
들어가며
1~4편을 통해 수집·저장·탐색·Trace/Logs 연동까지 확보했다.
이번 글은 “이제 그 데이터를 운영과 로컬에서 어떻게 다르게 활용했는가”에 집중한다.
- 운영 = 빠른 감지와 추적
- 로컬 = 세밀한 분석과 실험
이 두 가지는 다르다는 걸 몸소 겪으면서, 대시보드 설계도 달라져야 한다는 걸 배웠다.
1) 운영 대시보드: 빠른 감지와 추적
운영 환경에서 중요한 건 빨리 감지하고 추적하는 흐름이었다.
-
주요 패널들 (운영 JSON 기반)
- 상단 요약 지표 (CPU, Memory, Error Rate) → 한눈에 전체 상태
- Error Rate 그래프 → 장애 징후 탐지 포인트
- HTTP Requests / Latency → 트래픽 흐름 & 성능 확인
- API Traces (Tempo) → 이상 API 추적
- Loki Logs (traceId 포함) → 트레이스와 로그 연동
- Top Slow Queries → DB 병목 탐지
흐름 = 이상 감지 → Trace 추적 → Logs 확인
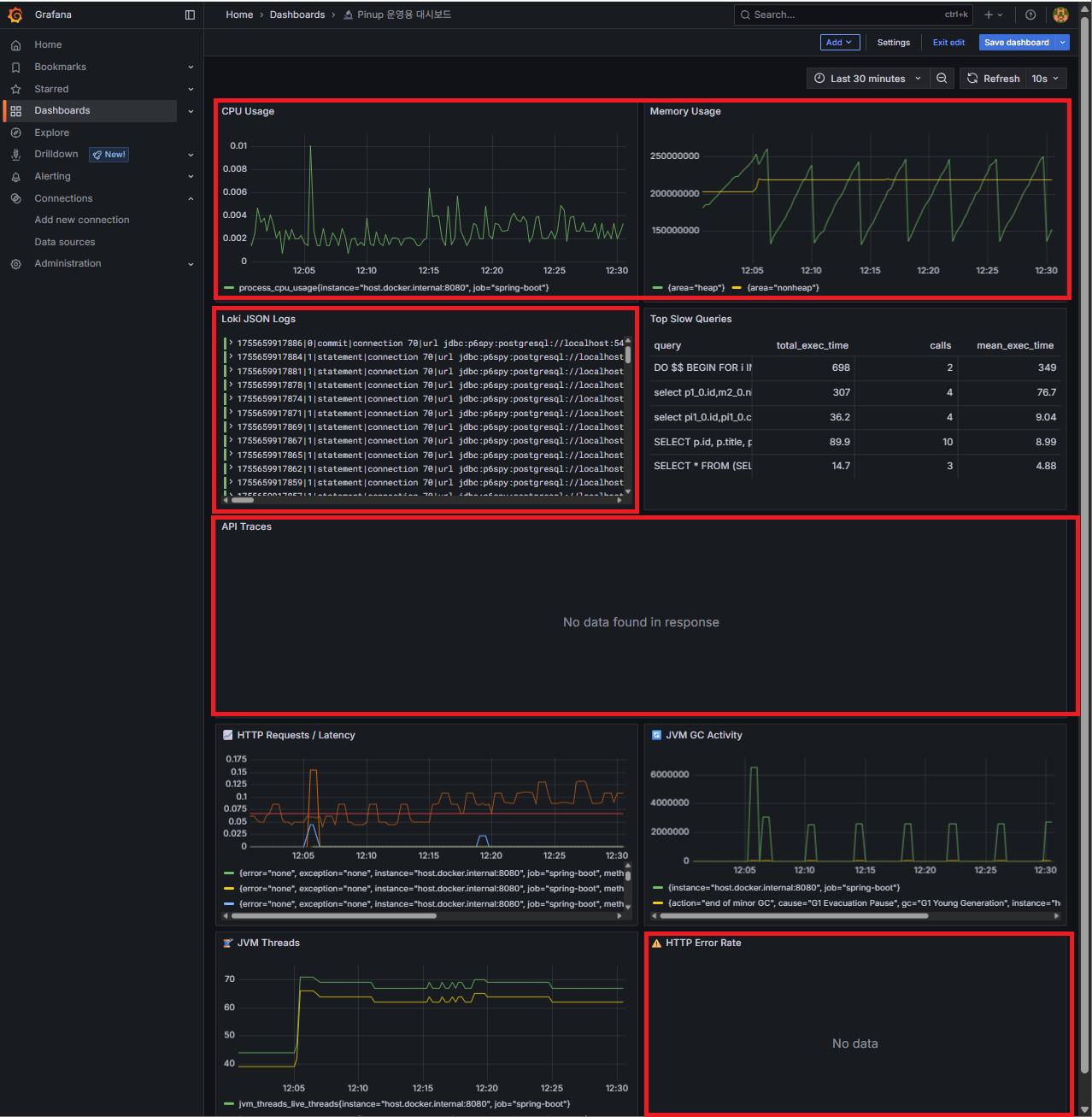
- 상단 요약 → Error Rate → Trace/Logs
2) 로컬 대시보드: 병목 분석과 실험
로컬에서는 운영과 달리 깊게 파고드는 분석이 목적이었다.
-
주요 패널들 (로컬 JSON 기반)
- 📈 URI별 Latency (변수
$uri2) → 특정 API만 골라 실험 - Top Slow Queries (pg_stat_statements) → DB 병목 분석
- HikariCP Connection 상태 → 커넥션 풀 튜닝용
- JVM Heap 메모리 / GC 횟수 → 자원 사용 패턴 확인
- Trace 보기 (Tempo) → API 요청 단위 상세 추적
- Loki 로그(traceId 포함) → Trace ↔ Logs 연동 검증
- 컨테이너 CPU 사용률 (docker_stats_exporter) → 로컬 리소스 병목 확인
- 📈 URI별 Latency (변수
흐름 = 성능 실험 → 병목 지점 확인 → Trace/Logs 교차 검증
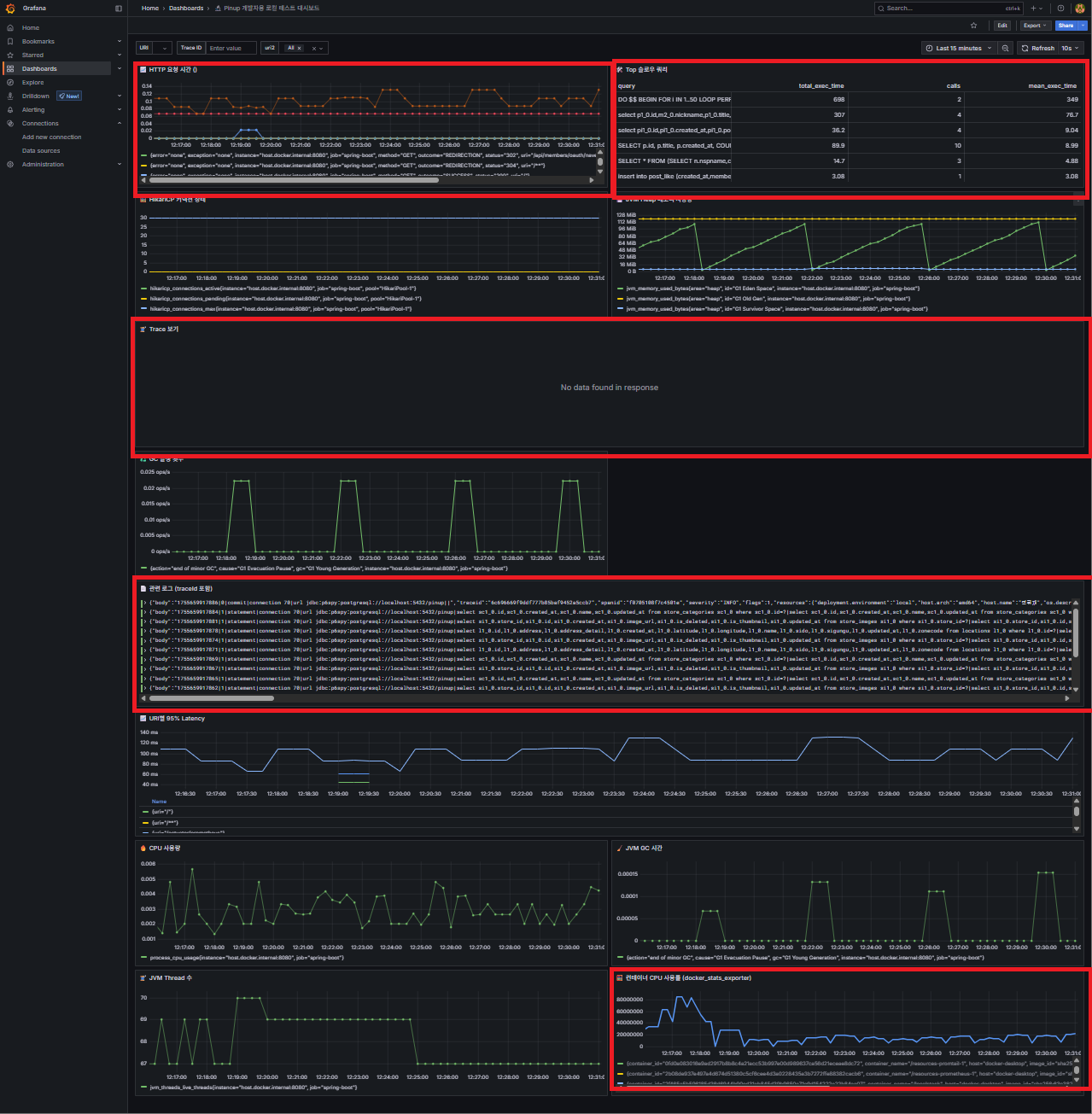
- 특정 URI Latency 그래프
- Top Slow Queries
- 컨테이너 CPU 사용률
3) 시행착오 기록
- Trace Table view 저장 불가 → 운영에서는 “보이기만 하면 된다”라서 그냥 넘김.
- 컨테이너 CPU 라벨링 문제 cadvisor로는 컨테이너 이름이 안 보임 → relabeling 시도 실패 결국
docker_stats_exporter로 전환 →container_name라벨이 붙어 “이게 DB 컨테이너구나”를 알 수 있게 됨.
docker-compose.yml (일부)
services:
docker-stats-exporter:
image: wywywywy/docker_stats_exporter:latest
container_name: docker-stats-exporter
ports:
- "9487:9487"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
prometheus.yml (scrape 설정)
scrape_configs:
- job_name: 'docker-stats'
static_configs:
- targets: ['docker-stats-exporter:9487']
이렇게 붙이면
container_cpu_usage_seconds_total{container_name="pinup-service"}형태로 메트릭이 잡히고, 컨테이너별 시계열을 확실하게 볼 수 있다.
4) 내가 배운 점
- 운영과 로컬은 대시보드 관점부터 달라야 한다.
- 운영: 단순하고 빠른 감지
- 로컬: 깊고 세밀한 분석
- UI 삽질(Trace Table view 저장 불가) 같은 건 운영에서는 치명적이지 않았다.
- 컨테이너 CPU는 “단순히 수치만 보는 것”과 “라벨로 컨테이너별로 나누어 보는 것”은 전혀 다르다. →
docker_stats_exporter가 그 차이를 만들었다.
---
마무리
이번 대시보드는 단순히 운영용이 아니라, 로컬 환경에서도 충분히 계측하고 분석할 수 있었다는 게 핵심 성과였다.
- API 응답 시간, DB 슬로우 쿼리, 컨테이너 CPU 사용량을 로컬에서 실험적으로 측정할 수 있었고
- Trace ↔ Logs 연동까지 해두니 “어떤 요청이 어떤 쿼리 때문에 느려졌는지”를 손쉽게 확인할 수 있었다.
- 운영에 올리기 전에, 로컬에서 성능 병목을 확인하고 개선 루프를 빠르게 돌릴 수 있었다.
즉, 내가 직접 겪은 시행착오(Trace Table view 문제, 컨테이너 라벨링 실패 → docker_stats_exporter 전환)는
“운영 전 단계에서 로컬을 제대로 계측 가능한 환경으로 만드는 과정”이었다.

운동처럼 개발도 작은 실천이 성장의 힘이 된다고 믿는 개발자 minpractice_jhj 기록