
안녕하세요. 밍기뉴와제제입니다.
설 연휴가 끝났습니다. 시간이 참 빨리도 흘러갑니다. 야속하네요. 전 완성한게 아무것도 없는데. 흑흑.
이전에 1100장의 이미지로 데이터셋을 만들었다고 말씀드렸습니다.
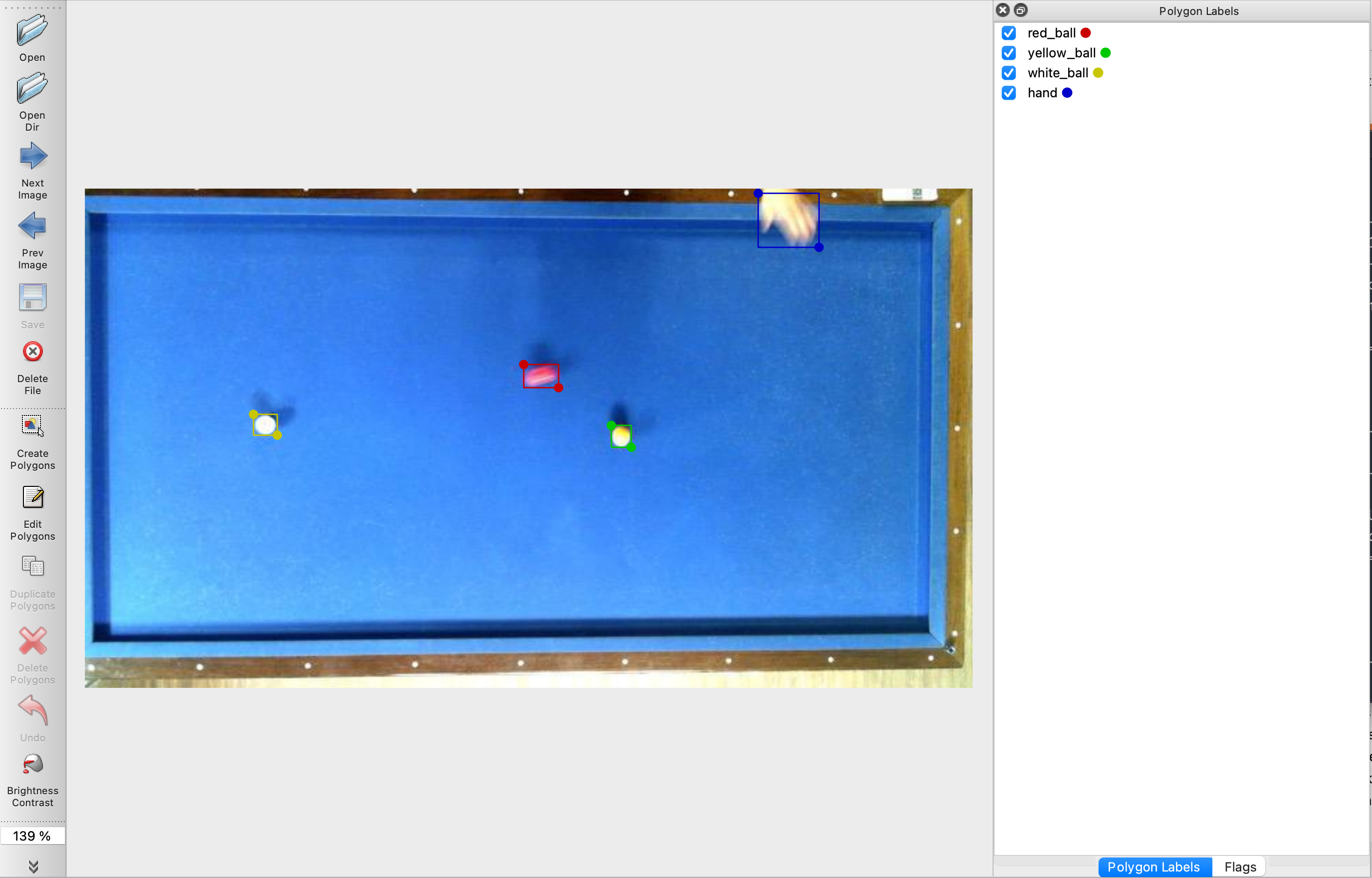
위와 같이 데이터 라벨링을 하여 데이터셋을 만들었고 학습을 시켜봤습니다. 라벨링에 사용한 프로그램은 labelme구요, 학습을 시킨 모델은 YOLOv3입니다.
제가 이전 근황글에서
객체 탐지 모델의 기반을 MS COCO 데이터셋으로 학습된 모델을 사용하기로 결정해 MS COCO 양식으로 다시 라벨링을 하기로 했습니다.
말을 했는데요, 이 때 말한 모델을 학습시킬려고 하니 제가 설치한 개발 환경이랑 호환이 잘 안되어 고심끝에 YOLOv3을 사용했습니다. 제가 사용한 YOLOv3 구현 코드는 데이터 라벨의 조건이 따로 있었긴 했으나 만들기가 쉬웠기 때문에 pascal voc양식으로 만들어진 라벨 데이터를 YOLOv3이 요구하는 방식에 맞게 변환하는 함수를 제작해 사용했습니다.
아무튼, 그렇게 1100개의 데이터가 속한 데이터셋으로 YOLOv3를 학습시키고 테스트 해봤습니다. 우선 검증 데이터셋으로 얻은 성능은
+-------------+-----------------------+
| Type | Value |
+-------------+-----------------------+
| IoU loss | 0.019257018342614174 |
| Object loss | 0.0049205804243683815 |
| Class loss | 0.0026953278575092554 |
| Batch loss | 0.026872927322983742 |
+-------------+-----------------------+
+-------+-------------+---------+
| Index | Class | AP |
+-------+-------------+---------+
| 0 | white_ball | 0.95239 |
| 1 | yellow_ball | 0.98411 |
| 2 | red_ball | 0.99498 |
+-------+-------------+---------+
---- mAP 0.97716 ----
+----------------------+----------+
| Type | Value |
+----------------------+----------+
| validation precision | 0.898061 |
| validation recall | 0.987879 |
| validation mAP | 0.977156 |
| validation f1 | 0.939965 |
+----------------------+----------+위와 같았습니다. 정말 높았습니다. 그런데 막상 테스트를 하고 나니 큐대를 공으로 인식하고 손도 공으로 인식하고...오차가 너무 많았습니다.
그걸 보고 깨달았습니다. '아, 손이랑 큐대도 라벨링을 해줘야 되겠구나'
처음에는 부정했습니다. 추가로 데이터셋 제작을 해야하는게 너무 싫었으니까요. 우선 기존에 분류하던 3종류의 클래스에서 '나머지'를 담당하는 네번째 클래스를 추가해 총 4종류의 객체를 분류하는 object detection 모델로 학습시켜 데이터셋 제작의 귀찮음을 피하고자 했습니다.
확실히 공을 잘못 판단하는 일이 줄어들긴 했는데 어...그래도 문제가 많았습니다.
그래서 하는 수 없이 손이랑 큐대를 추가로 라벨링하였습니다. 제가 왜 공에 대한 라벨링을 개선하는게 아니라 손이랑 큐대를 라벨링 했냐면 그 이유는 다음과 같습니다.
손이랑 큐대는 정확히 판단할 필요는 없는 대상입니다. 하지만 이들이 '공이 아니다'는 모델이 알고있어야 공으로 잘못 판단하는 일이 적어질 것이기 때문에 추가로 라벨링 작업을 하였습니다.
그리고 라벨링을 하는 김에 이미지 개수도 늘렸으며 그렇게 총 2896개의 데이터를 가지고 있는 데이터셋이 만들어졌습니다. 데이터셋을 추가로 만들자마자 바로 학습을 시켰습니다. 이전에 1100개의 데이터로 학습할 때는 미니 배치의 크기가 16이면 문제가 없었는데 2896장이 되니까 vram부족이라고 에러가 뜨더군요. 그래서 배치 사이즈를 12로 변경했습니다. 어짜피 이미지는 미니배치 단위로 불러올건데 메모리 사용량이 차이가 나다니...뭔가 신기했습니다.
학습을 시키고 또다시 테스트를 해봤습니다. 그런데...


이렇게 곂쳐있는 두 공을 하나의 공으로 판정하는 일이 발생하더라구요. 그래서 공이 모인 것에 대해서도 추가로 라벨링을 하고 또다시 학습을 시켜봤습니다.
근데 그래도 개선된게 없더라구요.
그래서 데이터셋을 다시 확인해봤습니다. 음...공을 라벨링 하는데 공의 경계면을 포함하지 않고 '공 내부'만 bbox의 영역으로 지정한 경우가 꽤 많다는 것을 확인할 수 있었습니다. 그러면 YOLOv3은 특정 색깔이 모여있는 픽셀 덩어리들을 다 공이라 판정하게 될 확률이 꽤 높아질 겁니다. '공'이란걸 판정할 때 공의 둥근 경계면이 아니라 bbox를 가득 채우는 같은 색상의 픽셀 덩어리들을 공이라 판정하게 될 것이니 말이죠.
저의 생각이 맞는지 확인하기 위해 라벨링 되어있던 bbox의 크기를 조금씩 늘리고 특정 크기나 특정 비율에 해당하는 공의 bbox를 '움직이는 공'의 bbox로 지정하였습니다. 그러면 '공'에 해당하는 객체는 '공'과 '움직이는 공'이 되는 것이죠.
성능이 어찌 되려나요? 아직 학습이 덜끝나서 성능을 확인할 수가 없습니다. 아마 별일 없으면 내일 확인할 수 있을듯 합니다. 좋은 결과가 나오길 바랍니다.
그리고 깃허브에도 이번 프로젝트에 관한 레포지토리를 올렸습니다. 실행파일도 같이 공유하고 싶었으나 실행파일 생성 과정에서 에러가 발생해 공유를 못하고 있습니다. 얼른 문제를 해결하고 싶네요.
다음 글은 논문리뷰로 뵙고싶은데 음...그러기가 쉽지 않아보입니다. 개발인력이 저밖에 없어서 할게 많네요. 흑흑.
그러면 다음 글에서 뵙겠습니다.
