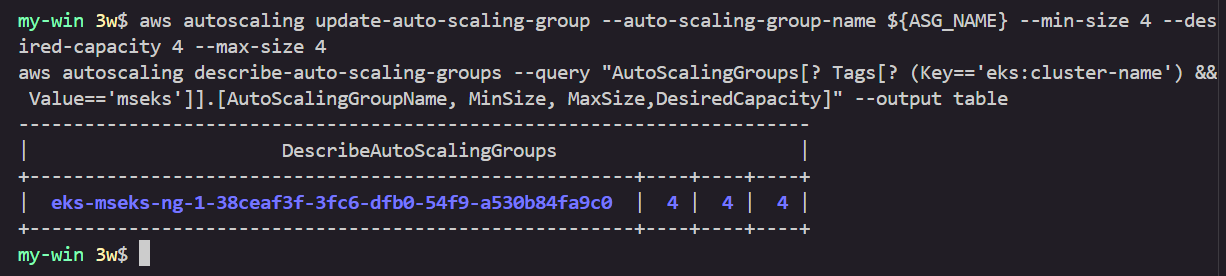
7. CA/CAS - Cluster Autoscaler
소개
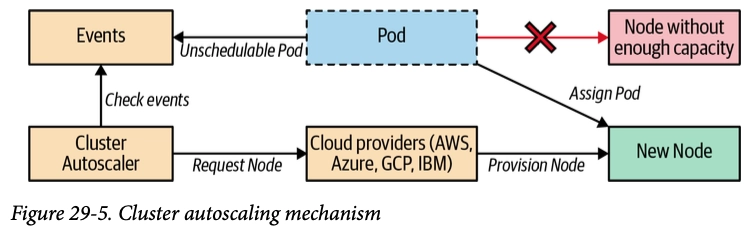
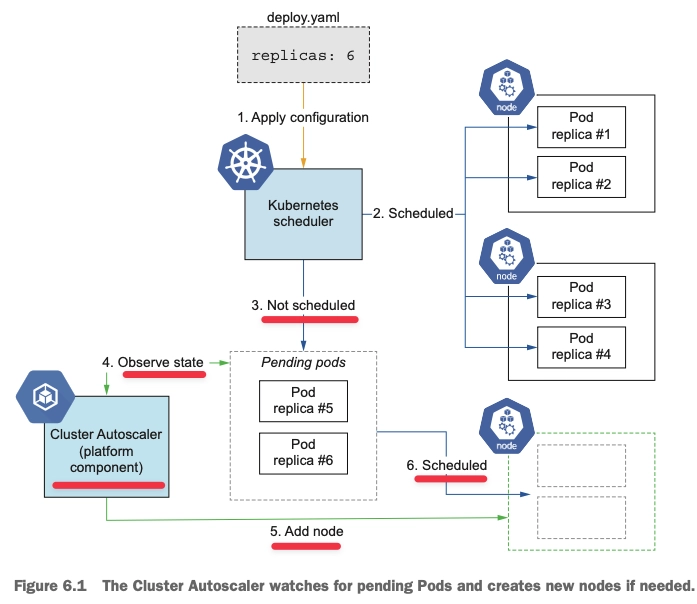
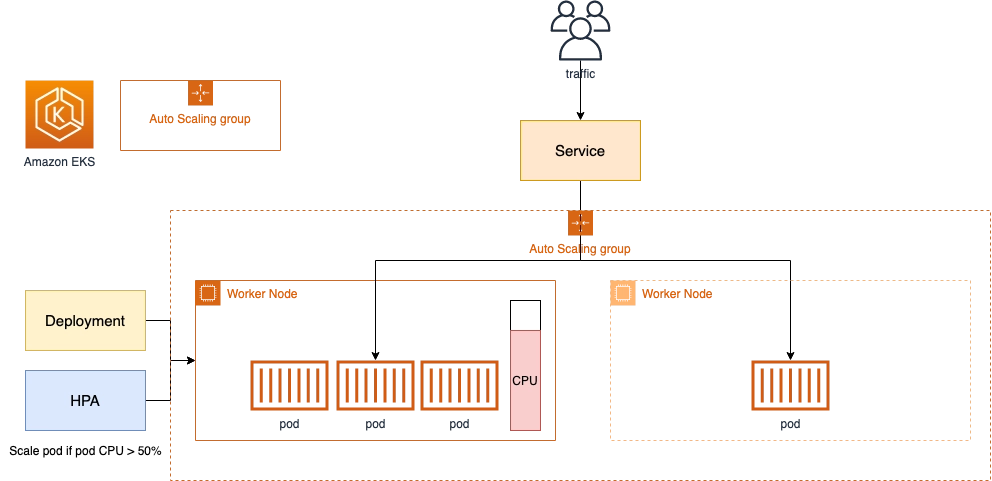
- Pending 파드 발생 시, Cluster Autoscaler가 Auto Scaling Group을 통해 워커 노드를 자동으로 스케일 인/아웃한다.
Cluster Autoscaler(CAS) 설정
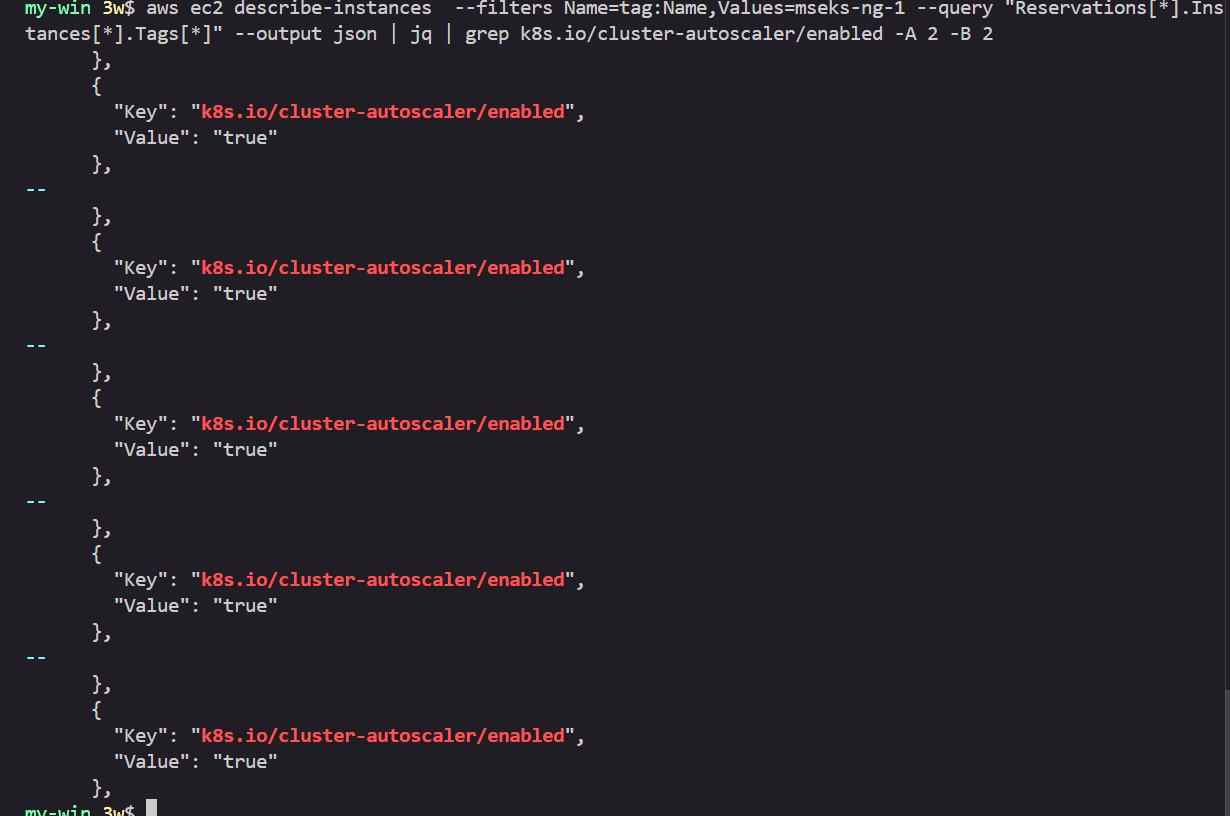
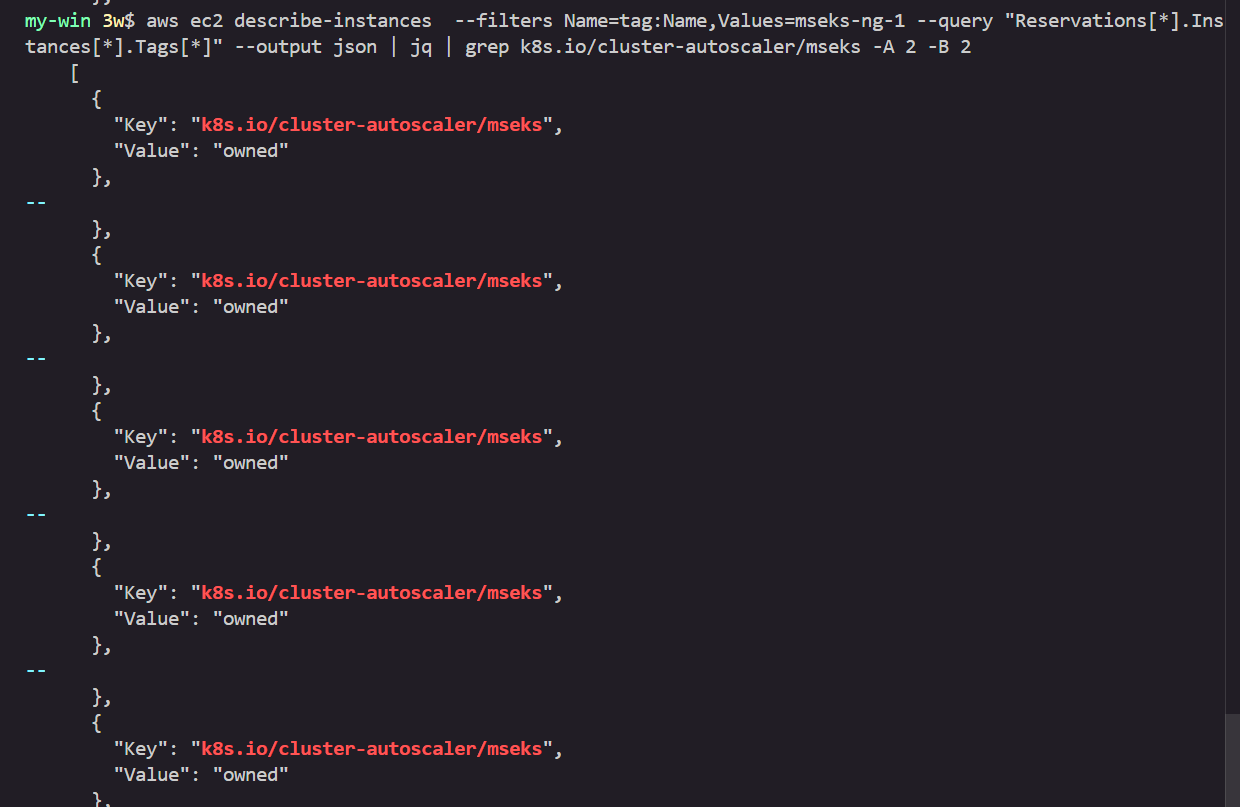
설정 전 태그 확인
# EKS 노드에 이미 아래 tag가 들어가 있음
# https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md#auto-discovery-setup
# k8s.io/cluster-autoscaler/enabled : true
# k8s.io/cluster-autoscaler/myeks : owned
aws ec2 describe-instances --filters Name=tag:Name,Values=myeks-ng-1 --query "Reservations[*].Instances[*].Tags[*]" --output json | jq
aws ec2 describe-instances --filters Name=tag:Name,Values=myeks-ng-1 --query "Reservations[*].Instances[*].Tags[*]" --output yaml
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...
CA 설치
# 현재 autoscaling(ASG) 정보 확인
# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='클러스터이름']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-44c41109-daa3-134c-df0e-0f28c823cb47 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
# MaxSize 6개로 수정
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 확인
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-c2c41e26-6213-a429-9a58-02374389d5c3 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
# 배포 : Deploy the Cluster Autoscaler (CAS)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
...
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false # 로컬 스토리지를 가진 노드를 autoscaler가 scale down할지 결정, false(가능!)
- --expander=least-waste # 노드를 확장할 때 어떤 노드 그룹을 선택할지를 결정, least-waste는 리소스 낭비를 최소화하는 방식으로 새로운 노드를 선택.
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/<YOUR CLUSTER NAME>
...
sed -i -e "s|<YOUR CLUSTER NAME>|myeks|g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
# 확인
kubectl get pod -n kube-system | grep cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler | grep node-group-auto-discovery
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
SCALE A CLUSTER WITH Cluster Autoscaler(CA)
# 모니터링
kubectl get nodes -w
while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
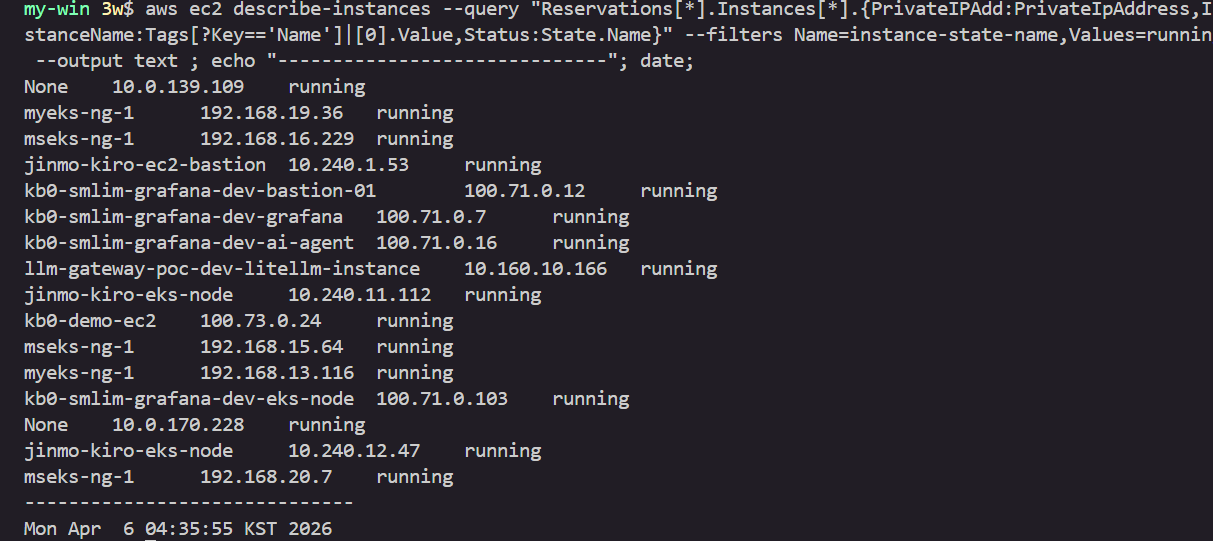
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
# Deploy a Sample App
# We will deploy an sample nginx application as a ReplicaSet of 1 Pod
cat << EOF > nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EOF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
# Scale our ReplicaSet
# Let’s scale out the replicaset to 15
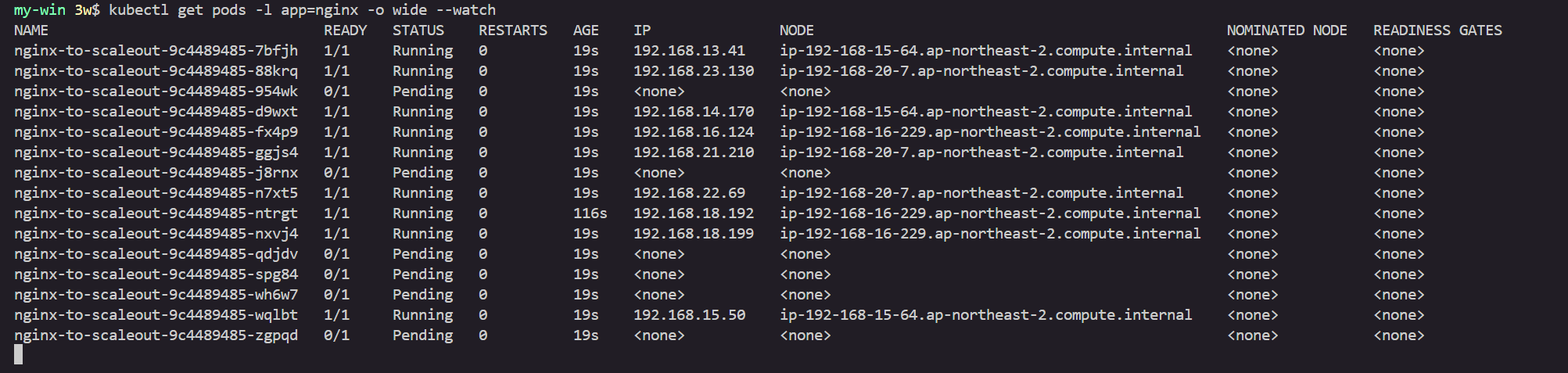
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# 확인
kubectl get pods -l app=nginx -o wide --watch
kubectl -n kube-system logs -f deployment/cluster-autoscaler
# 노드 자동 증가 확인
kubectl get nodes
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
eks-node-viewer --resources cpu,memory
혹은
eks-node-viewer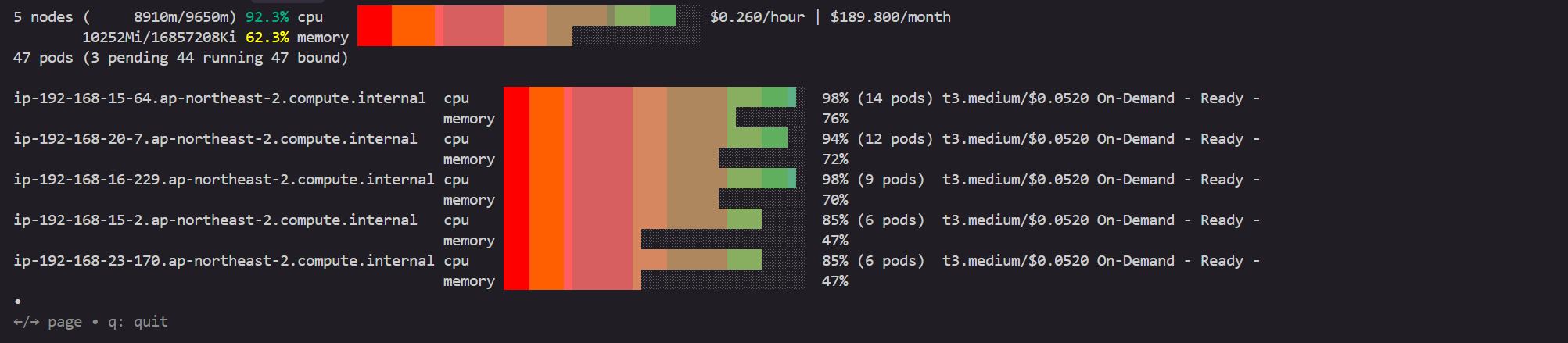
# 디플로이먼트 삭제
kubectl delete -f nginx.yaml && date
# [scale-down] 노드 갯수 축소 : 기본은 10분 후 scale down 됨, 물론 아래 flag 로 시간 수정 가능 >> 그러니 디플로이먼트 삭제 후 10분 기다리고 나서 보자!
# By default, cluster autoscaler will wait 10 minutes between scale down operations,
# you can adjust this using the --scale-down-delay-after-add, --scale-down-delay-after-delete,
# and --scale-down-delay-after-failure flag.
# E.g. --scale-down-delay-after-add=5m to decrease the scale down delay to 5 minutes after a node has been added.
# 터미널1
watch -d kubectl get node
# CloudTrail 에 CreateFleet 이벤트 조회 : 최근 90일 가능
aws cloudtrail lookup-events --lookup-attributes AttributeKey=EventName,AttributeValue=CreateFleet
8. Karpenter
개요
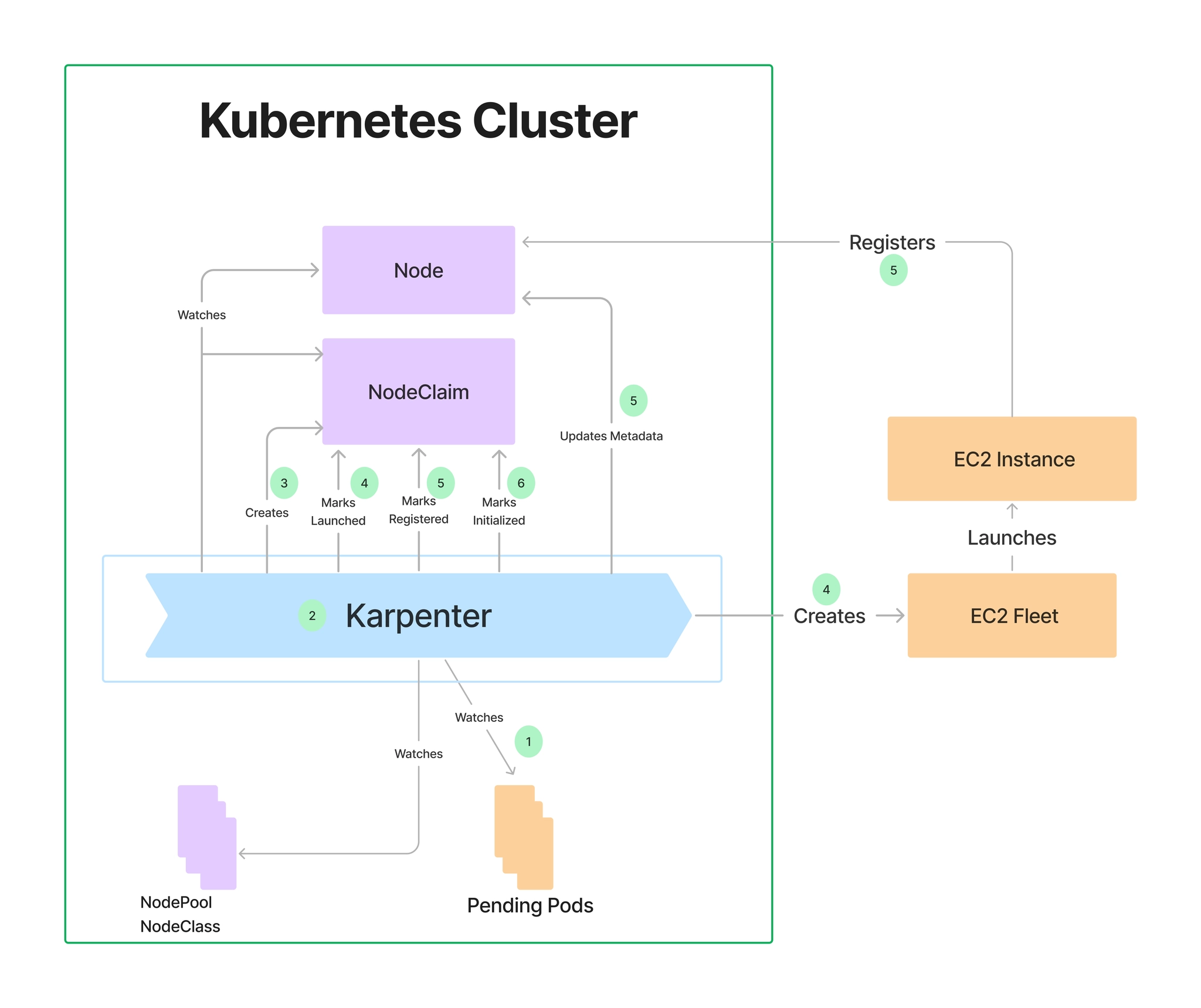
- Kubernetes 환경에서 노드 자동 생성/삭제 수행하는 오토스케일링 도구
- 기존 Cluster Autoscaler는 노드 그룹(ASG) 기반 구조
- Karpenter는 Pending Pod를 직접 분석하여 필요한 노드 즉시 생성
- 클라우드 API 직접 호출 → 중간 계층 제거 → 빠른 프로비저닝
- 스케일링 속도 개선 및 비용 최적화 가능
동작 흐름
- Pending Pod 감지
- 리소스 요구사항(CPU, Memory 등) 분석
- 최적 인스턴스 선택
- 노드 생성 및 스케줄링 수행
- 유휴 노드 자동 제거
특징 정리
| 구분 | 내용 |
|---|---|
| 스케일링 기준 | Pod 기반 |
| 프로비저닝 방식 | 클라우드 API 직접 호출 |
| 속도 | 빠름 |
| 유연성 | 다양한 인스턴스 타입 선택 가능 |
| 비용 효율성 | 자동 축소로 비용 절감 |
| 기존 방식 대비 | 노드 그룹 의존성 제거 |
9. Fargate - Nodeless(Serverless) compute engine for containers
개요
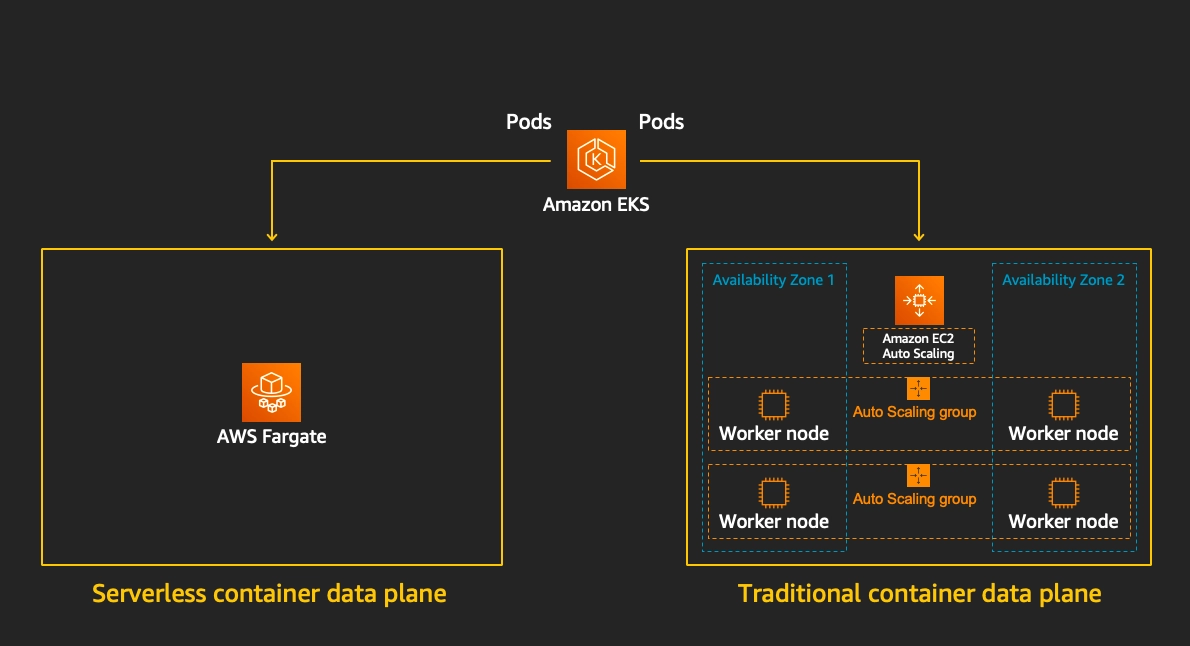
-
AWS에서 제공하는 서버리스 컨테이너 실행 환경
-
Kubernetes에서는 Amazon EKS와 통합되어 사용됨
-
노드(EC2)를 직접 생성/관리할 필요 없음 → 인프라 관리 제거됨
-
Pod 단위로 리소스를 할당하여 실행하는 구조
-
개발자는 애플리케이션과 리소스 요구사항만 정의하면 됨
-
기존 방식: 노드 기반(EC2) → 직접 프로비저닝 및 스케일링 필요
-
Fargate 방식: Pod 기반 → 필요 시 자동으로 컴퓨트 생성됨
동작 흐름
- Fargate Profile로 특정 Pod 조건 정의
- Pod 생성 요청 발생
- 조건에 맞는 Pod를 Fargate가 감지
- 전용 컴퓨트 환경(MicroVM 수준) 생성
- Pod를 해당 환경에서 실행
- Pod 종료 시 컴퓨트 리소스도 함께 제거
특징
| 구분 | 내용 |
|---|---|
| 실행 단위 | Pod 단위 |
| 인프라 관리 | 없음 (서버리스) |
| 프로비저닝 | 자동 (온디맨드) |
| 격리 수준 | Pod별 독립 환경 |
| 스케일링 | Pod 생성 시 자동 확장 |
| 운영 부담 | 낮음 |
| 제약 사항 | GPU, DaemonSet 등 일부 기능 제한 |
10. 정리하며
요약
- EKS 스케일링은 Pod 레벨과 Node 레벨로 역할 분리된 구조
- Pod 레벨(HPA, VPA, KEDA)은 워크로드 자체를 확장
- Node 레벨(Cluster Autoscaler, Karpenter)은 부족한 인프라를 확장
- Fargate는 노드 자체를 제거한 서버리스 실행 모델
서비스별 비교
| 구분 | 대상 | 스케일링 기준 | 특징 | 포지션 |
|---|---|---|---|---|
| HPA | Pod | CPU/Metric | 기본 자동 확장 | Pod 스케일링 |
| VPA | Pod | 리소스 사용량 | 리소스 자동 튜닝 | Pod 최적화 |
| KEDA | Pod | 이벤트 | 큐/스트림 기반 확장 | 이벤트 스케일링 |
| Cluster Autoscaler | Node | Pod 스케줄 실패 | ASG 기반 | 전통 Node 확장 |
| Karpenter | Node | Pod 요구사항 | 빠르고 유연한 프로비저닝 | 차세대 Node 확장 |
| Fargate | Pod | Pod 생성 | 서버리스 | 인프라 제거 |

클라우드 왕초보